Sketch-Based Image Retrieval
Author :Horizon Max
✨ 编程技巧篇:各种操作小结
神经网络篇:经典网络模型
Title
- 01. A Zero-Shot Framework for Sketch Based Image Retrieval
-
- Contributions
- Architecture
- 02. Doodle to search: Practical zero-shot sketch-based image retrieval
-
- Contributions
- Architecture
- 03. Generalising Fine-Grained Sketch-Based Image Retrieval
-
- Contributions
- Architecture
- 04. Semantically tied paired cycle consistency for zero-shot sketch-based image
-
- Contributions
- Architecture
- 05. Zero-shot sketch-based image retrieval via graph convolution network
-
- Contributions
- Architecture
- 06. StyleMeUp: Towards Style-Agnostic Sketch-Based Image Retrieval
-
- Contributions
- Architecture
- 07. S^3^NET: GRAPH REPRESENTATIONAL NETWORK FOR SKETCH RECOGNITION
-
- Contributions
- Architecture
- 08. Multigraph Transformer for Free-Hand Sketch Recognition
-
- Contributions
- Architecture
- 09. More Photos are All You Need: Semi-Supervised Learning for Fine-Grained Sketch Based Image Retrieval
-
- Contributions
- Architecture
- 10. Sketching without Worrying: Noise-Tolerant Sketch-Based Image Retrieval
-
- Contributions
- Architecture

1️⃣:Awesome-Sketch-Based-Applications
2️⃣:Awesome Fine-Grained Image Analysis – Papers, Codes and Datasets
3️⃣:SketchX @ CVSSP
01. A Zero-Shot Framework for Sketch Based Image Retrieval
Publication :ECCV 2018
Paper :A Zero-Shot Framework for Sketch Based Image Retrieval
Github :Zero-shot-SBIR
Contributions
- propose a new benchmark for zero-shot SBIR where the model is evaluated on novel classes that are not seen during training.
- CVAE:Conditional Variational Autoencoders.
- CAAE:Conditional Adversarial Autoencoders.
dataset :Sketchy
Architecture
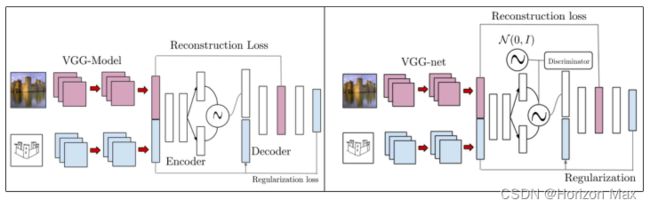
Fig. 2. The architectures of CVAE and CAAE are illustrated in the left and right diagrams respectively.
02. Doodle to search: Practical zero-shot sketch-based image retrieval
Publication :CVPR 2019
Paper :Doodle to search: Practical zero-shot sketch-based image retrieval
Github :doodle2search
Contributions
- two important but often neglected challenges of practical ZS-SBIR, (i) the large domain gap between amateur sketch and photo, (ii) the necessity for moving towards large-scale retrieval.
- first contribute to the community a novel ZS-SBIR dataset, QuickDrawExtended.
- a new dataset to simulate the real application scenario of ZS-SBIR.
- a novel cross-domain zero-shot embedding model that addresses all challenges posed by this new setting.
- 在两个常用的ZS-SBIR数据集 TUBerlin-Extended 和 Sketchy-Extended 上进行了大量的实验.
dataset :Sketchy-Extended、TUBerlin-Extended、QuickDraw-Extended
Architecture
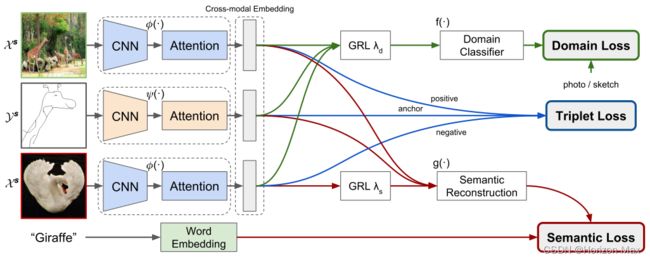
Figure 3. Proposed architecture for ZS-SBIR which maps sketches and photos in a common embedding space. It combines three losses:(i) triplet loss to learn a ranking metric; (ii) domain loss to merge images and sketches to an indistinguishable space making use of a GRL; (iii) semantic loss forces the embeddings to contain semantic information by reconstructing the word2vec embedding of the class. It also helps to distinguish semantically similar classes by means of a GRL on the negative example (best viewed in color).
