CMU Computer Vision(16720) HW3 Template Tracking and Action Classification
Lucas-Kanade Tracking.


frame 20 frame 60
can use Robust-estimator to enhance the tracking performance.
基于Hough 变换的直线检测(Matlab实现)
输入图像:

输出图像:

源代码:
(参考Matlab houghlines 例程)
clear
I = imread('taj1small3.jpg');
I = rgb2gray(I);
%I = imrotate(I,33,'crop');
% figure
% imshow(rotI);
figure
imshow(I);
BW = edge(I,'canny');
figure
imshow(BW);
[H,T,R] = hough(BW);
figure
imshow(H,[],'XData',T,'YData',R,

'InitialMagnification','fit');
xlabel('\theta'), ylabel('\rho');
axis on
axis normal
hold on
P = houghpeaks(H,5,'threshold',ceil(0.3*max(H(:))));
x = T(P(:,2)); y = R(P(:,1));
plot(x,y,'s','color','white');
% Find lines and plot them
lines = houghlines(BW,T,R,P,'FillGap',5,'MinLength',7);
figure, imshow(I),hold on
max_len = 0;
for k = 1:length(lines)
xy = [lines(k).point1; lines(k).point2];
plot(xy(:,1),xy(:,2),'LineWidth',2,'Color','green');
% Plot beginnings and ends of lines
plot(xy(1,1),xy(1,2),'x','LineWidth',2,'Color','yellow');
plot(xy(2,1),xy(2,2),'x','LineWidth',2,'Color','red');
% Determine the endpoints of the longest line segment
len = norm(lines(k).point1 - lines(k).point2);
if ( len > max_len)
max_len = len;
xy_long = xy;
end
end
% highlight the longest line segment
plot(xy_long(:,1),xy_long(:,2),'LineWidth',2,'Color','blue');
PS: Matlab的例程写的还真不错,以后应该多参考下...
CMU Computer Vision(16720) HW2 Bag-of-Words-based Object Classification
Steps:
1 Representing the World with Visual Words
1.1 Creating Visual Words
1.2 Computing Visual Words
2 Building a Recognition System
2.1 Extracting Features
2.2 Comparing Windows
2.3 Building A Model of the Visual World
2.4 Quantitative Evaluation
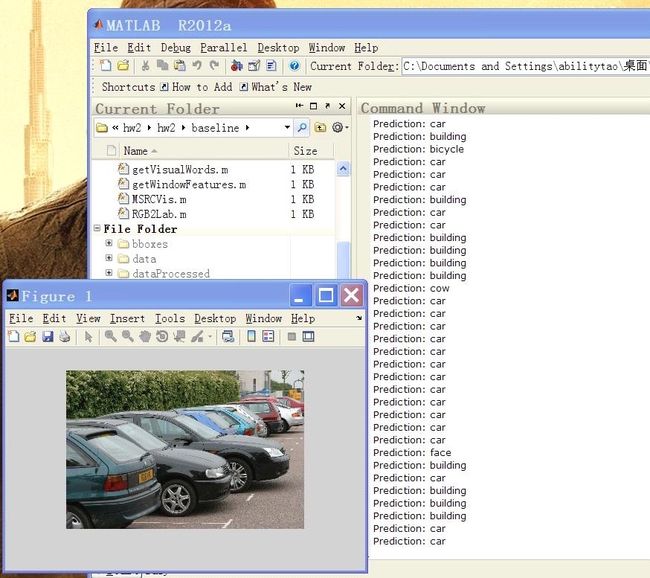
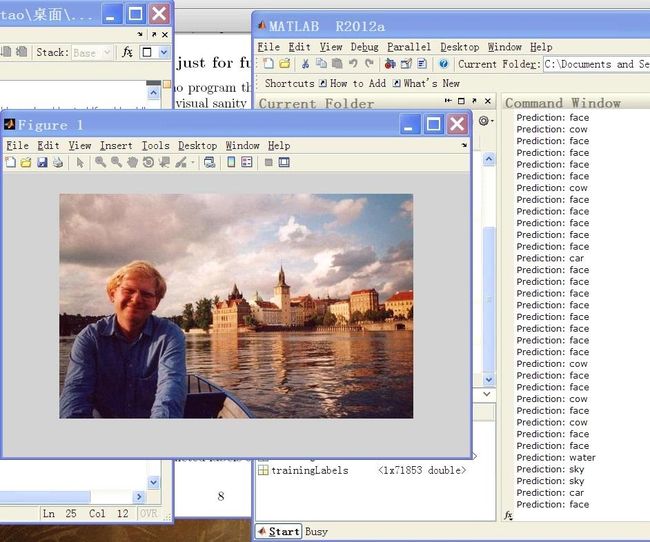
recognition rate is nearly 65%.
