Deformable ConvNets v2 原理与代码解析
paper:Deformable ConvNets v2: More Deformable, Better Results
code:https://github.com/4uiiurz1/pytorch-deform-conv-v2
DCN v1的介绍参考 DCN v1 可变形卷积v1解析(修正篇)
DCN v1存在的问题
DCN v1根据输入特征学习到的偏移量,改变了卷积的采样位置,使得其具有更强的适应物体几何变化的能力。但是作者发现,虽然相比普通卷积,可变形卷积的采样位置更接近物体的真实结构,但有部分采样点超出了感兴趣区域,导致提取的特征受到无关图像内容的影响。
本文的创新点
- 堆叠更多可变形卷积层
- 引入了一种调制机制
- 提出了一种特征模拟方案来指导网络训练
将模型中更多的普通卷积替换成可变形卷积,进一步增强了整个网络对几何变换的建模能力。引入了调制机制,增加了一个自由度,对于每个偏移后的采样点用学习到的权重控制,比如对于超出感兴趣区域的采样点,学习到的权重可能非常小甚至为0,这就大大减小了无关特征的干扰。引入R-CNN特征模拟,可以帮助网络更关注目标的感兴趣区域,同时学习R-CNN特征的分类能力。
方法介绍
Stacking More Deformable Conv Layers
以ResNet-50为例,DCN v1只将conv5阶段的3x3卷积替换成了可变形卷积,因此整个网络中有3层可变形卷积。在DCV v2中,将conv3~conv5阶段所有的3x3卷积都替换成了可变形卷积,总共有12层可变形卷积,进一步增强了网络对几何变换的建模能力。
Modulated Deformable Modules
通过对可变形卷积引入调制机制,DCN不仅可以调整采样位置,还可以调制采样处的特征大小。极端情况下,modulated deformable module可将某个采样点的调制因子设置为0,从而不感知该位置处的信号,因此对应位置处的图像内容对模块的输出的影响大大减小甚至没有影响。
如下所示,其中 \(\bigtriangleup m_{k}\) 是新增的调制权重因子,其值位于[0, 1]内,和DCN v1中引入的学习到的偏差 \(\bigtriangleup p_{k}\) 一样,\(\bigtriangleup m_{k}\) 也是对输入进行一层单独额外的卷积得到的,并通过sigmoid将值控制到[0, 1]区间。
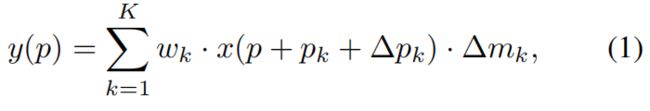
R-CNN Feature Mimicking
ROI之外的图像内容可能会影响所提取的特征,从而降低最终的检测精度。除了引入调制权重可以缓解这种影响,作者还提出了R-CNN特征模拟来指导网络训练的方法,因为R-CNN的输入是RPN模块从从图片中crop出的ROI区域,合并R-CNN学习到的特征有助于缓解冗余上下文的问题,提高检测精度。这个辅助监督目标可以驱使Deformable Faster R-CNN像R-CNN一样关注更重要的特征表示。完整的网络结构如下图所示

具体如下,左边是原始的Faster R-CNN分支,右边是新增的R-CNN辅助训练分支。对于Faster R-CNN中RPN输出的postive region proposals,随机采样32个得到集和 \(\Omega\),然后将这些ROI映射回原图得到对应区域,将原图上的这些区域crop出来并resize成224x224就得到辅助分支的输入。然后和Faster R-CNN中一样,经过backbone、modulated deformable ROIpooling,最终经过两层fc层得到了1024维的输出,然后和Faster R-CNN中两层全连接层的1024维输出计算feature mimic loss,损失函数定义为两者之间的余弦相似度,完整形式如下

此外,对于辅助分支,还额外进行了分类的监督,即1024维的输出经过softmax,并与gt计算交叉熵分类损失。因此完整的训练损失包括Faster R-CNN原本的分类和回归损失、新增的feature mimic损失、以及辅助分支的分类损失。
实验结果
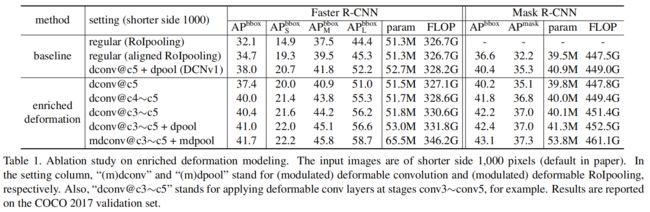
Enriched Deformation Modeling
从下表可以看出,随着将更多的普通卷积层替换为可变形卷积,添加可变形roi pooling,以及添加调制权重因子,模型的变形建模能力越来越强,精度也越来越高。
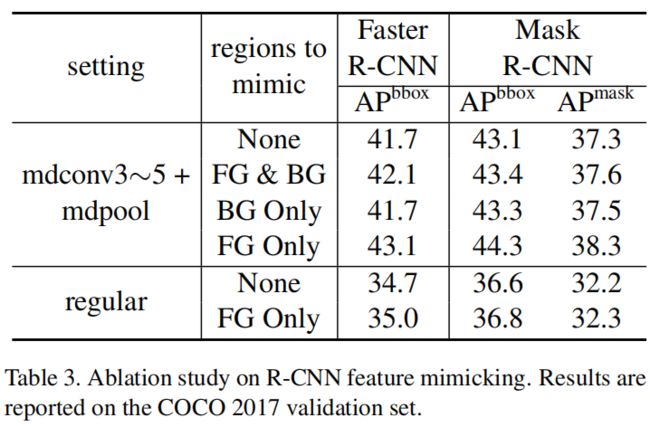
R-CNN Feature Mimicking
下表是将feature mimick用到前景、背景、以及普通卷积上,可以看出,当只mimick前景特征时,精度最高,这是因为对于背景,模型通常需要更多的上下文信息,这会导致feature mimick的作用不大。另一方面,当模型都是普通卷积时,feature mimick的提升也不大,这是因为相比于调制可变形卷积,普通卷积的表示能力有限,feature mimick超出了普通卷积将特征聚焦于前景的表示能力。
代码解析
下面是modulated deformable convolution的实现,其中参数modulation=True时就是DCN v2,modulation=False时就是DCN v1。其中self.m_conv就是对输入feature map进行单独的一层卷积来学习调制权重,对于大小为kernel_size的原始普通卷积,偏差self.p_conv的输出通道为2*kernel_size*kernel_size,即卷积核内每个采样点学习x,y两个方向的偏差,调制权重self.m_conv的输出通道为kernel_size*kernel_size,即每个采样点学习一个调制权重
import torch
