经典树结构——B+树的原理及实现
文章目录
-
- B+树的概念
- B+树实现
-
- B+树节点参数
- B+树的查询
-
- 实现
- B+树插入
-
- 实现
- B+树删除
-
- 实现
B+树的概念
规则:
- B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加
- B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样
- B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针
- 非叶子节点的子节点数=关键字数(来源百度百科)(Mysql 的B+树)
B+树相比于B树的优点
- 由于B+树在内部节点上不好含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子几点上关联的数据也具有更好的缓存命中率;
- B+树的叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
总结:B+树的I/O次数更少,磁盘读写代价更低,时间更稳定,范围搜索更好
B+树的存在形式
- 结点内有n个元素就会n个子结点;每个元素是子结点元素里的最大值或最小值。

- 结点内有n个元素就会n+1个子结点;最左边的子结点小于最小的元素,其余的子结点是>=当前元素。

B+树实现
以第一种形式实现
B+树节点参数
protected int degree;//阶数
protected BPlusNode<K,V> parent;//父节点
protected int keyNum;//关键字个数
protected LinkedList<K> keys;//存放数据项的list,K为key
protected boolean isLeaf;//是否为叶子节点
LinkedList<BPlusNode<K,V>> childList;//存放孩子节点list
public BPlusNode(int degree){
if (degree<3) throw new IllegalArgumentException("The BPlusTree degree must be at least three!");
this.degree = degree;
parent=null;
keys= new LinkedList<>();
childList= new LinkedList<>();
}
//查找
abstract BPlusNode<K,V> search(K key);
//删除
abstract BPlusNode<K,V> delete(K key);
//插入
abstract BPlusNode<K,V> insert(K key,V value);
//上溢
protected boolean isOverFlow(){
return keyNum >degree;
}
//下溢
protected boolean isUnderFlow(){
return keyNum<Math.ceil(degree/2.0);
}
```java
public V searchData(K key){
Objects.requireNonNull(key);
var search =(LeafNode<K, V>) root.search(key);
if (search.insertIndex<search.entryKey.size()){
var searchEntry = search.entryKey.get(search.insertIndex);
if (searchEntry.key().equals(key)) return searchEntry.value();
}
return null;
}
B+树的查询
从根节点开始,对根节点关键字使用二分查找, 向下逐层查找,最终找到匹配的叶子节点
比如要查找5
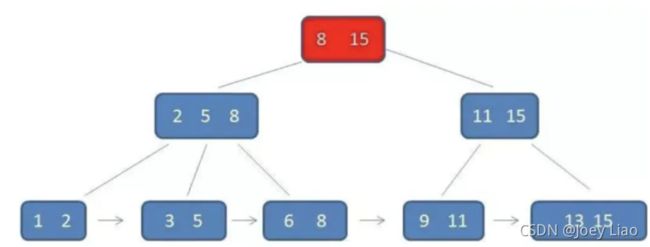
- 从根节点开始,5<8则从左分支向下查找,对应磁盘一次IO
- 找到2 5 8 节点,5>2&&5<=5 则从5对应的分支进行查找,最终定位到5,查找结束
实现
//非叶子节点查找,定位到需要插入的叶子节点
@Override
BPlusNode<K,V> search(K key) {
var insertIndex= Collections.binarySearch(keys, key);
if (this.isLeaf){
return this;
}
insertIndex= insertIndex>=0?insertIndex:-insertIndex-1;
if (childList.size() > 0&&childList.getFirst().keys.size() > 0){
return childList.get(Math.min(insertIndex, keys.size()-1)).search(key);
}
return this;
}
//对叶子节点的key使用二分查找
@Override
LeafNode<K, V> search(K key) {
