对话清华大学周昊,详解IJCAI杰出论文及其背后的故事

来源:授权自AI科技大本营(ID:rgznai100)
本文约7700字,建议阅读10+分钟。
本文中周昊分享了自己NLP研究心得,并对自己的获奖论文进行了解读,希望可以给大家的研究与学习带来灵感。
[ 导读 ]2018 年 7月 13 日——19 日,ICJAI 2018 在瑞典首都斯德哥尔摩顺利召开。IJCAI(International Joint Conference on Artificial Intelligence)人工智能领域顶级学术会议之一,涵盖领域包括机器学习、图像识别、语音技术、自然语言处理、视频技术等,对全球人工智能行业有着巨大的影响力。
IJCAI 的评审历来都很严格,今年投稿数量更是达到了 3470 篇,接收论文 710 篇,接收率只有 20.5%(同比 2017 年, 2540 篇投稿,接收 660 篇,约26%的接收率);而来自国内的论文更是近达半数之多,可见国内研究的活跃。与往年不同,今年 IJCAI 没有评选出 Best Paper,但是选出了 7 篇 Distinguished Paper ,其中有 4 篇都是来自国内的研究成果。
本文为大家采访到了本次 IJCAI 大会 Distinguished Paper 《Commonsense Knowledge Aware Conversation Generation with Graph Attention》(具有图注意力的常识知识感知会话生成系统)的第一作者——来自清华大学的博士研究生周昊,和大家分享其中更多的故事。
其实在去年,周昊和所在的课题组就有一项研究成果——Emotional Chatting Machine(情绪聊天机)获得了国内外的高度关注,MIT 科技评论、卫报和 NIVIDIA 就相继进行了追踪和报道。

来源于 MIT Technology Review

此节选部分内容来源于 MIT Technology Review
计算机无法衡量对话内容的情感,对话人的情绪,也就无法和人进行共情。而一个没有情商的聊天机器人反而会成为一个话题终结者。周昊和他所在的课题组就开发了一个能够评估对话内容情感并作出相应回应的聊天机器人,这项工作打开了通往具有情感意识的新一代聊天机器人的大门。

他们在研究中所提出的情绪聊天机(ECM),不仅可以在内容上给出适当的反应,而且能在情感上给出适当的反应(情绪一致)。这项工作已经在 TensorFlow 中实现,我们在文末附上了关于这项研究工作的论文和 GitHub 访问链接。
IJCAI 会议回来后,我们约到了周昊,请他谈了谈这次获奖的一些感悟、研究成果和心得,在此分享给各位读者们。
以下在对话内容上做了不改变原意的整理。
Q:今年国内在 ICJAI 会议上的成果很多,是什么时候收到通知被评为 Distinguished Paper的?还记得当时是什么心情吗?
周昊:我是在开幕式的时候才知道被评为Distinguished Paper 的,之前没有收到任何通知,当时就觉得比较幸运吧,论文能被评审认可。
Q:现在 NLP 领域中还有很多有待突破的问题,大家也都很想知道关于更有价值的研究方向?你觉得未来新的研究方向会有什么?
周昊:在会议上听了LeCun的演讲《 Learning World Models: the Next Step Towards AI》,感觉World Models或者Commonsense Knowledge在机器学习中的应用可能会成为新的研究方向。
Q:你在这次的研究工作中也是引入了 Commonsense Knowledge (常识知识),从提出到实现的这个研究过程,遇到过什么问题吗?可以和大家分享一下吗?
周昊:当时最早开始想做知识驱动的对话生成模型,是因为对话或者语言其实是一种知识交流的媒介,而现有的从大规模语料中学习的生成式对话模型尽管能学习到不错的语法知识,但是对语言背后本质的知识却缺少建模能力。所以我们设计了这个引入常识知识的对话模型想利用知识驱动对话生成。
我们当时的想法是利用知识推理的一种方式,可以从用户问题的知识子图出发,选择一度邻域的子图中概率最大的实体作为下一个关键节点,继续拓展其一度邻域的子图选择概率最大的实体,这样一步步推理下去会得到一个推理路径,作为我们对话生成的知识信息,这也是我们人类进行知识推理的方式。
然而在实际工作中,我们发现无论是常识知识图还是对话语料中都存在许多噪声,并且数据稀疏性也是个大问题。所以我们最后选择了一度邻域子图进行数据集的过滤与创建。感兴趣的同学可以继续探索知识推理在对话中的应用。
Q:能用一句话来介绍一下图注意力机制吗?其本质是什么?
