【深度学习】Batch Normalization
7. BN的原理!!!它的参数是怎么学习到的??
答案:变换重构,引入了可学习参数γ、β。
BN算法(Batch Normalization)其强大之处如下:
(1)你可以选择比较大的初始学习率,让你的训练速度飙涨。以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性;
(2)你再也不用去理会过拟合中dropout、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项了参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
(后面的看了也不理解,就记这两个吧。。。)
- 在神经网络训练开始前,都要对输入数据做一个归一化处理,那么具体为什么需要归一化呢?归一化后有什么好处呢?
原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
网络一旦train起来,那么参数就要发生更新,除了输入层的数据外(因为输入层数据,我们已经人为的为每个样本归一化),后面网络每一层的输入数据分布是一直在发生变化的,因为在训练的时候,前面层训练参数的更新将导致后面层输入数据分布的变化。以网络第二层为例:网络的第二层输入,是由第一层的参数和input计算得到的,而第一层的参数在整个训练过程中一直在变化,因此必然会引起后面每一层输入数据分布的改变。我们把网络中间层在训练过程中,数据分布的改变称之为:“Internal Covariate Shift”。BN就是要解决在训练过程中,中间层数据分布发生改变的情况。
BN概述
在每一层输入的时候,再加个预处理操作,比如网络第三层输入数据X3(X3表示网络第三层的输入数据)把它归一化至:均值0、方差为1,然后再输入第三层计算,这样我们就可以解决前面所提到的“Internal Covariate Shift”的问题了。paper的算法本质原理就是这样:在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理,然后再进入网络的下一层。它是一个可学习、有参数的网络层。
神经网络输入数据预处理
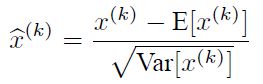
这个公式是对某一个层网络的输入数据做一个归一化处理。需要注意的是,我们训练过程中采用batch 随机梯度下降,上面的E(xk)指的是每一批训练数据神经元xk的平均值;然后分母就是每一批数据神经元xk激活度的一个标准差了。
BN算法实现
在网络中间层数据做一个归一化处理,这么简单的想法,为什么之前没人用呢?
如果是仅仅使用上面的归一化公式,对网络某一层A的输出数据做归一化,然后送入网络下一层B,这样是会影响到本层网络A所学习到的特征的。比如我网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧,你强制把它给我归一化处理、标准差也限制在了1,把数据变换成分布于s函数的中间部分,这样就相当于我这一层网络所学习到的特征分布被你搞坏了,这可怎么办?于是文献使出了一招惊天地泣鬼神的招式:变换重构,引入了可学习参数γ、β,这就是算法关键之处: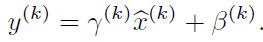
每一个神经元xk都会有一对这样的参数γ、β。这样其实当:
 (标准差啊!( ⊙ o ⊙ )啊!大姐)
(标准差啊!( ⊙ o ⊙ )啊!大姐)

是可以恢复出原始的某一层所学到的特征的。因此我们引入了这个可学习重构参数γ、β,让我们的网络可以学习恢复出原始网络所要学习的特征分布。(这样呢A所学到的特征分布就给恢复了呀,然后归一化的数据再接下去送给B,不会破坏A学到的特征分布,哈哈哈)
最后Batch Normalization网络层的前向传导过程公式就是:
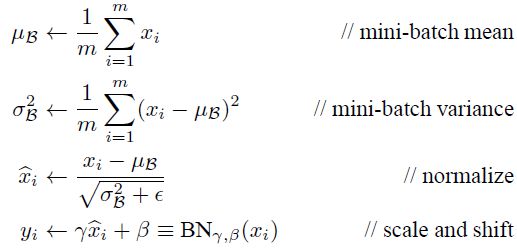
上面的公式中m指的是mini-batch size。
BN源码实现(我应该也不会看,但就要整整齐齐)
m = K.mean(X, axis=-1, keepdims=True)#计算均值
std = K.std(X, axis=-1, keepdims=True)#计算标准差
X_normed = (X - m) / (std + self.epsilon)#归一化
out = self.gamma * X_normed + self.beta#重构变换BN实战使用——也就是测试的时候怎么办???
