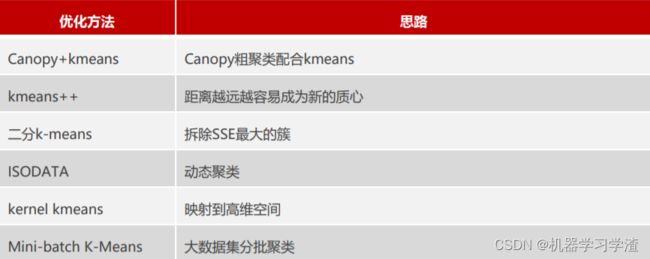
聚类优化算法——基于Kmeans算法
聚类优化算法——基于Kmeans算法
Kmeans算法
Kmeans算法的基本原理及计算流程见上文——Kmeans算法及简单案例
Kmeans算法的优缺点
- 优点
- 原理简单(靠近中心点),实现容易
- 聚类效果中上(依赖K的选择)
- 空间复杂度o(N),时间复杂度o(IKN);N为样本点个数,K为中心点个数,I为迭代次数 - 缺点
- 对离群点,噪声敏感 (中心点易偏移)
- 很难发现大小差别很大的簇及进行增量计算
- 结果不一定是全局最优,只能保证局部最优(与K的个数及初值选取有关)
# 代码
from sklearn.cluster import KMeans
Canopy算法配合初始聚类
Canopy算法基本思想(自总结):随机初始化一个点为质点,分别以指定的T1、T2画圈,在T1圈的划分为该类,在T1与T2之间的待定,然后再两个圈外面的点再指定另一个簇的质心,重新画圈,重复以上步骤。
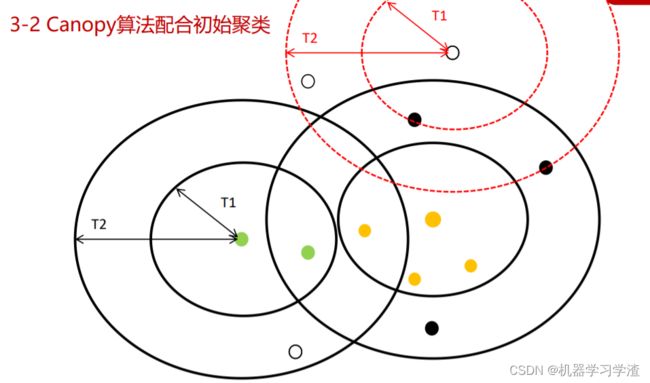
Canopy算法基本步骤
Step1: 确定K值以及初始化聚类中心,选取K个初始凝聚点,做为欲形成的中心(最简单的方法就是K的值自己确定,但必须小于数据集个数,然后从数据集中选取K个数据做为初始聚类中心);
Step2: 计算每个数据到K个初始凝聚点的距离,将每个数据和最近的凝聚点分到一组,形成K个初始分类;
Step3: 计算初始分类的重心(或均值),做为新的凝聚点,重新计算每个数据到分类重心(或均值)的距离,将每个数据和最近的凝聚点分为一组;
Step4: 重复进行Step2和Step3,直到分类的重心或均值没有明显变化为止。
Canopy算法流程
(1)、将数据集向量化得到一个list后放入内存,选择两个距离阈值:T1和T2,其中T1 > T2,对应上图,内圈为T1,外圈为T2,T1和T2的值可以用交叉校验来确定;
(2)、从list中任取一点P,用低计算成本方法快速计算点P与所有Canopy之间的距离(如果当前不存在Canopy,则把点P作为一个Canopy),如果点P与某个Canopy距离在T1以内,则将点P加入到这个Canopy;
