2021 年最新版 CentOS 7 配置 Caffe 深度学习环境
前言
本文写于 2021 年 7 月 4 日。若按本文的方法配置出现了错误,请留意是否距离写作时间过远。
请确保你的电脑显卡是 NVIDIA 显卡。本文不适用于 AMD 显卡和 Intel 集成显卡。
一、准备工作:安装 EPEL 源和 ELRepo 源
CentOS 7 官方源的软件包数量过少,很多依赖项需要借助第三方源才能安装。这里 ELRepo 源用于安装 NVIDIA 显卡驱动,EPEL 源用于安装 Caffe 框架所必需的依赖项。
# 安装 EPEL 源
sudo yum install -y epel-release
# 安装 ELRepo 源
sudo rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
sudo yum install https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
# 将系统内的软件更新到最新版本
sudo yum update -y
# 清除旧内核,只保留最新的内核,然后重新启动
# 注意这里的 count=1 选项,表示只保留最新的内核,旧的内核一个都不备份
# 这样做有风险,可以考虑改为 count=2。这样当新内核无法使用时,可以无损回滚到旧内核
sudo package-cleanup --oldkernels --count=1
reboot二、安装 NVIDIA 显卡驱动
这里使用 yum 命令安装软件仓库里的 NVIDIA 驱动。这种方法不但简单,而且安装上的驱动也很稳定,不会导致系统崩溃。
首先安装显卡检测程序,检查自己需要装什么版本的 NVIDIA 驱动。
# 安装检测程序
sudo yum install nvidia-detect
# 安装完毕后,执行检测程序
nvidia-detect -v注意看输出的内容,告知你应该装的是哪个版本的驱动。
我的机子上显示的是 This device requires the current 460.84 NVIDIA driver kmod-nvidia,所以可以直接装最新的 460.84 版本的驱动。如果被告知只能装 390.xx、340.xx 或 304.xx 版本的 legacy 驱动,则要注意别安装错。
# 大多数显卡可以直接安装最新版本的驱动
sudo yum install nvidia-x11-drv
# 如果显卡检测程序告知你只能装 390.xx 版本的驱动,则执行下面这行命令
sudo yum install nvidia-x11-drv-390xx
# 如果显卡检测程序告知你只能装 340.xx 版本的驱动,则执行下面这行命令
sudo yum install nvidia-x11-drv-340xx
# 如果显卡检测程序告知你只能装 304.xx 版本的驱动,则执行下面这行命令
sudo yum install nvidia-x11-drv-304xx安装完毕后,输入 reboot 重启计算机。重启后,输入 nvidia-smi 命令,检查 NVIDIA 驱动和 CUDA 驱动是否被正确安装。如果有类似下面这样的输出,则说明安装成功。
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.84 Driver Version: 460.84 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce GT 720 Off | 00000000:01:00.0 N/A | N/A |
| 40% 41C P0 N/A / N/A | 146MiB / 974MiB | N/A Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+三、安装 CUDA 工具包
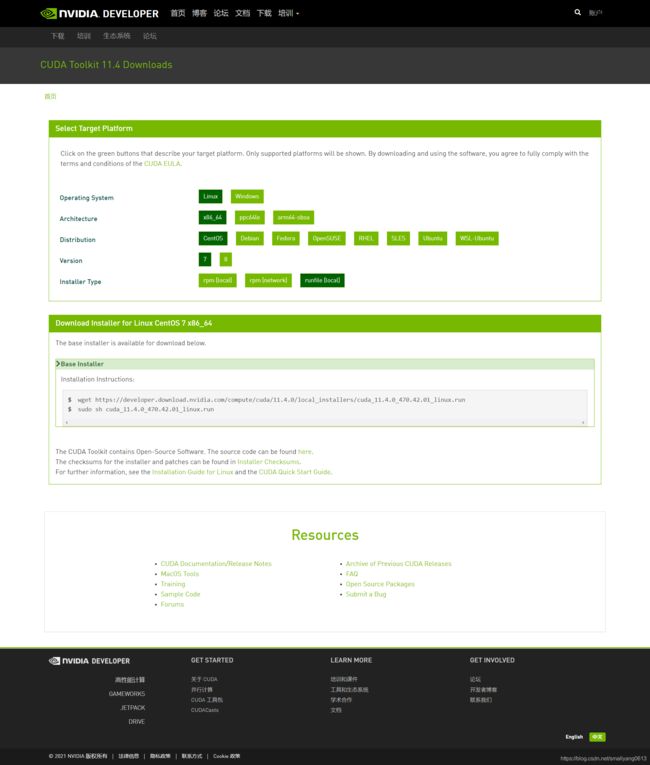
用浏览器打开 NVIDIA 开发者官网 NVIDIA 开发者 | NVIDIA Developer,点击网页最下方【常用 SDK】里的【CUDA 开发工具包/SDK】,进入 CUDA 专区。点击【立即下载】后,按下述顺序配置下载选项:
Operating System: Linux
Architecture: x86_64
Distribution: CentOS
Version: 7
Installer Type: runfile (local)
此时网页显示如下图所示:
我们按照网页上的指示,在终端里键入下述命令,下载 CUDA 工具包:
# 切换到用户目录
cd ~
# 下载 CUDA 工具包的安装程序
wget https://developer.download.nvidia.com/compute/cuda\
/11.4.0/local_installers/cuda_11.4.0_470.42.01_linux.run
# 运行安装程序
sudo sh cuda_11.4.0_470.42.01_linux.run
