聚类算法——kmeans
聚类属于无监督学习:训练数据中只有x没有y
聚类算法又叫无监督分类,目标是将数据划分为有意义的簇,将所有样本按照K个质心进行聚类
质心:一类坐标的平均点
聚类过程:先随机选取K个质心,根据质心生成簇,计算簇的质心,找到新的质心,直到簇与质心不在变化,聚类完成
聚类与分类:
聚类:在未知数据上进行划分,无监督
分类:已知数据进行划分,有监督
聚类使用场景:使用聚类找到同类客户,实现精准营销
聚类中使用距离衡量样本之间的相似性,簇中样本距离越小样本相似度高
kmeans中通常使用欧几里得距离,在文本处理中通常使用余弦距离
盲点:在聚类中没有损失函数的说法,损失函数只有在需要求参数的模型中使用,不求参数的模型不适用损失函数
n_clusters表示聚类的数量,是聚类中的重要参数
聚类模型评估:(主要依据实际业务)使用轮廓系数
轮廓系数:计算簇内差异与簇间差异,表示范围是[-1,1],越大说明效果越好
代码实例:
from sklearn.datasets import make_blobs
import matplotlib.pyplot as pltx,y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1) #自己创建数据集500个数据,二维数据,具有随机性使用random_state固定数据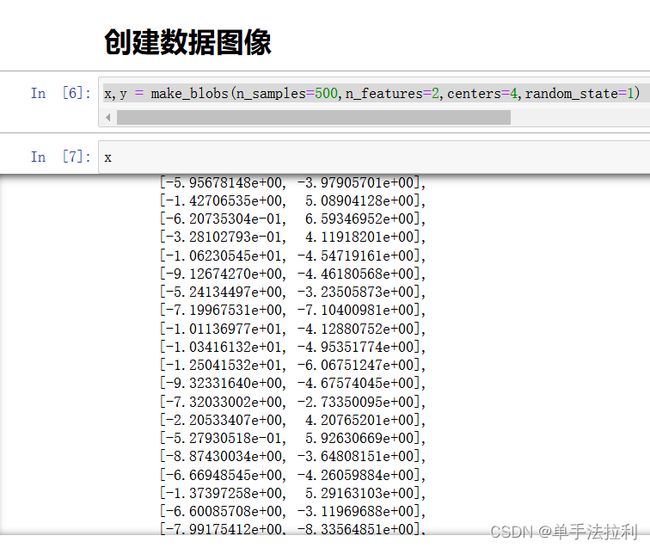
在进行聚类之前,查看数据
plt.scatter(x[:,0],x[:,1]
,marker = "o"
,s = 8
)
plt.show()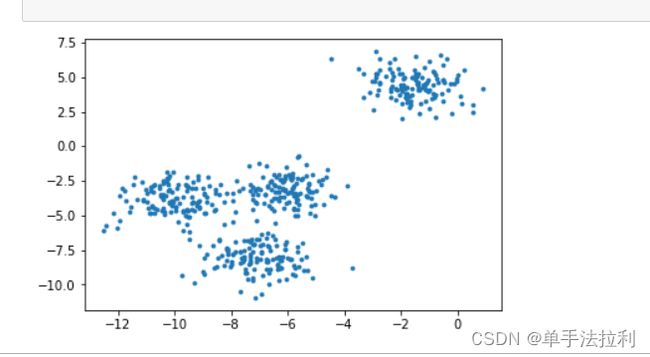
from sklearn.cluster import KMeans
cluster = KMeans(n_clusters = 3,random_state=1).fit(x) #聚类个数为3,实列化+训练
y = cluster.labels_ #查看每个样本的聚类结果
y #在结果未知下所预测样本结果
聚类模型时间长,所以在大数据进行聚类时,通常使用fit先进行小部分数据聚类,在使用fit_predict对聚类结果进行合并。
cen = cluster.cluster_centers_ #生成3个簇,查看3个质心
cen
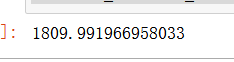
可以使用inertia_函数查看簇的距离平方和,但是效果不如轮廓系数。
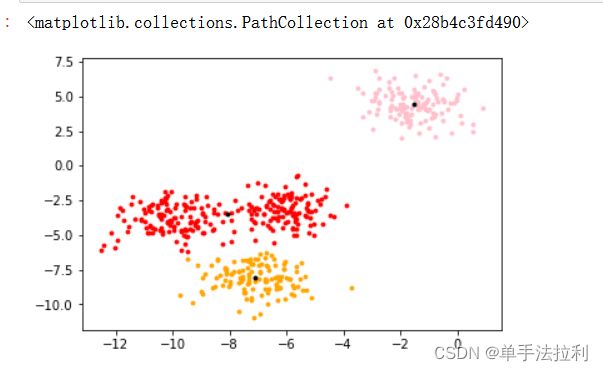
将聚类结果可视化
color = ["red","pink","orange","gray"]
for i in range(3): #查看聚类结果
plt.scatter(x[y==i,0],x[y==i,1]
,marker = "o"
,s = 8
,c = color[i]
)
plt.scatter(cen[:,0],cen[:,1] #查看质心结果
,marker = "o"
,s = 8
,c = "black"
)
使用silhouette轮廓系数进行模型评估
from sklearn.metrics import silhouette_score #平均轮廓系数
from sklearn.metrics import silhouette_samples #每个样本是轮廓系数silhouette_score(x,y) #返回平均轮廓系数 silhouette_samples(x,y) #返回每个样本的轮廓系数,求均值为silhoue_score
也可以使用卡林斯基—哈拉巴斯指数进行评估,优点:速度比轮廓系数快
from sklearn.metrics import calinski_harabasz_score
calinski_harabasz_score(x,y) #评估指数越大越好