基于结构化数据的文本生成:非严格对齐生成任务及动态轻量的GCN生成模型

作者|邴立东、程丽颖、付子豪、张琰等
单位|阿里巴巴达摩院、香港中文大学等
摘要
基于结构化数据生成文本(data-to-text)的任务旨在生成人类可读的文本来直观地描述给定的结构化数据。然而,目前主流任务设定所基于的数据集有较好的对齐 (well-aligned)关系,即输入(i.e. 结构化数据)和输出(i.e. 文本)具有相同或很接近的信息量,比如 WebNLG 当中的输入 triple set 和输出文本所描述的知识完全匹配。但是,这样的训练数据制作困难且成本很高,现有的数据集只限于少数几个特定的领域,基于此训练的模型在现实应用中存在较大的局限性。
因此,我们提出了基于部分对齐(partially-aligned)样本的文本生成任务。部分对齐数据的优势在于获取门槛低,可以用自动或半自动方式构造,因而更容易拓展到更多的领域。我们考虑了两个对偶的部分对齐场景,即输入数据多于文本描述和文本描述多于输入数据。
对于数据多于文本的情况,我们发布了 ENT-DESC 数据集 [1],并且针对数据中存在冗余信息的问题,我们提出了多图卷积神经网络 (Multi-Graph Convolutional Network)模型来抽取重要信息,生成更为凝练的文本描述。
对于文本多于数据的情况,我们发布了 WITA 数据集 [2],并且针对训练样本中文本的多余信息,提出了远程监督生成(Distant Supervision Generation)框架,以确保基于非严格对齐样本训练的模型,在应用中能够如实地生成给定数据的描述。
基础模型层面,本文将介绍我们提出的轻量、动态图卷积网络 (Lightweight, Dynamic Graph Convolutional Networks),简称 LDGCN [3],可以有效的融合图结构中来自不同阶节点的信息,进而学习更优的图表示,并提升下游文本生成的效果。
参考文献
[1] ENT-DESC: Entity Description Generation by Exploring Knowledge Graph. Liying Cheng, Dekun Wu, Lidong Bing, Yan Zhang, Zhanming Jie, Wei Lu, Luo Si. EMNLP, 2020.
[2] Partially-Aligned Data-to-Text Generation with Distant Supervision. Zihao Fu, Bei Shi, Wai Lam, Lidong Bing, Zhiyuan Liu. EMNLP, 2020.
[3] Lightweight, Dynamic Graph Convolutional Networks for AMR-to-Text Generation. Yan Zhang, Zhijiang Guo, Zhiyang Teng, Wei Lu, Shay B. Cohen, Zuozhu Liu, Lidong Bing. EMNLP, 2020.

非严格对齐的文本生成:输入数据多于文本描述

论文标题:
ENT-DESC: Entity Description Generation by Exploring Knowledge Graph
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.90.pdf
数据代码连接:
https://github.com/LiyingCheng95/EntityDescriptionGeneration
1.1 任务设置
本篇论文的基本出发点是提出一个实用的主题化文本生成任务设定,而这个设定下构造的数据集具有输入数据多于生成文本的特点。现有结构化数据到文本生成的任务要求输出的信息在输入的结构化数据中有很充分的体现,比如 WebNLG 数据集 [1] 等。
这样的任务设定和数据准备在实际应用中均有一定的局限性。而本篇论文所提出的主题化实体描述生成,是在给定一个主实体(main entity)的前提下,通过利用该实体的多个附属主题实体(topic-related entity),对生成的主实体描述进行一定的导向和限制,使其符合某一主题。

