TFHE拓展:Programmable Bootstrapping
Improved Programmable Bootstrapping with Larger Precision and Efficient Arithmetic Circuits for TFHE(对TFHE优化的可编程同态刷新的方案,拥有高精度和高效率)
索引
- Improved Programmable Bootstrapping with Larger Precision and Efficient Arithmetic Circuits for TFHE(对TFHE优化的可编程同态刷新的方案,拥有高精度和高效率)
-
- 摘要
- 引言
-
- TFHE
- P B S \mathbf{PBS} PBS
- P B S \bf PBS PBS的缺陷:
- 贡献
- 背景知识
-
- G L W E \sf GLWE GLWE
- G L e v \sf GLev GLev
- G G S W \sf GGSW GGSW
- K e y S w i t c h i n g \sf KeySwitching KeySwitching
- P B S \bf PBS PBS算法思路
- TFHE Circuit Bootstrapping
- 构造模块
-
- L W E \sf LWE LWE乘法
- 一般化的 P B S \bf PBS PBS
- 进阶的 P B S \bf PBS PBS
-
- 第一种方法:
- 第二种方法
- 多输出的 P B S \bf PBS PBS
- 应用
-
- 固定点数
- 快速Circuit Bootstrapping
- 同态Decomp
- 总结
摘要
TFHE的Bootstrapping(同态刷新),除了减少噪音外,还可以运算一个单变量函数(用查找表LUT的方式)。然而,它需要预先知道明文的最高位,从而导致损失了一个位的空间来存储信息。此外,在许多使用情况下,它的计算开销很大。
在本文中,我们提出了一个解决方案来克服上述限制,我们称之为可编程的无填充同态刷新(Programmable Bootstrapping Without Padding WoP-PBS)。这种方法依赖于两个构建模块。第一个是BFV乘法,我们将其纳入TFHE。有充分的噪声分析来证明,使用TFHE的参数可以正确的进行BFV乘法。第二个构件是本文介绍的TFHE同态刷新的一般化。它提供了灵活性,可以在同态刷新过程中选择加密明文中的任何块位。当工作的精度足够小时,它还能同时评估许多LUT。所有这些改进在一些应用中特别有帮助,如布尔电路的评估(在每个被评估的门中不再需要自举),更普遍的是,即使有大的整数,也能有效评估算术电路。这些结果也改善了TFHE电路的同态刷新。此外,我们还表明,现在可以使用比TFHE的参数小得多的参数来同态刷新大精度的整数。
引言
TFHE是一种支持高效同态刷新的(R)LWE-based FHE方案。最初是对FHEW方案的一种优化,后来也加入了别的一些技术来提高效率。TFHE的高效性来自于他们选取的参数是非常小的,支持使用CPU内带的64位整形来表示出来,因此可以达到非常好的效率。
TFHE
TFHE加密形式:
TFHE使用将加密的消息放在最高位,对于消息 m ∈ Z m\in \Z m∈Z,加噪后的明文看起来就是 Δ ⋅ m + e m o d q \Delta \cdot m + e\bmod q Δ⋅m+emodq。其中 m m m的精度位大小为 p = log 2 ( q Δ ) p=\log_2(\frac{q}{\Delta}) p=log2(Δq)。可以通过下图来形式化地理解一下:

在这里 p = 7 p=7 p=7,最高位(蓝色部分)为消息,最低位(红色部分)为噪声。
P B S \mathbf{PBS} PBS
可编程同态刷新(Programmable Bootstrapping P B S \mathbf{PBS} PBS):
TFHE的同态刷新过程很高效,但其实也同时是可编程的,也就是说,可以在降低密文的噪声的同时,对明文运算一个单变量的函数 f f f。类似 L W E ( m + e ) → P B S L W E ( f ( m + e ) + e ′ ) \mathsf{LWE}(m+e)\stackrel{\mathbf{PBS}}{\rightarrow}\mathsf{LWE}(f(m+e)+e') LWE(m+e)→PBSLWE(f(m+e)+e′),因为使用LUT进行刷新,这里的 f f f可以是任意的函数(不局限于多项式)。具体的方法是将 f f f的LUT编码为一个多项式,然后通过同态地旋转查找表来得到 f ( m + e ) f(m+e) f(m+e),通常在 P B S \mathbf{PBS} PBS中,需要将LUT中的临近的几位设置为相同的系数,使得 f ( m + e ) = f ( m ) f(m+e)=f(m) f(m+e)=f(m)。
一次同态刷新运算多个函数:
文章1中有提到一种在一个密文上同时运算多个函数的技术, { f i } i \{f_i\}_i {fi}i,每个函数都被编码为一个多项式 P i P_i Pi,可以生成一个共享多项式 Q Q Q使得 P i = Q ⋅ P i ′ P_i = Q\cdot P_i' Pi=Q⋅Pi′,并计算 C T o u t ← P B S ∗ ( c t i n , B S K , Q ) {\sf CT_{out}}\gets {\bf PBS}^*({\sf ct_{in}, BSK},Q) CTout←PBS∗(ctin,BSK,Q),然后可以用 C T o u t \sf CT_{out} CTout去乘 P i ′ P_i' Pi′来得到运算不同函数的结果。
这种方法的一个缺点在于输出的密文的噪声与 P i ′ P_i' Pi′有关。
P B S \bf PBS PBS的缺陷:
- 总的来说,要刷新某个密文,要使得它的最高位为0,除非函数 f f f具有自反性质(所谓的自反性质指 f ( m ) = − f ( m + q / 2 ) f(m)=-f(m+q/2) f(m)=−f(m+q/2),要避免自反性就要求 m < q / 2 m
m<q/2
,即最高位为0)。 - 对于超过6位精度的密文来说,就无法高效地进行刷新操作了。每次能刷新的精度与 N N N有关,要想要增加精度就要扩大 N N N,而扩大 N N N会非常影响效率。
- P B S \bf PBS PBS过程对于多线程并不友好,因为它使用了一个累加器一遍遍地加。
- 对于两个 L W E \sf LWE LWE密文没有一个非常原生的方法来做乘法,有两种手段来最乘法:(1)使用 P B S \bf PBS PBS来运算 f : x ↦ x 2 4 f:x \mapsto \frac{x^2}{4} f:x↦4x2,可以调用两次这样的 P B S \bf PBS PBS来运算 x ⋅ y = ( x + y ) 2 4 − ( x − y ) 2 4 x \cdot y = \frac{(x+y)^2}4{-\frac{(x-y)^2}{4}} x⋅y=4(x+y)2−4(x−y)2;(2)调用一次 P B S \mathbf{PBS} PBS来将 G L W E \sf GLWE GLWE密文变为 G G S W \sf GGSW GGSW密文,然后执行一次 G G S W ⊙ G L W E → G L W E \sf GGSW \odot GLWE \to GLWE GGSW⊙GLWE→GLWE外积运算来得到乘积的密文。因为两种方法都要使用 P B S \bf PBS PBS,因此都受到条件1,2的限制。
- 因为1和2的限制存在,没有一个比较好的方法,将一个密文消息同态地分片。
- P B S \bf PBS PBS每次只可以运行一个函数 f f f,采用1中的方法,可以一次执行多个函数,但输出的噪声会与函数有关。
- TFHE可以有效地执行同态布尔电路,然而,这种方法需要在每个二进制电路中都进行一次 P B S \bf PBS PBS,那么运算就会很慢。而且TFHE没有提供支持比1比特大的整数的算数电路运算。
- TFHE电路的同态刷新需要 ℓ \ell ℓ次 P B S \bf PBS PBS,以及很多次 K e y S w i t c h \sf KeySwitch KeySwitch,就会非常的慢。
贡献
这篇文章解决了上述的TFHE的限制。
首先,他们扩展了TFHE的 P B S \bf PBS PBS,现在可以不引入额外噪声的情况下一次执行多个函数了。这种方法适用于明文非常小的情况。这种方法解决了限制6和8。
其次,他们分析了BFV类型的LWE乘法+重现性化的噪声增长,找到了适合TFHE的参数来运算BFV类型的乘法+重线性化,而不是通过 P B S \bf PBS PBS来做乘法。这就解决了限制4。
基于这种乘法,他们定义了一种新的 P B S \bf PBS PBS方案,这种 P B S \bf PBS PBS不需要消息的最高位为0,解决了限制1,并且这种新的 P B S \bf PBS PBS方案可以由多个子 P B S \bf PBS PBS并行运算得到,支持多线程操作,解决了限制3。不同于CHIMERA以及PEGASUS这样的方案,这篇文章在TFHE中加入了BFV类型的乘法,因此就可以全程保留在TFHE的状态下,而不需要去转换。
由新的 P B S \bf PBS PBS方案可以构造一个同态的 d e c o m p o s e \sf decompose decompose(分块)方案,解决了限制5,而且也解除了每个布尔门都需要 P B S \bf PBS PBS的限制7。
由上述的 P B S \bf PBS PBS方法和 h o m o m o r p h i c d e c o m p o s e \sf homomorphic~decompose homomorphic decompose方法,可以运算超过6比特的数。解决了限制2。
背景知识
