Deep Learning for Image Super-resolution 基于深度学习的图像超分辨率
论文 Deep Learning for Image Super-resolution:A Survey 摘抄
图像超分辨率是计算机视觉中提高图像和视频分辨率的一类重要的图像处理技术
1. 常用评价指标
- structural similarity index (SSIM) 基于结构信息退化的替代性补充质量评估框架
论文: Image Quality Assessment: From Error Visibility toStructural Similarity(可在sci hub 下载)

对于图像质量评估,局部应用SSIM指数比全局应用更有用。
首先,图像统计特征通常是高度空间非平稳的。
第二,图像失真可能取决于也可能不取决于局部图像统计,也可能是空间变化的。
第三,在典型的观看距离下,人类观察者在一个时间实例中只能以高分辨率感知图像中的局部区域(由于HVS 的凹入特征)。
最后,局部质量测量可以提供图像的空间变化质量图,这提供了关于图像质量退化的更多信息,并且可能在一些应用中有用。
SSIM指数的应用范围可能不限于图像处理。事实上,因为它是一个对称的度量,所以它可以被认为是比较任何两个信号的相似性度量。信号可以是离散的,也可以是连续的,并且可以存在于任意维度的空间中。
代码实现
- Peak signal-to-noise ratio (PSNR) 峰值信噪比
峰值信噪比(PSNR)是最流行的有损变换(例如,图像压缩、图像修复)的重建质量测量之一。对于图像超分辨率,PSNR是通过最大像素值(表示为L)和图像之间的均方误差(MSE)来定义的。给定具有N个像素的地面真实图像I和重建图像之间的PSNR定义如下:

其中L在一般情况下等于255,使用8位表示。由于PSNR只与像素级均方误差有关,只关心相应像素之间的差异而不关心视觉感知,因此它通常导致在真实场景中表示重建质量的性能较差,而在真实场景中,我们通常更关心人类的感知。然而,由于缺乏完全准确的感知度量,PSNR仍然是目前最广泛使用的SR模型的评估标准。
- Mean opinion score (MOS) 平均意见得分
平均意见分数(MOS)测试是一种常用的主观IQA方法,要求人类评分者为测试图像分配感知质量分数。通常分数从1(差)到5(好)。最终的MOS被计算为所有等级的算术平均值。
2. Super-resolution Frameworks超分辨率架构
- Pre-upsampling Super-resolution
用传统方法(例如双三次插值)将LR图像上采样为具有期望尺寸的粗略HR图像,然后对这些图像应用深度神经网络以重建高质量细节。由于最困难的上采样操作已经完成,CNNs只需要对粗图像进行细化,大大降低了学习难度。

- Post-upsampling Super-resolution
为了提高计算效率,并充分利用深度学习技术自动提高分辨率,研究人员建议在低维空间中执行大多数计算,方法是用集成在模型末端的端到端可学习层来代替预定义的上采样。即如图所示的后上采样SR中,在不增加分辨率的情况下,将LR输入图像馈送到深层CNNs中,并且在网络的末端应用端到端可学习的上采样层。

- Progressive Upsampling Super-resolution
虽然后上采样随机共振框架极大地降低了计算成本,但它仍然有一些缺点。一方面,上采样仅在一个步骤中执行,这极大地增加了大scaling factors的学习难度。另一方面,每个scaling factor需要训练一个单独的SR模型,这不能满足多尺度SR的需要。为了解决这些缺点,Laplacian pyramid SR network(LapSRN) 采用了渐进上采样框架,如图所示。具体来说,这一框架下的模型是基于级联的中枢神经系统,并逐步重建更高分辨率的图像。在每个阶段,图像都被上采样到更高的分辨率,并由CNNs进行细化。
通过将一个困难的任务分解成简单的任务,该框架下的模型极大地降低了学习难度,特别是在大因素的情况下,并且在不引入过多空间和时间代价的情况下处理多尺度SR。

- Iterative Up-and-down Sampling Super-resolution
为了更好地捕捉LRHR图像对的相互依存性,一个有效的迭代程序称为反投影被纳入到SR。这种超分辨率框架,即迭代上下采样超分辨率,试图迭代地应用反投影细化,即计算重建误差,然后将其融合以调整高分辨率图像强度。
该框架下的模型能够更好地挖掘低分辨率高分辨率图像对之间的深层关系,从而提供更高质量的重建结果。然而,back-projection 模块的设计标准仍然不清楚。由于这种机制刚刚被引入到基于深度学习的服务请求中,因此该框架具有很大的潜力,需要进一步探索。

3. Upsampling Methods上采样
- Interpolation-based Upsampling(基于插值的上采样)
图像插值,也称为图像缩放,是指调整数字图像的大小,广泛用于图像相关应用。传统的插值方法包括最近邻插值、双线性和双三次插 值、Sinc和Lanczos重采样等。由于这些方法是可解释的和易于实现的,其中一些仍然广泛用于基于CNN的SR模型。
Nearest-neighbor Interpolation
近邻插值是一种简单直观的算法。它为每个要插值的位置选择最接近的像素值,而不考虑任何其他像素。因此,这种方法非常快,但通常会产生低质量的块状结果
Bilinear Interpolation
双线性插值(BLI)首先在图像的一个轴上执行线性插值,然后在另一个轴上执行,如图3所示。由于它产生的是感受野大小为2×2的二次插值,因此在保持相对较快速度的同时,它显示出比最近邻插值好得多的性能。