from torch import nn
class DeformConv2d(nn.Module):
def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, bias=None, modulation=False):
"""
Args:
modulation (bool, optional): If True, Modulated Defomable Convolution (Deformable ConvNets v2).
"""
super(DeformConv2d, self).__init__()
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.zero_padding = nn.ZeroPad2d(padding)
self.conv = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias)
self.p_conv = nn.Conv2d(inc, 2*kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_backward_hook(self._set_lr)
self.modulation = modulation
if modulation:
self.m_conv = nn.Conv2d(inc, kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.m_conv.weight, 0)
self.m_conv.register_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x): # (1,64,5,5)
offset = self.p_conv(x) # (1, 18, 5, 5)
if self.modulation:
m = torch.sigmoid(self.m_conv(x)) # (1,9,5,5)
dtype = offset.data.type()
ks = self.kernel_size # 3
N = offset.size(1) // 2 # 9
if self.padding:
x = self.zero_padding(x) # (1, 64, 5, 5) -> (1, 64, 7, 7)
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# print(p.shape)
# print(p)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long() # (1,5,5,18)
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long() # (1,5,5,18)
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1) # (1,5,5,18)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1) # (1,5,5,18)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1) # (1,5,5,18)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# (b, c, h, w, N)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, c, h, w, N)
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
# modulation
if self.modulation:
m = m.contiguous().permute(0, 2, 3, 1) # (1,5,5,9)
m = m.unsqueeze(dim=1) # (1,1,5,5,9)
m = torch.cat([m for _ in range(x_offset.size(1))], dim=1) # (1,64,5,5,9)
x_offset *= m
x_offset = self._reshape_x_offset(x_offset, ks) # (b, c, h*ks, w*ks)
out = self.conv(x_offset)
return out
def _get_p_n(self, N, dtype):
p_n_x, p_n_y = torch.meshgrid(
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1))
# (2N, 1)
p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0)
p_n = p_n.view(1, 2*N, 1, 1).type(dtype)
return p_n
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(1, h*self.stride+1, self.stride),
torch.arange(1, w*self.stride+1, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1)//2, offset.size(2), offset.size(3) # 9,5,5
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype) # 3x3卷积内9个点相对中心点(0,0)的偏移坐标