SVD分解 (转)
前言:
上一次写了关于PCA与LDA的文章,PCA的实现一般有两种,一种是用特征值分解去实现的,一种是用奇异值分解去实现的。在上篇文章中便是基于特征值分解的一种解释。特征值和奇异值在大部分人的印象中,往往是停留在纯粹的数学计算中。而且线性代数或者矩阵论里面,也很少讲任何跟特征值与奇异值有关的应用背景。奇异值分解是一个有着很明显的物理意义的一种方法,它可以将一个比较复杂的矩阵用更小更简单的几个子矩阵的相乘来表示,这些小矩阵描述的是矩阵的重要的特性。就像是描述一个人一样,给别人描述说这个人长得浓眉大眼,方脸,络腮胡,而且带个黑框的眼镜,这样寥寥的几个特征,就让别人脑海里面就有一个较为清楚的认识,实际上,人脸上的特征是有着无数种的,之所以能这么描述,是因为人天生就有着非常好的抽取重要特征的能力,让机器学会抽取重要的特征,SVD是一个重要的方法。
在机器学习领域,有相当多的应用与奇异值都可以扯上关系,比如做feature reduction的PCA,做数据压缩(以图像压缩为代表)的算法,还有做搜索引擎语义层次检索的LSI(Latent Semantic Indexing)
另外在这里抱怨一下,之前在百度里面搜索过SVD,出来的结果都是俄罗斯的一种狙击枪(AK47同时代的),是因为穿越火线这个游戏里面有一把狙击枪叫做SVD,而在Google上面搜索的时候,出来的都是奇异值分解(英文资料为主)。想玩玩战争游戏,玩玩COD不是非常好吗,玩山寨的CS有神马意思啊。国内的网页中的话语权也被这些没有太多营养的帖子所占据。真心希望国内的气氛能够更浓一点,搞游戏的人真正是喜欢制作游戏,搞Data Mining的人是真正喜欢挖数据的,都不是仅仅为了混口饭吃,这样谈超越别人才有意义,中文文章中,能踏踏实实谈谈技术的太少了,改变这个状况,从我自己做起吧。
前面说了这么多,本文主要关注奇异值的一些特性,另外还会稍稍提及奇异值的计算,不过本文不准备在如何计算奇异值上展开太多。另外,本文里面有部分不算太深的线性代数的知识,如果完全忘记了线性代数,看本文可能会有些困难。
一、奇异值与特征值基础知识:
特征值分解和奇异值分解在机器学习领域都是属于满地可见的方法。两者有着很紧密的关系,我在接下来会谈到,特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。先谈谈特征值分解吧:
1)特征值:
如果说一个向量v是方阵A的特征向量,将一定可以表示成下面的形式:

这时候λ就被称为特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。特征值分解是将一个矩阵分解成下面的形式:

其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。我这里引用了一些参考文献中的内容来说明一下。首先,要明确的是,一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。比如说下面的一个矩阵:
 它其实对应的线性变换是下面的形式:
它其实对应的线性变换是下面的形式:

因为这个矩阵M乘以一个向量(x,y)的结果是:
 上面的矩阵是对称的,所以这个变换是一个对x,y轴的方向一个拉伸变换(每一个对角线上的元素将会对一个维度进行拉伸变换,当值>1时,是拉长,当值<1时时缩短),当矩阵不是对称的时候,假如说矩阵是下面的样子:
上面的矩阵是对称的,所以这个变换是一个对x,y轴的方向一个拉伸变换(每一个对角线上的元素将会对一个维度进行拉伸变换,当值>1时,是拉长,当值<1时时缩短),当矩阵不是对称的时候,假如说矩阵是下面的样子:

它所描述的变换是下面的样子:

这其实是在平面上对一个轴进行的拉伸变换(如蓝色的箭头所示),在图中,蓝色的箭头是一个最主要的变化方向(变化方向可能有不止一个),如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。反过头来看看之前特征值分解的式子,分解得到的Σ矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)
当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个线性变化可能没法通过图片来表示,但是可以想象,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。也就是之前说的:提取这个矩阵最重要的特征。总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
(说了这么多特征值变换,不知道有没有说清楚,请各位多提提意见。)
2)奇异值:
下面谈谈奇异值分解。特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有N个学生,每个学生有M科成绩,这样形成的一个N * M的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
 假设A是一个N * M的矩阵,那么得到的U是一个N * N的方阵(里面的向量是正交的,U里面的向量称为左奇异向量),Σ是一个N * M的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),V’(V的转置)是一个N * N的矩阵,里面的向量也是正交的,V里面的向量称为右奇异向量),从图片来反映几个相乘的矩阵的大小可得下面的图片
假设A是一个N * M的矩阵,那么得到的U是一个N * N的方阵(里面的向量是正交的,U里面的向量称为左奇异向量),Σ是一个N * M的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),V’(V的转置)是一个N * N的矩阵,里面的向量也是正交的,V里面的向量称为右奇异向量),从图片来反映几个相乘的矩阵的大小可得下面的图片

那么奇异值和特征值是怎么对应起来的呢?首先,我们将一个矩阵A的转置 * A,将会得到一个方阵,我们用这个方阵求特征值可以得到: 这里得到的v,就是我们上面的右奇异向量。此外我们还可以得到:
这里得到的v,就是我们上面的右奇异向量。此外我们还可以得到:
 这里的σ就是上面说的奇异值,u就是上面说的左奇异向量。奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
这里的σ就是上面说的奇异值,u就是上面说的左奇异向量。奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:

r是一个远小于m、n的数,这样矩阵的乘法看起来像是下面的样子:

右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵A,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。
二、奇异值的计算:
奇异值的计算是一个难题,是一个O(N^3)的算法。在单机的情况下当然是没问题的,matlab在一秒钟内就可以算出1000 * 1000的矩阵的所有奇异值,但是当矩阵的规模增长的时候,计算的复杂度呈3次方增长,就需要并行计算参与了。Google的吴军老师在数学之美系列谈到SVD的时候,说起Google实现了SVD的并行化算法,说这是对人类的一个贡献,但是也没有给出具体的计算规模,也没有给出太多有价值的信息。