(3)、如果点P曾经与某个Canopy的距离在T2以内,则需要把点P从list中删除,这一步是认为点P此时与这个Canopy已经够近了,因此它不可以再做其它Canopy的中心了;
(4)、重复步骤2、3,直到list为空结束。
Canopy算法优缺点
- 优点
- Kmeans对噪声抗干扰较弱,通过Canopy对比,将较小的NumPoint的Cluster直接去掉有利于抗干扰。
- Canopy选择出来的每个Canopy的centerPoint作为K会更精确。
- 只是针对每个Canopy的内做Kmeans聚类,减少相似计算的数量。 - 缺点
- 算法中 T1、T2的确定问题
K-means++算法
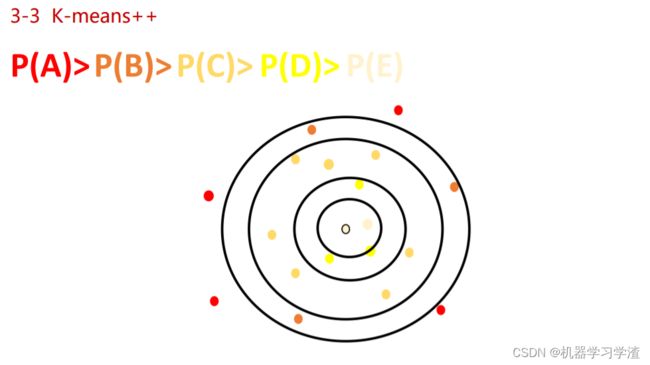
K-means++算法基本思想(自总结):先随机指定一个质心,计算所有点到质心的距离作为选择另一个簇的质心的权重,根据每个样本到每个簇质心的距离划定该样本的归属簇,继续挑选下一个簇的质心,重复以上步骤,直到满足K个质心,算法结束。
K-means++算法基本步骤
KMeans++ 算法就是通过算法来选择初始聚类中心点。初始聚类中心点的算法如下:
- 从输入的数据点集合中随机选择一个点作为第一个聚类中心;
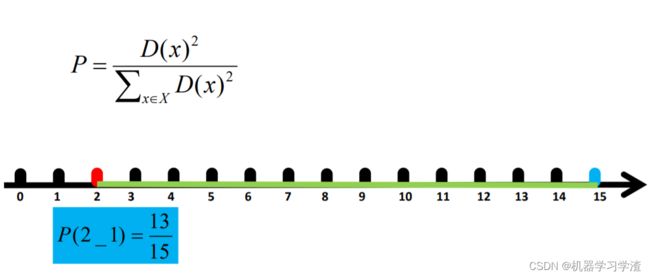
- 对于数据集中的每一个点 x ,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x);
- 选择一个新的数据点作为新的聚类中心,选择的原则是:D(x) 较大的点,被选取作为聚类中心的概率较大;
- 重复2和3,直到 k 个聚类中心被选出来;
- 利用这 k 个初始的聚类中心来运行标准的KMeans 算法。
K-means++算法案例
- 距离计算
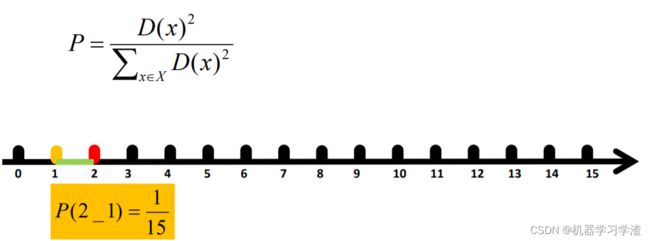
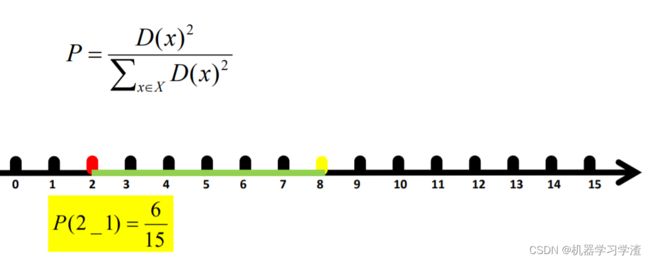
- 距离比较,选择簇类质心
- 用Kmeans算法进行调整每个样本的归属簇
- 重复以上步骤,直到簇类质心不再改变
二分Kmeans算法
二分Kmeans算法基本思想:以评估值指标(SSE)为依据进行二分,直到满足条件K,类似于CART树。
二分Kmeans算法基本步骤:
- 所有点作为一个簇
- 将该簇一分为二
- 选择能最大限度降低聚类代价函数(也就是误差平方和)的簇划分为两个簇。.