周昊:图注意力机制是一种层次化的概率模型,通过不同层次知识图的概率计算,可以提取知识图中不同层次的知识,同时生成知识的推理路径。
Q:知识图会成为 NLP 的未来吗?
周昊:知识在NLP中已经有了很多应用,未来应用会更广泛,至于是否会以知识图的方式加入进来取决于技术和模型的发展了。
Q:去年你的另外一篇论文关于 Emotional Chatting Machine 的研究也是获得了非常高的关注,MIT科技评论、卫报和NIVIDIA也进行了专门的报道,再到今年获得 Distinguished Paper,有什么研究经验可以让大家借鉴吗?
周昊:在研究方面,我比较喜欢发现一些新的问题。大致过程就像做产品一样,首先要明确需求(需求最好是重要且容易定义的),然后寻找资源构造数据(数据没有必要十分旁大,因为数据处理,模型训练会浪费很多时间,从小数据做起验证想法,一步步扩展也是不错的思路),接着是从需求出发设计模型(可以将人的先验知识如任务的定义、语言学的资源融入到模型中),最后就是对比实验(不同会议偏好的实验也不同,比如 AAAI、IJCAI 之类 AI 的会议比较偏向能够解释说明 motivation 的实验,ACL、EMNLP 之类 NLP 的会议比较偏向统计性指标、多组 baseline 对比以及 ablation test 等实验)。通过实验结果的反馈不断迭代修改整个流程,最后得到一个满意的结果。
Q:大家都非常关注也想更多了解关于清华大学 NLP 的研究,可以给我们的读者介绍一下清华 NLP 研究课题组吗?
周昊:清华大学进行 NLP 研究的课题组有很多,研究方向各不相同。我们组(指导老师:朱小燕、黄民烈)主要研究的是交互式人工智能,即通过对话、交互体现出来的智能行为,通常智能系统通过与用户或环境进行交互,并在交互中实现学习与建模。我们组的主要研究方向有深度学习、强化学习、问答系统、对话系统、情感理解、逻辑推理、语言生成等。其他如孙茂松老师组的诗词生成,刘洋老师组的机器翻译等等。如果有对 NLP 研究感兴趣的同学们欢迎来各个课题组交流。

很感谢今天周昊和我们聊了这么多关于 NLP 领域的研究,自己的研究心得还有关于清华 NLP 课题组的分享。最后我们在周昊的指导意见下对他的获奖论文进行了解读,希望可以给大家的研究与学习带来灵感,有所收获。
摘要
常识知识对于自然语言处理来说至关重要。在本文中,我们提出了一种新的开放域对话的生成模型,以此来展现大规模的常识知识库是如何提升语言理解与生成的。若输入一个问题,模型会从知识库中检索相关的知识图,然后基于静态图注意力机制对其进行编码,图注意力机制有助于提升语义信息,从而帮助系统更好地理解问题。接下来,在语句的生成过程中,模型会逐个读取检索到的知识图以及每个图中的知识三元组,并通过动态的图注意力机制来优化语句的生成。
我们首次尝试了在对话生成中使用大规模的常识知识库。此外,现有的模型都是将知识三元组分开使用的,而我们的模型将每个知识图作为完整的个体,从而获得结构更清晰,语义也更连贯的编码信息。实验显示,与当前的最高水平相比,我们提出的模型所生成的对话更为合理,信息量也更大。
简介
在许多自然语言处理工作中,尤其在处理常识知识和客观现象时,语义的理解显得尤为重要,毋庸置疑,它是一个成功的对话系统的关键要素,因为对话互动是一个基于“语义”的过程。 在开放域对话系统中,常识知识对于建立有效的互动是很重要的,这是因为社会共享的常识知识是大众乐于了解并在谈话中使用的信息。