上图例子中,红色框内是输入的主实体(Bruno Mars)和多个附属主题实体(funk, rock, R&B 等),目标是生成符合这一特定主题的文本描述,如蓝色方框所示,来介绍 Bruno Mars 其人以及其音乐风格等。为了使生成的描述符合现实世界的知识,我们依据输入实体,有选择性地利用知识图谱中关于这些实体的知识,如绿色方框所示,辅助生成该实体的主题化描述。本任务相较于现有的生成任务更具有实用性和挑战性。
1.2 ENT-DESC数据集
基于这样的任务设定,本篇论文提出了一个新的数据集 ENT-DESC。此数据集采用了较为普遍和常规的维基百科数据集和 WikiData 知识图谱。
首先,我们用 Nayuki 的工具(https://www.nayuki.io/page/computing-wikipedias-internal-pageranks)去给超过 990 万维基百科页面计算 PageRank。然后我们根据 PageRank 排名,选用了来自于四种主要领域的 11 万主实体名词,以及维基百科第一段文本中带有超链接的名词作为附属主题实体。
我们即用每个维基百科页面的第一段文本作为输出。另外我们利用已有知识图谱 Wikidata,选取了主实体的相邻实体,以及主实体和附属主题实体间的 1 跳和 2 跳路径。据我们所知,ENT-DESC 是现有知识图谱生成文本的类似数据集中规模最大的。其与部分现有数据集的比较如下图所示。
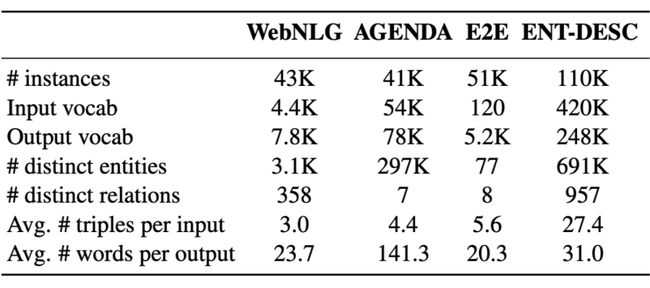
此数据集的一大特性为输入中包含输出内容以外的信息,因此要求模型可以有效选取输入中更为有用的信息去做生成。有关 ENT-DESC 数据集以及其更详细的准备和处理步骤可参阅:
https://github.com/LiyingCheng95/EntityDescriptionGeneration/tree/master/sockeye/data/ENT-DESC%20dataset
1.3 MGCN模型
在模型层面,现有序列到序列的文本生成模型不能够很好地利用图的结构与信息,而图到序列模型 [2] 将图中实体间的关系变为实体的参数,此类模型遇到信息丢失和参数过多的问题。有论文提出了 Levi 图转换方法 [3],即将原始图中的关系转化成点,以用于解决前面提到的问题。但是 Levi 图转化仍然有它自己的缺陷。
在 Levi 图中,我们不能很好的区分哪些点是原始图中的实体或关系,并且实体间的直接联系在 Levi 图中被忽略。另外,不同类型的边被融合在 Levi 图中一起学习,不能很好地区分不同类型边的不同重要性。
为了解决现有模型在本篇论文提出的知识图谱驱动实体文本描述生成的任务上的缺陷,本篇论文采用了编码-解码架构(encoder-decoder),提出了一种基于多图卷积神经网络(Multi-Graph Convolutional Network)的文本生成模型。
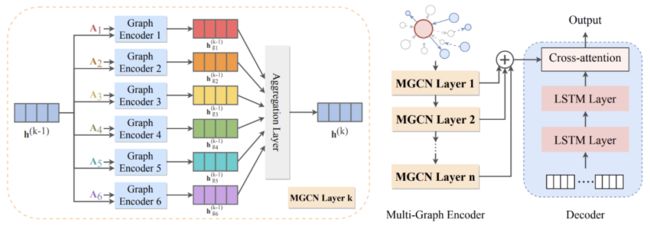
在多图编码器(Multi-Graph Encoder)中,不同于传统的图编码器,我们叠加了多层多图卷积神经网络。每层多图卷积神经网络的结构如左图所示。我们先将输入图嵌入转化为 6 个不同图的邻接矩阵,分别放入 6 个图编码器,以此得到 6 个包含不同类型信息的图嵌入。继而将这些图嵌入进行聚合运算,得到下一层的图嵌入。
解码器(decoder)是一个基于标准的长短时记忆网络(LSTM)的文本生成模型。本篇论文中的解码器对于在编码过程中学习到的隐藏子图的特征与结构信息进行解码,并生成相应的描述文本。此模型结构有效避免了信息丢失和参数过多的问题,有选择性地捕捉了多图中的重要信息并进行了有效聚合。
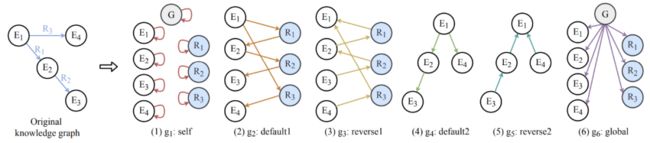
上图展示了多图转化的过程。类似于 Levi 图转化的过程,我们将原始图中的边转化为点。
(1)在 g1:self 图中,我们给所有的点加一条自循环的边。(2)在 g2:default1 图中,我们把点和边按原始图中的默认顺序进行连接。(3)在 g3:reverse1 中,我们将 g2 中的边进行反向连接。(4)在 g4:default2 中,我们将点和点之间按默认顺序连接。(5)类似地,在 g5:reverse2 中,我们将点和点之间的边反向相连。(6)最后,我们额外加了全局点(gnode),并把它与图中其他所有点按图中方向相连。
它的创新之处在于将原始图中的点到点、点到边的正向与反向信息明确地表示在不同图中,这样简单明了的转化过程对多图卷积神经网络中的学习起到了巨大的帮助作用。
1.4 主要实验结果
我们在本篇论文所提出的 ENT-DESC 数据集和 WebNLG 数据集上均实验了提出的模型。下图是我们在 ENT-DESC 数据集上的主要实验结果。
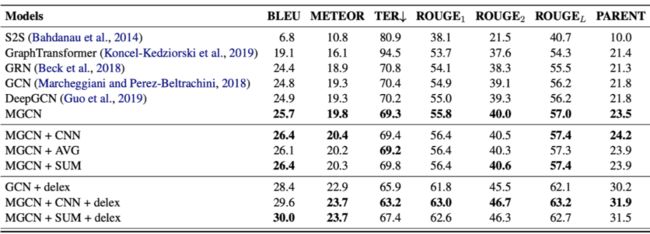
我们与序列到序列生成模型及多种图到序列生成模型在多种评测标准上均做了比较。从表格和图中,我们可以观察到,现有图到序列模型可以达到 BLEU 值 24.8,现有深层图到序列模型 [4] 的 BLEU 值为 24.9。而我们的多图神经网络结构在 6 层时可以达到 25.7 的 BLEU 值,加上聚合运算后可以达到 26.4。
由此可见,我们提出的多图卷机神经网络的模型有效地捕捉了知识图谱中的重要信息并进行了有效聚合。我们进一步对数据进行了归一化处理(delexicalization),实验结果均有更进一步的提升。
另外,此模型在 ENT-DESC 数据集以及现有数据集上(如:WebNLG)相对于多个基准模型在多个评测标准上均显示明显提升,同时其可被扩展应用于其他图相关的自然语言处理研究中。