var searchIndex = Collections.binarySearch(keys, key);
var node=this;
if (searchIndex>=0){
this.insertIndex=searchIndex;//找到保留检索位置为后序删除做铺垫
return this;
}
else{
this.insertIndex=-searchIndex-1;
}
return node;
}
B+树插入
插入的规则:
-
B+树的插入是从叶子节点开始插入 ,且不能破坏关键字自小而大的顺序;
-
由于 B+树中各结点中存储的关键字的个数有明确的范围,做插入操作可能会出现结点中关键字个数超过阶数的情况,此时需要将该结点进行“分裂”;
-
如果插入的关键字是比该节点位置的关键字要大,则需要向父节点更新更新关键字为插入的最大值,直到更新到根节点为止
以3阶B+树为例,对于3阶B+树:上溢 :>3; 下溢:<2
-
若被插入关键字所在的叶子结点,其含有关键字数目小于阶数 M,则直接插入结束;
插入5 8 12
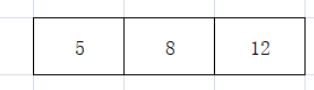
-
在插入 15 导致关键字个数>3 产生上溢;此时需要分裂:
1.将该节点中的8与15上移动到父节点,确保父节点8关键字对应分支的关键字的都比8小,关键字对应的分支节点关键字都比15小。 此时没有则创建父节点8 15 作为根节点
2. 将该节点分裂成【5 8】 【12 15】两部分
3. 将叶子节点用指针进行连接注意:只有是当前父节点为null时才上移动2个节点作为父节点,父节点不为空时则上移动中间节点

-
插入9 20 根据根节点找到对应的叶子节点进行插入,没有产生上溢,直接插入,
但9>叶子节点的8,20>15 ,所以需要向上更新父节点关键字的大小,直到更新到根节点为止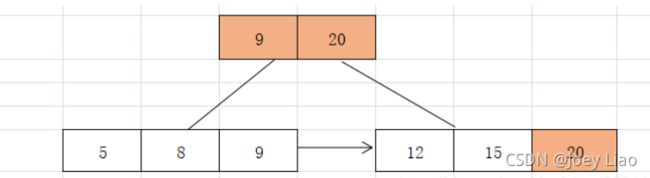
-
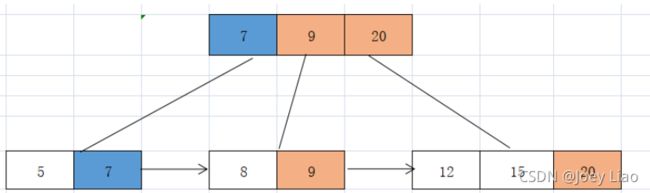
继续插入7 则会导致上溢出,则需要分裂
- 将7 所在的节点中间值mid=7 上移动到父节点
- 对应的节点进行分裂成左右2部分,右边到保留成当前this对象,左边的的则创建新的节点进行保存
- 检查上移动后父节点关键字是否存在上溢,有则需要继续上移动分裂
 5. 继续插入25 则插入20对应的子分支,该节点产生上溢出 ,需要分裂
5. 继续插入25 则插入20对应的子分支,该节点产生上溢出 ,需要分裂- 提取该节点的中间节点mid=15上移动到父节点20的前面插入
- 将该节点分裂成【12 15】【20 25】左右字节点,加入父节点的孩子节点分支中
- 将叶子节点使用指针进行连接形成链表
- 插入的25 关键字大于该节点最大值20.所以需要向上更新父节点的最大值为25,直到根节点为止
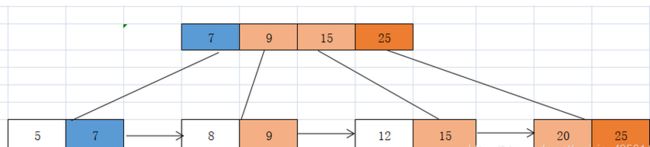 检查该父节点关键字>3产生上溢,所以需要对该父节点继续分裂
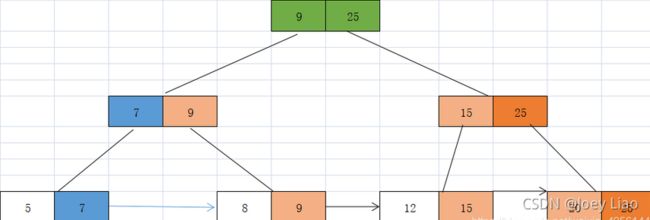
检查该父节点关键字>3产生上溢,所以需要对该父节点继续分裂注意此时上溢节点没有父节点即parent=null,所以我们需要上移动提取9 25 两个节点作为其父节点同时也作为新的根节点,对溢出节点进行分裂【7 9】【20 25】
实现
插入:
public void insert(K key, V value){
Objects.requireNonNull(key);
if (root.keys.isEmpty()){
root = root.insert(key,value);
}
else {
root=root.search(key).insert(key, value);
}
}
分裂:
protected BPlusNode<K, V> splitNode() {
var mid = degree / 2;
K upKey = keys.get(mid);
var sibling = this.isLeaf ? new LeafNode<K, V>(degree) : new NotLeafNode<K, V>(degree);
var nodeParent = this.parent == null ? new NotLeafNode<K, V>(degree) : this.parent;
sibling.keys = new LinkedList<>(keys.subList(0, mid + 1));
keys = new LinkedList<>(keys.subList(mid + 1, keyNum));
if (this instanceof LeafNode<K, V> cur && sibling instanceof LeafNode<K, V> sib){
sib.entryKey = new LinkedList<>(cur.entryKey.subList(0, mid + 1));
cur.entryKey = new LinkedList<>(cur.entryKey.subList(mid + 1, keyNum));
}
else {
sibling.childList = new LinkedList<>(childList.subList(0, mid + 1));