这里主要介绍几个文章中的符号,首先 R q = Z q [ X ] / ( X N + 1 ) \mathfrak{R}_q=\Z_q[X]/(X^N+1) Rq=Zq[X]/(XN+1)多项式环大家都比较熟悉了。
G L W E \sf GLWE GLWE
然后这篇文章将 L W E , R L W E \sf LWE, RLWE LWE,RLWE融合成了一个 G L W E \sf GLWE GLWE表示,具体来说为:
C T = ( A 1 , ⋯ , A k , B = ∑ i = 1 k A i ⋅ S i + ⌊ M ⋅ Δ ⌉ q + E ) = G L W E S ( M ⋅ Δ ) ∈ R q k + 1 {\sf CT} = (A_1,\cdots,A_k,B=\sum_{i=1}^kA_i\cdot S_i + \lfloor M \cdot \varDelta \rceil_q + E)={\sf GLWE}_{\bf S}(M\cdot \varDelta) \in \mathfrak{R}_{q}^{k+1} CT=(A1,⋯,Ak,B=i=1∑kAi⋅Si+⌊M⋅Δ⌉q+E)=GLWES(M⋅Δ)∈Rqk+1
其中 S = ( S 1 , ⋯ , S k ) ∈ R q k {\bf S}=(S_1,\cdots,S_k)\in \mathfrak{R}_{q}^k S=(S1,⋯,Sk)∈Rqk要么是一个{0,1},要么是{-1,0,1}中均匀分布的密钥。
对于 G L W E {\sf GLWE} GLWE密文来说,当 N = 1 N=1 N=1的时候这就是一个 L W E \sf LWE LWE密文,当 N > 1 , k = 1 N>1,k=1 N>1,k=1的时候这就是一个 R L W E \sf RLWE RLWE密文。
G L e v \sf GLev GLev
其实 G L e v \sf GLev GLev密文就是对 G L W E \sf GLWE GLWE密文的分解,形式如同:
C T ‾ = ( C T 1 , ⋯ , C T ℓ ) = G L e v S B , ℓ ∈ R q ℓ × ( k + 1 ) \overline{\sf CT}=({\sf CT}_1,\cdots ,{\sf CT}_{\ell}) = {\sf GLev}_{\bf S}^{\mathfrak{B},\ell}\in \mathfrak{R}_q^{\ell \times(k+1)} CT=(CT1,⋯,CTℓ)=GLevSB,ℓ∈Rqℓ×(k+1)
其中 C T i = G L W E ( M ⋅ q B i ) {\sf CT}_i={\sf GLWE}(M\cdot \frac{q}{\mathfrak{B}^i}) CTi=GLWE(M⋅Biq),是对于 M M M的基为 B \mathfrak{B} B的分解。
再定义一个分解算法。对于一个基 B ∈ N ∗ \mathfrak{B}\in \N^* B∈N∗, x ∈ Z q x\in\Z_q x∈Zq:
d e c ( B , ℓ ) ( x ) = ( x 1 , ⋯ , x ℓ ) ∈ Z q ℓ {\sf dec}^{(\mathfrak{B},\ell)}(x)=(x_1,\cdots,x_{\ell})\in \Z_q^{\ell} dec(B,ℓ)(x)=(x1,⋯,xℓ)∈Zqℓ
满足
⟨ d e c ( B , ℓ ) ( x ) , ( q B 1 , ⋯ , q B ℓ ) ⟩ = ⌊ x ⋅ B ℓ q ⌉ ⋅ q B ℓ ∈ Z q \langle {\sf dec}^{(\mathfrak{B},\ell)}(x),\big(\frac{q}{\mathfrak{B}^1},\cdots,\frac{q}{\mathfrak{B}^{\ell}} \big)\rangle=\left\lfloor x\cdot\frac{\mathfrak{B}^\ell}{q} \right\rceil \cdot \frac{q}{\mathfrak{B}^\ell} \in \Z_q ⟨dec(B,ℓ)(x),(B1q,⋯,Bℓq)⟩=⌊x⋅qBℓ⌉⋅Bℓq∈Zq
可以类似地定义一个对整数多项式的分解 X ∈ R q X\in \mathfrak{R}_q X∈Rq:
d e c ( B , ℓ ) ( X ) = ( X 1 , ⋯ , X ℓ ) ∈ R q ℓ {\sf dec}^{(\mathfrak{B},\ell)}(X)=(X_1,\cdots,X_{\ell})\in \mathfrak{R}_q^{\ell} dec(B,ℓ)(X)=(X1,⋯,Xℓ)∈Rqℓ
⟨ d e c ( B , ℓ ) ( X ) , ( q B 1 , ⋯ , q B ℓ ) ⟩ = ⌊ X ⋅ B ℓ q ⌉ ⋅ q B ℓ ∈ R q \langle {\sf dec}^{(\mathfrak{B},\ell)}(X),\big(\frac{q}{\mathfrak{B}^1},\cdots,\frac{q}{\mathfrak{B}^{\ell}} \big)\rangle=\left\lfloor X \cdot\frac{\mathfrak{B}^\ell}{q} \right\rceil \cdot \frac{q}{\mathfrak{B}^\ell} \in \mathfrak{R}_q ⟨dec(B,ℓ)(X),(B1q,⋯,Bℓq)⟩=⌊X⋅qBℓ⌉⋅Bℓq∈Rq