Bicubic Interpolation
双三次插值(BCI) 在两个轴的每一个上执行三次插值,如图3所示。与BLI相比,BCI考虑了4 × 4像素,结果更平滑,伪像更少,但速度更低。
基于插值的上采样方法仅基于其自身的图像信号来提高图像分辨率,而没有带来任何更多的信息。它们经常引入一些副作用,例如计算复杂性、噪声放大、结果模糊。因此,当前的趋势是用可学习的上采样层取代基于插值的方法。
- Learning-based Upsampling(基于学习的上采样)
Transposed Convolution Layer
转置卷积层,也称为反卷积层,试图执行与正常卷积相反的变换,即基于大小类似卷积输出的特征映射来预测可能的输入。

Sub-pixel Layer
亚像素层是另一个端到端可学习的上采样层,通过卷积生成多个通道,然后对它们进行整形来执行上采样。与转置卷积层相比,亚像素层具有更大的感受野,提供了更多的上下文信息,有助于生成更逼真的细节。

Meta Upscale Module
以前的方法需要预定义比例因子,即针对不同的因子训练不同的上采样模块,这样效率不高,不符合实际需要。因此,胡等人提出了Meta Upscale Module,该模块首先基于元学习来解决任意缩放因子的SR。该方法基于独立于图像内容的几个值来预测每个目标像素的大量卷积权重,因此当面对更大的放大率时,预测结果可能不稳定并且效率较低。

4. Network Design网络设计
- Residual Learning
Global Residual Learning:
研究人员只学习输入图像与目标图像之间的残差,即全局残差学习。在这种情况下,它避免了学习从一个完整图像到另一个完整图像的复杂转换,而是只需要学习一个残差图来恢复丢失的高频细节。由于大多数区域的残差接近于零,模型复杂度和学习难度大大降低。
Local Residual Learning:局部残差学习类似于ResNet 中的残差学习,用于缓解因网络深度不断增加而导致的退化问题,降低训练难度,提高学习能力。
Local Residual Learning:
局部残差学习类似于ResNet中的残差学习,用于缓解因网络深度不断增加而导致的退化问题,降低训练难度,提高学习能力。

- Recursive Learning
递归学习,即以递归方式多次应用相同的模块,递归学习可以在不引入过多参数的情况下学习更高级的表示,但仍然不能避免高计算成本。

- Multi-path Learning
多路径学习是指通过多条路径传递特征,这些路径执行不同的操作,并将它们融合在一起,以提供更好的建模能力。具体来说,它可以分为全局、局部和规模特定的多路径学习:
Global Multi-path Learning:
全局多路径学习是指利用多条路径提取图像的不同方面的特征。这些路径可以在传播中相互交叉,从而大大提高学习能力。
Local Multi-path Learning:

该模块采用两个3 × 3和5 × 5的卷积层同时提取特征,然后将输出连接并再次进行相同的运算,最后进行额外的1×1卷积。一个快捷方式通过按元素添加来连接输入和输出。通过这样的局部多路径学习,SR模型可以更好地从多个尺度提取图像特征,进一步提高性能。
Scale-specific Multi-path Learning:

考虑到不同尺度的随机共振模型需要经过相似的特征提取,Lim等人提出了特定尺度的多路径学习来处理单个网络的多尺度随机共振。通过这种方式,所提出的MDSR通过共享不同比例的大部分参数而大大减小了模型尺寸,并且表现出与单比例模型相当的性能。
- Dense Connections
于每个密集块,所有前面块的特征图都作为输入,其自身的特征图作为所有后续块的输入。密集连接不仅有助于减轻梯度消失、增强信号传播和鼓励特征重用,而且通过采用小的增长率(即,密集块中的通道数量)和在连接所有输入特征映射后压缩通道来显著减小模型尺寸。

- Attention Mechanism
Channel Attention:
虑到不同通道之间特征表示的相互依赖和相互作用,胡等人提出了一种“挤压-激励”模块,通过显式地模拟通道相互依赖来提高学习能力。

Non-local Attention:
现有的SR模型大多局部感受野非常有限。然而,一些遥远的物体或纹理对于局部补丁生成可能非常重要。因此,张等人出了局部和非局部注意块来提取捕捉像素之间的长程相关性的特征。
- Advanced Convolution
Dilated Convolution:
上下文信息有助于为随机共振生成逼真的细节。因此,张等人在随机共振模型中用扩张卷积代替普通卷积,将感受野增加两倍以上,并获得更好的性能。
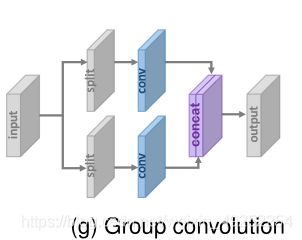
Group Convolution:
减少参数和操作的数量,代价是损失很小的性能。
Depthwise Separable Convolution:
它由分解的深度方向卷积和点方向卷积(即1 × 1卷积)组成,因此以很小的精度降低减少了大量参数和运算。
- Region-recursive Learning
通过使用两个网络来分别捕获全局上下文信息和连续的相关性。在一定程度上表现出较好的性能,但递归过程需要较长的传播路径,这大大增加了计算成本和训练难度。
- Pyramid Pooling
受空间金字塔汇集层的启发,赵等人提出了金字塔汇集模块,以更好地利用全局和局部上下文信息。

- Wavelet T ransformation
波变换是通过将图像信号分解成表示纹理细节的高频子带和包含全局拓扑信息的低频子带来高效表示图像的方法。
- Desubpixel
为了加快推理速度,Vu等人提出在低维空间中执行耗时的特征提取,并提出去子像素,这是子像素层的混洗操作的逆操作。
- xUnit
为了结合空间特征处理和非线性激活来更有效地学习复杂特征,Kligvasser等人提出了用于学习空间激活函数的xUnit。ReLU被视为确定权重图,以执行与输入按元素相乘,而xUnit通过卷积和高斯选通直接学习权重图。者将模型大小减少了近50%,而没有任何性能下降。
5. 数据集

6. 典型方法