最近,在对话生成方面有很多神经模型被提出。但这些模型往往给出比较笼统的回复,大多数情况下,无法生成合适且信息丰富的答案,因为若不对用户的输入信息、背景知识和对话内容进行深度理解,是很难从对话数据中获取语义交互信息的。当一个模型能够连接并充分利用大规模的常识知识库,它才能更好地理解对话内容,并给出更合理的回复。举个例子,假如模型要理解这样一对语句,“Don’t order drinks at the restaurant , ask for free water” 和“Not in Germany. Water cost more than beer. Bring your own water bottle”, 我们需要的常识知识可以包括(water,AtLocation,restaurant),(free, RelatedTo, cost) 等。
在此之前,有些研究已经在对话生成中引入了外部知识。这些模型所用到的知识是非结构化的文本或特定领域的知识三元组,但存在两个问题:
第一,它们高度依赖非结构化文本的质量,受限于小规模的、领域特定的知识库。
第二,它们通常将知识三元组分开使用,而不是将其作为每个图的完整个体。
因此,这类模型不能基于互相关联的实体和它们之间的关系来给出图的语义信息。
为解决这两个问题,我们提出了常识知识感知对话模型(Commonsense Knowledge Aware Conversational Model, CCM),以优化语言理解和开放域对话系统的对话生成。我们使用大规模的常识知识来帮助理解问题的背景信息,从而基于此类知识来优化生成的答案。该模型为每个提出的问题检索相应的知识图,然后基于这些图给出富有信息量又合适的回复,如图 1 所示。
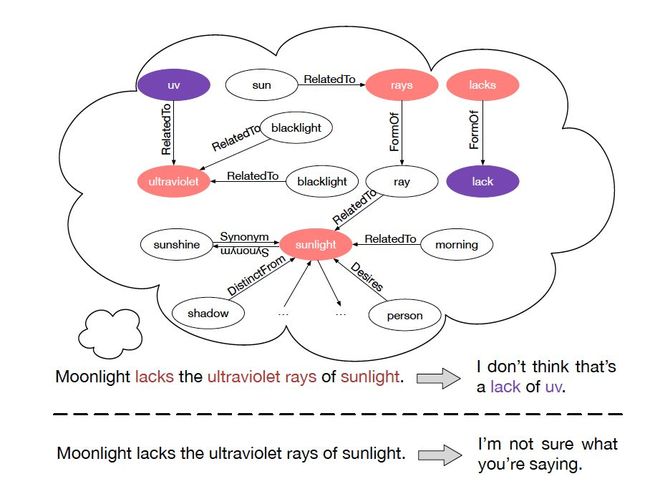
图 1:两种模型的对比
第一行回复由我们的模型(引入常识知识)生成
第二行回复由 Seq2Seq 模型(未引入常识知识)生成
为了优化图检索的过程,我们设计了两种新的图注意力机制。静态图注意力机制对检索到的图进行编码,来提升问题的语义,帮助系统充分理解问题。动态图注意机制会读取每个知识图及其中的三元组,然后利用图和三元组的语义信息来生成更合理的回复。
总地来说,本文主要做出了以下突破:
该项目是首次在对话生成神经系统中,尝试使用大规模常识知识。有了这些知识的支撑,我们的模型能够更好地理解对话,从而给出更合适、信息量更大的回复。
代替过去将知识三元组分开使用的方法,我们设计了静态和动态图注意力机制,把知识三元组看作一个图,基于与其相邻实体和它们之间的关系,我们可以更好地解读所研究实体的语义。
常识对话模型
2.1 背景:Encoder - Decoder 模型
首先,我们介绍一下基于 seq2seq 的 Encoder-Decoder 模型。编码器表示一个问题序列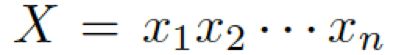 ,其隐藏层可表示为
,其隐藏层可表示为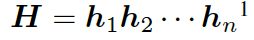 ,可以简单写作如下形式:
,可以简单写作如下形式:
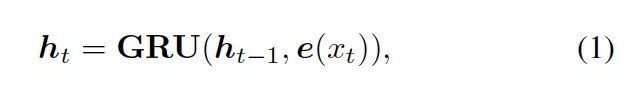
这里的![]() 是
是![]() 的词嵌入结果,GRU (Gated Recurrent Unit) 是门控循环单元。
的词嵌入结果,GRU (Gated Recurrent Unit) 是门控循环单元。