其实SVD还是可以用并行的方式去实现的,在解大规模的矩阵的时候,一般使用迭代的方法,当矩阵的规模很大(比如说上亿)的时候,迭代的次数也可能会上亿次,如果使用Map-Reduce框架去解,则每次Map-Reduce完成的时候,都会涉及到写文件、读文件的操作。个人猜测Google云计算体系中除了Map-Reduce以外应该还有类似于MPI的计算模型,也就是节点之间是保持通信,数据是常驻在内存中的,这种计算模型比Map-Reduce在解决迭代次数非常多的时候,要快了很多倍。
Lanczos迭代就是一种解对称方阵部分特征值的方法(之前谈到了,解A’* A得到的对称方阵的特征值就是解A的右奇异向量),是将一个对称的方程化为一个三对角矩阵再进行求解。按网上的一些文献来看,Google应该是用这种方法去做的奇异值分解的。请见Wikipedia上面的一些引用的论文,如果理解了那些论文,也“几乎”可以做出一个SVD了。
由于奇异值的计算是一个很枯燥,纯数学的过程,而且前人的研究成果(论文中)几乎已经把整个程序的流程图给出来了。更多的关于奇异值计算的部分,将在后面的参考文献中给出,这里不再深入,我还是focus在奇异值的应用中去。
三、奇异值与主成分分析(PCA):
主成分分析在上一节里面也讲了一些,这里主要谈谈如何用SVD去解PCA的问题。PCA的问题其实是一个基的变换,使得变换后的数据有着最大的方差。方差的大小描述的是一个变量的信息量,我们在讲一个东西的稳定性的时候,往往说要减小方差,如果一个模型的方差很大,那就说明模型不稳定了。但是对于我们用于机器学习的数据(主要是训练数据),方差大才有意义,不然输入的数据都是同一个点,那方差就为0了,这样输入的多个数据就等同于一个数据了。以下面这张图为例子:
 这个假设是一个摄像机采集一个物体运动得到的图片,上面的点表示物体运动的位置,假如我们想要用一条直线去拟合这些点,那我们会选择什么方向的线呢?当然是图上标有signal的那条线。如果我们把这些点单纯的投影到x轴或者y轴上,最后在x轴与y轴上得到的方差是相似的(因为这些点的趋势是在45度左右的方向,所以投影到x轴或者y轴上都是类似的),如果我们使用原来的xy坐标系去看这些点,容易看不出来这些点真正的方向是什么。但是如果我们进行坐标系的变化,横轴变成了signal的方向,纵轴变成了noise的方向,则就很容易发现什么方向的方差大,什么方向的方差小了。
这个假设是一个摄像机采集一个物体运动得到的图片,上面的点表示物体运动的位置,假如我们想要用一条直线去拟合这些点,那我们会选择什么方向的线呢?当然是图上标有signal的那条线。如果我们把这些点单纯的投影到x轴或者y轴上,最后在x轴与y轴上得到的方差是相似的(因为这些点的趋势是在45度左右的方向,所以投影到x轴或者y轴上都是类似的),如果我们使用原来的xy坐标系去看这些点,容易看不出来这些点真正的方向是什么。但是如果我们进行坐标系的变化,横轴变成了signal的方向,纵轴变成了noise的方向,则就很容易发现什么方向的方差大,什么方向的方差小了。
一般来说,方差大的方向是信号的方向,方差小的方向是噪声的方向,我们在数据挖掘中或者数字信号处理中,往往要提高信号与噪声的比例,也就是信噪比。对上图来说,如果我们只保留signal方向的数据,也可以对原数据进行不错的近似了。
PCA的全部工作简单点说,就是对原始的空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第1、2个轴正交的平面中方差最大的,这样假设在N维空间中,我们可以找到N个这样的坐标轴,我们取前r个去近似这个空间,这样就从一个N维的空间压缩到r维的空间了,但是我们选择的r个坐标轴能够使得空间的压缩使得数据的损失最小。
还是假设我们矩阵每一行表示一个样本,每一列表示一个feature,用矩阵的语言来表示,将一个m * n的矩阵A的进行坐标轴的变化,P就是一个变换的矩阵从一个N维的空间变换到另一个N维的空间,在空间中就会进行一些类似于旋转、拉伸的变化。

而将一个m * n的矩阵A变换成一个m * r的矩阵,这样就会使得本来有n个feature的,变成了有r个feature了(r < n),这r个其实就是对n个feature的一种提炼,我们就把这个称为feature的压缩。用数学语言表示就是:
 但是这个怎么和SVD扯上关系呢?之前谈到,SVD得出的奇异向量也是从奇异值由大到小排列的,按PCA的观点来看,就是方差最大的坐标轴就是第一个奇异向量,方差次大的坐标轴就是第二个奇异向量…我们回忆一下之前得到的SVD式子:
但是这个怎么和SVD扯上关系呢?之前谈到,SVD得出的奇异向量也是从奇异值由大到小排列的,按PCA的观点来看,就是方差最大的坐标轴就是第一个奇异向量,方差次大的坐标轴就是第二个奇异向量…我们回忆一下之前得到的SVD式子:
 在矩阵的两边同时乘上一个矩阵V,由于V是一个正交的矩阵,所以V转置乘以V得到单位阵I,所以可以化成后面的式子
在矩阵的两边同时乘上一个矩阵V,由于V是一个正交的矩阵,所以V转置乘以V得到单位阵I,所以可以化成后面的式子
 将后面的式子与A * P那个m * n的矩阵变换为m * r的矩阵的式子对照看看,在这里,其实V就是P,也就是一个变化的向量。这里是将一个m * n 的矩阵压缩到一个m * r的矩阵,也就是对列进行压缩,如果我们想对行进行压缩(在PCA的观点下,对行进行压缩可以理解为,将一些相似的sample合并在一起,或者将一些没有太大价值的sample去掉)怎么办呢?同样我们写出一个通用的行压缩例子:
将后面的式子与A * P那个m * n的矩阵变换为m * r的矩阵的式子对照看看,在这里,其实V就是P,也就是一个变化的向量。这里是将一个m * n 的矩阵压缩到一个m * r的矩阵,也就是对列进行压缩,如果我们想对行进行压缩(在PCA的观点下,对行进行压缩可以理解为,将一些相似的sample合并在一起,或者将一些没有太大价值的sample去掉)怎么办呢?同样我们写出一个通用的行压缩例子:
 这样就从一个m行的矩阵压缩到一个r行的矩阵了,对SVD来说也是一样的,我们对SVD分解的式子两边乘以U的转置U'
这样就从一个m行的矩阵压缩到一个r行的矩阵了,对SVD来说也是一样的,我们对SVD分解的式子两边乘以U的转置U'
 这样我们就得到了对行进行压缩的式子。可以看出,其实PCA几乎可以说是对SVD的一个包装,如果我们实现了SVD,那也就实现了PCA了,而且更好的地方是,有了SVD,我们就可以得到两个方向的PCA,如果我们对A’A进行特征值的分解,只能得到一个方向的PCA。
这样我们就得到了对行进行压缩的式子。可以看出,其实PCA几乎可以说是对SVD的一个包装,如果我们实现了SVD,那也就实现了PCA了,而且更好的地方是,有了SVD,我们就可以得到两个方向的PCA,如果我们对A’A进行特征值的分解,只能得到一个方向的PCA。
四、奇异值与潜在语义索引LSI:
潜在语义索引(Latent Semantic Indexing)与PCA不太一样,至少不是实现了SVD就可以直接用的,不过LSI也是一个严重依赖于SVD的算法,之前吴军老师在矩阵计算与文本处理中的分类问题中谈到:
“三个矩阵有非常清楚的物理含义。第一个矩阵X中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大越相关。最后一个矩阵Y中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。中间的矩阵则表示类词和文章雷之间的相关性。因此,我们只要对关联矩阵A进行一次奇异值分解,w 我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。”
上面这段话可能不太容易理解,不过这就是LSI的精髓内容,我下面举一个例子来说明一下,下面的例子来自LSA tutorial,具体的网址我将在最后的引用中给出:
 这就是一个矩阵,不过不太一样的是,这里的一行表示一个词在哪些title中出现了(一行就是之前说的一维feature),一列表示一个title中有哪些词,(这个矩阵其实是我们之前说的那种一行是一个sample的形式的一种转置,这个会使得我们的左右奇异向量的意义产生变化,但是不会影响我们计算的过程)。比如说T1这个title中就有guide、investing、market、stock四个词,各出现了一次,我们将这个矩阵进行SVD,得到下面的矩阵:
这就是一个矩阵,不过不太一样的是,这里的一行表示一个词在哪些title中出现了(一行就是之前说的一维feature),一列表示一个title中有哪些词,(这个矩阵其实是我们之前说的那种一行是一个sample的形式的一种转置,这个会使得我们的左右奇异向量的意义产生变化,但是不会影响我们计算的过程)。比如说T1这个title中就有guide、investing、market、stock四个词,各出现了一次,我们将这个矩阵进行SVD,得到下面的矩阵:
 左奇异向量表示词的一些特性,右奇异向量表示文档的一些特性,中间的奇异值矩阵表示左奇异向量的一行与右奇异向量的一列的重要程序,数字越大越重要。
左奇异向量表示词的一些特性,右奇异向量表示文档的一些特性,中间的奇异值矩阵表示左奇异向量的一行与右奇异向量的一列的重要程序,数字越大越重要。
继续看这个矩阵还可以发现一些有意思的东西,首先,左奇异向量的第一列表示每一个词的出现频繁程度,虽然不是线性的,但是可以认为是一个大概的描述,比如book是0.15对应文档中出现的2次,investing是0.74对应了文档中出现了9次,rich是0.36对应文档中出现了3次;
其次,右奇异向量中一的第一行表示每一篇文档中的出现词的个数的近似,比如说,T6是0.49,出现了5个词,T2是0.22,出现了2个词。
然后我们反过头来看,我们可以将左奇异向量和右奇异向量都取后2维(之前是3维的矩阵),投影到一个平面上,可以得到:
 在图上,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一篇文档,这样我们可以对这些词和文档进行聚类,比如说stock 和 market可以放在一类,因为他们老是出现在一起,real和estate可以放在一类,dads,guide这种词就看起来有点孤立了,我们就不对他们进行合并了。按这样聚类出现的效果,可以提取文档集合中的近义词,这样当用户检索文档的时候,是用语义级别(近义词集合)去检索了,而不是之前的词的级别。这样一减少我们的检索、存储量,因为这样压缩的文档集合和PCA是异曲同工的,二可以提高我们的用户体验,用户输入一个词,我们可以在这个词的近义词的集合中去找,这是传统的索引无法做到的。
在图上,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一篇文档,这样我们可以对这些词和文档进行聚类,比如说stock 和 market可以放在一类,因为他们老是出现在一起,real和estate可以放在一类,dads,guide这种词就看起来有点孤立了,我们就不对他们进行合并了。按这样聚类出现的效果,可以提取文档集合中的近义词,这样当用户检索文档的时候,是用语义级别(近义词集合)去检索了,而不是之前的词的级别。这样一减少我们的检索、存储量,因为这样压缩的文档集合和PCA是异曲同工的,二可以提高我们的用户体验,用户输入一个词,我们可以在这个词的近义词的集合中去找,这是传统的索引无法做到的。
不知道按这样描述,再看看吴军老师的文章,是不是对SVD更清楚了?:-D
参考资料:
1)A Tutorial on Principal Component Analysis, Jonathon Shlens
这是我关于用SVD去做PCA的主要参考资料
2)http://www.ams.org/samplings/feature-column/fcarc-svd
关于svd的一篇概念好文,我开头的几个图就是从这儿截取的
3)http://www.puffinwarellc.com/index.php/news-and-articles/articles/30-singular-value-decomposition-tutorial.html
另一篇关于svd的入门好文
4)http://www.puffinwarellc.com/index.php/news-and-articles/articles/33-latent-semantic-analysis-tutorial.html
svd与LSI的好文,我后面LSI中例子就是来自此
5)http://www.miislita.com/information-retrieval-tutorial/svd-lsi-tutorial-1-understanding.html
另一篇svd与LSI的文章,也还是不错,深一点,也比较长
6)Singular Value Decomposition and Principal Component Analysis, Rasmus Elsborg Madsen, Lars Kai Hansen and Ole Winther, 2004
跟1)里面的文章比较类似
转自:http://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
2-dimensional gauss function with Matlab (使用Matlab绘制二维高斯函数图象)
by using following codes.
%%
X1 = [0:0.1:10];
X2 = [0:0.1:10];
Z = exp(-((X-5).*(X-5)+(Y-5).*(Y-5))/18);
surf(X,Y,Z);
%%
the result is as following...
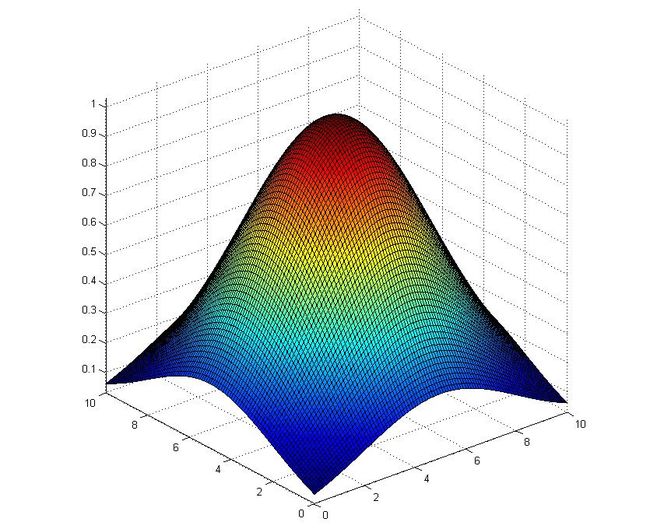
2D gauss function.
and the distribution of 4*(x*y)/pow((x+y),2) is
X1 = [0:1:100];
X2 = [0:1:100];
[X,Y] = meshgrid(X1,X2);
Z = 4*X.*Y./(X+Y)./(X+Y);
surf(X,Y,Z);
the relationship between eigenvalues of Harris Matrix
so we can see along the line y=x the value is maximized.
