Commonsense and Named Entity Aware Knowledge Grounded Dialogue Generation
摘要
motivation:
以外部知识为基础,在对话历史背景下解释语言模式,如省写、回指和共同引用,对对话的理解和生成至关重要。
this paper:
在本文中,我们提出了一种新的开放域对话生成模型,该模型有效地利用了大规模的常识知识,以及非结构化的特定主题的知识。我们使用使用协同引用的命名实体感知结构来增强常识知识。我们提出的模型利用一个多跳注意层来保存对话历史和相关知识的最准确和最关键的部分。
此外,我们采用了一个常识性的实体增强注意模块,该模块从不同来源提取的三元组开始,利用交互式对话知识模块获得的查询向量,利用多跳注意逐步找到相关的三元组支持集。
Our code is publicly available at
https://github.com/deekshaVarshney/CNTF;
https://www.iitp.ac.in/-ai-nlp-ml/resources/
codes/CNTF.zip
1. 引言
神经语言模型通常关注于较少的语言成分,如句子、短语或用于文本分析的单词。然而,语言的作用范围要广泛得多——一场对话通常会有一个中心主题,说话者会分享共同的信息,以便相互理解。信息经常被重复使用,但是为了避免过度使用,同样的东西和人都是在对话框中通过使用相关的表达式进行了多次引用。当所有这些信息都以结构化、逻辑和一致的方式传递时,对话变得连贯,说话者可以相互理解。
对对话的语义理解可以通过常识性知识或世界事实来得到帮助。此外,作为一种关键的人类语言现象,共同引用简化了人类语言,同时是机器理解的重要障碍,特别是代词,由于语义薄弱而难以解析(Ehrlich,1981)。
基于反应生成方法(Ghazvininejad等人,2018;Dinan等人,2018)可以在开放领域环境中提供事实的复制,而常识知识对于创建成功的互动至关重要,因为社会构建的常识知识是人类在对话中理解和使用的上下文细节的集合。
尽管在实证评价中证明了有效性,但过去的工作也有一些显著的缺点。特别是,没有对实体、语义关系或会话结构的明确表示。为了解决这些限制,要求对话模型识别对话历史中的相关结构可以直接测试对话理解的水平。本文主要讨论命名实体级知识,并分析对话历史背景下实体的参考。
为了确保我们的模型的通用化性,我们直接以三联体的形式合并实体,这是现代知识图中最常见的格式,而不是像传统方法那样用特征或规则来编码它。
我们创建了一个名为CNTF、常识、命名实体和局部知识融合神经网络的会话模型,通过利用特定主题的文档信息和使用结构化实体和常识知识来生成成功的响应。我们首先在解析对话中的共同引用后,构造基于命名实体的三元组,以增强从概念网获得的现有常识性三元组(Speer和Havasi,2012)。我们使用多跳注意力来迭代多源信息。我们从交互式对话-知识模块中获得一个加权查询向量,该模块用于对对话、主题知识和相应的三元组进行查询。 CNTF对对话的历史和知识的句子进行推理,我们使用它从对话的背景和主题知识中过滤出相关的信息。类似地,为了对这些三元组进行推理,我们再次进行多轮迭代,屏蔽出不相关的三元组。
contribution
- 我们提出了CNTF,一种新的基于知识的对话生成模型,它利用对话上下文、非结构化文本信息和结构性知识来促进显式推理。
- 我们使用共引用解析增强了从具有命名实体感知结构的ConceptNet数据库中提取的常识三元组。
- 我们定义了一个有效的滑动窗口机制,以从较长的对话上下文中删除无关的信息,并确保有效的内存利用率。我们使用一个交互式对话知识模块来生成一个加权查询向量,它捕获对话和主题知识之间的交互。
- 通过对公开的数据集进行广泛的定性和定量验证,我们表明我们的模型优于强基线。
2. 相关工作
在本文中,我们展示了如何使用结构化和非结构化知识来改进基于文档的对话生成任务。我们提出了一种有效的基于知识的对话模型CNTF,该模型是由多源异构知识构建的。基于基于知识的对话生成基准数据集的实验。维基百科的向导和CMU_DoG,已经展示了我们提出的方法的有效性。我们的方法采用了一个大规模的命名实体增强的常识知识网络,以及一个特定领域的事实知识库来帮助理解一个话语,以及使用一个新的基于多跳注意的模型生成反应。
3. 方法论