解码器将上下文向量![]() 和
和![]() 的词嵌入结果作为输入,同时使用另一个 GRU(门控循环单元)来更新其状态
的词嵌入结果作为输入,同时使用另一个 GRU(门控循环单元)来更新其状态![]() :
:
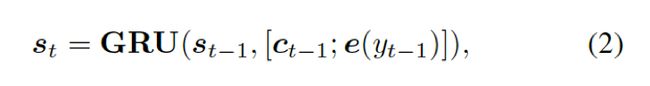
这里的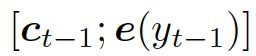 结合两个向量,共同作为 GRU 网络的输入。上下文向量
结合两个向量,共同作为 GRU 网络的输入。上下文向量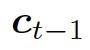 是 H 的词嵌入结果,也就是编码器隐藏状态的权重和:
是 H 的词嵌入结果,也就是编码器隐藏状态的权重和: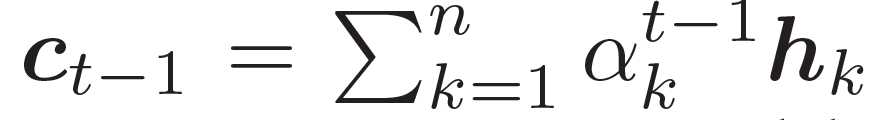 ,
,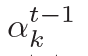 估量了状态
估量了状态![]() 和隐藏状态
和隐藏状态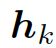 中间的相关度。
中间的相关度。
从输出的可能性分布中抽取样本,解码器会产生一个 token,可能性的计算如下:
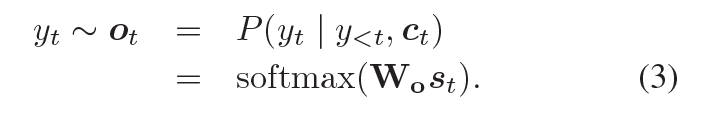
此处 ,这些词便生成了。
,这些词便生成了。
译者注:Seq2Seq 模型与经典模型有所不同的是,经典的 N vs N 循环神经网络要求序列要等长,但我们在做对话生成时,问题和回复长度往往不同。因此 Encoder-Decoder 结构通过 Encoder 将输入数据编码成一个上下文向量,再通过 Decoder 对这个上下文向量进行解码,这里的 Encoder 和 Decoder 都是 RNN 网络实现的。
2.2 任务定义与概述
我们的问题描述如下:给定一个问题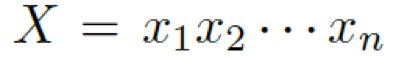 和一些常识知识的图
和一些常识知识的图 ![]() ,目标是生成合理的回复
,目标是生成合理的回复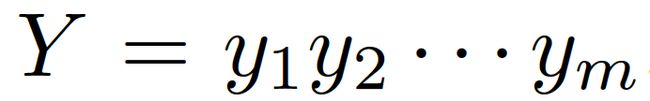 。本质上来看,该模型估计了概率:
。本质上来看,该模型估计了概率: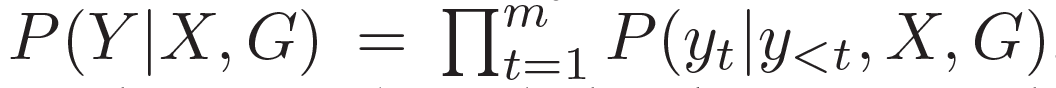 。基于问题从知识库中检索图,每个单词对应G中的一个图。每个图包含一个三元组的集合
。基于问题从知识库中检索图,每个单词对应G中的一个图。每个图包含一个三元组的集合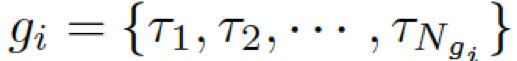 ,每个三元组(头实体、关系、尾实体)可表示为
,每个三元组(头实体、关系、尾实体)可表示为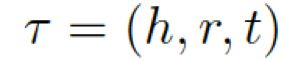 。
。
为了把知识库与非结构化的对话本文相关联,我们采用了 MLP 模型:一个知识三元组![]() 可以表示为 k= (h, r, t) = MLP(TransE(h,r, t)),这里的h / r / t 是经过 TransE 模型分别转化处理过的 h / r / t.
可以表示为 k= (h, r, t) = MLP(TransE(h,r, t)),这里的h / r / t 是经过 TransE 模型分别转化处理过的 h / r / t.