# 如果上述命令报错说 /tmp 目录空间不足
# 则需要在一个至少有 5GB 空间的分区里创建 CUDA 安装程序的临时目录
# 假设创建在自己的用户目录下 (~/cuda_temp)
rm -rf /tmp/*
mkdir cuda_temp
sudo sh cuda_11.4.0_470.42.01_linux.run --tmpdir=~/cuda_temp进入安装程序以后,首先输入 accept 同意协议,然后进入选择要安装的组件的部分。这里安装程序默认会安装 CUDA 驱动,但因为 CUDA 驱动我们已经在第二步安装 NVIDIA 驱动时同步安装过了,所以不需要再安装一遍。
将光标定位到 CUDA Driver 处,然后按 Enter,取消其勾选,然后再将光标移动到最下方,输入 i 开始安装。
安装完毕后,根据安装程序的指示配置环境变量。
需要在 PATH 变量里追加 /usr/local/cuda-11.4/bin 目录。
需要在 LD_LIBRARY_PATH 变量里追加 /usr/local/cuda-11.4/lib64 目录。
# 用文本编辑器打开 /etc/profile 文件,用于编辑环境变量
sudo gedit /etc/profile
# 在文件的末尾,新增如下三行,然后保存
export PATH=/usr/local/cuda-11.4/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.4/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
# 回到终端,重启计算机,使得环境变量配置生效
reboot重启计算机后,我们来验证 CUDA 工具包是否安装成功。
# 切换到 CUDA Sample 目录
cd ~/NVIDIA_CUDA-11.4_Samples
# 将演示项目的源代码编译成可执行文件
make -j8
# 尝试运行演示项目
cd bin/x86_64/linux/release
./deviceQuery如果终端里有类似如下的输出,说明 CUDA 工具包安装成功。
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GT 720"
CUDA Driver Version / Runtime Version 11.2 / 11.4
CUDA Capability Major/Minor version number: 3.5
Total amount of global memory: 974 MBytes (1021575168 bytes)
(001) Multiprocessors, (192) CUDA Cores/MP: 192 CUDA Cores
GPU Max Clock rate: 797 MHz (0.80 GHz)
Memory Clock rate: 900 Mhz
Memory Bus Width: 64-bit
L2 Cache Size: 524288 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.2, CUDA Runtime Version = 11.4, NumDevs = 1
Result = PASS四、安装 Caffe 框架必需的第三方库
根据 Caffe 官网 Caffe | Deep Learning Framework (berkeleyvision.org) 的指示,执行如下命令安装依赖:
# 如果没有执行第一步里的安装 epel 源的步骤,那么此处会有部分依赖项无法安装
# 请确保执行下述代码之前已成功安装 epel 源
# 常规依赖
sudo yum install -y protobuf-devel leveldb-devel snappy-devel
sudo yum install -y opencv-devel boost-devel hdf5-devel
sudo yum install -y gflags-devel glog-devel lmdb-devel
# BLAS (线性代数库) 依赖
sudo yum install -y atlas-devel openblas-devel
# 注:以上依赖项可以写在一条命令里,不必分开写
# 这里分开写只是为了提高阅读体验五、安装 Caffe 框架
首先从 GitHub 下载 Caffe 稳定版的源码:
# 切换到用户目录
cd ~
# 从 GitHub 下载 Caffe 1.0 的源码
wget https://github.com/BVLC/caffe/archive/refs/tags/1.0.zip
# 解压缩
unzip 1.0.zip此时你的用户目录下会多出一个叫 caffe-1.0 的目录。这就是我们的 Caffe 框架所在目录。
在安装 Caffe 框架之前,我们需要做一些配置。1.0 版本的框架是 2017 年发布的,距离现在已有四年,其所依赖的各种第三方库的代码架构也产生了较大的改变。原先的默认配置文件已无法正确编译并安装 Caffe 框架,我们需要对配置文件做较大的改动。
# 进入 Caffe 框架目录
cd caffe-1.0
# 重命名 example 后缀的配置文件
mv Makefile.config.example Makefile.config