03. Generalising Fine-Grained Sketch-Based Image Retrieval
Publication :CVPR 2019
Paper :Generalising Fine-Grained Sketch-Based Image Retrieval
Github :None
Contributions
- For the first time, the cross-category FG-SBIR generalisation (CC-FG-SBIR) problem is identified and tackled.
- A solution is introduced based on a novel universal prototypical visual sketch trait for instance-specific latent domain discovery.
dataset :Sketchy、QMUL-Shoe-V2
Architecture

Figure 1. Illustration of our proposed method using four categories, organised into two related pairs. TRN: triplet ranking
network. VTD: visual trait descriptor. In each bar-type VTD, we visualise its ten top distributed categories and highlight the
specific one along with three belonged representative sketch exemplars. Each sketch is uniquely assigned to one VTD that
describes a category-agnostic abstract sketch trait, which is in turn used to dynamically paramaterise the TRN so as to adapt
it to the query sketch. See how both training and testing sketches thematically and coherently mapped to some shared VTDs.
Best viewed in colour and zoom, more details in text.
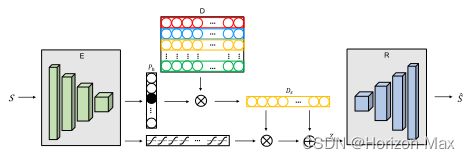
Figure 2. Schematic illustration of our proposed unsupervised encoder-decoder model. See details in text.
04. Semantically tied paired cycle consistency for zero-shot sketch-based image
Publication :CVPR 2019
Paper :Semantically tied paired cycle consistency for zero-shot sketch-based image
Github :None
Contributions
- We propose the SEM-PCYC model for zero-shot SBIR task, that maps sketch and image features to a common semantic space with the help of adversarial training. The cycle consistency constraint on each branch of the SEM-PCYC model facilitates bypassing the requirement of aligned sketch image pairs.
- Within a same end-to-end framework, we combine different side information via a feature selection guided auto-encoder which effectively choose side information that minimizes intra-class variance and maximizes inter-class variance.
- We evaluate our model on two datasets (Sketchy and TU-Berlin) with varying difficulties and sizes, and provide an experimental comparison with latest models available for the same task, which further shows that our proposed model consistently improves the state-of-the-art results of zero-shot SBIR on both datasets.
dataset :Sketchy、TU-Berlin
Architecture
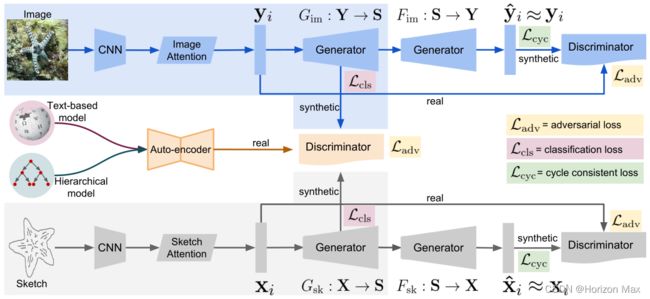
Figure 2. The deep network structure of SEM-PCYC. The sketch (in light gray) and image cycle consistent networks (in light blue) respectively map the sketch and image to the semantic space and then the original input space. An auto-encoder (light orange) combines the semantic information based on text and hierarchical model, and produces a compressed semantic representation which acts as a true example to the discriminator. During the test phase only the learned sketch (light gray region) and image (light blue region) encoders to the semantic space are used for generating embeddings on the unseen classes for zero-shot SBIR. (best viewed in color)
05. Zero-shot sketch-based image retrieval via graph convolution network
Publication :AAAI 2020
Paper :Zero-shot sketch-based image retrieval via graph convolution network
Github :None
Contributions
- We propose the SketchGCN model for the zero-shot SBIR task, using a graph convolution network and a Conditional Variational Autoencoder. With the help of these parts, our model can transfer the information from the seen categories to the unseen categories effectively.