(1)一个网络一旦训练完了,就没有了min-batch这个概念了。测试阶段我们一般只输入一个测试样本,看看结果而已。因此测试样本,前向传导的时候,上面的均值u、标准差σ 要哪里来?其实网络一旦训练完毕,参数都是固定的,这个时候即使是每批训练样本进入网络,那么BN层计算的均值u、和标准差σ 都是固定不变的。我们可以采用这些数值来作为测试样本所需要的均值、标准差,于是最后测试阶段的u和σ 计算公式如下: 。
。
上面简单理解就是:对于均值来说直接计算所有batch u值的平均值;然后对于标准偏差采用每个batch σB的无偏估计。最后测试阶段,BN的使用公式就是:
 。
。
(2)根据文献说,BN可以应用于一个神经网络的任何神经元上。文献主要是把BN变换,置于网络激活函数层的前面。在没有采用BN的时候,激活函数层是这样的:z=g(Wu+b)。
也就是我们希望一个激活函数,比如s型函数s(x)的自变量x是经过BN处理后的结果。因此前向传导的计算公式就应该是:z=g(BN(Wu+b))。
其实因为偏置参数b经过BN层后其实是没有用的,最后也会被均值归一化,当然BN层后面还有个β参数作为偏置项,所以b这个参数就可以不用了。因此最后把BN层+激活函数层就变成了:z=g(BN(Wu))。
(3)Batch Normalization在CNN中的使用
- BN层是对于每个神经元做归一化处理,甚至只需要对某一个神经元进行归一化,而不是对一整层网络的神经元进行归一化。既然BN是对单个神经元的运算,那么在CNN中卷积层上怎么办??
假如某一层卷积层有6个特征图,每个特征图的大小是100*100,这样就相当于这一层网络有100*100*6个神经元,如果采用BN,就会有100*100*6个参数γ、β,这样岂不是太恐怖了。因此卷积层上的BN使用,其实也是使用了类似权值共享的策略,把一整张特征图当做一个神经元进行处理。
CNN经过卷积后得到的是一系列的feature map,如果min-batch sizes为m,那么网络某一层输入数据可以表示为四维矩阵(m,f,p,q),m为min-batch sizes,f为特征图个数,p、q分别为特征图的宽高。在CNN中我们可以把每个特征图看成是一个特征处理(一个神经元),因此在使用Batch Normalization,mini-batch size 的大小就是:m*p*q,于是对于每个特征图都只有一对可学习参数:γ、β。说白了吧,这就是相当于求取所有样本所对应的一个特征图的所有神经元的平均值、方差,然后对这个特征图神经元做归一化。(划掉因为没看懂,前面的还看懂了呢)
。。。。。
补货
BN怎么实现的?有哪些缺点?如何改进?其他的归一化方法?
BN算法回顾:

BN为什么能解决过拟合
BN本身最主要的贡献其实并不是降低overfitting,而是在于控制前一层output的variance,使得模型更加稳定,并且训练速度加快。
如果说BN解决了过拟合问题。那么从BN的工作原理出发,每一次一个batch会统一进行前向传播,在一层hidden layer之后,假设我们进行了batch norm,实际上是对这一层的output进行normalization。(每层的输入值)那么每一次的训练,即使同样的样本,可能因为其他数据不一样,导致当前batch会不一样,所以batch_mean和batch_variance不一样,那么它经过BN之后的output就会不一样,对于同一个样本。这就引入了一些noise在里面,同样为了克服noise,模型必须更加generalize一些,这就降低了overfitting。
BN为什么能防止过拟合?
When training with Batch Normalization, a training example is seen in conjunction with other examples in the mini-batch, and the training network no longer producing deterministic values for a given training example. In our experiments, we found this effect to be advantageous to the generalization of the network.