3.1 问题定义
D = { d i } i = 1 K D= \{di\} _{i=1}^K D={di}i=1K 表示一段有K轮的对话
d i = ( a i 1 , a i 2 ) d_i=(a^1_i,a^2_i) di=(ai1,ai2) 表示两个代理之间的对话交换
和 ( a i 1 , a i 2 ) (a^1_i,a^2_i) (ai1,ai2)分别相关的文档 S i 1 , S i 2 S^1_i,S^2_i Si1,Si2包含特定主题的知识
我们通过创建三元组集来利用常识和面向命名实体的知识
τ = { τ 1 , τ 2 , . . . , τ ∣ τ ∣ } \tau=\{\tau_1,\tau_2,...,\tau_{\left| \tau\right|}\} τ={τ1,τ2,...,τ∣τ∣}
τ i \tau_i τi的格式(head, relation, tail),
三元组的来源:从ConceptNet中提取话语中每个单词的关系(如果单词是来自ConceptNet中的概念单词),以及采用共参考解析法形成基于命名实体的三元组
对于第k轮对话,已知前n轮对话历史,以及和对话历史相关的知识,生成response Y = { y 1 , y 2 , . . . , y ∣ y ∣ } Y=\{y_1,y_2,...,y_{\left| y\right|}\} Y={y1,y2,...,y∣y∣}
3.2 Encoder
3.2.1 Dialogue Encoder
Dialogue Encoder在多回合对话中跟踪对话上下文,依次对话语进行编码。
每轮的输入为 x = ( x 1 , x 2 , . . . , x n ) x= (x_1, x_2, ..., x_n) x=(x1,x2,...,xn), n指的是tokens数.
对于第一轮,输入就是 a 1 1 a^1_1 a11
对于之后的l轮次,第j轮,j>1,输入是前一个回合的第二个代理的反应和当前回合的第一个代理的话语的连接, [ a j − 1 2 ; a j 1 ] [a^2_{j−1}; a^1_j ] [aj−12;aj1]
然后,编码器利用BERT来获得 H D = { h i } i = 1 n H_D= \{h_i\}^n_{i=1} HD={hi}i=1n的表示。
对于对话表示,有两种状态 D S , D H D_S , D_H DS,DH
在第一轮都初始化为 H D H_D HD
然后,在接下来的轮次使用滑动窗口机制来更新 D S , D H D_S , D_H DS,DH
一个大小为“ l l l”的窗口意味着我们只连接前面的“ l − 1 l-1 l−1”回合的隐藏状态。这有助于消除更长的对话上下文中的噪音和节省内存 D H D_H DH 保持固定,并存储对话上下文的隐藏状态。而 D S D_S DS在每个回合都会更新,目的是捕获适当的历史信息,以准确地生成响应。
其实就是保留前n个对话历史
3.2.2 Knowledge Encoder
[ S j − 1 ; 2 S j 1 ] [S^2_{j−1;} S_j^1] [Sj−1;2Sj1] for turn j > 1, else S 1 1 S^1_1 S11
for the first turn
被截断到最大令牌计数为400。
还是使用ber进行编码得到 H K b = { h i } i = 1 m H_{Kb} = \{h_i\}^m_{i=1} HKb={hi}i=1m
m是文档的token数,m<=400
类似对话的 D S , D H D_S , D_H DS,DH ,知识文档有 K b S , K b H Kb_S ,Kb_H KbS,KbH ,都初始化为 H K b H_{Kb} HKb 与用于即将到来的回合的对话状态的滑动窗口机制不同, K b S , K b H Kb_S ,Kb_H KbS,KbH只存储从基于BERT的知识编码器中获得的当前回合的隐藏状态。
3.3 Multi-hop Attention
我们采用 dual and dynamic graph attention
mechanism(Wang et al.,2020)来模拟人类一步一步的探索和推理行为。
在每一步中,我们假定对话和知识状态都有一些信息需要传播。
