最陌生的老朋友Softmax Loss
今天给大家介绍的工作是大家最陌生的老朋友Softmax Loss。Softmax可以算是最为广泛使用的分类loss,在大家都在极力压榨网络结构来换取性能提升的时候,回过头来再去看看这个网络训练的“指挥棒”,能有很多新的发现。
其实在读到这一系列工作之前,我花很久考虑过一个问题,对于SVM来讲,margin的概念十分清晰易懂,那么对于Softmax而言,如果我们要引入Max Margin的概念,那么所谓的margin究竟是什么?实话讲,这个问题是我考虑很了很久,但是并没有清晰答案的一个问题,把这一系列的工作串起来后,这个困扰我很久的问题终于有了解答。
为了能对这一系列工作有更深刻的理解,我们需要从几何上来理解softmax loss究竟在做什么。为了方便表述,下文所指softmax loss均指softmax之前的全连接层+softmax loss function,即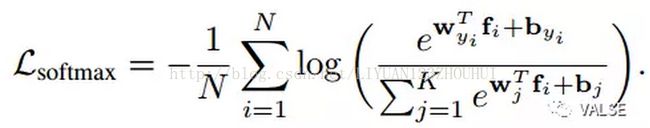
其中f_i为第i个sample的feature,y_i为其对应的label,w_{y_i}为y_i类对应的weight。为了方便后文推导,我们可以认为bias term b = 0。这里有一个关键的变换是,我们把inner product表示为:
这个简单的变换是后面这一系列工作的核心:我们可以看到这个inner product的大小,和三个元素相关:w的l2 norm,f的l2 norm,w和f这两个向量的夹角。如果我们对于类别没有特殊的假设,那么w的l2 norm可以认为是一致的。那么可以影响结果的就只有后两项了,后面介绍的一系列工作都是在这两项上进行改动。在开始之前,我们需要一个在二维的空间中直观的解释来帮助理解:
在这些图中,黄色和绿色的点分别代表两类样本,黑色的虚线代表decision boundary,黑色的实线代表两个class的weight。这些weight vector,把整个空间划分成了若干个锥形,每个锥形对应着一类样本的空间。如果假设每一类的weight的l2 norm是一致的,那么每个样本属于哪一类就只和这个样本在这些weight vector的方向上投影长度相关。
最左侧的图中,显示的是原始的softmax,可以看到,由于softmax并没有显式地加强margin,会导致训练样本可以分对,但是泛化性能并不好的情况。尤其是对于Deep Learning 模型而言,由于模型复杂度较高,大量的样本在训练后期正确类别的概率都会在0.99以上,这会导致大量的样本在训练后期回传的gradient非常小,从而不能更好地指导模型的训练。
所以为了拓展这个margin,根据前面的分析,主要有两个方向:第一个方向是限定f的l2 norm的情况下让不同类之间的角度维持一个margin,这个方向上代表的两个工作是[1, 2];第二个方向在第一个方向上更进一步,尽量让f的l2 norm变大[3]。这分别对应的是中间和右侧的示意图。在中间的图中,可以看到如果我们在投影的夹角上加入一个margin,可以让每一类的样本push向正确类别的weight方向(蓝色箭头),最终都集中在过原点的一个锥中,这样可以显著改善类间和类内距离;最右侧的图中,我们更进一步,我们不仅仅希望在这样的一个锥中,还希望样本的特征表示f尽量远离原点(红色箭头),在这样一个锥形的“底部”。下面分别介绍下这两类工作的formulation。
在第一类工作中,以[1]举例,我们希望得到一个更严格的formulation,对于合适的m,我们希望满足: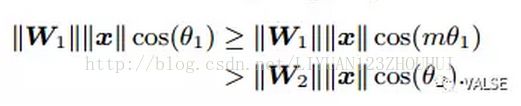
其对应的loss function为: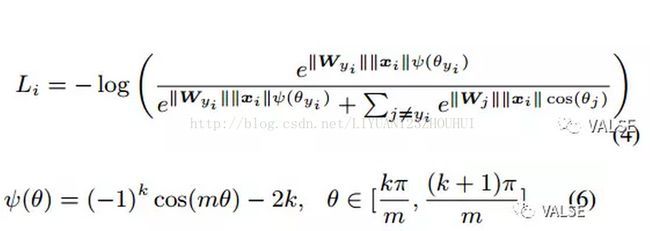
虽然看上去phi的定义比较复杂,原因在于cos函数并不是单调的,通过合适的phi定义是为了保障loss function是单调递减的。一个示例如下图:
整个BP的过程就不再赘述,是很标准的求导操作。实验中,作者使用mnist做了一个很直观的illustration,相信大家看了也会一目了然:
[2]在这个基础上,引入了对weight的normalization,提供了更好的理论分析,以及对open set样本性能的提升。
对于第二个方向,[3]给出了很好的探索。首先作者给出了理论证明,feature norm并不需要无限增长来保障泛化性能,所以在设计对应的regularization的时候,作者希望这个term的强度和feature norm的大小成反比。所以作者使用了下述的方式:
其中h(i)为一个indicator function指示第i个样本有没有分类正确。虽然可以理解作者引入这个indicator的目的是希望只有在分类正确的时候再讲feature的l2 norm加大以增强和其他类的margin,但是首先这个indicator会导致整个目标的不连续,不能区分刚好在margin上的样本和完全错误的样本。这里可能使用一个连续如tanh的近似可能更加合理。其次按照作者提供的motivation,对于分类正确的样本应当增加feature l2 norm,同样对于错误的样本应当减小其l2 norm,但是在这个设计上并没有体现出这一点。第三,这个indicator function并没有和w和f相关,这会导致这一项的gradient无法回传。所以个人觉得作者motivation很让人信服,但是在具体的regularization设计上,可能存在改进的空间。
值得一提的是,最近还有大量的文章[4, 5, 6, 7],提到了feature normalization和之后的scale对于性能的提升,也提供了很多理论分析的结果。这几个工作和前面介绍的工作十分相关,有兴趣的读者可以自行参考。但是需要注意这些工作中首先将feature normalize,然后再去scale到一个较大值的方式并不等价于直接增大f的l2 norm。原因在于这样scale并没有通过gradient回传给之前的feature extractor(即CNN)需要增大feature的l2 norm的信息,只是对于feature的“后处理”。这样虽然能够改善最终softmax分类器的性能,但并不能指导CNN学习到泛化能力更强的feature。
关于我们老朋友softmax的故事今天就给大家介绍到这里。除了各种花样翻新的网络结构,这些看似很熟悉的东西其实对于性能的提升也很显著,希望大家多拓宽思路,毕竟条条大路通罗马~
[1]Liu, Weiyang, Yandong Wen, Zhiding Yu, and Meng Yang. “Large-Margin Softmax Loss for Convolutional Neural Networks.” InProceedings of The 33rd International Conference on Machine Learning, pp. 507-516. 2016.
[2] Liu, Weiyang, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj, and Le Song. “SphereFace: Deep Hypersphere Embedding for Face Recognition.” arXiv preprint arXiv:1704.08063 (2017).
[3] Yuan, Yuhui, Yang Kuiyuan, Zhang Chao. “Feature Incay for Representation Regularization” arXiv preprint arXiv:1704.08063 (2017).
[4] Chunjie, Luo, and Yang Qiang. “Cosine Normalization: Using Cosine Similarity Instead of Dot Product in Neural Networks.” arXiv preprint arXiv:1702.05870 (2017).
[5] Ranjan, Rajeev, Carlos D. Castillo, and Rama Chellappa. “L2-constrained Softmax Loss for Discriminative Face Verification.” arXiv preprint arXiv:1703.09507 (2017).
[6] Wang, Feng, Xiang Xiang, Jian Cheng, and Alan L. Yuille. “NormFace: L2
Hypersphere Embedding for Face Verification.” arXiv preprint arXiv:1704.06369 (2017).
[7] Liu, Yu, Hongyang Li, and Xiaogang Wang. “Learning deep features via congenerous cosine loss for person recognition.” arXiv preprint arXiv:1702.06890 (2017).