- 以此进行下去,直到簇的数目等于用户给定的数目k为止。
二分Kmeans算法案例
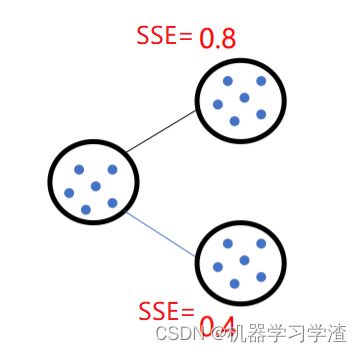
- 选择SSE大的簇,将该簇一分为二
- 继续选择SSE大的簇,将该簇一分为二
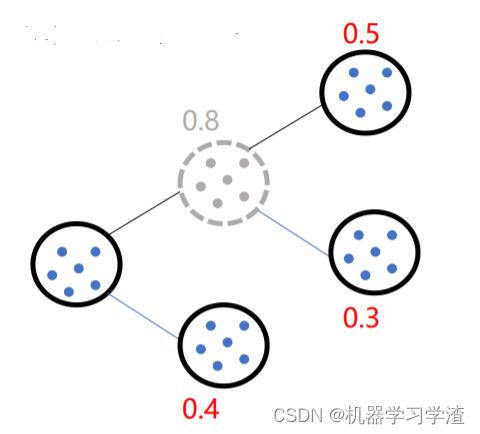
- 直到满足给定的数目k为止。
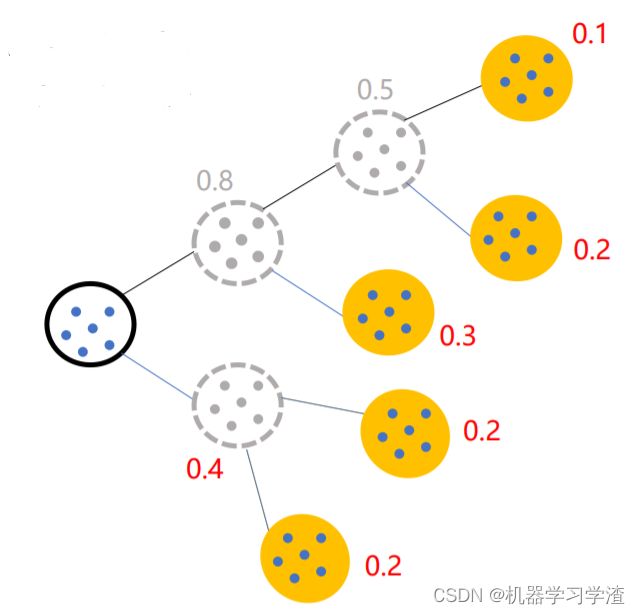
二分Kmeans隐含的一个原则
-
因为聚类的误差平方和能够衡量聚类性能,该值越小表示数据点越接近于他们的质心,聚类效果就越好。所以需要对误差平方和最大的簇进行再一次划分,因为误差平方和越大,表示该簇聚类效果越不好,越有可能是多个簇被当成了一个簇,所以我们首先需要对这个簇进行划分。
-
二分K均值算法可以加速K-means算法的执行速度,因为它的相似度计算少了并且不受初始化问题的影响,因为这里不存在随机点的选取,且每一步都保证了误差最小。
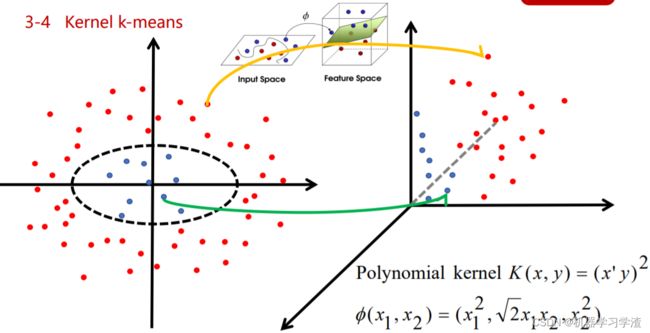
Kernel k-means算法
Kernel k-means算法基本思想:将原始线性不可分的数据,通过核函数映射到高维空间,使得原来线性不可分的数据在高位空间中线性可分,然后根据Kmeans算法来聚类。