G G S W \sf GGSW GGSW
G G S W \sf GGSW GGSW其实就是多个 G L e v \sf GLev GLev密文结合,令 S = ( S 1 , ⋯ , S k ) ∈ R q k {\bf S}=(S_1,\cdots ,S_k) \in \mathfrak{R}_q^k S=(S1,⋯,Sk)∈Rqk,则 G G S W \sf GGSW GGSW密文为:
C T ‾ ‾ = ( C T ‾ 1 , ⋯ , C T ‾ k + 1 ) = G G S W S ( B , ℓ ) ( M ) ∈ R q ( k + 1 ) × ℓ × ( k + 1 ) \overline{\overline{\sf CT}}=(\overline{\sf CT}_1,\cdots ,\overline{\sf CT}_{k+1})={\sf GGSW}_{\bf S}^{(\mathfrak{B},\ell)}(M) \in \mathfrak{R}_q^{(k+1)\times \ell \times (k+1)} CT=(CT1,⋯,CTk+1)=GGSWS(B,ℓ)(M)∈Rq(k+1)×ℓ×(k+1)
其中 C T ‾ i = G L e v S ( B , ℓ ) ( − S i ⋅ M ) 。 \overline{\sf CT}_i={\sf GLev}_{\bf S}^{(\mathfrak{B},\ell)}(-S_i\cdot M)。 CTi=GLevS(B,ℓ)(−Si⋅M)。
当 N = 1 N=1 N=1时,这就是个 G S W \sf GSW GSW密文,当 N > 1 , k = 1 N>1,k=1 N>1,k=1时,这是一个 R G S W \sf RGSW RGSW密文。
K e y S w i t c h i n g \sf KeySwitching KeySwitching
KeySwitching算是全同态加密当中最重要的一个组件了,没有这个好多事情都做不了。KeySwitching会需要一个 KSK,看一下这篇文章中的三种定义:
K S K = { C T ‾ i = G L e v S ′ B , ℓ ( s i ) 1 ≤ i ≤ n } {\sf KSK}=\{\overline{\sf CT}_i={\sf GLev}_{\bf S'}^{\mathfrak{B},\ell}(s_i)_{1 \le i \le n} \} KSK={CTi=GLevS′B,ℓ(si)1≤i≤n}。 s = ( s 1 , ⋯ , s n ) ∈ Z q n {\bf s}=(s_1,\cdots,s_n)\in\Z_q^n s=(s1,⋯,sn)∈Zqn是输入的LWE密钥, S ′ = ( S 1 ′ , ⋯ , S k ′ ) ∈ R q k {\bf S'}=(S'_1,\cdots,S_k')\in \mathfrak{R}_q^k S′=(S1′,⋯,Sk′)∈Rqk是输出的GLWE密钥。定义一个LWE-to-GLWE转换:
- C T o u t ← P r i v a t e K S ( { c t i } i ∈ { 1 , … , p } , K S K ) \mathsf{CT}_{\mathsf{out }} \leftarrow \mathbf{PrivateKS}\left(\left\{\mathsf{ ct }_{i}\right\}_{i \in\{1, \ldots, p\}}, \mathsf{KSK}\right) CTout←PrivateKS({cti}i∈{1,…,p},KSK),这里的KeySwitch和之前的都不太一样,在转换密钥的同时还是运算一个函数 f f f,具体的输入为 { c t i = L W E s ( m 1 ) } i ∈ { 1 , . . . , p } \{{\sf ct}_i = {\sf LWE}_{\bf s}(m_1)\}_{i\in\{1,...,p\}} {cti=LWEs(m1)}i∈{1,...,p},输出为 C T o u t = G L W E S ′ ( f ( m 1 , ⋯ m p ) ) {\sf CT}_{\sf out}={\sf GLWE}_{\bf S'}(f(m_1,\cdots m_p)) CTout=GLWES′(f(m1,⋯mp))。
