机器学习算法--协同过滤算法
0. 关键词
- 推荐算法
- 长尾理论
- UserCF
- ItemCF

1. 推荐算法
互联网的飞速发展使我们进入了信息过载的时代,搜索引擎可以帮助我们查找内容,但只能解决明确的需求。为了让用户从海量信息中高效地获得自己所需的信息,推荐系统应运而生。
推荐系统可以通过分析用户的历史记录来了解用户的喜好,从而主动为用户推荐其感兴趣的信息,满足用户的个性化推荐需求。推荐系统是自动联系用户和物品的一种工具,和搜索引擎相比,推荐系统通过研究用户的兴趣偏好,进行个性化计算。推荐系统可发现用户的兴趣点,帮助用户从海量信息中去发掘自己潜在的需求。
2. 长尾理论
推荐系统可以创造全新的商业和经济模式,帮助实现长尾商品的销售。“长尾” 用来描述以亚马逊为代表的电子商务网站的商业和经济模式,电子商务网站销售种类繁多,虽然绝大多数商品都不热门,但这些不热门的商品总数量极其庞大,所累计的总销售额将是一个可观的数字。
热门推荐是常用的推荐方式,广泛应用于各类网站中,如热门排行榜。但热门推荐的主要缺陷在于推荐的范围有限,所推荐的内容在一定时期内也相对固定。无法实现长尾商品的推荐。因此,可以通过发掘长尾商品并推荐给感兴趣的用户来提高销售额。这需要通过个性化推荐来实现。
3. 协同过滤
协同过滤是应用最早和最为成功的推荐方法之一,利用与目标用户相似的用户已有的商品评价信息,来预测目标用户对特定商品的喜好程度
分为
基于用户的协同过滤(UserCF)
基于物品的协同过滤(ItemCF)
4. 基于用户的协同过滤
UserCF算法符合人们对于“趣味相投”的认知,即兴趣相似的用户往往有相同的物品喜好:当目标用户需要个性化推荐时,可以先找到和目标用户有相似兴趣的用户群体,然后将这个用户群体喜欢的、而目标用户没有听说过的物品推荐给目标用户。
UserCF算法的实现主要包括两个步骤:
第一步:找到和目标用户兴趣相似的用户集合;
第二步:找到该集合中的用户所喜欢的、且目标用户没有听说过的物品推荐给目标用户
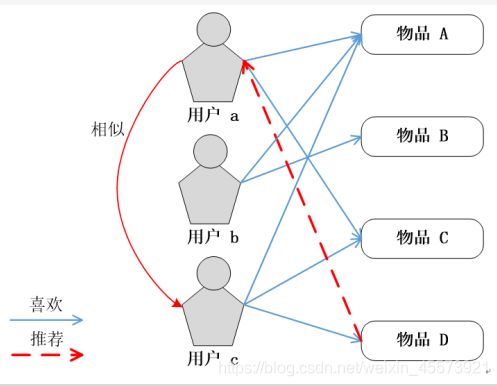
下面,我们来讨论一下,这需要如何进行实现?
根据算法的大纲来看,肯定是需要找到相似用户,如何判断用户之间的相似程度呢?
相似度算法判断用户相似度
目前较多使用的相似度算法有:泊松相关系数、余弦相似度、调整余弦相似度。
余弦相似度, N ( u ) N(u) N(u)表示用户 u 感兴趣的物品集合, N ( v ) N(v) N(v)表示用户 v 感兴趣的物品的集合,那么用户 u, v的相似度权重 ω u v \omega_{uv} ωuv 为

给出了算法,我们如何快速求出公式中的参数呢?(不难得知,这里最难计算的是分子,也就是区间的交,这是优化重点)
倘若服务器需要存储 所有用户之间的相似度的话,对时间的复杂度要求是极高的!倘若我们 先对 u 遍历,再对 v 遍历,然后再遍历 u 感兴趣的商品,是否在 v 感兴趣的商品中,那这基本就是爆炸了,所以说,正解的优化算法是:
首先,倘若用户 a 需要商品 X,那么就将它放在商品 X 的集合里面,经过对所有用户预处理之后,每个商品都对应一个集合,集合内部两两成对即可。
如下图所示:(物品到用户的倒排表)
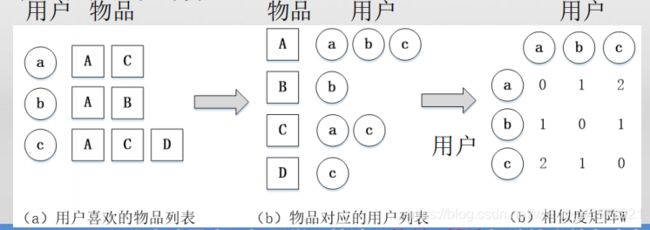
量化用户对物品的兴趣程度
从上面的分析中,可知用户直接的相似度 ω u , v \omega_{u,v} ωu,v,下面,我们进一步计算出用户对物品的兴趣程度:
p ( u , i ) p(u,i) p(u,i)表示用户 u(user) 对物品 i (item)的兴趣程度, S ( u , k ) S(u,k) S(u,k)是和用户 u 兴趣最为接近的用户的集合(对 ω u , x \omega_{u,x} ωu,x排序,取前 k 个 x)