CMU Computer Vision(16720) HW1 Constructing Panoramas
to create a panorama image.
input:


output:
图像处理和计算机视觉中的经典论文(转)
前言:最近由于工作的关系,接触到了很多篇以前都没有听说过的经典文章,在感叹这些文章伟大的同时,也顿感自己视野的狭小。 想在网上找找计算机视觉界的经典文章汇总,一直没有找到。失望之余,我决定自己总结一篇,希望对 CV 领域的童鞋们有所帮助。由于自己的视野比较狭窄,肯定也有很多疏漏,权当抛砖引玉了,如果你觉得哪篇文章是非常经典的,也可以把相关信息连带你的昵称发给我,我好补上。我的信箱 [email protected]
文章主要来源:PAMI, IJCV, TIP, CVIU, PR, IVC, CVGIU, CVPR, ICCV, ECCV, NIPS, SIGGRAPH, BMVC等
主要参考网站: Google scholar, citeseer, cvpapers, opencv 中英文官方网站
主要参考书籍:
数字图像处理 第三版 冈萨雷斯等
图像处理,分析和机器视觉 第三版 Sonka等(非常非常好的一本书)
学习OpenCV
计算机视觉:算法与应用
文章按时间排序,排名不分先后,^_^。每一行最后一栏是我自己加的注释,如果不喜欢可以无视之,如果有不对的地方还请告诉我,免得继续出丑。 给出的文章有些是从google scholar或者citeseer上拷贝下来的,所以有链接。所有的文章在网上都很容易找到。有空的时候我会把它们全部整理出来,逐步上传到ishare.iask.sina.com
由于整理的很仓促,时间也很短,还有很多不完善的地方。我会不断改进,并不时上传新版本。
上传地址为http://iask.sina.com.cn/u/2252291285/ish?folderid=775855
最后更新:2012/3/14
1990 年之前
| Peter Burt, Edward Adelson |
The Laplacian Pyramid as A Compact Image Code |
虽说这个Laplacian Pyramid是有冗余的,但使用起来非常简单方便,对理解小波变换也非常有帮助。这位Adelson是W.T.Freeman的老板,都是大牛. |
| J Canny |
A Computational Approach to Edge Detection |
经典不需要解释。在 Sonka的书里面对这个算法也有比较详细的描述。 |
| S Mallat. |
A theory for multiresolution signal decomposition: The wavelet representation |
Mallat的代表作 |
| M Kass, A Witkin, D Terzopoulos. |
Snakes: active contour models |
Deformable model的开山鼻祖。 |
| RM HARALICK |
Textural Features for Image Classification |
这三篇都是关于纹理特征的,虽然过去这么多年了,现在在检索和识别中依然很有用。 |
| RM HARALICK |
Statistical and structural approaches |
|
| Tamura等 |
Texture features corresponding to visual perception |
|
| A P Dempster, N M Laird, D B Rubin. 1977 |
Maximum likelihood from incomplete data via the EM algorithm |
EM 算法在计算机视觉中有着非常重要的作用 |
| L Rabiner. 1989 |
A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition |
HMM 同样是计算机视觉必须掌握的一项工具 |
| B D Lucas, T Kanade |
An iterative image registration technique with an application to stereo- vision |
Lucas 光流法 |
| J R Quinlan |
Induction of decision trees |
偏模式识别和机器学习一点 |
1990 年
| P Perona, J Malik. PAMI |
Scale-space and edge detection using anisotropic diffusion |
关于 scale space 最早的一篇论文之一,引用率很高 |
| T Lindeberg |
Scale-space for discrete signals. |
Lindeberg 关于 scale space 比较早的一篇,后续还有好几篇 |
| anzad, A.; Hong, Y.H. |
Invariant image recognition by Zernike moments |
Zernike moment,做过模式识别或者检索的应该都知道这个东东 |
1991 年
| W Freeman, E Adelson. |
The design and use of steerable filters |
Freeman最早的一篇力作,也是我读的第一篇学术论文。现在Freeman在 MIT 风生水起,早已是IEEE Fellow了 |
| Michael J. Swain , Dana H. Ballard |
Color Indexing. |
google scholar 上引用将近五千次 |
| MA Turk CVPR |
Face recognition using eigenfaces |
|
1992 年
| L G Brown. |
A survey of image registration techniques. |
比较早的一篇关于配准的综述了 |
1993 年
| S G Mallat, Z Zhang. |
Matching pursuits with time-frequency dictionaries |
Mallat另一篇关于小波的文章,不研究小波的可以无视之 |
| L Vincent. |
Morphological grayscale reconstruction in image analysis: Applications and efficient algorithms |
|
| DP Huttenlocher |
Comparing images using the Hausdorff distance |
Google scolar 上引用2200多次 |
1994 年
| J Shi, C Tomasi. |
Good feature to track. |
Tomasi这个名字还会出现好几次,真的很牛 |
| Linderberg |
Scale-space theory in computer vision |
|
| J L Barron, D J Fleet, S S Beauchemin. |
Performance of optical flow techniques. |
|
1995 年
| R Malladi, J Sethian, B Vemuri. |
Shape Modeling with Front Propagation: A Level Set Approach |
Level set的经典文章 |
| TF COOTES |
Active Shape Models-Their Training and Application |
ASM |
| MA Stricker |
Similarity of color images |
颜色检索相关 |
| C Cortes, V Vapnik. |
Support-vector networks. |
SVM 在计算机视觉中也有着非常重要的地位 |
1996 年
| T MCINERNEY. |
Deformable models in medical image analysis: A survey |
活动模型的一篇较早的综述 |
| Tai Sing Lee |
Image Representation Using 2D Gabor Wavelets |
Google引用也有近千次 |
| Amir Said, A. Pearlman |
A New, Fast, and Efficient Image Codec Based on Set Partitioning in Hierarchical Tree |
SPIHT。图像压缩领域与 EBCOT齐名的经典算法。 |
| L P Kaelbling, M L Littman, A W Moore. |
Reinforcement learning: A survey |
机器学习里面的一篇综述,引用率比较高,就列在这了。 |
| B. S. Manjunath and W. Y. Ma |
Texture features for browsing and retrieval of image data |
检索的文章比较多,其实它们的应用不仅仅是检索。只要是需要提取特征的地方,检索里面的方法都可以用到 |
| |
comparing images using color coherence vectors |
检索中的CCV方法 |
| |
Image retrieval using color and shape |
关于形状特征后面有一篇综述 |
1997 年
| V Caselles, R Kimmel, G Sapiro. |
Geodesic active contours |
活动轮廓模型的一个小分支 |