- C T o u t ← P u b l i c K S ( { c t i } i ∈ { 1 , … , p } , K S K , f ) \mathsf{CT}_{\mathsf {out }} \leftarrow \mathbf{PublicKS}\left(\left\{\mathsf{ct}_{i}\right\}_{i \in\{1, \ldots, p\}}, \mathsf{KSK}, f\right) CTout←PublicKS({cti}i∈{1,…,p},KSK,f),Public和Private的区别在于Public中的 f f f是公开的。Private中时私有的。
- C T o u t ← P a c k i n g K S ( { c t j } j = 1 p , { i j } j = 1 p , K S K ) \mathsf{CT}_{\mathsf {out }} \leftarrow \mathbf{PackingKS}\left(\left\{\mathsf{ct}_{j}\right\}_{j=1}^{p},\left\{i_{j}\right\}_{j=1}^{p}, \mathsf{KSK}\right) CTout←PackingKS({ctj}j=1p,{ij}j=1p,KSK),PackingKeySwitch的区别在于它运算的 f f f是给定的,为 f ( { m j } j = 1 p → ∑ j = 1 p m j ⋅ X i j ) f(\{m_j\}_{j=1}^{p}\to \sum_{j=1}^{p}m_j\cdot X^{i_j}) f({mj}j=1p→∑j=1pmj⋅Xij)。
这三个算法来自TFHE2017 Asiacrypt那篇,具体可以参考那个。
P B S \bf PBS PBS算法思路
P B S \bf PBS PBS分为三步:
第一步: M o d u l u s S w i t c h i n g \sf Modulus~Switching Modulus Switching,将一个在 Z q n + 1 \Z_q^{n+1} Zqn+1上的 L W E ( m ) {\sf LWE}(m) LWE(m)密文缩减到 Z 2 N n + 1 \Z_{2N}^{n+1} Z2Nn+1上,这里可以参考FHEW的Bootstrapping过程,只支持模 2 N 2N 2N大小的密文。
第二步:使用 B l i n d R o t a t i o n \sf Blind Rotation BlindRotation(其实和FHEW里面的Refresh算法差不多,可以参考一下)得到一个 G L W E ( f ( m ) ) ∈ R q {\sf GLWE}(f(m))\in\mathfrak{R}_q GLWE(f(m))∈Rq密文。
第三步:通过一个 e x t r a c t \sf extract extract算法将 G L W E \sf GLWE GLWE密文提取为 L W E \sf LWE LWE密文。
对PBS感兴趣可以看一下这篇 TOTA: Fully Homomorphic Encryption with Smaller Parameters and Stronger Security
TFHE Circuit Bootstrapping
在TFHE2017的文章里面有讲如何做Circuit Bootstrapping,可以在降低噪声的同时将LWE密文转换文GGSW密文。
但是一次Circuit Bootstrapping需要使用 ℓ \ell ℓ次的 P B S \bf PBS PBS以及 ( k + 1 ) ℓ (k+1)\ell (k+1)ℓ次的 P r i v a t e K S \mathbf{PrivateKS} PrivateKS,是通过像搭积木一样把GLWE密文搭成一个GGSW密文,感觉效率会很慢。
构造模块
L W E \sf LWE LWE乘法
首先定义一个 G L W E M u l t \bf GLWEMult GLWEMult,由乘法和一次relinearize组成。

单个 L W E \sf LWE LWE乘法:
有了 G L W E \sf GLWE GLWE的乘法之后,就可以通过将 L W E \sf LWE LWE先转换为 G L W E \sf GLWE GLWE,然后调用 G L W E M u l t \bf GLWEMult GLWEMult做乘法,最后通过 S a m p l e E x t r a c t \bf SampleExtract SampleExtract将 L W E \sf LWE LWE从 G L W E \sf GLWE GLWE中提取出来。

这里刚开始不太明白为什么要用两次KeySwitch以及一次GLWE乘法+Relin和一次Extract来做LWE之间的乘法,难道会比LWE原生的乘法要快吗?我觉得应该是为了能够计算后面的Packed LWE乘法。但这种PackedLWEMult应该也要满足 α ( α + 1 ) < k N \alpha(\alpha+1) < kN α(α+1)<kN的限制。
多个 L W E \sf LWE LWE乘法:
可以通过简单的修改算法2,让其可以单次计算多个 L W E \sf LWE LWE密文的乘积。