大概意思是:在训练中,BN的使用使得一个mini-batch中的所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果。
这句话什么意思呢?意思就是同样一个样本的输出不再仅仅取决于样本本身,也取决于跟这个样本属于同一个mini-batch的其它样本。同一个样本跟不同的样本组成一个mini-batch,它们的输出是不同的(仅限于训练阶段,在inference阶段是没有这种情况的)。我把这个理解成一种数据增强:同样一个样本在超平面上被拉扯,每次拉扯的方向的大小均有不同。不同于数据增强的是,这种拉扯是贯穿数据流过神经网络的整个过程的,意味着神经网络每一层的输入都被数据增强处理了。
BN优点:
- 减少梯度消失,加快了收敛过程。
- 起到类似dropout一样的正则化能力,一定程度上防止过拟合。
- 放宽了一定的调参要求。
缺点:
- 但是需要计算均值与方差,不适合动态网络或者RNN。(BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其他sequence长很多,这样training时,计算很麻烦。
- 计算均值方差依赖每批次,因此数据最好足够打乱。对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布。

BN改进:
Layer Normalization
- 与BN不同,LN是针对深度网络的某一层的所有神经元的输入按以下公式进行normalize操作。
BN与LN的区别在于:
- LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;
- BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
所以,LN不依赖于batch的大小和输入sequence的深度,因此可以用于batchsize为1和RNN中对边长的输入sequence的normalize操作。
其他的归一化方法:
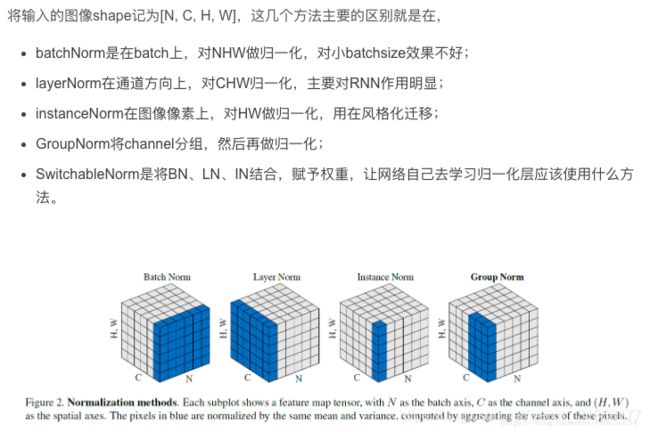
(麻烦一定要看这个好吗?)BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结
IN
BN注重对每个batch进行归一化,保证数据分布一致,因为判别模型中结果取决于数据整体分布。
但是图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
GN
主要是针对Batch Normalization对小batchsize效果差,GN将channel
方向分group,然后每个group内做归一化,算(C//G)*H*W的均值,这样与batchsize无关,不受其约束。
SN
- 归一化虽然提高模型泛化能力,然而归一化层的操作是人工设计的。在实际应用中,解决不同的问题原则上需要设计不同的归一化操作,并没有一个通用的归一化方法能够解决所有应用问题;
- 一个深度神经网络往往包含几十个归一化层,通常这些归一化层都使用同样的归一化操作,因为手工为每一个归一化层设计操作需要进行大量的实验。
因此作者提出自适配归一化方法——Switchable Normalization(SN)来解决上述问题。与强化学习不同,SN使用可微分学习,为一个深度网络中的每一个归一化层确定合适的归一化操作。
BN解决的问题:
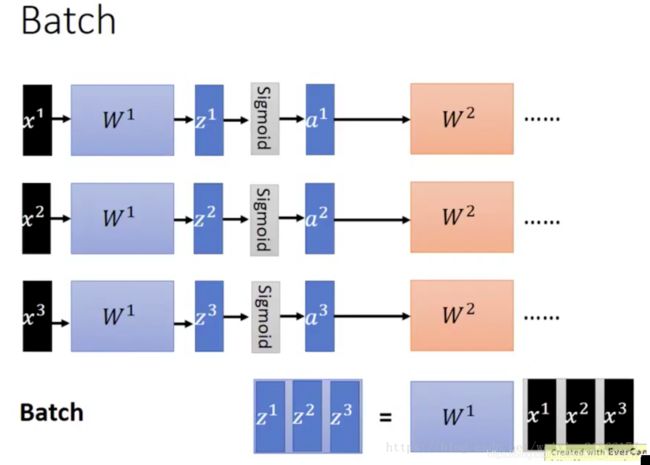
引入u等参数
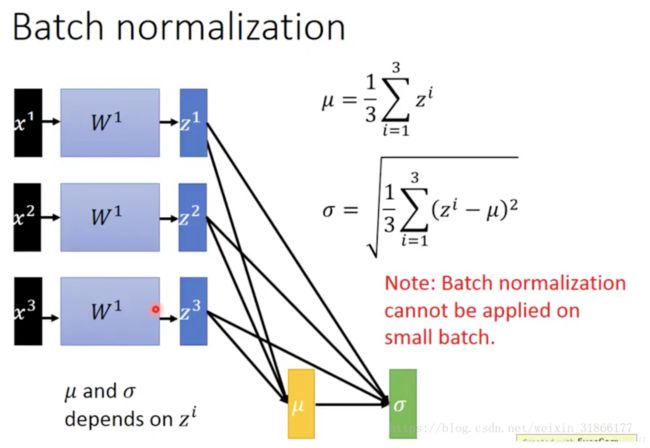
进行参数的调解
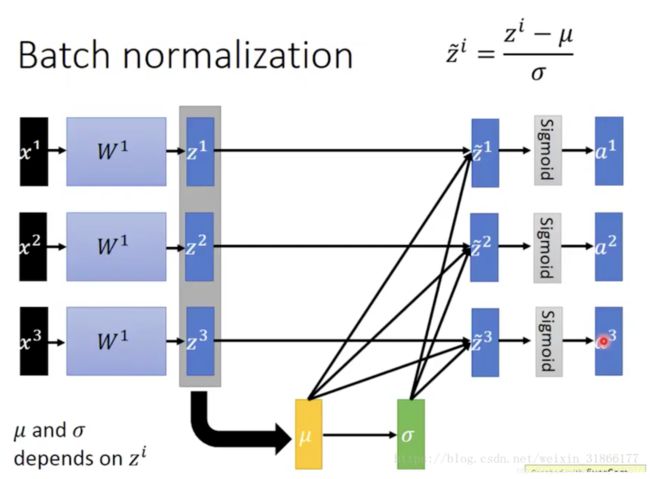
最后✌️

是对深度学习(二十九)Batch Normalization 学习笔记 所做的个人标注。详细内容看原blog~\(≧▽≦)/~啦啦啦。
详解深度学习中的Normalization,BN/LN/WN - Juliuszh的文章 - 知乎