2-图像分割之FCN
1.FCN简介
终于来到图像分割的开山之作FCN,在FCN之前进行的图像分割,大多是根据图像的一些低阶视觉信息来进行分割,经典的方法有N-cut,Grab cut等,这些算法的优点是不需要使用算法进行训练,计算复杂度小,但是同时的,对于一些较困难的分割任务效果不太理想同时分割效率也比较低。伴随着机器学习等一系列技术的发展,图像分割也来到了一个新的时代,FCN便是其中的开山鼻祖,为往后的模型提供了基石。
FCN的一些优点可以简答概括为以下几点:
1.将原始的分类网络改编为全卷积神经网络,具体包括全连接层转化为卷积层,以及通过反卷积进行上采样
2.使用迁移学习的方法进行微调(因为使用了之前的VGG,GoogLeNet等网络做基础)
3.使用跳跃结构使得语义信息和表征信息相结合,使得分割结果更加准确。
全局信息与局部信息:

离图片越近层次的网络越接近图片本身,几何信息保留较为完整,感受野小,局部信息越丰富,有助于分割小尺寸的目标
而离图片越远的网络基本看不出是个图片样了,此时网络注重整体性,感受野大,上下文信息越丰富,有助于分割尺寸较大的目标。
局部信息与全局信息可谓是不可兼得的鱼和熊掌,需要在两者之间做平衡来使得效果最好。
感受野相关概念:
上采样相关概念:
FCN模型架构
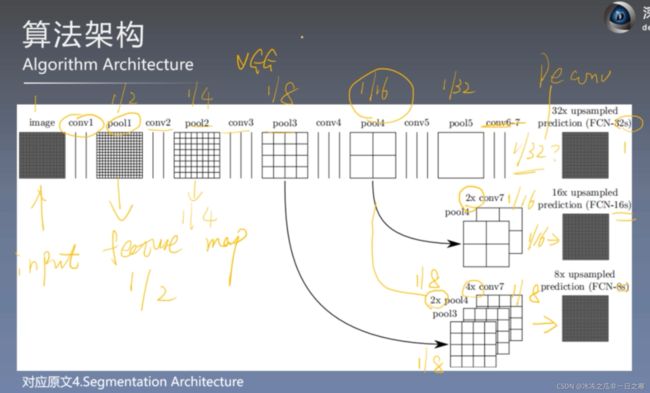
按照论文里说的其实这张图其实包含三个模型。FCN-32s,FCN-16s,FCN-8s
FCN-32s:其实就是第一层,con6-7之后直接进行32倍上采样至原图大小。
FCN-16s:把con6-7之后的网络先进行2倍上采样恢复至原图的1/16,再结合pool4中1/16的特征图,最后两个一起进行16倍上采样恢复至原图大小。
FCN-8s:则是在FCN-16s的基础上再加上pool3的特征图,最后一起进行8倍上采样。
其实大家大概可以想到,一个进行32倍上采样,一个8倍上采样,直观上有感觉32倍上采样放大的效果应该是不如8倍上采样的,最后实验结果也的确如此,因为直接进行32倍上采样有许多特征被丢失导致分割结果不太理想。



小总结:

2.基于Pytorch的FCN实现
数据预处理:dateset.py
目标就是把带颜色的label图转化为单通道的编码图
"""补充内容见 data process and load.ipynb"""
import pandas as pd
import os
import torch as t
import numpy as np
import torchvision.transforms.functional as ff
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
import cfg
class LabelProcessor:
"""对标签图像的编码"""
def __init__(self, file_path):
self.colormap = self.read_color_map(file_path)
self.cm2lbl = self.encode_label_pix(self.colormap)
# 静态方法装饰器, 可以理解为定义在类中的普通函数,可以用self.方式调用
# 在静态方法内部不可以示例属性和实列对象,即不可以调用self.相关的内容
# 使用静态方法的原因之一是程序设计的需要(简洁代码,封装功能等)
@staticmethod
def read_color_map(file_path): # data process and load.ipynb: 处理标签文件中colormap的数据
pd_label_color = pd.read_csv(file_path, sep=',')
colormap = []
for i in range(len(pd_label_color.index)):
tmp = pd_label_color.iloc[i]
color = [tmp['r'], tmp['g'], tmp['b']]
colormap.append(color)
return colormap
@staticmethod
def encode_label_pix(colormap): # data process and load.ipynb: 标签编码,返回哈希表
cm2lbl = np.zeros(256 ** 3)
for i, cm in enumerate(colormap):
cm2lbl[(cm[0] * 256 + cm[1]) * 256 + cm[2]] = i
return cm2lbl
def encode_label_img(self, img):
data = np.array(img, dtype='int32')
idx = (data[:, :, 0] * 256 + data[:, :, 1]) * 256 + data[:, :, 2]
return np.array(self.cm2lbl[idx], dtype='int64')
class CamvidDataset(Dataset):
def __init__(self, file_path=[], crop_size=None):
"""para:
file_path(list): 数据和标签路径,列表元素第一个为图片路径,第二个为标签路径
"""
# 1 正确读入图片和标签路径
if len(file_path) != 2:
raise ValueError("同时需要图片和标签文件夹的路径,图片路径在前")
self.img_path = file_path[0]
self.label_path = file_path[1]
# 2 从路径中取出图片和标签数据的文件名保持到两个列表当中(程序中的数据来源)
self.imgs = self.read_file(self.img_path)
self.labels = self.read_file(self.label_path)
# 3 初始化数据处理函数设置
self.crop_size = crop_size
def __getitem__(self, index):
img = self.imgs[index]
label = self.labels[index]
# 从文件名中读取数据(图片和标签都是png格式的图像数据)
img = Image.open(img)
label = Image.open(label).convert('RGB')
img, label = self.center_crop(img, label, self.crop_size)
img, label = self.img_transform(img, label)
# print('处理后的图片和标签大小:',img.shape, label.shape)
sample = {'img': img, 'label': label}
return sample
def __len__(self):
return len(self.imgs)
def read_file(self, path):
"""从文件夹中读取数据"""
files_list = os.listdir(path)
file_path_list = [os.path.join(path, img) for img in files_list]
file_path_list.sort()
return file_path_list
def center_crop(self, data, label, crop_size):
"""裁剪输入的图片和标签大小"""
data = ff.center_crop(data, crop_size)
label = ff.center_crop(label, crop_size)
return data, label
def img_transform(self, img, label):
"""对图片和标签做一些数值处理"""
label = np.array(label) # 以免不是np格式的数据
label = Image.fromarray(label.astype('uint8'))
transform_img = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]
)
img = transform_img(img)
label = label_processor.encode_label_img(label)
label = t.from_numpy(label)
return img, label
label_processor = LabelProcessor(cfg.class_dict_path)
if __name__ == "__main__":
TRAIN_ROOT = './CamVid/train'
TRAIN_LABEL = './CamVid/train_labels'
VAL_ROOT = './CamVid/val'
VAL_LABEL = './CamVid/val_labels'
TEST_ROOT = './CamVid/test'
TEST_LABEL = './CamVid/test_labels'