令输入为 { c t i ( 1 ) } = { L W E S ( m i ( 1 ) ⋅ Δ 1 ) } ( 0 ≤ i < α ) , { c t i ( 2 ) } = { L W E S ( m i ( 2 ) ⋅ Δ 2 ) } ( 0 ≤ i < α ) \{{\sf ct}_i^{(1)}\}=\{{\sf LWE}_{\bf S}(m_i^{(1)}\cdot \varDelta_1)\}_{}(0\le i < \alpha),\{{\sf ct}_i^{(2)}\}=\{{\sf LWE}_{\bf S}(m_i^{(2)}\cdot \varDelta_2)\}_{}(0\le i < \alpha) {cti(1)}={LWES(mi(1)⋅Δ1)}(0≤i<α),{cti(2)}={LWES(mi(2)⋅Δ2)}(0≤i<α)。
只需要修改算法2的2,3步,将2的Index从 { 0 } \{0\} {0}改为 I 1 = { 0 , 1 , 2 , ⋯ , α − 1 } 。 \mathcal{I}_1=\{0,1,2,\cdots,\alpha-1\}。 I1={0,1,2,⋯,α−1}。,将3的Index从 { 0 } \{0\} {0}改为 I 2 = { 0 , α , 2 α , ⋯ , ( α − 1 ) α } \mathcal{I}_2=\{0,\alpha,2\alpha,\cdots,(\alpha-1)\alpha\} I2={0,α,2α,⋯,(α−1)α}。可以算一下这样最后GLWE密文中的第 i ⋅ ( α + 1 ) i \cdot(\alpha+1) i⋅(α+1)项就是 m i ( 1 ) ⋅ m i ( 2 ) ⋅ Δ o u t m_i^{(1)}\cdot m_i^{(2)}\cdot \varDelta_{\sf out} mi(1)⋅mi(2)⋅Δout。
多个 L W E \sf LWE LWE乘累加:
只要简单的修改一下上面的index,改为 I 1 = { 0 , 1 , 2 , ⋯ , α − 1 } \mathcal{I}_1=\{0,1,2,\cdots,\alpha-1\} I1={0,1,2,⋯,α−1}, I 2 = { α − 1 , α − 2 , α − 3 , ⋯ , 0 } \mathcal{I}_2=\{\alpha-1,\alpha-2,\alpha-3,\cdots,0\} I2={α−1,α−2,α−3,⋯,0},那么结果的 G L W E \sf GLWE GLWE中的第 α − 1 \alpha-1 α−1项就 ∑ 0 ≤ i < α ( m i ( 1 ) m i ( 2 ) ⋅ Δ o u t ) \sum_{0\le i<\alpha}(m_i^{(1)}m_{i}^{(2)}\cdot \varDelta_{\sf out}) ∑0≤i<α(mi(1)mi(2)⋅Δout)。
文中还有一个做PackedSquare的,和PackedMult同样思路,就不写了。
一般化的 P B S \bf PBS PBS
在TFHE(以及FHEW)中,他们的 P B S \bf PBS PBS都是只刷出一个MSB(为了做Bootstrapping),而其实 P B S \bf PBS PBS可以刷新一段消息中的任何位置,而且一次 P B S \bf PBS PBS可以同时对这一段位置执行多个函数。为了形式化地表达这种能力,这篇文章引入了两个额外的参数 ϰ \varkappa ϰ和 ϑ \vartheta ϑ。其中 ϰ \varkappa ϰ表示在 P B S \bf PBS PBS刷新的那段消息前面的没被刷新的消息个数, ϑ \vartheta ϑ表示可以批量执行 2 ϑ 2^{\vartheta} 2ϑ个函数。

这张图可以理解一下一般化的 P B S \bf PBS PBS以及上述两个参数,将一个密文中包含的phase展开为二进制 ( Δ M + e ) (\Delta M+e) (ΔM+e),其中 M M M为原始消息,很显然,消息部分由于乘了 Δ \varDelta Δ,所以在高位,而噪声在低位,只要噪声没有达到蓝色部分-1的位置,即 ∣ e ∣ < Δ / 2 |e|<\varDelta/2 ∣e∣<Δ/2,就可以正确解密。
对于 P B S \bf PBS PBS来说,他的有效空间是模 2 N 2N 2N的,所以图中只有绿色部分的消息可以进入 P B S \bf PBS PBS,而由于刷出来的消息是 f ( m + e ) f(m+e) f(m+e),因此要使得 f ( m + e ) = f ( m ) f(m+e)=f(m) f(m+e)=f(m)这个性质满足,也就是不能刷 2 N 2N 2N这么大的数,有噪声存在,可以看到图中每次只能刷 5 5 5比特。而刷出来的密文后面本应该有6位的噪声(应该Output中后面六位是红的),但这里为了实现批量运算 2 ϑ 2^{\vartheta} 2ϑ个函数的功能,手动将后面 ϑ \vartheta ϑ位设为 0 0 0。