- Instead of only taking semantic information into account, our graph convolution model with a learnable adjacency matrix considers both visual and semantic information to solve the challenges in ZS-SBIR.
- A Conditional Variational Autoencoder is implemented to enhance the generalization ability of our proposed model by generating the semantic embedding from the visual features. The SketchGCN model successfully produces good retrieval performance under two widely used datasets, which shows the effectiveness of our model.
dataset :Sketchy-Extended
Architecture

Figure 1. An overview of the architecture of our proposed SketchGCN for ZS-SBIR, which contains encoding network, semantic preserving network, and semantic reconstruction network.
The encoding network maps the sketches and images into a common space, while the semantic preserving network takes both the visual information and the semantic information as input and uses a graph convolution network to build and handle their relations. Besides, the model is optimized by the feature loss, classification loss, and semantic loss.
Loss function :- nn.CrossEntropyLoss(pred, lable)
- nn.nn.TripletMarginLoss(sketch, pos, neg)
06. StyleMeUp: Towards Style-Agnostic Sketch-Based Image Retrieval
Publication :CVPR 2021
Paper :StyleMeUp: Towards Style-Agnostic Sketch-Based Image Retrieval
Github :StyleMeUp
Contributions
- For the first time, we propose the concept of style-agnostic SBIR to deal with a largely neglected user style diversity issue in SBIR.
- We introduce a novel style-agnostic SBIR framework based on disentangling a photo/sketch image into a modalinvariant semantic content part suitable for SBIR and a model-specific part that needs to be explicitly modelled in order to minimise its detrimental effects on retrieval.
- To make the disentanglement generalisable to unseen user styles and object categories/instances, feature transformation layers and latent modal-invariant code regulariser are introduced to a VAE, both of which are meta-learned using a MAML framework for style/category/instance adaptation.
- Extensive experiments show that state-of-the-art performances can be achieved as a direct result of the style-agnostic design.
dataset :Sketchy-Extended、TU-Berlin Extension (category-level SBIR);QMUL-Chair-V2 and QMUL-Shoe-V2 (FG_SBIR)
Architecture

Figure 2. Our core model is a VAE framework that disentangles the modal variant and invariant semantics in a sketch in a crossmodal translation setting. While a regulariser network regularises parameters of the invariant component (Ωinv), feature transformation (FT) layers aid in style-agnostic encoding following a meta-learning paradigm.
07. S3NET: GRAPH REPRESENTATIONAL NETWORK FOR SKETCH RECOGNITION
Publication :ICME 2020
Paper :S3NET: GRAPH REPRESENTATIONAL NETWORK FOR SKETCH RECOGNITION
Github :s3net
Contributions
- we propose an effective approach to build a sketch-graph implementing the segment-stroke-sketch hierarchical relationship.
- Based on that, we propose a joint network which can learn temporal and structural cues simultaneously, the S3Net. ( a RNN sub-module and a GCN sub-module connected together via a graph-building module)
dataset :QuickDraw
Architecture
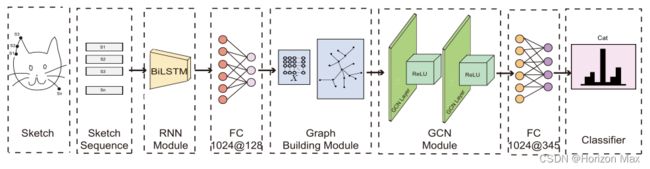
Fig. 2. S3Net. The RNN sub-module takes in a sketch sequence and outputs a node embedding matrix via a fully-connected layer. That matrix is used to build a sketch graph which is subsequently fed into the GCN sub-module. The feature generated by GCN is used for classification via a fully-connected layer.
08. Multigraph Transformer for Free-Hand Sketch Recognition
Publication :TNNLS 2021
Paper :Multigraph Transformer for Free-Hand Sketch Recognition
Github :multigraph_transformer
Contributions
- We propose to model sketches as sparsely connected graphs, which are flexible to encode local and global geometric sketch structures.
- We introduce a novel transformer architecture that can handle multiple arbitrary graphs. Using intrastroke and extra-stroke graphs, the proposed multigraph transformer (MGT) learns both local and global patterns along with subcomponents of sketches.