上图展示了知识驱动文本生成的例子。红色高亮文本是主要实体,蓝色高亮文本是附属主题实体。与维基百科的参考文本相比,我们提出的多图卷积神经网络与聚合运算能够准确捕捉到主要实体以及大部分附属主题实体。而传统的图到序列生成模型未能识别出主要实体。这进一步体现了传统图到序列模型会造成信息丢失的情况,同时也体现了多图卷积神经网络对于提取重要信息的有效性。
参考文献
[1] Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017. The webnlg challenge: Generating text from rdf data. In Proceedings of INLG.
[2] Diego Marcheggiani and Ivan Titov. 2017. Encoding sentences with graph convolutional networks for semantic role labeling. In Proceedings of EMNLP.
[3] Daniel Beck, Gholamreza Haffari, and Trevor Cohn. 2018. Graph-to-sequence learning using gated graph neural networks. In Proceedings of ACL.
[4] Zhijiang Guo, Yan Zhang, Zhiyang Teng, and Wei Lu. 2019. Densely connected graph convolutional networks for graph-to-sequence learning. TACL.

非严格对齐的文本生成:文本描述多于输入数据

论文标题:
Partially-Aligned Data-to-Text Generation with Distant Supervision
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.738.pdf
数据代码链接:
https://github.com/fuzihaofzh/distant_supervision_nlg
2.1 简介
在基于结构化数据生成文本(data-to-text)[1,2] 任务中,现有的模型要求训练的数据和文本是严格对齐的(well-aligned),导致可以用于训练的数据非常稀少且标注代价高昂,因此,现有的经典生成任务只限于少数几个特定的领域。
本文旨在探索使用部分对齐(partially-aligned)的数据来解决数据稀缺的问题。部分对齐的数据可以自动爬取、标注,从而能将文本生成任务推广到更多的数据稀缺的领域。但是,直接使用此类数据来训练现有的模型会导致过度生成的问题(over-generation),即在生成的句子中添加与输入无关的内容。
为了使模型能够利用这样的数据集来训练,我们将传统的生成任务扩展为“部分对齐的数据到文本生成的任务”(partially-aligned data-to-text generation task),因为它利用自动标注的部分对齐数据进行训练,因此可以很好地被应用到数据稀缺领域。
为了解决这一任务,我们提出了一种新的远程监督(distant supervision)训练框架,通过估计输入数据对每个目标词的支持度,来自动调节相应的损失权重,从而控制过度生成的问题。我们通过从 Wikipedia 中抽取句子并自动提取相应的知识图谱三元组的方式制作了部分对齐的 WITA 数据集。
实验结果表明,相较于以往的模型,我们的框架能更好地使用部分对齐的数据,缓解了过度生成问题,从而验证了使用部分对齐的数据来训练生成模型的可行性。本文的数据和源代码可以从下方链接获取:
https://github.com/fuzihaofzh/distant_supervision_nlg
2.2 WITA数据集
我们通过抽取 Wikipedia 句子中的三元组来自动构建部分对齐的数据集。整个抽取框架如图所示。