其中,S(u, K)是和用户u兴趣最接近的 K 个用户的集合,N(i)是喜欢物品 i i i 的用户集合(含义变了), ω u v \omega_{uv} ωuv是用户u和用户v的相似度, r v i r_{vi} rvi是隐反馈信息,代表用户 v v v对物品i的感兴趣程度,为简化计算可令 r v i r_{vi} rvi=1(为了追求更高准确率是不应该都为一个数值的,比如说看客户对商品的评价等等)。
对所有物品计算p(u,i)后,可以对p(u,i)进行降序处理,取前N个物品作为推荐结果展示给用户u(称为Top-N推荐)。
具体的步骤
1.收集用户信息
收集可以代表用户兴趣的信息。一般的网站系统使用评分的方式或是给予评价,这种方式被称为“主动评分”。另外一种是“被动评分”,是根据用户的行为模式由系统代替用户完成评价,不需要用户直接打分或输入评价数据。电子商务网站在被动评分的数据获取上有其优势,用户购买的商品记录是相当有用的数据。
2.最近邻搜索(Nearest neighbor search, NNS)
以用户为基础(User-based)的协同过滤的出发点是与用户兴趣爱好相同的另一组用户,就是计算两个用户的相似度。例如:查找n个和A有相似兴趣用户,把他们对M的评分作为A对M的评分预测。一般会根据数据的不同选择不同的算法,较多使用的相似度算法有Pearson Correlation Coefficient、Cosine-based Similarity、Adjusted Cosine Similarity。
3.产生推荐结果
有了最近邻集合,就可以对目标用户的兴趣进行预测,产生推荐结果。依据推荐目的的不同进行不同形式的推荐,较常见的推荐结果有Top-N 推荐和关系推荐。Top-N 推荐是针对个体用户产生,对每个人产生不一样的结果,例如:通过对A用户的最近邻用户进行统计,选择出现频率高且在A用户的评分项目中不存在的,作为推荐结果。关系推荐是对最近邻用户的记录进行关系规则(association rules)挖掘。
UserCF小结
- userCF首先是根据相似度算法,求出每个用户之间的相识度衡量标准( ω u , v \omega_{u,v} ωu,v),得出的结果回用于求 与用户 u 相似的 前 k 个人
- 得到 ω u , v \omega_{u,v} ωu,v 数组之后,我们需要进一步计算 用户 u 对于 物品 i (item) 的兴趣程度 p u , i p_{u,i} pu,i,这个是通过 与用户 u 相似的前 k 个用户 v(基于用户) ω u , v ∗ r v , i \omega_{u,v}*r_{v, i} ωu,v∗rv,i求和得到。
- 然后对 p u , i p_{u,i} pu,i进行排序,得到个性化推荐的商品。
5. 基于物品的协同过滤
基于物品的协同过滤算法(简称ItemCF算法)是目前业界应用最多的算法。ItemCF算法是给目标用户推荐那些和他们之前喜欢的物品相似的物品。ItemCF算法主要通过分析用户的行为记录来计算物品之间的相似度。该算法基于的假设是:物品A和物品B具有很大的相似度是因为喜欢物品A的用户大多也喜欢物品B。例如,该算法会因为你购买过《数据挖掘导论》而给你推荐《机器学习实战》
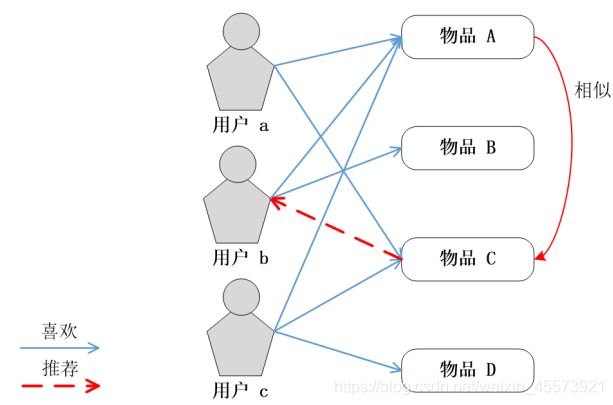
ItemCF算法与UserCF算法类似,计算也分为两步:
第一步:计算物品之间的相似度;
第二步:根据物品的相似度和用户的历史行为,给用户生成推荐列表。
下面,我们来讨论一下,这需要如何进行实现?
判断物品之间的相似度
ItemCF算法通过建立用户到物品倒排表(每个用户喜欢的物品的列表)来计算物品相似度