在介绍 G e n P B S \bf GenPBS GenPBS前要先说一下为什么一般化的 P B S \bf PBS PBS函数会没办法一起刷最高位。对于编码为 2 N 2N 2N上的多项式 f : Z 2 N → Z f:\Z_{2N}\to\Z f:Z2N→Z的函数来说,输入为 ( 0 , 1 , . . . , 2 N − 1 ) (0,1,...,2N-1) (0,1,...,2N−1),做 P B S \bf PBS PBS时需要将这个函数打包为一个多项式 P = f ( 0 ) − f ( N − 1 ) X − ⋯ − f ( 1 ) X ( N − 1 ) ∈ R q P=f(0)-f(N-1)X-\cdots - f(1)X^{(N-1)}\in R_q P=f(0)−f(N−1)X−⋯−f(1)X(N−1)∈Rq。而我们的 R q R_q Rq是模 X N + 1 X^N+1 XN+1的,所以对于 f ( i ) f(i) f(i)来说,我们计算 P ⋅ X i P\cdot X^i P⋅Xi,这个多项式的常数项为 f ( i ) f(i) f(i),但考虑到他只有模 X N + 1 X^N+1 XN+1,而 f f f的定义域在 2 N 2N 2N上。所以会满足一个自反的性质: X N = − 1 X^N=-1 XN=−1,即 f ( x + N ) = − f ( x ) f(x+N)=-f(x) f(x+N)=−f(x)。因此 x > N x>N x>N的时候,得到的是 − f ( x − N ) -f(x-N) −f(x−N),即有效位只有 log N − 1 \log N-1 logN−1。
可以看下面这张图,最后能刷的只有 m ′ m' m′,得到的结果是 ( − 1 ) β ⋅ m ′ (-1)^{\beta}\cdot m' (−1)β⋅m′。

那么来看一下本文的 G e n P B S \bf GenPBS GenPBS流程。

很标准的过程,modulusSwitch+BlindRotate(Accumulation)+Extract。值得注意的是这里的modulusSwitch是把最后的 2 ϑ 2^{\vartheta} 2ϑ位给空出来了,为了之前说的批量执行 2 ϑ 2^{\vartheta} 2ϑ个函数。
注意到这里的 P B S \bf PBS PBS刷新出来的结果并非 f ( m ) f(m) f(m),而是 ( − 1 ) β ⋅ f ( m ′ ) (-1)^{\beta}\cdot f(m') (−1)β⋅f(m′)。

我们先假设 ϑ = 0 \vartheta=0 ϑ=0,其实就有效位来说,其实只有 d d d比特 ( m ′ ) (m') (m′)。而非 d + 1 d+1 d+1比特 ( m ) (m) (m)。他所有运算的函数都要满足 f ( x + N ) = − f ( x ) f(x+N)=-f(x) f(x+N)=−f(x)的自反性性质。
进阶的 P B S \bf PBS PBS
现在的目的是把前面的一位 β \beta β所带来的自反性去掉。来看一下这篇文章是如何做的。作者管具有这种性质的 P B S \bf PBS PBS叫做PBS with out Padding W o p ⋅ P B S \bf Wop·PBS Wop⋅PBS。
第一种方法:
分别使用两次 P B S \bf PBS PBS刷新出 ( − 1 ) β ⋅ f ( m ′ ) (-1)^{\beta}\cdot f(m') (−1)β⋅f(m′)以及 ( − 1 ) β (-1)^{\beta} (−1)β,再将两者相乘就可以得到 f ( m ′ ) f(m') f(m′)的结果了。 P B S \bf PBS PBS可以用来得到 ( − 1 ) β (-1)^{\beta} (−1)β,就直接令 f ( x ) = 1 ( 0 ≤ x < N ) , − 1 ( N ≤ x < 2 N ) f(x)=1(0\le x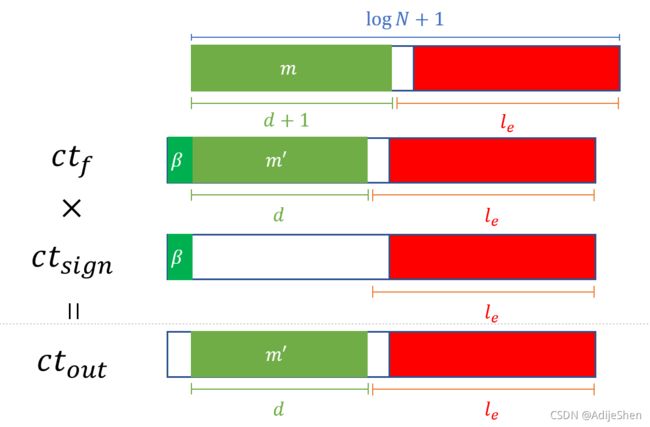
其实他的这样做之后的有效位还是d位,只是避免了翻转。
看一下算法怎么写的:

需要用两次 P B S \bf PBS PBS分别刷出 c t f = L W E ( ( − 1 ) β ⋅ m ′ ⋅ Δ o u t ) {\sf ct}_{\sf f}={\sf LWE}((-1)^{\beta}\cdot m'\cdot \varDelta_{\sf out}) ctf=LWE((−1)β⋅m′⋅Δout)。以及 c t s i g n = L W E ( ( − 1 ) β ) {\sf ct_{sign}}={\sf LWE}((-1)^{\beta}) ctsign=LWE((−1)β)。然后要做一次 L W E \sf LWE LWE的乘法。感觉来说优点在于两个 P B S \bf PBS PBS可以并行计算,缺点是也是只能刷 d d d比特,而且用乘法的噪声会比较大。
第二种方法

