初体验完全托管型图数据库 Amazon Neptune
0. 前言
嗨,大家好呀!最近我跟一个学摄影的高中朋友突然聊起天,发现摄影真的是一门我根本无法达到的艺术,我作为普通人,那只能说叫做拍照,哈哈。但给我更大的启发的是,这位朋友同时对星球星际也特别感兴趣,但正因为人类对宇宙的探索是十分有限的,我们即使通过高端的望远镜也只能领略到浩瀚宇宙的一角。有时候想到,宇宙中数十亿的星球聚集在一起,缩小到一定的比例,不就像一张由各个节点组成的网络吗?现实中我们的互联网、人体中的细胞、交际关系等,不都是这样吗?
这个时候我就联想到,那如果我们做开发的时候,对于这种“关系网络”,应该如何更加优雅地去存储呢?关系型数据库显然不够优雅,毕竟谁也不想通过数量庞大地关系表来表示错综复杂的数据,而且也不直观。
正因为如此,亚马逊推出了一款图数据库,用于解决这一问题。这就是大名鼎鼎的 Amazon Neptune。Neptune 译为海王星,可以说是非常的形象了。更为重要的是,Amazon Neptune 还支持免费试用,并且还提供了上手教程。只需要戳一下这里,就能开始使用了。
https://aws.amazon.com/cn/getting-started/databases/get-started/?nc=sn&loc=4&trk=fab55528-7c2e-4517-b90e-65b760ecfc1c&sc_channel=el
而且亚马逊这次提供的产品不仅仅只是 Neptune,亚马逊云科技提供了100余种产品免费套餐。其中,计算资源Amazon EC2首年12个月免费,750小时/月;存储资源 Amazon S3 首年12个月免费,5GB标准存储容量;数据库资源 Amazon RDS 首年12个月免费,750小时;Amazon Dynamo DB 25GB存储容量 永久免费。这边是入口:https://aws.amazon.com/cn/free/?nc2=h_ql_pr_ft&all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc&awsf.Free%20Tier%20Types=*all&awsf.Free%20Tier%20Categories=*all&trk=e0213267-9c8c-4534-bf9b-ecb1c06e4ac6&sc_channel=el
1. Amazon Neptune 是什么?
首先,我们来看亚马逊官方对 Amazon Neptune 给的英文定义:
Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. The core of Neptune is a purpose-built, high-performance graph database engine. This engine is optimized for storing billions of relationships and querying the graph with milliseconds latency. Neptune supports the popular graph query languages Apache TinkerPop Gremlin, the W3C’s SPARQL, and Neo4j’s openCypher, enabling you to build queries that efficiently navigate highly connected datasets. Neptune powers graph use cases such as recommendation engines, fraud detection, knowledge graphs, drug discovery, and network security.
我们将其翻译为中文:
Amazon Neptune是一种快速、可靠、完全管理的图形数据库服务,可以轻松构建和运行与高度连接的数据集一起工作的应用程序。Neptune的核心是一个专门构建的高性能图形数据库引擎。此引擎针对存储数十亿个关系和查询延迟毫秒的图形进行了优化。Neptune支持流行的图形查询语言Apache TinkerPop、Gremlin、W3C的SPARQL和Neo4j的openCypher,使您能够构建高效导航高度连接数据集的查询。Neptune powers图表用例,如推荐引擎、欺诈检测、知识图表、药物发现和网络安全。
通过官方定义我们了解到:Amazon Neptune 是一款支持 Gremlin 等图形查询语言查询的图形数据库产品,并且对高数据量时性能问题进行了优化,适用于推荐引擎、欺诈检测、知识图表、药物发现和网络安全等领域。
说到数据库产品,大家首先想到的可能是大名鼎鼎的关系型数据库 MySQL 。那么同为数据库,两者之间有什么区别呢?举个通俗易懂的例子,学习过关系型数据库的小伙伴应该都知道,在关系型数据库中,想要实现 用户-权限-关系 这个功能点,我们除了要设计三张主表外,还需要额外设计两张关系表,并且要通过设计复杂的外键,编写复杂的 SQL 语句,才能达到实现我们的产品,并且还要牺牲一部分性能,而 Neptune 则非常善于处理这种关系复杂的案例。这正是 Neptune 的用武之处。
2. 案例复现 Neptune 的用武之处
在理解 Neptune 之前,我们先来看一下什么是图表数据库。