案例1:
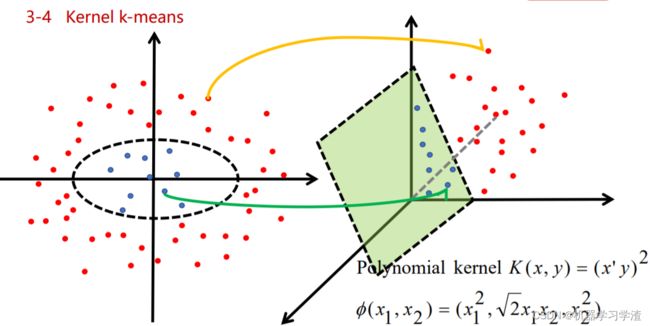
案例2:
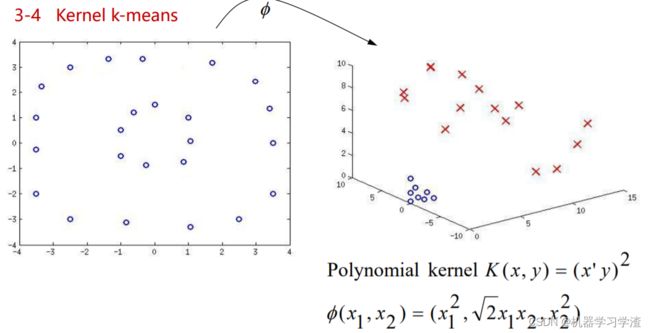
案例3:

Kernel k-means算法计算过程案例
- 原始空间中的数据
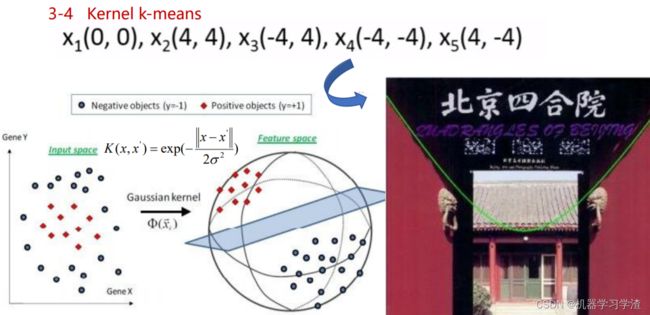
- 通过高斯核函数映射后的高维空间表示
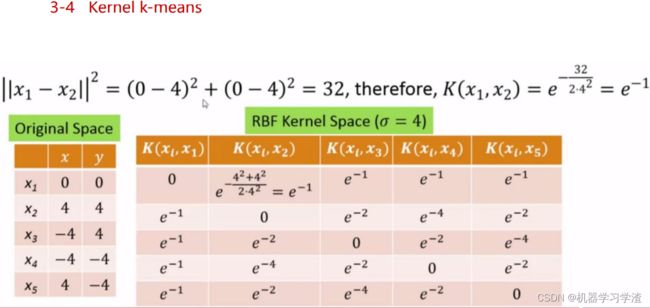
- 在高维空间中使用Kmeans算法进行聚类
Kernel k-means算法与Kmeans算法比较
从多个数据集结果来看,Kernel k-means算法效果也比Kmeans算法好。
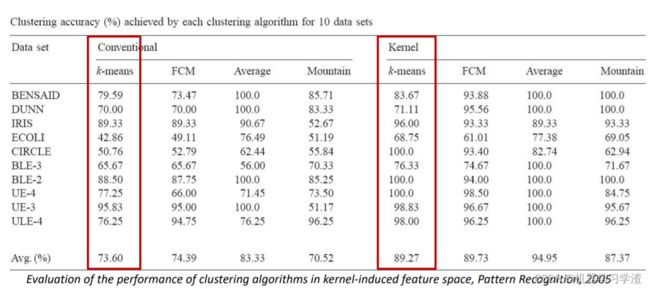
Kernel k-means算法与Kmeans算法适用情况:

k-medoids算法(k-中心聚类算法)
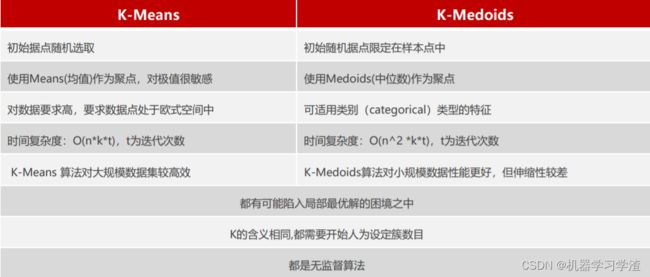
K-medoids和K-means区别
K-medoids和K-means是有区别的,不一样的地方在于中心点的选取:
- K-means中,将中心点取为当前cluster中所有数据点的平均值,对异常点很敏感!