| R E Schapire, Y Freund, P Bartlett, W S Lee. |
Boosting the Margin: A New Explanation for the Effectiveness of Voting Methods. |
Schapire 和 Freund 发 明 了Adaboost,给计算机视觉带来了不少经典算法 |
| F Maes, D Vandermeulen, G Marchal, P Suetens. |
Multimodality image registration by maximization of mutual information |
互信息量配准 |
| E Osuna, R Freund, F Girosi. |
Training support vector machines: An application to face detection. |
SVM在人脸检测中的应用。不过人脸检测最经典的方法应 该是Viola-Jones |
| J Huang, S Kumar, M Mitra, W-J Zhu, R Zabih. |
Image indexing using color correlogram |
Color correlogram,检索中的又一个颜色特征。和前面的 CCV 以及颜色矩特征基本上覆盖了所有的颜色特征。 |
| Y Freund, R Schapire. |
A decisiontheoretic generalization of on-line learning and an application to boosting. |
Adaboost的经典文章 |
1998 年
1998 年是图像处理和计算机视觉经典文章井喷的一年。大概从这一年开始,开始有了新的趋势。由于竞争的加剧,一些好的算法都先发在会议上了,先占个坑,等过一两年之后再扩展到会议上。
| T Lindeberg |
Feature detection with automatic scale selection |
Linderberg的 scale space到此为止基本结束了。在一些边缘提取,道路或者血管检测中,scale space 确实是一种很不错的工具 |
| C J C Burges. |
A tutorial on support vector machines for pattern recognition. |
使用 svm的话,这篇文章应该是必读的了。比 95 年那篇原始文章引用率还高 |
| M Isard, A Blake. |
CONDENSATION – Conditional TrackingDensity Propagation for Visual |
Tracking中的经典文章了 |
| L Page, S Brin, R Motwani, T Winograd |
The PageRank citation ranking: bringing order to the web |
这篇文章应该不属于 CV 的范畴,鉴于作者的大名鼎鼎,暂且列在这 |
| C Tomasi, R Manduchi. |
Bilateral filtering for gray and color images. |
做过图像滤波平滑去噪或者 HDR的应该都知道Bilateral filter。原理非常非常简单,简单到一个公式就可以概括这篇文章,简单到实在无法扩充到期刊。这也是 Tomasi 第二次出现了。一直很纳闷,这个很直观的思想在这之前怎么就从来没人提呢。 |
| C Xu, J L Prince. |
Snakes, shapes and gradient vector flow. |
终于碰到中国人写的文章了,很荣幸还是校友。GVF是 snake和levelset领域的重要分支和方法 |
| Wim Sweldens. |
The lifting scheme: A construction of second generation wavelets. |
第二代小波。真正让小波有了实用价值,在 JPEG2000 中就采用的提升小波。个人更喜欢的是下一篇,简单易懂,字体也大 |
| Daubechies Wim Sweldens |
Factoring wavelet transforms into lifting steps |
另一位作者也很牛,小波十讲的作者 |
| H A Rowley, S Baluja, T Kanade. |
Neural Network-based Face Detection. |
做人脸的应该是必看的了。不做人脸的话应该可以不用看吧 |
| J B A Maintz, M A Viergever. |
A survey of medical image registration. |
关于图像配准的另一篇综述 |
| T F Cootes, G J Edwards, C J Taylor. |
Active Appearance Models |
AAM |
1999 年
| D Lowe. |
Object Recognition from Local Scale-invariant Features |
大名鼎鼎的SIFT,后面有一篇IJCV上的 Journal版本,更全面一点。 |
| R E Schapire. |
A brief Introduction to Boosting |
还是 boosting |
| D M Gavrila. |
The visual analysis of human movements: a survey |
综述文章的引用一般都比较高 |
| Y Rui, T S Huang, S F Change. |
Image retrieval: current techniques, promising directions, and open issues |
TSHuang小组对检索的一个总结 |
| J K Aggarwal, Q Cai. |
Human motion analysis: a review |
人体运动分析的一个综述 |
2000 年
世纪之交,各种综述都出来了
| J Shi, J Malik. |
Normalized Cuts and Image Segmentation |
NCuts的引用率相当高,Jianbo Shi也因为这篇文章成为计算机视觉界引用率最高的作者之一 |
| Z Zhang. |
A Flexible New Technique for Camera Calibration |
张正友的关于摄像机标定的经典短文 |
| A K Jain, R P W Duin, J C Mao. |
Statistical pattern recognition: a review. |
统计模式识别综述,这一年 pami上两篇很有名的综述之一。 在这里推荐 Web 写的 Statistical Pattern Recognition第三版,相当不错,网上有电子版。 |
| C Stauffe |
Learning Patterns of Activity Using Real-Time Tracking |
搜 TLD 的时候发现这篇文章引用率也很高,两千多次。还没来得及读。 |
| D Taubman. |
High performance Scalable Image Compression With EBCOT |
EBCOT,JPEG2000 中的算法 |
| A W M Smeulders, M Worring, S Santini, A Gupta, R Jain. |
Content-based image retrieval at the end of the early years |
在世纪之交对图像检索的一篇很权威的综述。感觉在这之后检索的研究也没那么热了。不过在工业界热度依旧,各大网上购物平台,比如淘宝, 亚马逊,京东等都在做这方面的研发,衣服检索是一个很不错的应用点。 |
| M Pantic, L J M Rothkrantz. |
Automatic analysis of facial expressions: the state of the art. |
|
| N Paragios, R Deriche. |
Geodesic active contours and level sets for the detection and tracking of moving objects |
使用 level set做跟踪 |
| Y Rubner, C Tomasi, L Guibas. |
TThe earth mover’s distance as a metric for image retrieval. |
EMD算法。Tomasi再次出现 |
| |
PicToSeek Combining Color and Shape Invariant Features for Image Retrieval |
依然是检索特征 |
2001 年
| Paul Viola, Michael J Jones. |
Robust real-time object detection |
这是一篇很牛的文章,在人脸检测上几乎成了标准。比较坑爹的是,号称发在IJCV2001 上,但怎么找也找不到。应该是 IJCV2004年的那篇“Robust real-time face detection”吧。 他们在这一年另一篇比较出名的文章是在CVPR上的“Rapid ObjectDetection using a Boosted Cascade of Simple Features”这篇才是04年那篇著名文章的会议版。 |
| Y Boykov, Kolmogorov. |
An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. |
俄罗斯人在 graph cut 领域开始发力了 |