# 打开配置文件进行编辑
gedit Makefile.config我们需要对配置文件做如下几处改动:
- 让编译器按 C++11 标准来编译。2017 年时,Caffe 框架用到的第三方库都没有使用 C++11 标准,但现在有部分框架开始使用这个标准了。若不明确指定 C++11 标准,编译时会报错,要求强制指定该标准。
# CUSTOM_CXX := g++ # 找到上面这一行,在下面添加如下配置 CXXFLAGS += -std=c++11 LINKFLAGS += -std=c++11 NVCCFLAGS += -std=c++11 - CUDA 架构部分,只保留 3.5 以上的算力。CUDA 11.4 版本不再支持低于 3.5 的算力。保留低算力会导致编译时报出找不到低算力 API 的错误。
# 原始配置: # CUDA_ARCH := -gencode arch=compute_20,code=sm_20 \ # -gencode arch=compute_20,code=sm_21 \ # -gencode arch=compute_30,code=sm_30 \ # -gencode arch=compute_35,code=sm_35 \ # -gencode arch=compute_50,code=sm_50 \ # -gencode arch=compute_52,code=sm_52 \ # -gencode arch=compute_60,code=sm_60 \ # -gencode arch=compute_61,code=sm_61 \ # -gencode arch=compute_61,code=compute_61 # # 去掉前三行 20、21、30,变为下面的样子 CUDA_ARCH := -gencode arch=compute_35,code=sm_35 \ -gencode arch=compute_50,code=sm_50 \ -gencode arch=compute_52,code=sm_52 \ -gencode arch=compute_60,code=sm_60 \ -gencode arch=compute_61,code=sm_61 \ -gencode arch=compute_61,code=compute_61 - 线性代数库部分,默认使用的是是 ATLAS,我们需要将其改为 OpenBLAS。在 CentOS 7 里,保持 ATLAS 会报出找不到 -lcblas 和 -latlas 的错误。查询 /usr/lib64 目录可以发现,和 ATLAS 相关的库名是 libsatlas.so 和 libtatlas.so,atlas 前面多了一个 s 和 t,所以会找不到 libatlas.so 这个库。
# BLAS := atlas # 找到上面这一行,将 atlas 改为 open BLAS := open
完成以上配置后,我们保存该配置文件,然后在终端里完成如下一键三连,中途若无任何报错信息出现,则 Caffe 框架安装成功!
make all -j8 && make test -j8 && make runtest -j8六、用 Caffe 训练 MNIST(手写体数字)数据集
MNIST 数据集是深度学习里非常常用的一个数据集,该数据集有包含 60000 张手写体数字图片的训练集,以及 10000 张手写体数字图片的测试集。其地位相当于各大编程语言的第一个程序 Hello World,以及图像处理领域的 Lena 图。配置 MNIST 训练集,并正确识别出手写体数字,是深度学习的入门课程。
深度学习,就是在大量的训练集图片里,自动寻找这些图片的共同特征,然后在测试的时候通过比对已经记住的各种特征,来推测每张测试图片最有可能的是训练时的哪类图片。
首先根据官网教程,获取 MNIST 数据集,并将原始数据转换成 Caffe 框架能识别的数据类型。
# 切换到 Caffe 目录
cd ~/caffe-1.0
# 获取 MNIST 数据集
./data/mnist/get_mnist.sh
# 转换成 Caffe 能识别的数据类型
./examples/mnist/create_mnist.sh执行完以上代码后,你会在 ~/caffe-1.0/examples/mnist 目录下看到两个新的文件夹:mnist_train_lmdb 和 mnist_test_lmdb。这就是我们将要给 Caffe 框架训练的数据集。
然后我们开始用 MNIST 训练集里的数据训练手写体图像识别模型。
# 切换到 Caffe 目录
cd ~/caffe-1.0
# 开始训练模型
./examples/mnist/train_lenet.sh训练的过程中,我们能看到终端里会不断输出训练的阶段性成果
I0704 22:35:39.620370 7089 solver.cpp:330] Iteration 0, Testing net (#0)
I0704 22:35:41.662818 7096 data_layer.cpp:73] Restarting data prefetching from start.