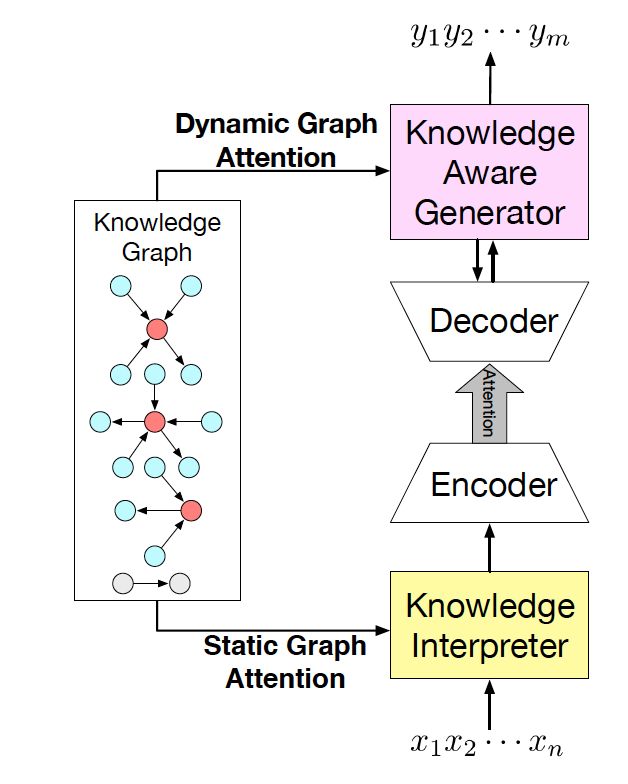
图 2:CCM 结构图
我们的常识对话模型(Commonsense Conversational Model, CCM)的概览如图 2 所示。知识解析器 (Knowledge Interpreter) 将问题和检索得到的知识图![]() 作为输入,通过把单词向量和与其对应的知识图向量相结合,来获得对每个单词的知识感知。
作为输入,通过把单词向量和与其对应的知识图向量相结合,来获得对每个单词的知识感知。
通过静态图注意力机制,知识图向量包含了问题 X中对应每个单词的知识图。基于我们的动态图注意力机制,知识感知生成器 (Knowledge Aware Generator) 生成了回复![]() 。在每个解码环节,它读取检索到的图和每个图中的实体,然后在词汇表中生成通用词汇,或在知识图中生成实体。
。在每个解码环节,它读取检索到的图和每个图中的实体,然后在词汇表中生成通用词汇,或在知识图中生成实体。
2.3 知识解析器

图 3:知识解析器把单词向量和图向量相结合。
在该例子中,单词 rays 对应第一个图,sunlight 对应第二个图。
每个图都用图向量表示。关键实体 (Key Entity) 表示当前问题中的实体。
知识解析器 (Knowledge Interpreter) 旨在优化问题理解这一环节。它通过引入每个单词对应的图向量,来增强单词的语义,如图 3 所示。知识解析器把问题中的每个单词 xt 作为关键实体,从整个常识知识库中检索图![]() (图中黄色部分)。每个检索到的图包含一个关键实体(图中红色圆点),与其相邻的实体(图中蓝色圆点)以及实体之间的关系。
(图中黄色部分)。每个检索到的图包含一个关键实体(图中红色圆点),与其相邻的实体(图中蓝色圆点)以及实体之间的关系。
对一些常用词汇(如:of)来说,常识知识图中没有与其匹配的图,这类词汇用一个带有特殊标志 Not_A_Fact(图中灰色圆点)的图来表示。
接下来,知识解析器会基于静态图注意力机制,来计算检索到的图的图向量![]() 。把单词向量
。把单词向量![]() 和知识图向量
和知识图向量![]() 相结合,就得到了向量
相结合,就得到了向量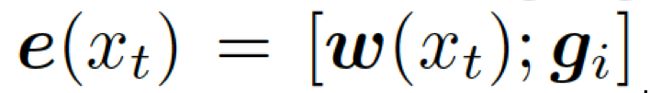 ,然后把它喂给编码器中的 GRU(门控循环单元,见图 1)。
,然后把它喂给编码器中的 GRU(门控循环单元,见图 1)。
2.4 静态图注意力
静态图注意力机制的设计旨在为检索到的知识图提供一个表现形式,我们设计的机制不仅考虑到图中的所有节点,也同时考虑节点之间的关系,因此编码的语义信息更加结构化。
静态图注意力机制会为每个图生成一个静态的表现形式,因而有助于加强问题中每个单词的语义。
形式上,静态图注意力把图中的知识三元组向量![]() 作为输入,来生成如下的图向量
作为输入,来生成如下的图向量![]() :
:
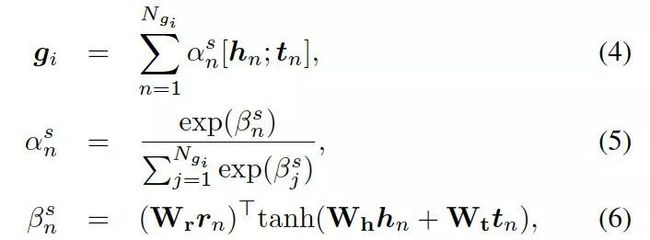
这里的![]() 分别是头实体、关系、尾实体的权重矩阵。注意力的权重估量了“实体间关系”
分别是头实体、关系、尾实体的权重矩阵。注意力的权重估量了“实体间关系”![]() 和“头实体”