第二种方法是弄两个函数,分别对应 β = 0 \beta=0 β=0和 β = 1 \beta=1 β=1的情况,然后用过乘法来做选择,劣势在于需要用到3个 P B S \bf PBS PBS,这样做的好处在于可以刷新 d + 1 d+1 d+1个比特。
具体的方案如下:
多输出的 P B S \bf PBS PBS
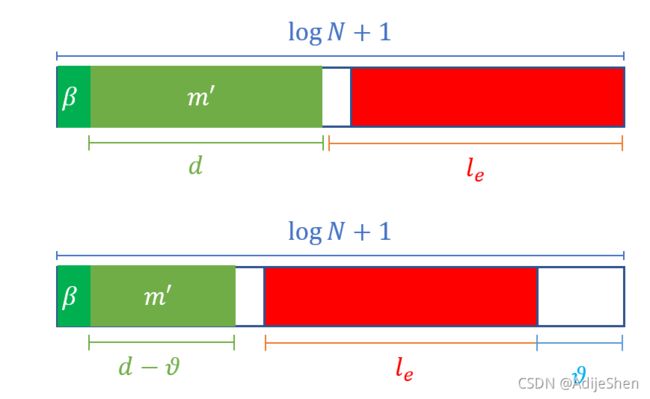
在编码多项式的时候,原本对于 f ( m ′ ) f(m') f(m′)我们的LUT是如下的:
f ( 0 ) , f ( 0 ) X , f ( 0 ) X 2 , f ( 0 ) X 3 , . . . , f ( 2 d − 1 ) X N − 3 , f ( 2 d − 1 ) X N − 2 , f ( 2 d − 1 ) X N − 1 f(0),f(0)X,f(0)X^2,f(0)X^3,...,f(2^d-1)X^{N-3},f(2^d-1)X^{N-2},f(2^d-1)X^{N-1} f(0),f(0)X,f(0)X2,f(0)X3,...,f(2d−1)XN−3,f(2d−1)XN−2,f(2d−1)XN−1
这样子做的话在查询常数项的时候会得到 f ( m ′ + e ) = f ( m ′ ) f(m'+e)=f(m') f(m′+e)=f(m′)。因为相邻几位的LUT是相同的,所以噪声不影响查询的结果。
那如果我们令噪声的最后几位(举例为1位)固定为0。
将LUT编码为
f 0 ( 0 ) , f 1 ( 0 ) X , f 0 ( 1 ) X 2 , f 1 ( 1 ) X 3 , . . . , f 0 ( 2 d − 1 − 1 ) X N − 2 , f 1 ( 2 d − 1 − 1 ) X N − 1 f_0(0),f_1(0)X,f_0(1)X^2,f_1(1)X^3,...,f_0(2^{d-1}-1)X^{N-2},f_1(2^{d-1}-1)X^{N-1} f0(0),f1(0)X,f0(1)X2,f1(1)X3,...,f0(2d−1−1)XN−2,f1(2d−1−1)XN−1
那么查询最后结果的常数项为 f 0 ( x ) f_0(x) f0(x),1项为 f 1 ( x ) f_1(x) f1(x),也就可以通过多次的extract将多输出的结果提取出来。
但这样做法会缩小函数的有效位。如图所示:
算法如下:

值得注意的是上面两个 W o p ⋅ P B S \bf Wop·PBS Wop⋅PBS也可以采用 P B S m a n y L U T \bf PBSmanyLUT PBSmanyLUT来代替 G e n P B S \bf GenPBS GenPBS来运算多个函数。
应用
固定点数
在应用里提到了固定精度算法,一个精度为p的数,密文表示为 c t i = L W E ( m i ⋅ q 2 p ) {\sf ct}_i={\sf LWE}(m_i \cdot \frac{q}{2^p}) cti=LWE(mi⋅2pq)。用整数 m i ∈ [ 0 , 2 p ) m_i\in [0,2^p) mi∈[0,2p)来表示一个精度为p的小数。
那对于一个固定点数的exact算法,就是每次做完加法和乘法之后(精度变为2p),把最低位p个数拿出来减掉,就重新回到了p位。

但这样做也有限制,因为一次刷新要把整个精度位p刷出来,所以能支持的精度位比较小。
要扩大精度位这篇文章也提出了方法,就是从最低位开始,每次刷p中的一部分,然后减去这一部分,重复上述步骤,直到刷到需要的精度为止。
快速Circuit Bootstrapping
Circuit Bootstrapping是在[CGGI17]中提出的,是将一个 R L W E ( μ ) \sf RLWE(\mu) RLWE(μ)刷为 R G S W ( μ ) {\sf RGSW}(\mu) RGSW(μ),是通过执行 ℓ \ell ℓ次Bootstrapping得到 ℓ \ell ℓ个 R L W E ( μ q B j ) 1 ≤ j ≤ ℓ {\sf RLWE}(\mu \frac{q}{\mathfrak{B}^j})_{1\le j\le \ell} RLWE(μBjq)1≤j≤ℓ密文,然后将 ℓ \ell ℓ个 R L W E \sf RLWE RLWE组合成一个 R G S W \sf RGSW RGSW。
在这篇文章里,可以用 P B S m a n y L U T \bf PBSmanyLUT PBSmanyLUT同时刷出 ℓ \ell ℓ个 R L W E \sf RLWE RLWE,那就有了 ℓ \ell ℓ倍的加速。
同态Decomp

除此之外,使用 W o P − P O S \bf WoP-POS WoP−POS还可以在密文上进行Decomp算法。这个很好理解。
总结
这篇文章主要的贡献就在于解决 P B S \bf PBS PBS的自反性吧。以及提出了一些可能的应用。
New techniques for multi-value input homomorphic evaluation and applications. ↩︎ ↩︎