用户对物品的兴趣程度
ItemCF计算的是物品相似度,再使用如下公式来度量用户u
对物品j的兴趣程度Puj(与UserCF类似)

说人话就是,用户 u 对一个物品 j 个喜爱与否,通过判断 和 j 相似的 前 k 个物品,用户喜欢的程度,进行 加权求和(物品之间多相似和用户对物品有多喜爱)
具体的算法步骤
1.收集用户信息
同以用户为基础(User-based)的协同过滤。
2.针对项目的最近邻搜索
先计算已评价项目和待预测项目的相似度,并以相似度作为权重,加权各已评价项目的分数,得到待预测项目的预测值。例如:要对项目 A 和项目 B 进行相似性计算,要先找出同时对 A 和 B 打过分的组合,对这些组合进行相似度计算,常用的算法同以用户为基础(User-based)的协同过滤。
3.产生推荐结果
以项目为基础的协同过滤不用考虑用户间的差别,所以精度比较差。但是却不需要用户的历史数据,或是进行用户识别。对于项目来讲,它们之间的相似性要稳定很多,因此可以离线完成工作量最大的相似性计算步骤,从而降低了在线计算量,提高推荐效率,尤其是在用户多于项目的情形下尤为显著。
6. UserCF和ItemCF算法的对比
UserCF算法和ItemCF算法的思想、计算过程都相似两者最主要的区别:
- UserCF算法推荐的是那些和目标用户有共同兴趣爱好的其他用户所喜欢的物品
ItemCF算法推荐的是那些和目标用户之前喜欢的物品类似的其他物品 - UserCF算法更偏向社会化,适合应用于新闻推荐、微博话题推荐等应用场景,其推荐结果在新颖性方面有一定的优势。
ItemCF算法更偏向于个性化。适合应用于电子商务、电影、图书等应用场景

从上图可以看出,是解决这个问题的两种写法
7. 隐式反馈和显示反馈
参考大佬的博客
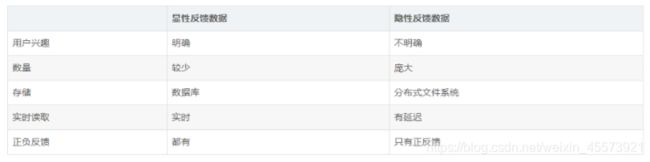
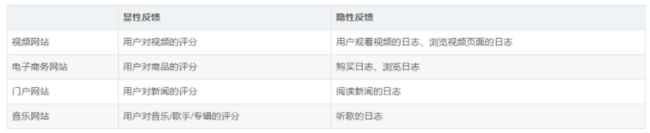
隐性反馈行为:不能明确反映用户喜好的行为。
显性反馈行为:用户明确表示对物品喜好的行为。
显性反馈行为包括用户明确表示对物品喜好的行为,隐性反馈行为指的是那些不能明确反应用户喜好的行为。在许多的现实生活中的很多场景中,我们常常只能接触到隐性的反馈,例如页面游览,点击,购买,喜欢,分享等等。
基于矩阵分解的协同过滤的标准方法,一般将用户商品矩阵中的元素作为用户对商品的显性偏好。在 MLlib 中所用到的处理这种数据的方法来源于文献: Collaborative Filtering for Implicit Feedback Datasets 。 本质上,这个方法将数据作为二元偏好值和偏好强度的一个结合,而不是对评分矩阵直接进行建模。因此,评价就不是与用户对商品的显性评分,而是与所观察到的用户偏好强度关联起来。然后,这个模型将尝试找到隐语义因子来预估一个用户对一个商品的偏好。
参考文献
- 燕山大学机器学习讲义
- 大佬的博客