| T Moeslund, E Granum. |
A Survey of Computer Vision Based Human Motion Capture |
人体运动综述 |
| T F Chan, L Vese. |
Active contours without edges. |
Snake 和 level set领域的经典文章 |
| A M Martinez, A C Kak. |
PCA versus LDA |
PCA 也是计算机视觉中非掌握不可的工具。LDA在模式识别中有很重要的地位 |
| BS Manjunath |
Color and texture descriptors |
颜色和纹理的描述子,在识别中很有用 |
2002 年
| D Comaniciu, P Meer. |
Mean shift: A robust approach toward feature space analysis. |
Mean shift的经典文章。前两天发现 Comaniciu 已经是 IEEE Fellow了 |
| Ming-Husan Yang, David J Kriegman, Narendra Ahuja. |
Detecting Faces in Images: A Survey. |
人脸检测综述,引用率想不高都难 |
| R Hsu, M Abdel-Mottaleb. |
Face Detection in Color Images. |
依然是人脸检测,名字都起得这么霸气 |
| J-L Starck, E J Candès, D L Donoho. |
The curvelet transform for image denoising. |
Geometrical wavelet 中的一篇代表 作 。 其 他 的 如 ridgelet, contourlet, bandelet 等在这里就不赘述了。研究这方面的很容易找到这方面的经典文献。个人以为不研究这方面的看了后对自己的研究也不会有多大启发。曾经以为这个方向会很火,到最后还是没火起来。 我觉得原因可能是现在存储和传输能力的大大提高,使得对压缩的需求没有那么大了,这方面的研究自然就停滞了,就如同JPEG2000没有成气候 |
| |
Shape matching and object recognition using shape contexts |
Shape context。用形状匹配达到目标识别目的。这方面最经典的文章了。随后后续也有一些这方面的文章,但基本都是很小的改进或者应用。作者提供了原码,可以在 matlab上运行看看效果。 |
| N Paragios, R Deriche. |
Geodesic active regions and level set methods for supervised texture segmentation |
|
| |
Statistical Color Models with Application to Skin Detection |
|
| |
A tutorial on particle filters for online nonlinear non-Gaussian Bayesian tracking |
particle filter 的一个综述 |
2003 年
| W Zhao, R Chellappa, P J Phillips, A Rosenfeld. |
Face recognition: A literature survey. |
人脸检测的综述 |
| J Sivic, A Zisserman. |
Video Google: A text retrieval approach to object matching in videos. |
好像是Visual words的起源文章。引用率很高,先列出来再看。 |
| D Comaniciu, V Ramesch, P Meer. |
Kernel-Based Object Tracking. |
基于核的跟踪。 |
| B Zitová, J Flusser. |
Image registration methods: A survey. |
又一篇图像配准的综述。做图像配准的比较有福气,综述很多 |
| K Mikolajczyk, C Schmid. |
A performance evaluation of local descriptors. |
比较各种描述子的,包括SIFT |
| M J Wainwright, M I Jordan. |
Graphical models, exponential families, and variational inference. |
乔丹的名气太大,不露露脸说不过去 |
| J Portilla, V Strela, M Wainwright, E Simoncelli. |
Image denoising using scale mixtures of gaussians in the wavelet domain. |
图像去噪,小波变换,混合高斯 |
| Robert E. Schapire |
The Boosting Approach to Machine Learning An Overview |
boosting作者自己写的综述,自然值得一看。 |
2004 年
| |
Lucas-Kanade 20 Years On A Unifying Framework |
引用文章摘要的第一句话Since the Lucas-Kanade algorithm was proposed in 1981 image alignment has become one of the most widely used techniques in computer vision. Applications range from optical flow and tracking to layered motion, mosaic construction, and face coding. |
| D G Lowe. |
Distinctive image features from scale-invariant keypoints. |
SIFT,不解释 |
| Chih-ChungChang,Chih-Jen Lin. |
LIBSVM: A library for support vectormachines |
我实在怀疑引用这篇文章的人是否都看过这篇文章。貌似不看这篇文章也可以使用 LIBSVM |
| Z Wang, A C Bovik, H R Sheikh, E P Simoncelli. |
Image quality assessment: From error visibility to structural similarity |
图像质量评价,最近 Bovik 还有一篇类似的文章也刊登在 TIP上 |
| Y Ke, R Sukthankar. |
Pca-sift: a more distinctive representation for local image descriptors |
SIFT 的变形 |
| |
Review of shape representation and description techniques |
|
| |
Efficient Graph-Based Image Segmentation |
|
2005 年
| N Dalal, B Triggs. |
Histograms of oriented gradients for human detection. |
HOG 虽然很新,但很经典 |
| A C Berg, T L Berg, J Malik. |
Shape matching and object recognition using low distortion correspondences. |
还是 shape matching |
| S Roth, M Black. |
Fields of experts: A framework for learning image priors. |
这篇应该要归结到图像统计特性的范畴吧 |
| Z Tu, X Chen,A L Yuille, S C Zhu. |
Image parsing: Unifying segmentation, detection, and recognition. |
|
| |
Geodesic active regions and level set methods for motion estimation and tracking |
|
| Chunming Li, Chenyang Xu, Changfeng Gui, and Martin D. Fox |
Level Set Evolution Without Re-initialization: A New Variational Formulation |
这篇文章解决了level set中需要不停的重初始化的问题。在 2010 年的 TIP上有一篇 Journal版本 Distance Regularized Level Set Evolution and its Application to Image Segmentation |
| |
A Performance Evaluation of Local Descriptors |
前面那篇是会议的,这篇是 PAMI上的。比较各种描述子的,包括SIFT |
2006 年
| D Donoho. |
Compressed sensing. |
CS 压缩感知 最近很火的一个名词 |
| Greg Welch, Gary Bishop. |
An introduction to the Kalman Filter. |
kalman滤波 |