crop_size = (352, 480)
Cam_train = CamvidDataset([TRAIN_ROOT, TRAIN_LABEL], crop_size)
Cam_val = CamvidDataset([VAL_ROOT, VAL_LABEL], crop_size)
Cam_test = CamvidDataset([TEST_ROOT, TEST_LABEL], crop_size)
模型搭建 FCN.py:
自己额外加入了FCN32s(scores1)和FCN16s(scores2)的输出.
另外在实现的过程中有两个感悟:
1.self.scores1等和self.conv_trans1等似乎原理相同?感觉都是1乘以1卷积降低通道,或许可以起相同的名字
2.最后在add2之后下一步是不是也可以先self.upsample_8x进行上采样调整至352,480,256,然后再调整通道数变成352,480,12呢?我个人给出的解释是两种方法应该都可以,都不影响结果,不过先降低通道可以使得参数量更少一点,所以先对通道进行操作,再上采样操作。
# encoding: utf-8
"""补充内容见model and loss.ipynb & 自定义双向线性插值滤子(卷积核).ipynb"""
import numpy as np
import torch
from torchvision import models
from torch import nn
def bilinear_kernel(in_channels, out_channels, kernel_size):
"""Define a bilinear kernel according to in channels and out channels.
Returns:
return a bilinear filter tensor
"""
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:kernel_size, :kernel_size]
bilinear_filter = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype=np.float32)
weight[range(in_channels), range(out_channels), :, :] = bilinear_filter
return torch.from_numpy(weight)
pretrained_net = models.vgg16_bn(pretrained=True)
class FCN(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.stage1 = pretrained_net.features[:7]
self.stage2 = pretrained_net.features[7:14]
self.stage3 = pretrained_net.features[14:24]
self.stage4 = pretrained_net.features[24:34]
self.stage5 = pretrained_net.features[34:]
self.scores1 = nn.Conv2d(512, num_classes, 1)
self.scores2 = nn.Conv2d(512, num_classes, 1)
self.scores3 = nn.Conv2d(128, num_classes, 1)
self.conv_trans1 = nn.Conv2d(512, 256, 1)
self.conv_trans2 = nn.Conv2d(256, num_classes, 1)
self.upsample_32x = nn.ConvTranspose2d(512, 512, 64, 32, 16, bias=False)
self.upsample_32x.weight.data = bilinear_kernel(512, 512, 64)
self.upsample_16x = nn.ConvTranspose2d(512, 512, 32, 16, 8, bias=False)
self.upsample_16x.weight.data = bilinear_kernel(512, 512, 32)
self.upsample_8x = nn.ConvTranspose2d(num_classes, num_classes, 16, 8, 4, bias=False)
self.upsample_8x.weight.data = bilinear_kernel(num_classes, num_classes, 16)
self.upsample_2x_1 = nn.ConvTranspose2d(512, 512, 4, 2, 1, bias=False)
self.upsample_2x_1.weight.data = bilinear_kernel(512, 512, 4)
self.upsample_2x_2 = nn.ConvTranspose2d(256, 256, 4, 2, 1, bias=False)
self.upsample_2x_2.weight.data = bilinear_kernel(256, 256, 4)
def forward(self, x): #352,480,3
s1=self.stage1(x) #176,240,64
s2 = self.stage2(s1) #88,120,128
s3=self.stage3(s2) #44,60,256
s4 = self.stage4(s3) #22,30,512
s5 = self.stage5(s4) #11,15,512
q1=self.upsample_32x(s5) #352,480,512
scores1=self.scores1(q1) #352,480,12
s5=self.upsample_2x_1(s5) #22,30,512
add1=s4+s5 #22,30,512
q2=self.upsample_16x(add1) #352,480,512
scores2=self.scores2(q2) #352,480,12
add1=self.conv_trans1(add1) #22,30,256
add1=self.upsample_2x_2(add1) #44,60,256
add2=add1+s3 #44,60,256
add2=self.conv_trans2(add2) #44,60,12
scores3=self.upsample_8x(add2) #352,480,12
return scores3
if __name__ == "__main__":
import torch as t
print('-----'*5)
rgb = t.randn(1, 3, 352, 480)
net = FCN(12)
out = net(rgb)
print(out.shape)关于上采样部分输出的计算:

卷积部分对应的计算:

训练,验证,预测函数:
train.py
import torch as t
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from datetime import datetime
from dataset import CamvidDataset
from evalution_segmentaion import eval_semantic_segmentation
from FCN import FCN
import cfg
device = t.device('cuda') if t.cuda.is_available() else t.device('cpu')
Cam_train = CamvidDataset([cfg.TRAIN_ROOT, cfg.TRAIN_LABEL], cfg.crop_size)
Cam_val = CamvidDataset([cfg.VAL_ROOT, cfg.VAL_LABEL], cfg.crop_size)
train_data = DataLoader(Cam_train, batch_size=cfg.BATCH_SIZE, shuffle=True, num_workers=0)
val_data = DataLoader(Cam_val, batch_size=cfg.BATCH_SIZE, shuffle=True, num_workers=0)
fcn = FCN(12)
fcn = fcn.to(device)
criterion = nn.NLLLoss().to(device)
optimizer = optim.Adam(fcn.parameters(), lr=1e-4)
def train(model):
best = [0]
net = model.train()
# 训练轮次
for epoch in range(cfg.EPOCH_NUMBER):
print('Epoch is [{}/{}]'.format(epoch + 1, cfg.EPOCH_NUMBER))
if epoch % 50 == 0 and epoch != 0:
for group in optimizer.param_groups:
group['lr'] *= 0.5
train_loss = 0
train_acc = 0
train_miou = 0
train_class_acc = 0
# 训练批次
for i, sample in enumerate(train_data):
# 载入数据
img_data = Variable(sample['img'].to(device)) # [4, 3, 352, 480]
img_label = Variable(sample['label'].to(device)) # [4, 352, 480]
# 训练
out = net(img_data) # [4, 12, 352, 480]
out = F.log_softmax(out, dim=1)
loss = criterion(out, img_label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
# 评估
pre_label = out.max(dim=1)[1].data.cpu().numpy() # (4, 352, 480)
pre_label = [i for i in pre_label]
true_label = img_label.data.cpu().numpy() # (4, 352, 480)
true_label = [i for i in true_label]
eval_metrix = eval_semantic_segmentation(pre_label, true_label)
train_acc += eval_metrix['mean_class_accuracy']
train_miou += eval_metrix['miou']
train_class_acc += eval_metrix['class_accuracy']
print('|batch[{}/{}]|batch_loss {: .8f}|'.format(i + 1, len(train_data), loss.item()))
metric_description = '|Train Acc|: {:.5f}|Train Mean IU|: {:.5f}\n|Train_class_acc|:{:}'.format(
train_acc / len(train_data),
train_miou / len(train_data),
train_class_acc / len(train_data),
)
print(metric_description)
if max(best) <= train_miou / len(train_data):
best.append(train_miou / len(train_data))
t.save(net.state_dict(), '{}.pth'.format(epoch))
def evaluate(model):
net = model.eval()
eval_loss = 0
eval_acc = 0
eval_miou = 0
eval_class_acc = 0
prec_time = datetime.now()
for j, sample in enumerate(val_data):
valImg = Variable(sample['img'].to(device))
valLabel = Variable(sample['label'].long().to(device))
out = net(valImg)
out = F.log_softmax(out, dim=1)
loss = criterion(out, valLabel)
eval_loss = loss.item() + eval_loss
pre_label = out.max(dim=1)[1].data.cpu().numpy()
pre_label = [i for i in pre_label]
true_label = valLabel.data.cpu().numpy()