- K-medoids中,将从当前cluster 中选取到其他所有(当前cluster中的)点的距离之和最小的点作为中心点。
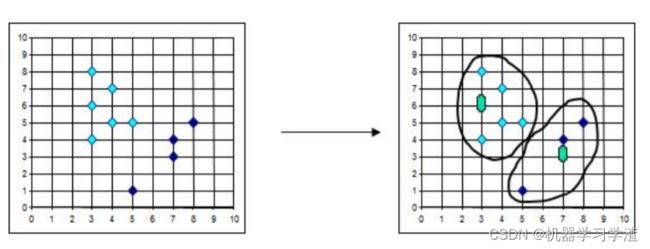
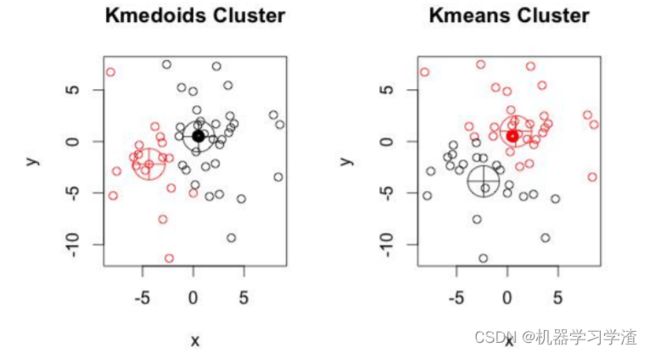
从结果来看:
K-medoids较k-means来说,多次运行每次结果偏差较小,而k-means对初值依赖大,导致每次运行结果相异程度大。
K-medoids衡量标准
K-medoids使用绝对差值和(Sum of Absolute Differences,SAD)的度量来衡量聚类结果的优劣,在n维空间中,计算SAD的公式如下所示:
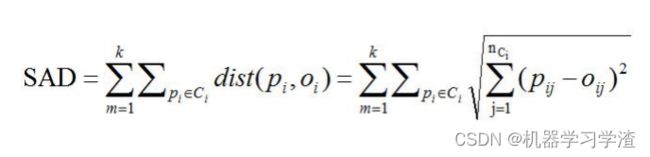
K-medoids算法流程
( 1 )总体n个样本点中任意选取k个点作为medoids
( 2 )按照与medoids最近的原则,将剩余的n-k个点分配到当前最佳medoids代表的类中
( 3 )对于第i个类中除对应medoids点外的所有其他点,按顺序计算当其为新的medoids时,代价函数的值,遍历所有可能,选取代价函数最小时对应的点作为新的medoids
( 4 )重复2-3的过程,直到所有的medoids点不再发生变化或已达到设定的最大迭代次数
( 5 )产出最终确定的k个类
K-medoids和K-means比较
k-medoids对噪声鲁棒性好。例:当一个cluster样本点只有少数几个,如(1,1),(1,2),(2,1),(1000,1000)。其中(1000,1000)是噪声。如果按照k-means质心大致会处在(1,1),(1000,1000)中间,这显然不是我们想要的。这时k-medoids就可以避免这种情况,他会在(1,1),(1,2),(2,1),(1000,1000)中选出一个样本点使cluster的绝对误差最小,计算可知一定会在前三个点中选取。
k-medoids只能对小样本起作用,样本大,速度就太慢了,当样本多的时候,少数几个噪音对k- means的质心影响也没有想象中的那么重,所以k-means的应用明显比k-medoids多。
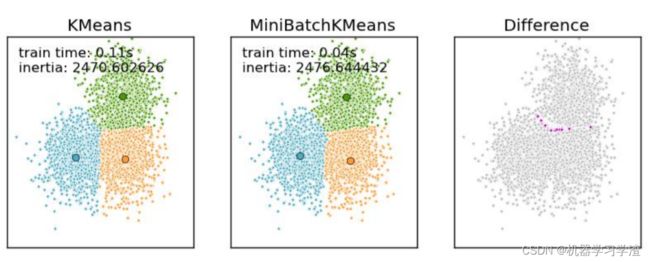
Mini Batch K-Means算法(适合大数据的聚类算法)
大数据量是什么量级?通过当样本量大于1万做聚类时,就需要考虑选用Mini Batch K-Means算法。
Mini Batch KMeans使用了Mini Batch(分批处理)的方法对数据点之间的距离进行计算。
Mini Batch计算过程中不必使用所有的数据样本,而是从不同类别的样本中抽取一部分样本来代表
各自类型进行计算。由于计算样本量少,所以会相应的减少运行时间,但另一方面抽样也必然会带来准确度的下降。
Mini Batch K-Means算法与K-Means算法效果比较案例:
Mini Batch K-Means算法的步骤:
- 首先抽取部分数据集,使用K-Means算法构建出K个聚簇点的模型
- 继续抽取训练数据集中的部分数据集样本数据,并将其添加到模型中,分配给距离最近的聚簇中心点
- 更新聚簇的中心点值
- 循环迭代第二步和第三步操作,直到中心点稳定或者达到迭代次数,停止计算操作
与Kmeans相比,数据的更新在每一个小的样本集上。对于每一个小批量,通过计算平均值得到更新质心,并把小批量里的数据分配给该质心,随着迭代次数的增加,这些质心的变化是逐渐减小的,直到质心稳定或者达到指定的迭代次数,停止计算。
总结