上图我们可以获得信息: Justin 的朋友是 Anna,Anna 喜欢 books 和 Movies,而 Justin 只喜欢 Movies。而从上一节我们知道,图表数据库更善于存储和查询数据项与数据项之间的关系。而对于上图,我们更加印证了这一点,想想如果用关系型数据库去表示上面的这些关系,既复杂,又不直观。
上面的元素以及他们的关系,我们可以试图用更专业的词语去描述他们。比如:
对于每个数据项,我们把他们叫做 vertices,也就是顶点。
对于数据项之间的关系,我们把他们叫做 edges(边),每条边都有一种类型,并且由一个数据项指向另一个数据项。
3. Neptune 可以运用于哪些领域?
在我们现实世界中,存在着各种各样的关系,而当我们需要描述这些关系的时候,就可以使用图表数据库。
几种常见的领域:
知识图谱:在这个领域中,我们可以将知识定义为顶点,知识的从属可以定义为边。例如 编程语言 和 Java 可以定义为顶点,Java 属于 编程语言这层关系定义为边。
社交网络:将各种人物定义为顶点,把关系(朋友,老师,家长)定义为边。
行车路线:把两座城市定义为顶点,把路的名称定义为边。
物流:将货物的出发地和目的地定义为顶点,路线定义为边。
…
4. 如何查询 Neptune 图数据库?
在第一节中,我们讲到,官方推荐我们可以使用 Gremlin 或 SPARQL 等流行的图形查询语言对 Neptune 数据库进行查询,接下来我们来演示一下。

对于上图的关系,我们如果想要查询 Howard 的朋友的朋友,那么怎么编写代码呢?
Gremlin 遍历查询,返回 Howard 的朋友的朋友:
g.V().has('name', 'Howard').out('friend').out('friend').values('name')
SPARQL 遍历查询,返回 Howard 的朋友的朋友:
prefix : <#>
select ?names where {
?howard :name "Howard" .
?howard :friend/:friend/:name ?names .
}
5. 使用 Neptune 图表笔记本
5.1 使用方式及对比
Neptune 图表笔记本,顾名思义就是用于编写代码的工具,用于管理 Neptune 图数据库。亚马逊提供了两种方式使用笔记本。一种是在 Neptune 工作台托管 Neptune 笔记本,一种是在本地计算机上设置图形笔记本。
对于使用笔记本的两种操作方式,主要的特点如下:
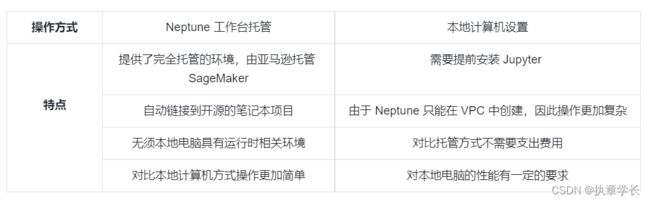
通过综合对比之后发现,Neptune 工作台完全托管方式比本地安装更加方便,更加高效。
5.2 Neptune 工作台托管的使用方法
1、确保允许入站规则
2、登录 AWS 管理控制台
3、在左侧导航窗口,选择笔记本并创建笔记本
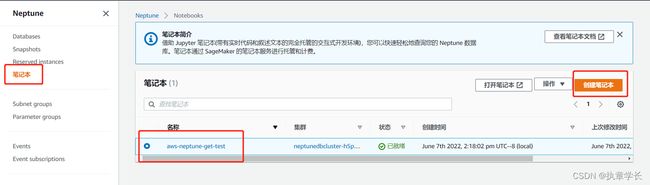
4、选择一个自己的集群,如果你自己没有集群的话,需要选择创建集群创建一个。
5、创建好笔记本后选择打开笔记本即可。

6. 实验环境搭建
6.1 实验环境搭建
步骤一:登录到 AWS console,选择 cloudshell
1、先进入亚马逊官网,找到 AWS 管理控制台

2、搜索 cloudshell 服务并进入

将会来到一个控制台页面

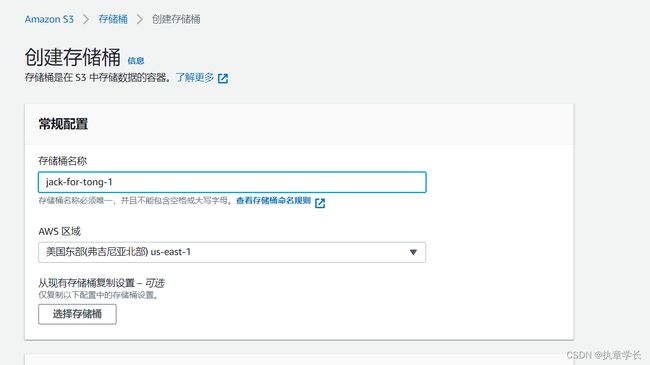
步骤二:创建 S3 存储桶,取个不常见的名字,需要记住创建的名字,后面都会用到,在这个地方我将我的存储桶的名字命名为 myawsjackui,你可以任意的取一个名字。创建存储桶的命令如下:aws s3api create-bucket --bucket 自己取个复杂点的名字 --region us-east-1
你也可以使用手动的方式创建存储桶,方法如下:

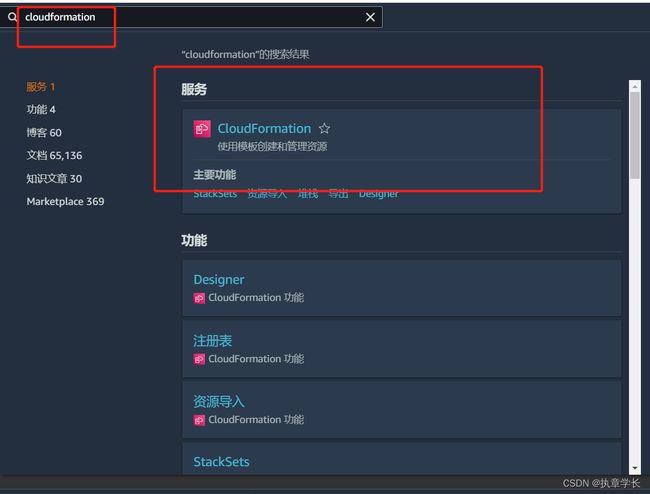
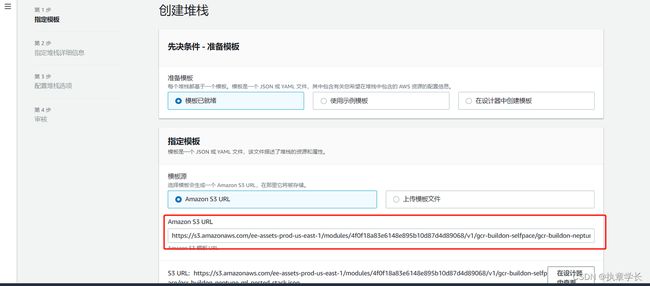
步骤三:创建 cloudformation
创建 cloudformation 命令如下:aws s3api create-bucket --bucket jack_for_test_one --region us-east-1
创建完成后,控制台没有报错信息,此时你需要等待大约 30 分钟才能进行下一步。
30 分钟过后,搜索 cloudformation ,找到对应的服务并打开
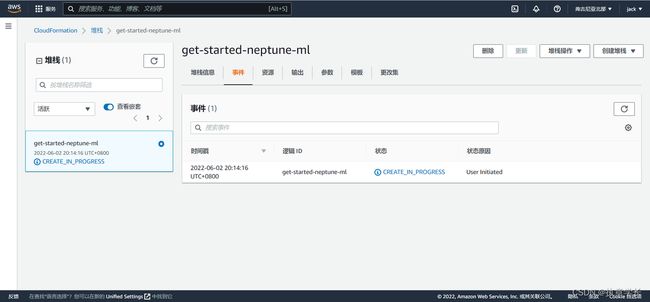
6.2 实验具体步骤(一)
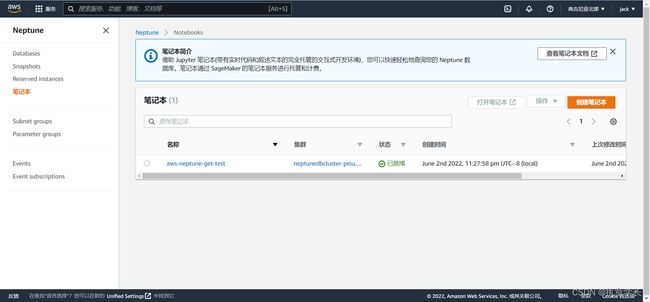
步骤一:创建笔记本
搜索 neptune ,打开对应的服务,找到笔记本选项,会发现目录下有一个名为 aws-neptune-get-test的笔记本,打开该笔记本。


