pd.concat 和 np.concatenate(全网最细)
目录
1: pd.concat 和 np.concatenated的异同
2: np.concatenate
3: pd.concat(理解:数据合并与重塑)
3.1 行拼接
3.2 列拼接
3.2.0 axis=1
3.2.1 join='inner'
3.2.2 reindex
3.3 拼接过程中增加键
引子:
在使用决策树完成实验 的过程中 一个类 需要 产生5000一个二元高斯分布o和400个均匀分布的o
用数组X (列表存储的是一维数据,而数组则能存储多维数据)
X = np.random.multivariate_normal(mean1, cov, int(5000))#生成一个多元正态分布矩阵
X = np.concatenate((X, 20*np.random.rand(400,2)))以往都是用concat 新的函数concatenate 引发了我的思考,
1: pd.concat 和 np.concatenated的异同
同:都是一种可以是实现拼接的函数
异:
concat是对于df DataFrame数据类型的拼接函数 在pandas库内可以查询
concatencate是对于数组的拼接函数 在numpy库内可以查询
2: np.concatenate
np.concatenate 是numpy中对array进行拼接的函数
先看文档 以下:
numpy.concatenate((a1, a2, ...), axis=0, out=None, dtype=None, casting="same_kind")¶对于一维数组拼接,axis的值不影响最后的结果
axis =1 axis=1为行数不变列拼接
axis =0 axis=0为列数不变行拼接
参数
A1,A2,…阵列序列
数组必须具有相同的形状,除了与 axis (默认为第一个)。
axis可选的
阵列将沿其连接的轴。如果“轴”为“无”,则阵列在使用前将被展平。默认值为0。
outndarray,可选
如果提供,则为放置结果的目的地。形状必须正确,与未指定out参数时concatenate返回的形状匹配。
dtypeSTR或D型
如果提供,目标数组将具有此数据类型。不能与一起提供 out .
1.20.0 新版功能.
casting'no'、'equiv'、'safe'、'same'u kind'、'unsafe'、可选
控制可能发生的数据转换类型。默认为“同类”。
1.20.0 新版功能.
实例:1
# 行数不变,列数相加
a=np.array([[1,2,3]])
b=np.array([[11,21]])
d = np.concatenate((a,b),axis=1) # 默认情况下,axis=0可以不写
print(d)

2:
# 列数不变,行数相加
a=np.array([[1,2,3],[4,5,6]])
b=np.array([[11,21,31]])
d = np.concatenate((a,b),axis=0) # 默认情况下,axis=0可以不写
print(d)