I0704 22:35:41.755663 7089 solver.cpp:397] Test net output #0: accuracy = 0.0688
I0704 22:35:41.755774 7089 solver.cpp:397] Test net output #1: loss = 2.33572 (* 1 = 2.33572 loss)
I0704 22:35:41.831012 7089 solver.cpp:218] Iteration 0 (-nan iter/s, 2.2116s/100 iters), loss = 2.2965
I0704 22:35:41.831136 7089 solver.cpp:237] Train net output #0: loss = 2.2965 (* 1 = 2.2965 loss)
I0704 22:35:41.831241 7089 sgd_solver.cpp:105] Iteration 0, lr = 0.01
I0704 22:35:46.380082 7089 solver.cpp:218] Iteration 100 (21.9824 iter/s, 4.54909s/100 iters), loss = 0.19359
I0704 22:35:46.380213 7089 solver.cpp:237] Train net output #0: loss = 0.19359 (* 1 = 0.19359 loss)
I0704 22:35:46.380260 7089 sgd_solver.cpp:105] Iteration 100, lr = 0.00992565
I0704 22:35:50.928442 7089 solver.cpp:218] Iteration 200 (21.9858 iter/s, 4.54839s/100 iters), loss = 0.167063
I0704 22:35:50.928577 7089 solver.cpp:237] Train net output #0: loss = 0.167063 (* 1 = 0.167063 loss)
I0704 22:35:50.928629 7089 sgd_solver.cpp:105] Iteration 200, lr = 0.00985258
I0704 22:35:55.473757 7089 solver.cpp:218] Iteration 300 (22.0006 iter/s, 4.54534s/100 iters), loss = 0.21728
I0704 22:35:55.473884 7089 solver.cpp:237] Train net output #0: loss = 0.21728 (* 1 = 0.21728 loss)
I0704 22:35:55.473948 7089 sgd_solver.cpp:105] Iteration 300, lr = 0.00978075
I0704 22:36:00.029469 7089 solver.cpp:218] Iteration 400 (21.9503 iter/s, 4.55574s/100 iters), loss = 0.091555
I0704 22:36:00.029603 7089 solver.cpp:237] Train net output #0: loss = 0.091555 (* 1 = 0.091555 loss)
I0704 22:36:00.029650 7089 sgd_solver.cpp:105] Iteration 400, lr = 0.00971013
I0704 22:36:04.519203 7089 solver.cpp:330] Iteration 500, Testing net (#0)
I0704 22:36:06.570842 7096 data_layer.cpp:73] Restarting data prefetching from start.
I0704 22:36:06.663012 7089 solver.cpp:397] Test net output #0: accuracy = 0.9719
I0704 22:36:06.663120 7089 solver.cpp:397] Test net output #1: loss = 0.0895511 (* 1 = 0.0895511 loss)可以看到,迭代 0 次(Iteration 0)时,测试的准确率(accuracy)低得可怜,只有 6%,总共 10 个数字,这个准确率已经和瞎蒙的期望准确率(10%)差不多了。
然而,迭代了 500 次(Iteration 500)后,测试准确率(accuracy)就提到了 97%。
迭代的过程中,通过观察终端的输出,我们不难发现,准确率或许偶尔会有上下波动,但整体趋势是在不断逼近 100% 的。
我们的这个示例训练程序最终会迭代 10000 次,最终的准确率能高达 99%。
训练完成后,你会在 ~/caffe-1.0/examples/mnist 文件夹下发现两个新文件:lenet_iter_5000.caffemodel 和 lenet_iter_10000.caffemodel。顾名思义,这两个文件分别是迭代了 5000 次和 10000 次的训练模型。
七、用自己的手写体数字图片检验训练成果
待续……