利用MessagePassing实现GAT(了解pyG的底层逻辑)
利用MessagePassing实现GAT,感觉还挺麻烦的。当然geometric实现的GAT比我实现的这个更难。
GAT的计算公式依照官方文件
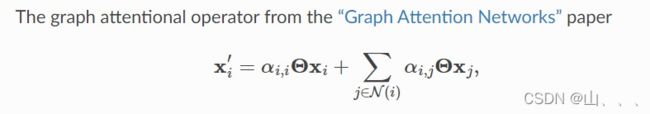


第一个函数 __init__
GAT需要的参数更多,本次实现GAT采用了多头注意力机制,heads表示多头数目,negative_slope表示LeakyReLU的负斜率。
lin_l和lin_r表示:

att_l 和att_r 表示:
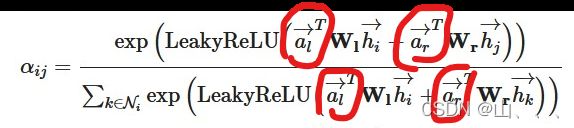
class GAT(MessagePassing):
def __init__(self, in_channels, out_channels, heads = 2,
negative_slope = 0.2, dropout = 0., **kwargs):
super(GAT, self).__init__(node_dim=0, **kwargs)
self.in_channels = in_channels
self.out_channels = out_channels
self.heads = heads
self.negative_slope = negative_slope
self.dropout = dropout
self.lin_l = torch.nn.Linear(in_channels,heads*out_channels)
self.lin_r = self.lin_l
# 两个线性层 分别用来对自己和邻居节点进行处理
# 意思是,自己和邻居节点用的同一个线性层处理
# Use nn.Parameter instead of nn.Linear
self.att_l = Parameter(torch.Tensor(1, heads, out_channels)) #a_l
self.att_r = Parameter(torch.Tensor(1, heads, out_channels)) #a_r
# 这两个是求注意力时的线性变换层 一个是给自己的,一个是给邻居的
self.reset_parameters()第二个函数reset_parameters(self)略过。
第三函数forward(self, x, edge_index, size = None)。
首先需要增加自环——这个地方与后面aggregate函数相关。他在edge_index中增加了自环。因为每次聚集信息时,不仅仅会聚集邻居的信息还会聚集自己的信息,加入自环后,自己就相当于自己的邻居。因此在聚集邻居的操作时,就一同聚集了自己的信息! 并且增加自环后,在后面计算注意力时,也会计算
x_l 和x_r分别表示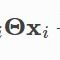 和
和
alpha_l和 alpha_r分别表示 和
和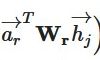
然后调用propagate函数,propagate会调用很多隐式函数然后调用message函数和aggregate函数。propagate函数返回的out值,就是aggregate函数返回的out值,代表最后的结果
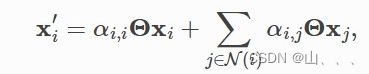
但是因为是多头注意力,所以需要对多头结果取平均。
def reset_parameters(self):
nn.init.xavier_uniform_(self.lin_l.weight)
nn.init.xavier_uniform_(self.lin_r.weight)
nn.init.xavier_uniform_(self.att_l)
nn.init.xavier_uniform_(self.att_r)
def forward(self, x, edge_index, size = None):
H, C = self.heads, self.out_channels
# Add self-loops to the adjacency matrix.
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# 根据公式推导需要增加自环 在后面aggregate里面就可以直接得到
#线性转换
x_l=self.lin_l(x) #W_l*h_i [N,H*C]
#
x_r=self.lin_r(x) #W_r*h_j
# 改变shape,这样就和att shape一致
x_l=x_l.view(-1,H,C) #[N,H,C]
x_r=x_r.view(-1,H,C)
alpha_l = (x_l * self.att_l).sum(axis=-1) #[N,H] 点乘(对应位置元素相乘
alpha_r = (x_r * self.att_r).sum(axis=-1) # [N,H] 点乘(对应位置元素相乘
out = self.propagate(edge_index, x=(x_l, x_r), alpha=(alpha_l, alpha_r),size=size) #[N,H,C]
# [N,H,C]
out = out.mean(dim=1) #[N,C]
return out
第四个函数message函数。
首先需要注意的是:message函数的输入参数与propagate函数的输入参数不是一一对应的!在得到propagate函数的参数数据后,它还做了很多隐藏变换!
这里的alpha_l, alpha_r 与alpha_i , alpha_j 并不是同一个东西
按照我的理解,此处的alpha_i , alpha_j应该是——它的值是从alpha_l, alpha_r来的,用这个值去替换edge_index里面数据!
这里的softmax是PyG而非torch的内置函数,此处的softmax计算方式其实与aggregate里面的scatter函数的计算方式相似,是scatter与普通softmax的结合版本。
def message(self, x_j, alpha_j, alpha_i, index, ptr, size_i):
#alpha:[E,H]
#x:[N,H,C]
#index 应该是edge_index 第一行
#步骤:
#在message而非aggregate函数中应用attention
#attention coefficient=LeakyReLU(alpha_i+alpha_j)
#attention weight=softmax(attention coefficient)(就这两步都是alpha,就在代码里没区分e和alpha)
#embeddings * attention weights
alpha = alpha_i + alpha_j # [E,H]
# 这个地方应该是有其他函数被调用了,
#alpha_l, alpha_r 与alpha_i , alpha_j 并不是同一个东西
alpha = F.leaky_relu(alpha,self.negative_slope)
alpha = softmax(alpha, index, ptr, size_i)
#这个softmax是PyG而非torch的内置函数
#但是反正参数是这些参数
#可参考:
#https://pytorch-geometric.readthedocs.io/en/latest/modules/utils.html#torch-geometric-utils
#https://github.com/rusty1s/pytorch_geometric/blob/master/torch_geometric/utils/softmax.py
alpha = F.dropout(alpha, p=self.dropout, training=self.training).unsqueeze(-1) #[E,H,1]
out = x_j * alpha #[E,H,C] 对应位置相乘 并且广播
return out
第五个函数,aggregate
这部分与其他模型没有区别!!
这个inputs就是message函数的输出,index应该就是edge_index中的第一行! 这个scatter函数就完成了,对于节点i的邻居信息求和的操作——当index相同时,其实就是中心节点相同时,对于inputs做求和操作,也就是对邻居信息求和!
### message的输出是 aggregate的输入
def aggregate(self, inputs, index, dim_size = None):
out = scatter(inputs, index, dim=self.node_dim, dim_size=dim_size, reduce='sum')
return out
附:


我觉得非常非常重要的就是:对于edge_index的理解,一般第一行会当作index,第二行就当作信息,这个信息会随着传入的信息变化!! 也可以理解为,edge_index表示信息的位置,传入propagate的参数才是信息的值!