true_label = [i for i in true_label]
eval_metrics = eval_semantic_segmentation(pre_label, true_label)
eval_acc = eval_metrics['mean_class_accuracy'] + eval_acc
eval_miou = eval_metrics['miou'] + eval_miou
#eval_class_acc = eval_metrics['class_accuracy'] + eval_class_acc
cur_time = datetime.now()
h, remainder = divmod((cur_time - prec_time).seconds, 3600)
m, s = divmod(remainder, 60)
time_str = 'Time: {:.0f}:{:.0f}:{:.0f}'.format(h, m, s)
val_str = ('|Valid Loss|: {:.5f} \n|Valid Acc|: {:.5f} \n|Valid Mean IU|: {:.5f} \n|Valid Class Acc|:{:}'.format(
eval_loss / len(train_data),
eval_acc / len(val_data),
eval_miou / len(val_data),
eval_class_acc / len(val_data)))
print(val_str)
print(time_str)
if __name__ == "__main__":
train(fcn)
test.py
import torch as t
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from evalution_segmentaion import eval_semantic_segmentation
from dataset import CamvidDataset
from FCN import FCN
import cfg
device = t.device('cuda') if t.cuda.is_available() else t.device('cpu')
BATCH_SIZE = 4
miou_list = [0]
Cam_test = CamvidDataset([cfg.TEST_ROOT, cfg.TEST_LABEL], cfg.crop_size)
test_data = DataLoader(Cam_test, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
net = FCN(12)
net.eval()
net.to(device)
net.load_state_dict(t.load('xxx.pth'))
train_acc = 0
train_miou = 0
train_class_acc = 0
train_mpa = 0
error = 0
for i, sample in enumerate(test_data):
data = Variable(sample['img']).to(device)
label = Variable(sample['label']).to(device)
out = net(data)
out = F.log_softmax(out, dim=1)
pre_label = out.max(dim=1)[1].data.cpu().numpy()
pre_label = [i for i in pre_label]
true_label = label.data.cpu().numpy()
true_label = [i for i in true_label]
eval_metrix = eval_semantic_segmentation(pre_label, true_label)
train_acc = eval_metrix['mean_class_accuracy'] + train_acc
train_miou = eval_metrix['miou'] + train_miou
train_mpa = eval_metrix['pixel_accuracy'] + train_mpa
if len(eval_metrix['class_accuracy']) < 12:
eval_metrix['class_accuracy'] = 0
train_class_acc = train_class_acc + eval_metrix['class_accuracy']
error += 1
else:
train_class_acc = train_class_acc + eval_metrix['class_accuracy']
print(eval_metrix['class_accuracy'], '================', i)
epoch_str = ('test_acc :{:.5f} ,test_miou:{:.5f}, test_mpa:{:.5f}, test_class_acc :{:}'.format(train_acc /(len(test_data)-error),
train_miou/(len(test_data)-error), train_mpa/(len(test_data)-error),
train_class_acc/(len(test_data)-error)))
if train_miou/(len(test_data)-error) > max(miou_list):
miou_list.append(train_miou/(len(test_data)-error))
print(epoch_str+'==========last')predict.py
import pandas as pd
import numpy as np
import torch as t
import torch.nn.functional as F
from torch.utils.data import DataLoader
from PIL import Image
from dataset import CamvidDataset
from FCN import FCN