childList = new LinkedList<>(childList.subList(mid + 1, keyNum));
updateChildPoints(sibling);
}
sibling.parent = nodeParent;
parent = nodeParent;
keyNum=keys.size();
sibling.keyNum=sibling.keys.size();
nodeParent.childList.addFirst(sibling);
if (nodeParent.keys.isEmpty()){
nodeParent.keys.addFirst(upKey);
nodeParent.keys.add(keys.getLast());
nodeParent.childList.add(this);
nodeParent.keyNum=nodeParent.keys.size();
return nodeParent;
}
return this.parent.insert(upKey,null);
}
更新关键字
protected void upDateKey(K oldKey,K newKey){
//向上更新父节点关键字
var currentNode=(BPlusNode<K, V>)this;
while (currentNode.parent!=null){
currentNode= currentNode.parent;
var upDateIndex=Collections.binarySearch(currentNode.keys, oldKey);
oldKey=currentNode.keys.getLast();
currentNode.keys.set(upDateIndex, newKey);
if (newKey.compareTo(currentNode.keys.getLast())<0) return;
}
}
B+树删除
B+树的删除可能会触发下溢出,即节点关键字个数<2,此时需要修复
-
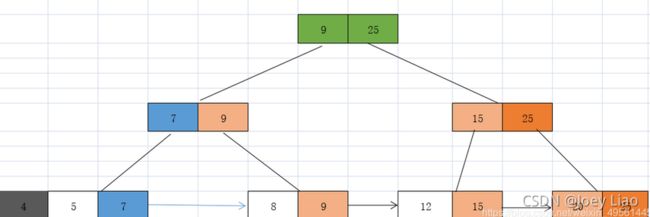
找到存储有该关键字所在的结点时,由于该结点中关键字个数大于⌈M/2⌉(2), 删除操作不会破坏 B+树,则可以直接删除。比如删除4 关键字不会下溢,可以直接删除
-
删除 关键字8 ,导致该节点关键字不足,产生下溢,需要修复
- 看兄弟节点是否富余,如果富余则向兄弟节点借关键字,这里兄弟节点不富余
- 兄弟节点不富余则和兄弟节与当前节点合并(哪边有兄弟节点则和 合并哪边)–这里和左兄弟节点合并
- 合并后需要将左兄弟节点的指针置空,并从其父节点的孩子集合中删除对应分支
- 删除父节点上左节点合并后对应的关键字
- 如果删除最大值,则需要向上更新父节点最大值为该节点倒数第二位,即删除节点的前一个进行更新替换,直到更新到根节点为止
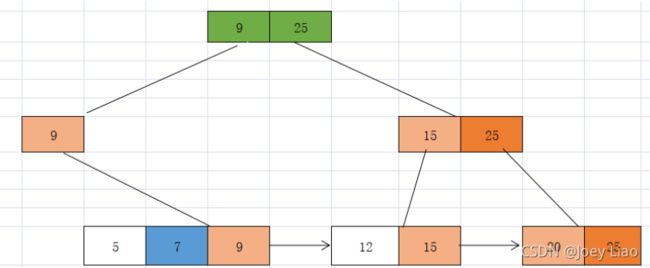 很明显删除导致父节点关键字不足产生下溢出,则需要递归对父节点关键字进行处理
很明显删除导致父节点关键字不足产生下溢出,则需要递归对父节点关键字进行处理
右兄弟不足,需要继续将右兄弟与之合并
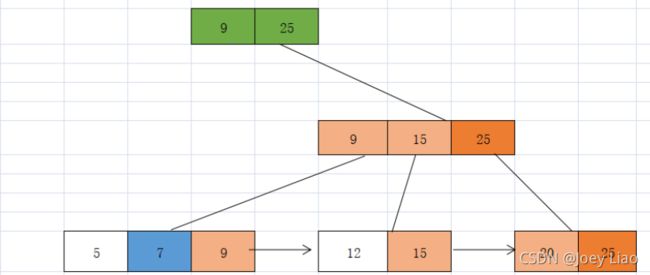 合并后会发现根节点少了一个子节点,没关系,我们直接拿根节点的子节点即右子节点作为新的根节点即可,此时B+树的高度比原来降低了1高度
合并后会发现根节点少了一个子节点,没关系,我们直接拿根节点的子节点即右子节点作为新的根节点即可,此时B+树的高度比原来降低了1高度

-
继续删除12 ,我们发现12对应节点的左兄弟节点关键字富余,可以向左兄弟节点借关键字9 放入15的前面,并更新左兄弟节点对应的父节点关键字为7 即可完成修复。
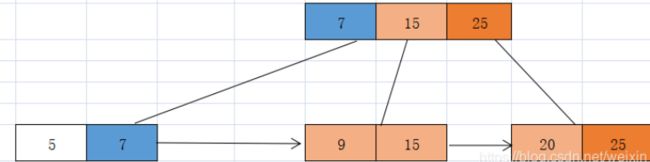
-
继续 删除25 删除的是该节点分支的最大值,所以需要向上更新父节点最大值为20
删除后导致该节点关键字个数不足2个产生下溢出,所以需要修复。 其左兄弟关键字个数不足,所以需要合并。
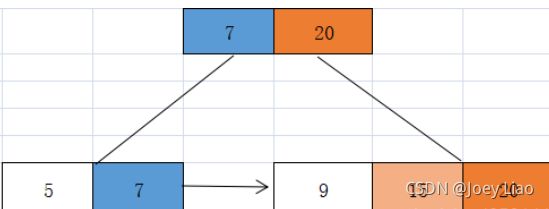
总结:兄弟节点富余,向对应富余的兄弟借关键字,不富余则将兄弟节点与该节点合并,然后更新父节点,递归向上到根节点
实现
删除代码片段
public void delete(K key){
Objects.requireNonNull(key);
if (root.keys.isEmpty()){
System.out.println("BPlus tree is empty!");
return;
}
var deleteNode =(LeafNode<K,V>) root.search(key);
if (!deleteNode.keys.get(deleteNode.insertIndex>=deleteNode.keyNum?0:deleteNode.insertIndex).equals(key)){
throw new NoSuchElementException("The key "+key+" is not existence in the BPlus Tree or double delete it");