- Numerical experiments demonstrate the performances of our model. MGT significantly outperforms RNN-based models and achieves a small recognition gap to CNN-based architectures.
- This MGT model is agnostic to graph domains and can be used beyond sketch applications.
dataset :QuickDraw
Architecture
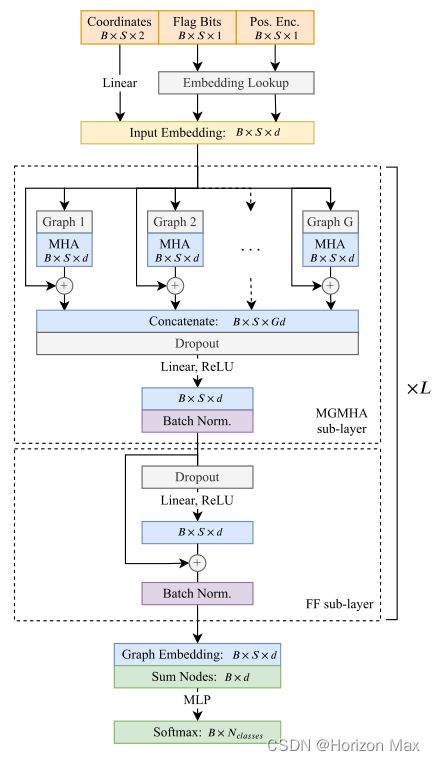
Fig. 3. MGT architecture. Each MGT layer is composed of 1) a MGMHA sublayer and 2) a position-wise fully connected FF sublayer. See details in text. “B” denotes batch size.
09. More Photos are All You Need: Semi-Supervised Learning for Fine-Grained Sketch Based Image Retrieval
Publication :CVPR 2021
Paper :More Photos are All You Need: Semi-Supervised Learning for Fine-Grained Sketch Based Image Retrieval
Github :semisupervised-FGSBIR
Contributions
- For the first time, we propose to solve the data scarcity problem in FG-SBIR by adopting semi-supervised approach that additionally leverages large scale unlabelled photos to improve retrieval accuracy.
- To this end, we couple sequential sketch generation process with fine-grained SBIR model in a joint learning framework based on reinforcement learning.
- We further propose a novel photo-to-sketch generator and introduce a discriminator guided instance weighting along with consistency loss to retrieval model training with noisy synthetic photo-sketch pairs.
- Extensive experiments validate the efficacy of our approach for overcoming data scarcity in FG-SBIR (Figure 4) – we can already reach performances at par with prior arts with just a fraction (≈60%) of the training pairs, and obtain state-of-the-art performances on both QMUL-Shoe and QMUL-Chair with the same training data (by ≈6% and ≈7% respectively).
dataset :QMUL-Shoe and QMUL-Chair
Architecture

Figure 2. Our framework: a FG-SBIR model (F) leverages large scale unlabelled photos using a sequential photo-to-sketch generation model (G) along with labelled pairs. Discriminator (DC) guided instance-wise weighting and distillation loss are used to guard against the noisy generated data.
Simultaneously, G learns by taking reward from F and DC via policy gradient (over both labelled and unlabelled) together with supervised VAE loss over labelled data. Note rasterization (vector to raster format) is a non-differentiable operation.
10. Sketching without Worrying: Noise-Tolerant Sketch-Based Image Retrieval
Publication :CVPR 2022
Paper :Sketching without Worrying: Noise-Tolerant Sketch-Based Image Retrieval
Github :NoiseTolerant-SBIR
Contributions
- We tackle the fear-to-sketch problem for sketch-based image retrieval for the first time,
- We formulate the “can’t sketch” problem as stroke subset selection problem following detailed experimental analysis,
- We propose a RL-based framework for stroke subset selection that learns through interacting with a pre-trained retrieval model.
- We demonstrate our pre-trained subset selector can empower other sketch applications in a plug-and-plug manner.
dataset :QMUL-Shoe and QMUL-Chair
Architecture

Figure 2. Illustration of Noise Tolerant FG-SBIR framework. Stroke Subset Selector X (·) acts as a pre-processing module in the sketch vector space to eliminate the noisy strokes. Selected stroke subset is then rasterized and fed through an existing pre-trained FG-SBIR model for reward calculation, which is optimised by Proximal Policy Optimisation. For brevity, actor-only version is shown here.