和“头实体” 以及“尾实体”
以及“尾实体”![]() 之间的关联度。
之间的关联度。
本质上来说,图向量![]() 是每个三元组中头尾向量
是每个三元组中头尾向量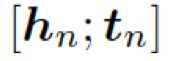 的权重和。
的权重和。
2.5 知识感知生成器
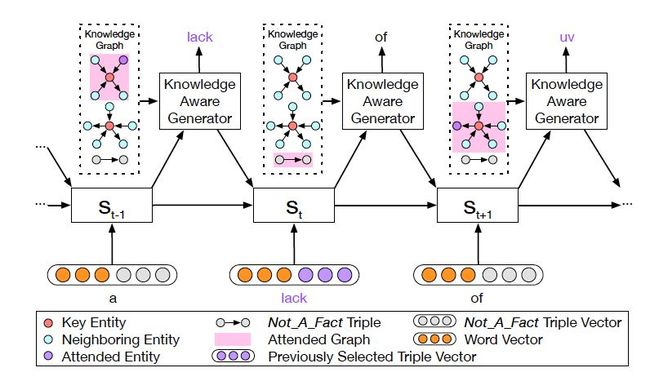
图 4: 知识感知生成器动态地处理着图
知识感知生成器 (Knowledge Aware Generator) 旨在通过充分利用检索到的图,来生成相应的回复,如图 4 所示。知识感知生成器扮演了两个角色:1) 读取所有检索到的图,来获取一个图感知上下文向量,并用这个向量来更新解码器的状态;2) 自适应地从检索到的图中,选择通用词汇或实体来生成词语。形式上来看,解码器通过如下过程来更新状态:
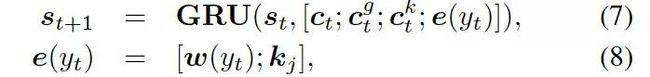
这里![]() 是单词向量
是单词向量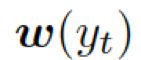 和前一个知识三元组向量
和前一个知识三元组向量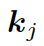 的结合,其来自上一个所选单词
的结合,其来自上一个所选单词![]() 。
。
![]() 是式 2 中的上下文向量,
是式 2 中的上下文向量,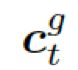 和
和![]() 分别是作用于知识图向量
分别是作用于知识图向量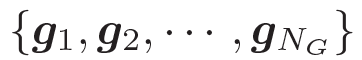 和知识三元组向量
和知识三元组向量 的上下文向量。
的上下文向量。
2.6 动态图注意力
动态图注意力机制是一个分层的、自上而下的过程。首先,它读取所有的知识图和每个图中的所有三元组,用来生成最终的回复。若给定一个解码器的状态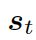 , 它首先作用于知识图向量,以计算使用每个图的概率,如下:
, 它首先作用于知识图向量,以计算使用每个图的概率,如下:
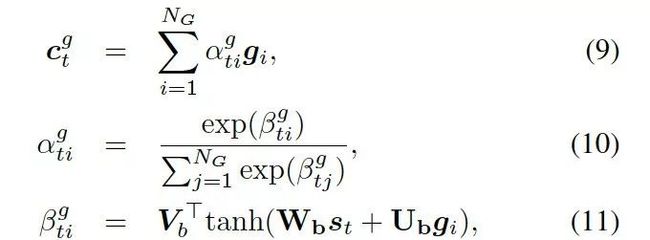
这里 都是参数,
都是参数, 是处于第 t 步时选择知识图
是处于第 t 步时选择知识图![]() 的概率。图的上下文向量
的概率。图的上下文向量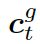 是图向量的权重和,这个权重估量了解码器的状态和图向量
是图向量的权重和,这个权重估量了解码器的状态和图向量![]() 之间的关联。
之间的关联。
接下来,该模型用每个图![]() 中的知识三元组向量
中的知识三元组向量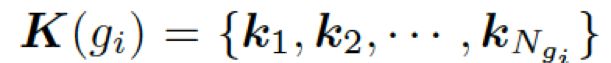 ,来计算选择某个三元组来生成答案的概率,过程如下:
,来计算选择某个三元组来生成答案的概率,过程如下:
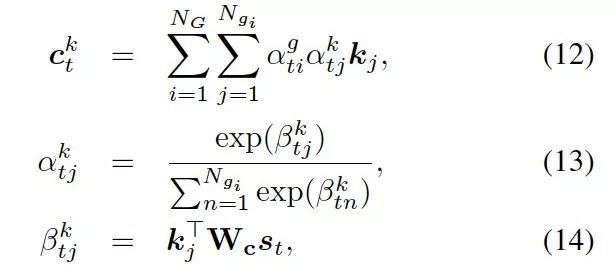