# tensor([[[[-1.]],
#
# [[-1.]],
#
# [[-1.]],
#
# [[ 0.]],
#
# [[ 0.]],
#
# [[ 0.]],
#
# [[ 1.]],
#
# [[ 1.]],
#
# [[ 1.]],
#
# [[-1.]],
#
# [[ 0.]],
#
# [[ 1.]],
#
# [[-1.]],
#
# [[ 0.]],
#
# [[ 1.]],
#
# [[-1.]],
#
# [[ 0.]],
#
# [[ 1.]]]])
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype) # 输入特征图上的每个像素点的原始坐标
# tensor([[[[1., 1., 1., 1., 1.],
# [2., 2., 2., 2., 2.],
# [3., 3., 3., 3., 3.],
# [4., 4., 4., 4., 4.],
# [5., 5., 5., 5., 5.]],
#
# [[1., 1., 1., 1., 1.],
# [2., 2., 2., 2., 2.],
# [3., 3., 3., 3., 3.],
# [4., 4., 4., 4., 4.],
# [5., 5., 5., 5., 5.]],
#
# [[1., 1., 1., 1., 1.],
# [2., 2., 2., 2., 2.],
# [3., 3., 3., 3., 3.],
# [4., 4., 4., 4., 4.],
# [5., 5., 5., 5., 5.]],
#
# [[1., 1., 1., 1., 1.],
# [2., 2., 2., 2., 2.],
# [3., 3., 3., 3., 3.],
# [4., 4., 4., 4., 4.],
# [5., 5., 5., 5., 5.]],
#
# [[1., 1., 1., 1., 1.],
# [2., 2., 2., 2., 2.],
# [3., 3., 3., 3., 3.],
# [4., 4., 4., 4., 4.],
# [5., 5., 5., 5., 5.]],
#
# [[1., 1., 1., 1., 1.],
# [2., 2., 2., 2., 2.],
# [3., 3., 3., 3., 3.],
# [4., 4., 4., 4., 4.],
# [5., 5., 5., 5., 5.]],
#
# [[1., 1., 1., 1., 1.],
# [2., 2., 2., 2., 2.],
# [3., 3., 3., 3., 3.],
# [4., 4., 4., 4., 4.],
# [5., 5., 5., 5., 5.]],
#
# [[1., 1., 1., 1., 1.],
# [2., 2., 2., 2., 2.],
# [3., 3., 3., 3., 3.],
# [4., 4., 4., 4., 4.],
# [5., 5., 5., 5., 5.]],
#
# [[1., 1., 1., 1., 1.],
# [2., 2., 2., 2., 2.],
# [3., 3., 3., 3., 3.],
# [4., 4., 4., 4., 4.],
# [5., 5., 5., 5., 5.]],
#
# [[1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.]],
#
# [[1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.]],
#
# [[1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.]],
#
# [[1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.]],
#
# [[1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.]],
#
# [[1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.]],
#
# [[1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.]],
#
# [[1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.]],
#
# [[1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.],
# [1., 2., 3., 4., 5.]]]])
p = p_0 + p_n + offset
# p = p_0 + p_n
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
@staticmethod
def _reshape_x_offset(x_offset, ks):
b, c, h, w, N = x_offset.size()
x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1)
x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks)
return x_offset
if __name__ == '__main__':
deformconv2d = DeformConv2d(
64, 128, kernel_size=3, padding=1, stride=1, bias=None, modulation=True
)
_input = torch.ones((1, 64, 5, 5))
result = deformconv2d(_input)
print(result.shape)
print(result)