决策树-->预测泰坦尼克号哪些人可以幸存
决策树–>预测泰坦尼克号哪些人可以幸存
1、数据地址
https://datahub.csail.mit.edu/download/jander/historic/file/titanic.csv
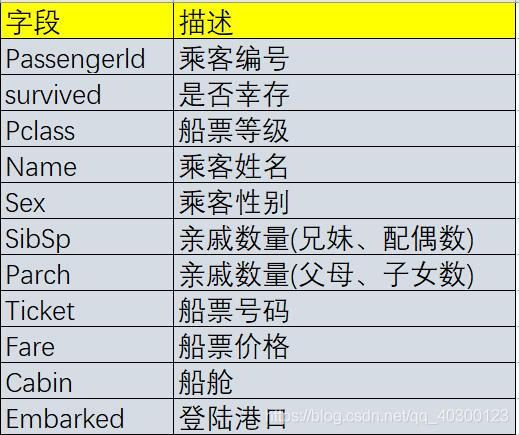
数据描述
2、实验目标
通过对决策树算法对泰坦尼克号历史数据进行学习,学习幸存用户所具备的一些特性,从而指导对未来沉船时哪些用户的预测。(假设场景)
3、编写代码
首先导入pandas 库用于读取数据以及对数据的基本操纵
# 导入库
import numpy as np
import pandas as pd
# 读取数据
titanic = pd.read_csv('./train.csv')
titanic.head() #查看数据集的前五行
# 导入missingo库查看缺失值分布,绘图时需要依赖于matplotlib.pyplot
# missingo库用户查看缺失值分布
import missingno
import matplotlib.pyplot as plt
missingno.bar(titanic)

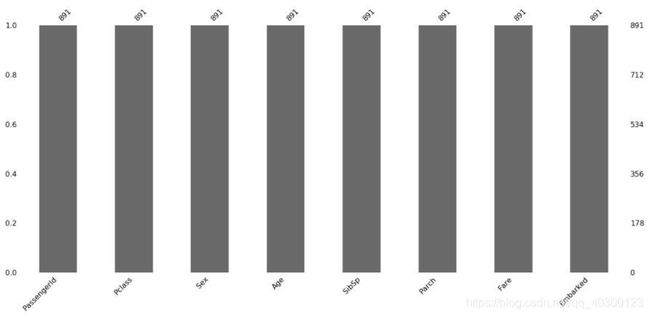
通过missingo绘制的柱状图发现数据存在缺失值,对存在缺失值的数据进行处理。
# 缺失值处理
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].mean()) #使用均值填充
titanic['Embarked'] = titanic['Embarked'].fillna('S') #S为Embarked出现次数最对的值所以对缺失值使用众数填充
# 缺失值填充后的数据
missingno.bar(titanic)
 删除不相关数据。
删除不相关数据。
此处删除不相关数据时为认为判断,还可以更换为使用特征选择中的方法进行选择,比如使用皮尔逊相关系数。
titanic_drop_data = titanic.drop(['Cabin','Name','Survived','Ticket'],axis=1) #axis表示按列删除
再次观察数据,
missingno.bar(titanic_drop_data)
 通过图片可以发现不想关列已经被删除掉了。
通过图片可以发现不想关列已经被删除掉了。
为了方便后续建模对数据进行编码,此处选择的方式时独热编码,将字符型数据转换为数值型。
# 数据预处理-->独热编码
dummy_enconded_data = pd.get_dummies(titanic_drop_data)
数据挖掘准备工作
# 指定类标号,告知分类器按照哪些类比进行划分
y_target = titanic['Survived'].values
y_target
# 指定建模数据
x_feature = dummy_enconded_data.values
拆分出训练集和测试集,训练集进行建模,测试集对模型准确率进行验证。
# 导入训练集测试集拆分模块
from sklearn.model_selection import train_test_split
# 拆分数据
# 训练集 测试集 训练集标号 测试集标号
x_train,x_test,y_train,y_test = train_test_split(x_feature,y_target,test_size=0.3,random_state=1)
进行数据建模
# 导入决策树算法模块
from sklearn import tree
# 构建模型 决策树属性选择方式 数据的深度
tree_one = tree.DecisionTreeClassifier(criterion='gini',max_depth=5)
tree_one.fit(x_train,y_train)
模型测试
# 模型测试
tree_one_zq = tree_one.score(x_test,y_test)
out = tree_one_zq*100
print(round(out,3),'%')