这里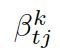 可被看作每个知识三元组向量
可被看作每个知识三元组向量![]() 和解码器状态
和解码器状态![]() 的相似度,
的相似度,![]()
是处于第 t 步时从图![]() 的所有三元组中选择
的所有三元组中选择![]() 的概率。
的概率。
最后,知识感知生成器选取通用词汇或实体词汇,基于如下概率分布:
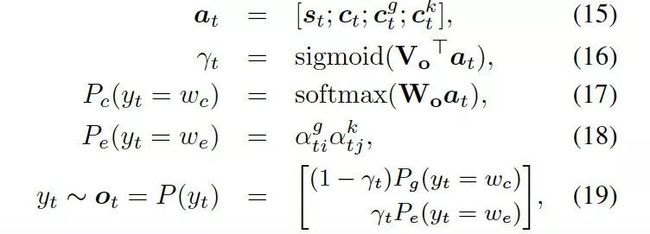
这里![]() 是用来平衡实体词汇
是用来平衡实体词汇![]() 和通用词汇
和通用词汇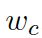 之间选择的标量,
之间选择的标量,![]() 分别是通用词汇和实体词汇的概率。最终的概率
分别是通用词汇和实体词汇的概率。最终的概率 由两种概率结合所得。
由两种概率结合所得。
译者注:在语言生成过程中,引入动态图注意力机制,模型可以通过当前解码器的状态,注意到最合适的知识图以及对应的知识三元组,再基于此来选择合适的常识与词汇来生成回复,从而使对话的信息量更大,内容更加连贯合理。与很多动态优化算法相类似,状态不断地更新与反馈,随之自适应地调整下一步决策,在对话生成系统中引入该机制有效地改善了生成结果。
实验
3.1 数据集
常识知识库
我们使用语义网络 (ConceptNet) 作为常识知识库。语义网络不仅包括客观事实,如“巴黎是法国的首都”这样确凿的信息,也包括未成文但大家都知道的常识,如“狗是一种宠物”。这一点对我们的实验很关键,因为在建立开放域对话系统过程中,能识别常见概念之间是否有未成文但真实存在的关联是必需的。
常识对话数据集
我们使用了来自 reddit 上一问一答形式的对话数据,数据集大小约为 10M。由于我们的目标是用常识知识优化语言理解和生成,所以我们滤出带有知识三元组的原始语料数据。若一对问答数据与任何三元组(即一个实体出现在问题中,另一个在答复中)都没有关联,那么这一对数据就会被剔除掉。具体数据概况可见表 1。
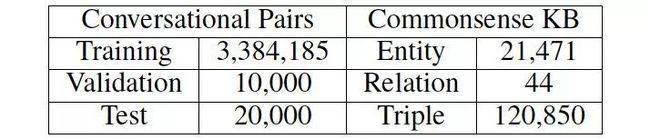
表 1: 数据集与知识库概况
3.2 实验细节
我们的模型是在 Tensorflow 下运行的。编码器与解码器均有两层 GRU 结构,每层有 512 个隐藏单元,它们之间不会共享参数。词嵌入时的长度设置为 300。词汇表大小限制在 30000。
我们采用了 Adam 优化器,学习率设置为 0.0001。具体代码已共享在 github上,文末附有地址。
3.3 对比模型
我们选取了几种合适的模型作为标准来进行对比:
Seq2Seq:一种 seq2seq 模型,它被广泛应用于各种开放域对话系统中。
MemNet:一个基于知识的模型,其中记忆单元用来存储知识三元组经 TransE 嵌入处理后的数据。
CopyNet:一种拷贝网络模型,它会从知识三元组中拷贝单词或由词汇表生成单词。
3.4 自动评估
指标
我们采用复杂度 (perplexity)来评估模型生成的内容。我们也计算了每条回复中的实体个数,来估量模型从常识知识库中挑选概念的能力,这项指标记为 entity score.