3
更多实例

补充:
numpy.append()和numpy.concatenate()两个函数的运行时间进行比较的 话,numpy.concatenate()效率更高,适合大规模的数组拼接。
3: pd.concat(理解:数据合并与重塑)
文档中的介绍 pd.concat( objs, axis=0, join="outer", ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True, )参数:
objs: series,dataframe或者是panel构成的序列lsit
axis: 需要合并链接的轴,0是行,1是列
join:{'inner','outer',默认为'outer'。如何处理其他轴上的索引。外部表示联合,内部表示交叉。keys:序列,默认无。
levels;序列列表,默认无。用于构造多索引的特定级别(唯一值)。否则,将从键推断出它们。
names:列表,默认无。结果层次索引中级别的名称。
varify_integrity:布尔值,默认值为False。检查新连接轴是否包含重复项。相对于实际的数据串联,这可能非常昂贵。
copy:布尔值,默认为True。如果为False,请不要不必要地复制数据。
以下根据pandas文档内容介绍concat用法
3.1 行拼接
concat()函数(位于pandas主命名空间中)执行所有繁重的操作,即沿一个轴执行串联操作,同时在其他轴上执行索引(如果有)的可选集合逻辑(并集或交集)。请注意,我之所以说“如果有的话”,是因为串联只有一个可能的串联轴。
在深入了解concat的所有细节及其功能之前,下面是一个简单的示例:
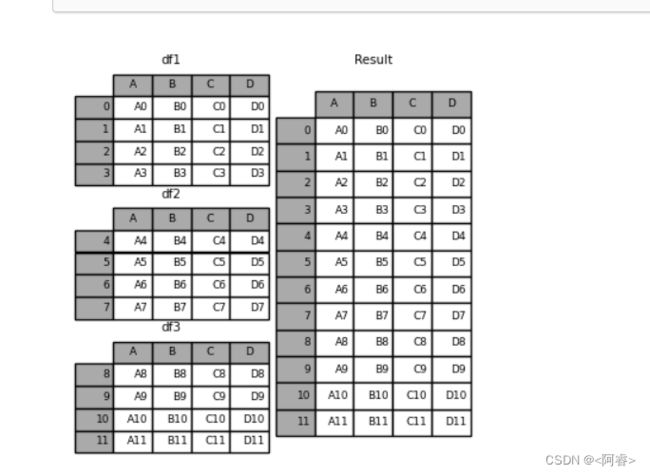
例1:axis =0 列数不变 行拼接|| 相同字段的表首尾相接
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)df2 = pd.DataFrame(
{
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
},
index=[4, 5, 6, 7],
)
df3 = pd.DataFrame(
{
"A": ["A8", "A9", "A10", "A11"],
"B": ["B8", "B9", "B10", "B11"],
"C": ["C8", "C9", "C10", "C11"],
"D": ["D8", "D9", "D10", "D11"],
},
index=[8, 9, 10, 11],
)df4 = pd.DataFrame(
{
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
},
index=[2, 3, 6, 7],
)
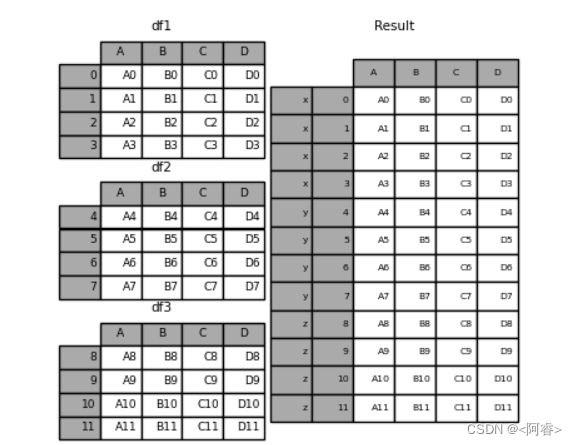
frames = [df1, df2, df3] #[ ] 列表中有3个df数据类型
result = pd.concat(frames)#concat中axis 默认为0 ,即列不变 行拼接
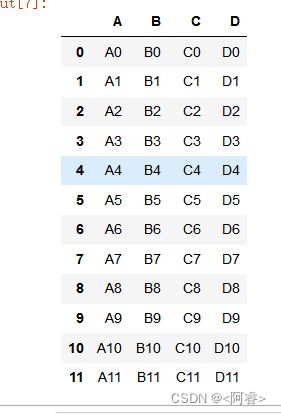
文档中给出的解释
心中有图 撸码自然神
3.2 列拼接
3.2.0 axis=1
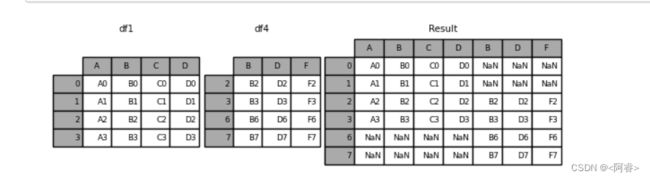
例2 :axis =1 行数不变 列拼接
result = pd.concat([df1, df4], axis=1)

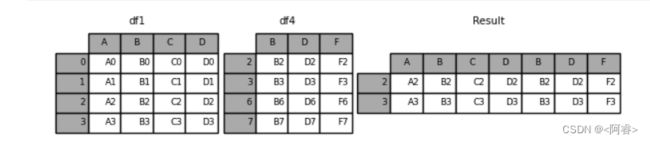
3.2.1 join='inner'
join参数的属性,如果为’inner’得到的是两表的交集,如果是outer,得到的是两表的并集(默认为outer)
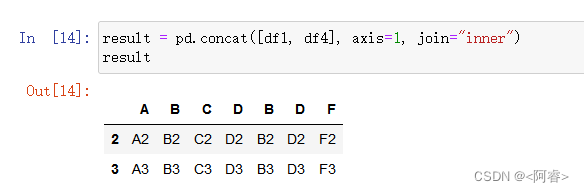
result = pd.concat([df1, df4], axis=1, join="inner")
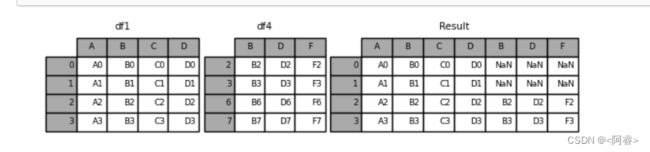
3.2.2 reindex
如果有join_axes的参数传入,可以指定根据那个轴来对齐数据
例如:根据df1表对齐数据,就会保留指定的df1表的轴,然后将df4的表与之拼接
pd.concat([df1, df4.reindex(df1.index)], axis=1) 或者
pd.concat([df1, df4], axis=1).reindex(df1.index)

3.3 拼接过程中增加键
例2:key的理解 :合并的同时增加区分数据组的键 frames = [df1, df2, df3] #[ ] 列表中有3个df数据类型 result = pd.concat(frames, keys=["x", "y", "z"])