D S D_S DS is updated using the forget and add operations.每个hop的 D S , D H D_S,D_H DS,DH是不同的,是存在更新的
对于hop r,

目标是计算 c k , t ( r ) c^{(r)}_{k,t} ck,t(r)
k是第k轮,t是第t个时间步
先计算公式(2) q k , t q_{k,t} qk,t是query embedding
v 1 ( r ) , W 1 ( r ) , W 2 ( r ) v^{(r)} _1 , W_1^{(r)}, W_2^{(r)} v1(r),W1(r),W2(r)
计算完(1),(2),(3)之后根据附录A更新 D S D_S DS
D H D_H DH是固定的
3.4 Constructing Named Entity based Triples using Co-reference Resolution
为了向现有的常识性三元组添加更多有用的链接,我们使用了从对话中提取的共引用链和命名实体。首先,我们使用AllenNLP共引用解析模块来识别对话中的共引用链。
使用命名的实体和概念作为节点,获得新的三元组集,对应的边构建如下:
(a)在同一对话中出现的每一对命名实体之间,以及
(b)在命名实体节点与同一对话框中的其他概念之间。
我们可能会注意到,首先解析共同引用,然后提取命名实体,可以确保跨多个话语的实体以某种方式连接。此外,我们显式地形成一个具有RelatedTo的三重联体,因为它很适合在大多数情况下,是因为它表示两个命名实体及其在对话中的不同引用或别名之间的关系
3.5 Commonsense and Named Entity Enhanced Attention Module
对于每个对话,最后一组三元组由常识和命名实体的三元组组成。我们从可训练的嵌入层即
E = e m b _ l a y e r ( τ ) E = emb\_layer(\tau) E=emb_layer(τ)
中得到了三元组的头和尾实体嵌入。形式上,一个查询用于循环三重嵌入,并计算每个跳p处的注意权值。
α k , t ( p ) = s o f t m a x ( q t ( p − 1 ) E ( p − 1 ) ) \alpha^{(p)}_{k,t} = softmax(q_t^{(p−1)}E^{(p−1)}) αk,t(p)=softmax(qt(p−1)E(p−1))
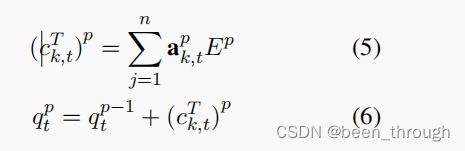
先计算5得到知识三元组的加权上下文
然后计算6来更新。使用了一种查询更新机制,其中查询嵌入使用当前步骤的加权三重嵌入进行查询。
3.6 Decoder
3.6.1 Interactive Dialogue-Knowledge Module
由于每一个话语都与特定主题的非结构化知识有关,我们采用一种交互机制来关注对话和知识句子。利用编码的加权对话上下文作为初始查询向量qt(3.5计算得到),我们可以改进从对话中提取的信息提取和知识隐藏状态,从而生成响应。为了获得加权对话上下文W HD,我们在HD和HK之间应用了如第3.3节所述的多跳注意,它们分别是从对话和知识编码器中接收到的隐藏状态。
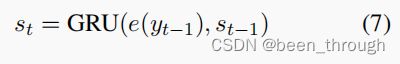
decoder的隐藏状态(就是 s t s_t st)初始为3.3计算的上下文对话表示
decoder是一个词一个词的生成, e ( y t − 1 ) e(y_{t-1}) e(yt−1)是生成的前一个词 ( y t − 1 ) (y_{t-1}) (yt−1)的embedding
s t s_t st就可以反应对话,知识,三元组的表示
3.6.2 Fusion Block
词汇表Pg(yt)单词上的概率分布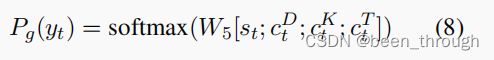
W 5 W_5 W5 is a trainable parameter
3.6.3 Copy Block
特别地,时间步长t时的单词要么从词汇表中生成,要么从对话历史、知识历史中复制,或者使用三元组中的实体。
t是时间步,生成一个词就是一个时间步,hop是模型multi-hop
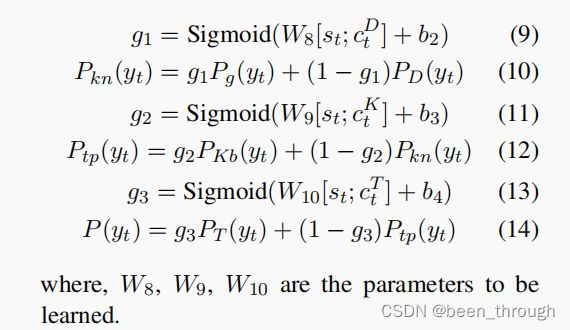

loss就是decder的loss