结果
如表 2 所示,CCM 获得了最低的复杂度,说明 CCM 可以更好地理解用户的问题,从而给出语义上更合理的回复。而且与其他模型相比,在对话生成中,CCM 从常识知识中选取的实体最多,这也可以说明常识知识可以在真正意义上优化回复的生成。
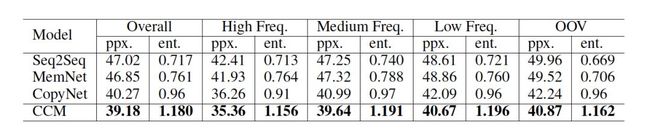
表 2: 基于 perplexity 和 entity score 的模型自动评估
3.5 人工评估
我们借助于众包服务 Amazon Mechanical Turk,从人工标记过的数据中随机采集 400 条数据。我们基于此来将 CCM 和另外几个模型对同一问题生成的回复进行对比。我们有三个对比模型,总计 1200 个问答数据对。
指标
我们定义了两项指标:appropriateness 在内容质量上进行评估(基于语法、主题和逻辑);informativeness 在知识层面进行评估(基于生成的答复是否针对问题提供了新的信息和知识)。
结果
如表 3 所示,CCM 在两项指标下都比另外几个模型表现更为突出。其中 CopyNet 是将知识三元组分开单独使用的,这也证明了图注意力机制的有效性。
很明显,在 OOV (out-of-vocabulary) 数据集的表现上, CCM 比 Seq2Seq 突出得多。这也进一步说明常识知识在理解生僻概念上很有效,而 Seq2Seq 并没有这个能力。对于 MemNet 和 CopyNet,我们未发现在这一点上的差别,是因为这两个模型都或多或少引入使用了常识知识。

表 3: 基于 appropriateness (app.) 和 informativeness (inf.) 的人工评估
3.6 案例研究
如表 4 所示,这是一个对话示例。问题中的红色单词 "breakable" 是知识库里的一个单词实体,同时对于所有模型来说,也是一个词汇表以外的单词。由于没有使用常识知识,且 "breakable" 是词汇表之外的单词,所以 Seq2Seq 模型无法理解问题,从而给出含有 OOV 的回复。MemNet 因为读取了记忆中嵌入的三元组,可以生成若干有意义的词汇,但输出中仍包含 OOV。CopyNet 可以从知识三元组中读取和复制词汇。
然而,CopyNet 生成的实体单词个数比我们的少(如表 2 所示),这是因为 CopyNet 将知识三元组分开使用了。相比之下,CCM 将知识图作为一个整体,通过相连的实体和它们之间的关系,与信息关联起来,使解码更加结构化。通过这个简单的例子,可以证明相比于其他几个模型,CCM 可以生成更为合理、信息也更丰富的回复。

表 4: 对于同一问题,所有模型生成的回复
总结和未来的工作
在本文中,我们提出了一个常识知识感知对话模型 (CCM),演示了常识知识有助于开放域对话系统中语言的理解与生成。自动评估与人工评估皆证明了,与当前最先进的模型相比,CCM 能够生成更合理、信息量更丰富的回复。图注意力机制的表现,鼓舞了我们在未来的其他项目中也将使用常识知识。
最后非常感谢周昊这次给我们的读者带来的精心分享!也希望在今后研究与工作的道路上,周昊同学都可以一帆风顺!也希望今后有机会和我们大本营的读者分享更多的研究心得与技术干货!如果大家对周昊的研究工作或 NLP 研究领域有任何想交流的问题、想法或建议,都可以在下方给我们留言,一起交流学习!
关于论文《Commonsense Knowledge Aware Conversation Generation with Graph Attention》
论文链接:
http://coai.cs.tsinghua.edu.cn/hml/media/files/2018_commonsense_ZhouHao_3_TYVQ7Iq.pdf
GitHub地址:
https://github.com/tuxchow/ccm
关于论文《Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory》
论文链接:
http://coai.cs.tsinghua.edu.cn/hml/media/files/aaai2018-ecm.pdf
GitHub 地址:
https://github.com/tuxchow/ecm