| S Lazebnik, C Schmid, J Ponce. |
Beyond bags of features: spatial pyramid matching for recognizing natural scene categories. |
Visual words |
| Xiaojin Zhu. |
Semi-supervised learning literature survey. |
|
| A Yilmaz, O Javed, M Shah. |
Object Tracking: A survey. |
tracking的一篇综述 |
| |
Image Alignment and Stitching: A Tutorial |
|
2007 年
| |
A Review of Statistical Approaches to Level Set Segmentation: Integrating Color, Texture, Motion and Shape |
|
| |
The Appearance of Human Skin: A Survey |
|
| |
Local Invariant Feature Detectors: A Survey |
|
2008 年
| H Bay, A Ess, T Tuytelaars, L V Gool. |
SURF: Speeded Up Robust Features. |
|
| K E A van de Sande, T Gevers, C G M Snoek. |
Evaluation of Color Descriptors for Object and Scene Recognition |
|
| M Yang |
A Survey of Shape Feature Extraction Techniques |
虽然这篇文章的引用率目前来看并不高,但个人认为这是一篇在shape feature方面很不错的文章 |
| P.Felzenszwalb, D. McAllester, D. Ramanan |
A Discriminatively Trained, Multiscale, Deformable Part Model |
2008 年的 CVPR,到现在引用已有四百多次,潜力巨大。rosepink提供 |
2009 年
| J Wright, A Y Yang, A Ganesh, S S Sastry, Ma. |
Robust Face Recognition via Sparse Representation. |
|
| B Settles. |
Active learning literature survey |
|
2010 年
2011 年
| |
Hough Forests for Object Detection, Tracking, and Action Recognition |
|
| |
Robust Principal Component Analysis? |
Candes 和 UIUC 的Ma Yi等人 |
2012 年
| Zdenek Kalal, Krystian Mikolajczyk,and Jiri Matas, |
Tracking-Learning-Detection |
PAMI上的,虽然还没有正式发表,但肯定会火。在作者的主页上有几篇相关的会议文章, demo和code。用到了 Lucas-Kanade方法 |
| |
|
|
A summary about the Computer Vision Industry
http://www.cs.ubc.ca/~lowe/vision.html
时间管理 PPT
最近学习了时间管理相关的知识,这是我的报告PPT.
/Files/abilitytao/TimeManagement.ppt
数学公式的英文读法
这些你都知道吗?以后给老外作报告的时候可千万别再“The equation is like this…”, “The value is like this…”
有些公式不好写,能看出来什么意思就行了。
1.Logic
∃there exist
∀for all
p⇒q p implies q / if p, then q
p⇔q p if and only if q /p is equivalent to q / p and q are equivalent
2.Sets
x∈A x belongs to A / x is an element (or a member) of A
x∉A x does not belong to A / x is not an element (or a member) of A
A⊂B A is contained in B / A is a subset of B
A⊃B A contains B / B is a subset of A
A∩B A cap B / A meet B / A intersection B
A∪B A cup B / A join B / A union B
A\B A minus B / the diference between A and B
A×B A cross B / the cartesian product of A and B
3. Real numbers
x+1 x plus one
x-1 x minus one
x±1 x plus or minus one
xy xy / x multiplied by y
(x-y)(x+y) x minus y, x plus y
= the equals sign
x=5 x equals 5 / x is equal to 5
x≠5 x (is) not equal to 5
x≡y x is equivalent to (or identical with) y
x>y x is greater than y
x≥y x is greater than or equal to y
xx is less than y
x≤y x is less than or equal to y
0zero is less than x is less than 1
0≤x≤1 zero is less than or equal to x is less than or equal to 1
|x| mod x / modulus x
x2 x squared / x (raised) to the power 2
x3 x cubed
x4 x to the fourth / x to the power 4
xn x to the nth / x to the power n
x (−n) x to the (power) minus n
x的平方根(square) root x / the square root of x
x的三次根cube root (of) x
x的四次根fourth root (of) x
x的n次根nth root (of) x
(x+y)2 x plus y all squared
n! n factorial
x^x hat
x¯ x bar
x˜ x tilde
xi xi / x subscript i / x suffix i / x sub i
∑(i=1~n) ai the sum from i equals one to n ai / the sum as i runs from 1 to n of the ai
4. Linear algebra
‖x‖the norm (or modulus) of x
OA→OA / vector OA
OA¯ OA / the length of the segment OA
AT A transpose / the transpose of A
A−1 A inverse / the inverse of A
5. Functions
f(x) fx / f of x / the function f of x
f:S→T a function f from S to T
x→y x maps to y / x is sent (or mapped) to y
f’(x) f prime x / f dash x / the (first) derivative of f with respect to x
f”(x) f double-prime x / f double-dash x / the second derivative of f with respect to x
f”’(x) triple-prime x / f triple-dash x / the third derivative of f with respect to x
f (4) (x) f four x / the fourth derivative of f with respect to x
∂f/∂x1 the partial (derivative) of f with respect to x1
∂2f/∂x12 the second partial (derivative) of f with respect to x1
∫0∞ the integral from zero to infinity
limx→0the limit as x approaches zero
limx→0+the limit as x approaches zero from above
limx→0−the limit as x approaches zero from below
logey log y to the base e / log to the base e of y / natural log (of) y
lny log y to the base e / log to the base e of y / natural log (of) y