步骤二:具体实验步骤
1、运行 Neptune ML

2、配置自己的存储桶及获取资源


3、创建相关端点,等待约 5 - 10 分钟
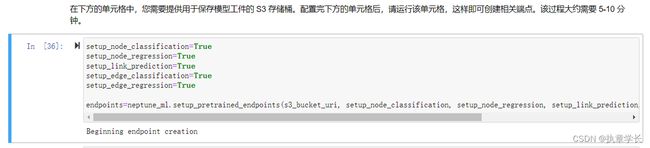
4、节点回归

5、关联预测
6.3 实验具体步骤(二)
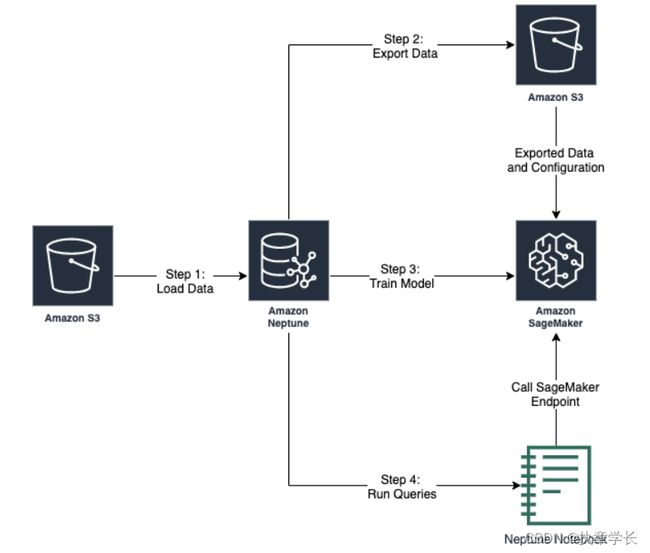
1、项目运行流程图:
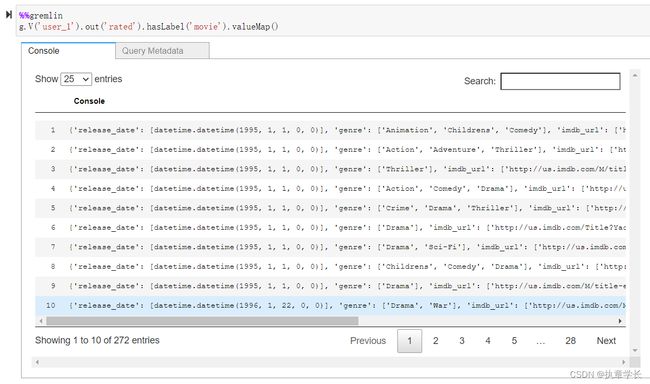
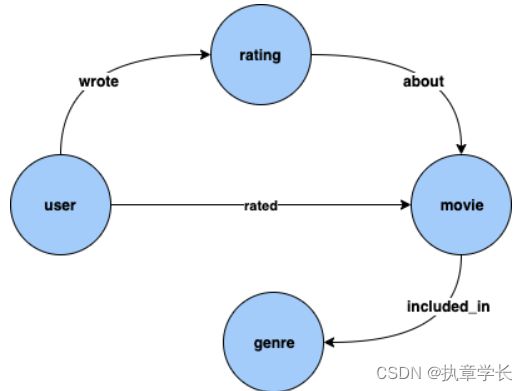
2、数据集包含电影、用户,以及用户对这些电影的评分信息,大致关系如下:
3、同样是准备好运行 Neptune ML
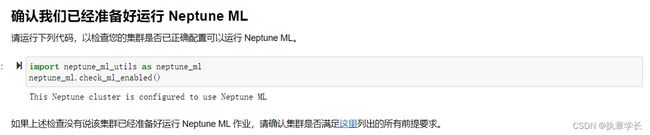
4、加载数据
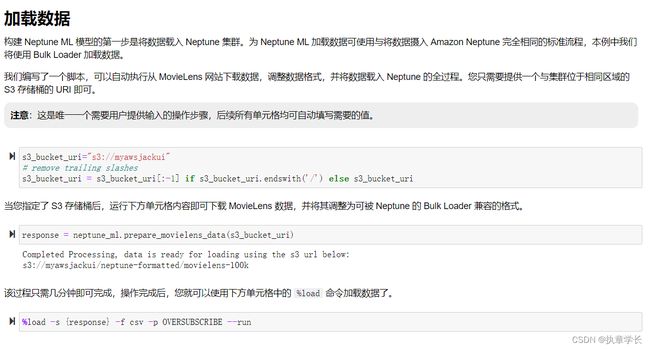
5、此时必须确认数据已经成功过加载
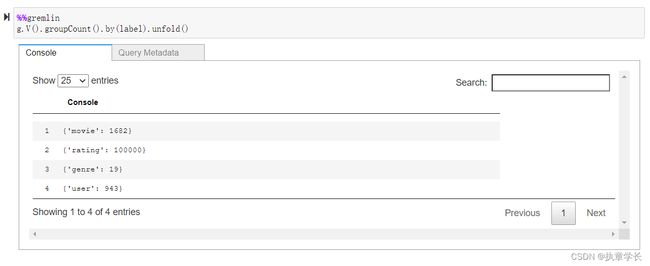
6、包括边缘数据
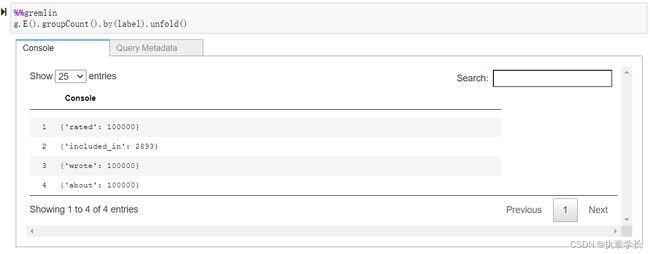
7、导出数据
完成数据验证操作后,我们首先需要移除一些 rated 顶点,以便构建可以预测这些缺失连接的模型。
