pytorch 实现CIFAR-10多分类
基于数据集CIFAR-10,利用卷积神经网络进行分类。
1.CIFAR-10数据集
1.1概念
由10个类的6w个32x32彩色图像组成,每个类由6k个图像。5w个训练图,1W测试图。
分为5个训练批次,1个测试批次,每个批次有1w个图像。测试批次每个类恰好1k张随机图像。训练批次随机顺序包含剩余图像,总之,5个训练集之和包含每个类的5k张。
多分类单标签

1.2组成
data ——一个10000x3072个uint8s的numpy数组。数组的每一行存储一个32x32的彩色图像。前1024个条目包含红色通道值,下一个1024个条目为绿色,最后1024个条目为蓝色。图像按行的主要顺序存储,因此数组的前32个条目是图像第一行的红色通道值。
labels——范围为0-9的10000个数字的列表。索引i处的数字表示数组数据中第i个图像的标签。
该文件包含另一个称为数据集的文件批处理.meta. 它也包含一个Python字典对象。它包含以下条目:
label_names——一个10个元素的列表,为上面描述的labels数组中的数字标签提供有意义的名称。例如,label_names[0]=“飞机”,label_names[1]=“汽车”,等等。
2.代码
2.1数据记载、预处理和可视化
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import torch
import torchvision
import torchvision.transforms as transforms
#下载数据预处理
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
trainset=torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform )
trainloader=torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True,num_workers=2)
testset=torchvision.datasets.CIFAR10(root='./data',train=False,download=False,transform=transform )
testloader=torch.utils.data.DataLoader(testset,batch_size=4,shuffle=False)
classes=('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')#10个类
#可视化
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img=img/2+0.5
npimg=img.numpy()
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
#随机获取部分训练数据
dataiter=iter(testloader) #依次取出迭代器里的值。执行一次只能取到迭代器里的一个值
images,labels=dataiter.next()
#显示图像
imshow(torchvision.utils.make_grid(images))
print(''.join('%5s'% classes[labels[j]] for j in range(4) ))
~- 跟手写数字做比较,这次是彩色图片归一化,有三个通道transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
- DataLoader一次处理四张图像
- iter和enumerate功能类似,都可以当迭代器使用,区别是enumerate还返回编号
2.2构建网络
#构建网络
import torch.nn as nn
import torch.nn.functional as F
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet,self).__init__()
self.conv1=nn.Conv2d(in_channels=3,out_channels=16,kernel_size=5,stride=1)
self.pool1=nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=36, kernel_size=3, stride=1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1=nn.Linear(1296,128)
self.fc2=nn.Linear(128, 10)
def forward(self,x):
x=self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x=x.view(-1,36*6*6) #展开成全连接层
x=F.relu(self.fc2(F.relu(self.fc1(x))))
return x
net=CNNNet()
net=net.to(device)
#print(net) #显示网络定义了哪些层~结构
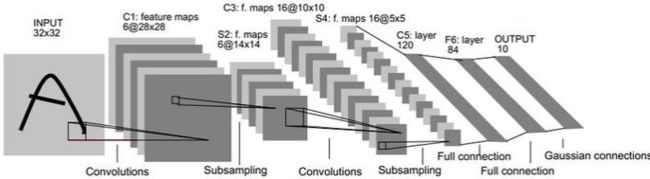
网络结构类似LeNet5,用了两层卷积层,两层池化层,两层全连接层,参数有些不同。
不过也用到了relu激活函数。
#查看网络中前几层
nn.Sequential(*list(net.children())[:4])
#初始化参数
for m in net.modules():
if isinstance(m,nn.Conv2d):
nn.init.normal_(m.weight)
nn.init.xavier_normal_(m.weight)
nn.init.kaiming_normal_(m.weight) # 卷积层参数初始化
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight) #全连接层参数初始化~2.3训练
#定义损失函数优化器
import torch.optim as optim
criterion=nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
if __name__ == '__main__':#训练模型
for epoch in range(10):
running_loss=0.0
for i,data in enumerate(trainloader,0):
inputs,labels=data
inputs,labels=inputs.to(device),labels.to(device)
#权重参数梯度清零
optimizer.zero_grad()
#正向传播反向传播
output=net(inputs)
loss=criterion(output,labels)
loss.backward()
optimizer.step()
#显示损失值
running_loss+=loss.item()
if i % 2000 == 1999: #2000mini-batch输出一次
print('[%d,%5d] loss:%.3f' %(epoch+1, i+1, running_loss/2000))
running_loss = 0.0
print('finish training')~跟手写数字的流程没什么区别,迭代10次,在一次迭代中每2000个图像 输出一次平均损失值。
2.4测试
这里只采用一次测试,计算准确率
目前的网络简单,没有做过多的优化,能够达到60%左右的准确率。
#一次测试
correct=0
total=0
with torch.no_grad():
for data in testloader:
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
output = net(inputs)
_,predicted=torch.max(output.data,1)
total+=labels.size(0)
correct+=(predicted==labels).sum().item()
print('accuracy:%d %%'%(100*correct/total))~各个类别准确率
class_correct=list(0.for i in range(10))#初始化list中每个元素是0.0,定义一个存储每类中测试正确的个数的列表
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
output = net(inputs)
_,predicted=torch.max(output,1) #返回元组,值和索引,弃掉值只要索引predicted
c=(predicted==labels).squeeze() #有四个值
for i in range(4): #一次输入四张图像
label=labels[i] # 对各个类的进行各自累加
class_correct[label]+=c[i].item()
class_total[label] +=1
for i in range(10):
print('accuracy of %5s:%2d %%'%(classes[i],100*class_correct[i]/class_total[i]))~