import cfg
device = t.device('cuda') if t.cuda.is_available() else t.device('cpu')
Cam_test = CamvidDataset([cfg.TEST_ROOT, cfg.TEST_LABEL], cfg.crop_size)
test_data = DataLoader(Cam_test, batch_size=1, shuffle=True, num_workers=0)
net = FCN(12).to(device)
net.load_state_dict(t.load("xxx.pth"))
net.eval()
pd_label_color = pd.read_csv('./CamVid/class_dict.csv', sep=',')
name_value = pd_label_color['name'].values
num_class = len(name_value)
colormap = []
for i in range(num_class):
tmp = pd_label_color.iloc[i]
color = [tmp['r'], tmp['g'], tmp['b']]
colormap.append(color)
cm = np.array(colormap).astype('uint8')
dir = "/home/lsj/Documents/深度之眼/Semantic_Segmentation_FCN-master/result_pics/"
for i, sample in enumerate(test_data):
valImg = sample['img'].to(device)
valLabel = sample['label'].long().to(device)
out = net(valImg)
out = F.log_softmax(out, dim=1)
pre_label = out.max(1)[1].squeeze().cpu().data.numpy()
pre = cm[pre_label]
pre1 = Image.fromarray(pre)
pre1.save(dir + str(i) + '.png')
print('Done')在看教程的时候留了一个作业,就是加入验证的代码,由于本人属实菜,没搞得出来,目前想法是应该在训练的每一轮epoch后面加,要么就是加入一个判断条件。个人对验证集的看法是用来监督训练的过程,比如训练了10轮,然后输入验证集看一下指标,然后调整参数,再开始训练集的训练。感觉验证集就是人为构造的一个“测试集”,在这种情况下,测试集应该模拟的是真实世界里的数据。
补充知识:
1.双线性插值简单实现
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import cv2
def Bilinear_interpolation (src, new_size):
"""使用双线性插值方法放大图像
para:
src(np.ndarray):输入图像
new_size:(tuple): 目标尺寸
ret:
dst(np.ndarray): 目标图像
"""
dst_h, dst_w = new_size # 目标图像的高和宽
src_h, src_w = src.shape[:2] #源图像的高和宽
if src_h == dst_h and src_w == dst_w:
return src.copy()
scale_x = float(src_w) / dst_w #缩放比例
scale_y = float(src_h) / dst_h
#遍历目标图上的每一个像素,由原图的点插入数值
dst = np.zeros((dst_h, dst_w, 3), dtype=np.uint8) #生成一张目标尺寸大小的空白图,遍历插值
for n in range(3): #循环channel
for dst_y in range(dst_h): #循环height
for dst_x in range(dst_w): #循环width
#目标像素在源图上的坐标
# src_x + 0.5 = (dst_x + 0.5) * scale_x
src_x = (dst_x + 0.5) * scale_x - 0.5 # 一个像素默认为1*1的小格子,其中心在像素坐标点加0.5的位置
src_y = (dst_y + 0.5) * scale_y - 0.5
#计算在源图上四个近邻点的位置
src_x_0 = int(np.floor(src_x)) #向下取整 floor(1.2) = 1.0
src_y_0 = int(np.floor(src_y))
src_x_1 = min(src_x_0 + 1, src_w - 1) #防止出界
src_y_1 = min(src_y_0 + 1, src_h - 1)
#双线性插值 新图像每个像素的值来自于原图像上像素点的组合插值
value0 = (src_x_1 - src_x) * src[src_y_0, src_x_0, n] + (src_x - src_x_0) * src[src_y_0, src_x_1, n]
value1 = (src_x_1 - src_x) * src[src_y_1, src_x_0, n] + (src_x - src_x_0) * src[src_y_1, src_x_1, n]
dst[dst_y, dst_x, n] = int((src_y_1 - src_y) * value0 + (src_y - src_y_0) * value1)
return dst
if __name__ == '__main__':
img_in = cv2.imread('放入你需要放大的图片')
img_out = Bilinear_interpolation(img_in, (1000,1000)) #放大成1000乘以1000分辨率
cv2.imshow('src_img',img_in)
cv2.imshow('dst_img',img_out)
key = cv2.waitKey()
if key == 27:
cv2.destroyAllWindows()
print(img_in.shape)
print(img_out.shape)2.期望:

熵:

相对熵:

交叉熵(相对熵的变形):

代码中用到softmax激活:

P(x)标签值,Q(x)预测值,这里这个表达式来看的话ai应该等于Q(xi),softmax也就是预测的值,对应下面代码里这个out其实就可以相当于上面表达式里的log(softmax)
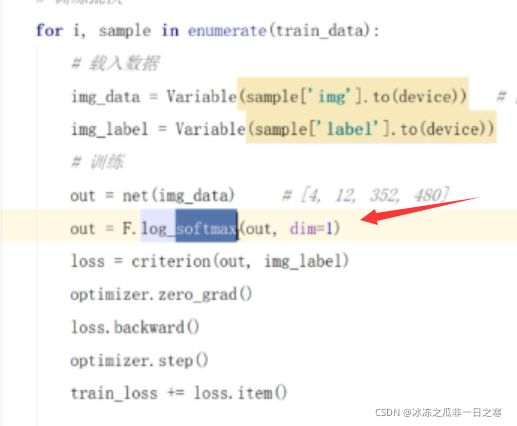
那么至此交叉熵函数H(P,Q)就变成yi乘以log(softmax),后面这个根据上面应该不难推断出是个值,那么yi如何参与进计算?这里引入one-hot编码概念。

交叉熵与NLLoss的关系:
将激活函数剥离开来好处是方便进行激活函数的选择与调整。
接下来是我个人对整个流程的一个理解:
首先要明白的是之前预处理返回的一对训练数据是包含一张训练的图片,以及哈希编码过后的和原图大小相等的数值图,类似下面这种

# gt = tensor([[[0, 1, 1],
# [0, 0, 0]]])
# gt:dim(batch, w, h)
# out = tensor([[[[-0.2070, -1.0661, -0.6972],
# [-0.1605, -0.6022, -0.4681]],
#
# [[-1.6767, -0.4221, -0.6891],
# [-1.9085, -0.7933, -0.9839]]]])
# out:dim(Batch, channel, w, h)
criterion = nn.NLLLoss(reduction='none') # default reduction='mean'
loss = criterion(out, gt)
loss
# loss = tensor([[[0.2070, 0.4221, 0.6891],
# [0.1605, 0.6022, 0.4681]]])
# loss:dim(batch, w, h)
# loss[0][0][0] = 0.2070 来自 -out[0][i][0][0] i=gt[0][0][0]=0
# loss[0][1][0] = 0.1605 来自 -out[0][i][1][0] i=gt[0][1][0]=0
# loss[0][0][1] = 0.4221 来自 -out[0][i][0][1] i=gt[0][0][1]=1
# (0.2070 + 0.4221 + 0.6891 + 0.1605 + 0.6022 + 0.4681) / 6 = 0.4248
# criterion = nn.NLLLoss() # default reduction='mean'
# loss = criterion(out, gt) = 0.4248label标签维度:gt:dim(batch, h, w)
模型输出维度:out:dim(Batch, channel, h, w)
loss维度:loss:dim(batch, h, w)
首先输入训练的image,模型会输出一张全是scores的分数图,维度dim(Batch, channel, h, w),随后进入log_softmax函数,然后输出。此时产生了对应每个像素所对应的分类的概率。

以左上角第一个元素来说,模型输出的就是[0.1,0.1,0.6,0.1,0.1],此时对于这个像素的label值是[0,0,1,0,0],然后做计算结果就是对于第一个像素模型预测产生的loss。
还记得上面说的数据吐出来的label只是哈希编码过的值,所以还需要把这个哈希编码过的label转化为one-hot值,然后再参与计算。实际使用NLLLoss()损失函数时,传入的标签,无需进行 one_hot 编码。Log_Softmax()激活函数、NLLLoss()损失函数、CrossEntropyLoss()损失函数浅析_Lyndon0_0的博客-CSDN博客。按照理论上应该是转化为one-hot编码再传入进行计算,但是因为one-hot编码其实只有0和1两种,最终体现出来其实只是1乘以模型对应地方的值,只要从模型对应的地方直接去取值就行,以上是我对为什么传入标签无需进行one-hot编码的一点理解。
3.混淆矩阵

bin代表下面橙色数组的元素个数

实际代码操作是倒着来的,先初始化上面6*6的向量,然后在往里面填值.
参考:
【论文复现代码数据集见评论区】FCN语义分割的“开山之作”,小姐姐10小时中气十足讲paper,你也能专注学习不犯困_哔哩哔哩_bilibili
【pytorch】ConvTranspose2d的计算公式_计算机研究生-CSDN博客
pytorch nn.conv2d参数个数计算_probie的博客-CSDN博客