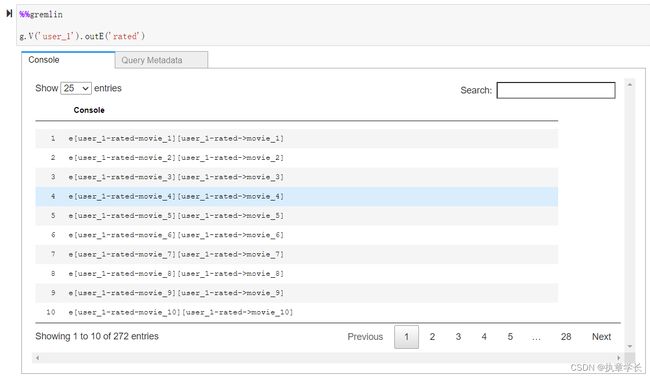
8、接下来我们需要除去这些边缘来模拟真实缺失的边缘
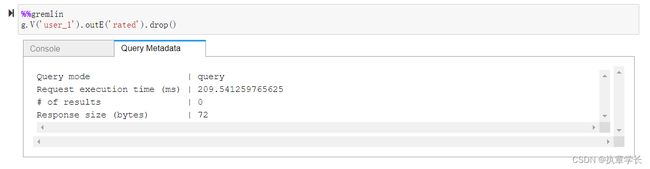
9、再一次检查数据,发现边缘已经去除
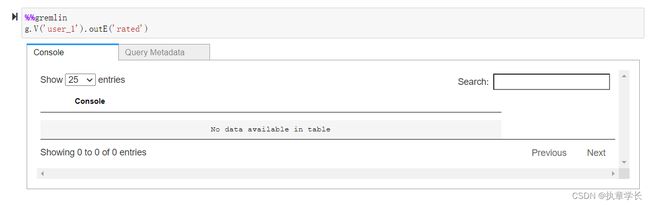
10、导出对应的数据
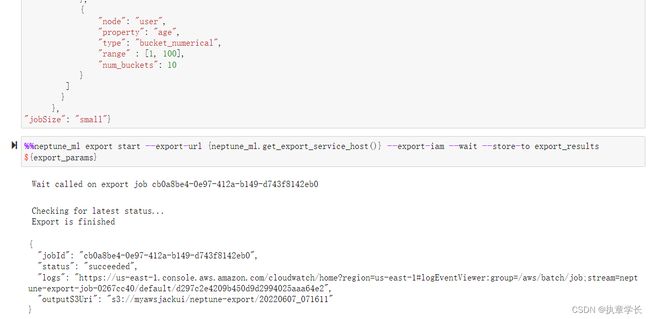
11、接下来要对数据进行处理、模拟训练和端点创建


12、预测用户可能对哪些电影进行评论
![[图片]](http://img.e-com-net.com/image/info8/e4d8aca65bf04077b155e4f38aed04d3.jpg)
13、最后需要对数据进行清理

7. 使用总结
Neptune 这款产品对我来说是眼前一亮的感觉,上手体验感非常优雅,支持常见的开放图谱 API,在安全方面方面也是提供了多级保护,并且完全托管的概念让开发者不在过多的关注如何管理数据库任务等等。
总而言之,在关系型数据库仍然占据主流的今天,很多领域,特别是大数据相关领域,对数据的查询效率要求非常高,需要更小更低的延迟,这种时候,传统的数据库从设计之初的角度就已经不够使用。你完全可以尝试使用一款全新的图数据库来更优雅地存储各种错综复杂地关系。