}
root= deleteNode.delete(key);
}
非叶子节点删除
/*
* @param: [key]
* @return: DataStructure.Tree.BPlusTree.BPlusNode
* @description:非叶子节点删除
*/
@Override
BPlusNode<K,V> delete(K key) {
var targetParentIndex=this.parent!=null?Collections.binarySearch(this.parent.keys,this.keys.getLast()):0;
this.keys.remove(key);
this.keyNum--;
if (this.parent==null){
//如果父节点关键字不够合并及借,降低树的高度根节点[2,M]
if (this.childList.size() > 0&&this.keyNum<2){
var newRoot=this.childList.getFirst();
newRoot.parent = null;
return newRoot;
}
}
else {
K updateKey;
if ((updateKey=this.keys.getLast()).compareTo(key)<0){
upDateKey(key,updateKey);
}
if (isUnderFlow()){
return flxUpNode(targetParentIndex);
}
}
return this.getRoot();
}
叶子节点删除
/*
* @param: [key]
* @return: DataStructure.Tree.BPlusTree.BPlusNode
* @description: 叶子节点删除
*/
@Override
BPlusNode<K, V> delete(K key) {
var deleteIndex=this.insertIndex;
var removeKey = this.keys.remove(deleteIndex);
this.entryKey.remove(deleteIndex);
if (deleteIndex==--keyNum&&keyNum>0){
upDateKey(removeKey,this.keys.getLast());
}
if (this.parent!=null){
var parentTargetIndex= Collections.binarySearch(this.parent.keys,this.keys.getLast());
if (this.isUnderFlow()){
return flxUpNode(parentTargetIndex);
}
}
return this.getRoot();
}
删除后下溢修复
/*
* @param: [parentTargetIndex]
* @return: DataStructure.Tree.BPlusTree.BPlusNode
* @description: 删除后下溢修复
*/
protected BPlusNode<K, V> flxUpNode(int parentTargetIndex){
var leftChildIndex = parentTargetIndex-1;
var rightChildIndex = parentTargetIndex+1;
var parentChildList = this.parent.childList;
var isLeftBrother = leftChildIndex>=0;
if (isLeftBrother&&parentChildList.get(leftChildIndex).keyNum>Math.ceil(degree/2.0)){
borrowNodeFromBrother(leftChildIndex,true);
}
else if (rightChildIndex<parentChildList.size()&&parentChildList.get(rightChildIndex).keyNum > Math.ceil(degree / 2.0)){
borrowNodeFromBrother(rightChildIndex,false);
}
else {
var mergeIndex= isLeftBrother?leftChildIndex:rightChildIndex;
mergeChild(mergeIndex,parentTargetIndex,isLeftBrother);
//兄弟节点被合并到当前删除关键字的节点中如果是左兄弟节点与之合并的则删除父节点左兄弟节点位置的关键字,反之删除当前节点的位置的父节点关键字
var deleteKey=isLeftBrother?this.parent.keys.get(leftChildIndex):this.parent.keys.get(parentTargetIndex);
//删除合并后原来父节点合并时没有删除的关键字
return this.parent.delete(deleteKey);
}
return this.getRoot();
}