首先,我们提取出 Wikipedia 每篇文章的第一个句子,随后,我们用实体检测器(Entity Detector)来抽取出每个句子所包含的所有实体,该实体检测器包含三个部分,分别是链接检测,NER 检测以及名词检测,其中 NER 检测和名词检测通过 spaCy 实现。接着,这些名词经过一些规则过滤后,两两组合(笛卡尔积)得到了实体对(Entity Pair)的列表。
另一方面,我们将 Wikidata 导入到 ElasticSearch,Wikidata 是一个知识图谱的库,包含了很多客观信息的三元组描述。
我们用每个三元组的头尾实体对做索引,用整个三元组做值,这样一旦给定一个实体对,我们就能方便地通过查询 ElasticSearch 得到他们之间的三元组关系。我们将笛卡尔积中的每个实体对输入到 ElasticSearch 中查询他们的关系,通过一些规则过滤,得到最终句子对应的三元组。
下表是我们的新的数据集(WITA)和现有的数据集 WebNLG [1] 的对比。我们发现,我们的数据集比 WebNLG 大,同时包含的关系种类(Relation Type)是 WebNLG 的两倍,含有的实体种类是 WebNLG 的 40 倍,而包含的词典大小也是 WebNLG 的 12 倍。因此 WITA 数据集包含有更广阔领域的信息。
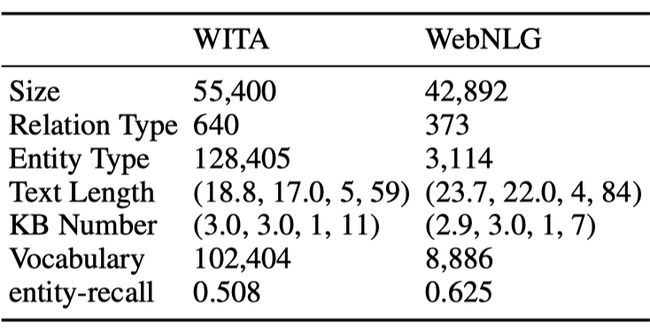
然而,这种自动标注的数据并不是严格对齐的,如图所示,因为很多信息 Wikidata 中并不包含,所以文本会包含比三元组多的信息。直接使用此类数据来训练现有的模型会导致过度生成的问题(over-generation)。
在图中,文本中红色的部分是三元组中未包含的信息,普通的生成模型会错误地认为这些信息是由给定三元组的某些部分给出的,因此,在使用训练好的模型做生成时,给定一些数据,它会生成额外的未提及的信息。
以下图为例,训练数据中“develpoed in Canada”就没有对应的三元组描述,模型会错误地将其绑定到给定的 genre 三元组中,因此,在生成关于另一个 genre 三元组的描述时,就可能会加上这个冗余的信息。我们提出了远程监督生成框架(Distant Supervision Generation)来解决这个问题。

2.3 模型框架
如图所示,我们的远程监督生成框架(Distant Supervision Generation framework)包含了四个模块:
1)支持度估计器(Supportiveness Estimator,SE);2)序列到序列生成器(Sequence-to-Sequence Generator,S2SG);3)支持度适配器(Supportiveness Adaptor,SA);4)重平衡集束搜索(Rebalanced Beam Search,RBS)。下面我们分别来看每个模块的作用。
SE 模块主要负责计算输入数据对目标文本中每个词的支持度。如图所示, 是文本序列, 是输入数据,我们首先采样一个负样本文本 ,然后得出他们对应的特征矩阵 以及这些特征矩阵之间的点积矩阵 和 。其中, 的每个元素表示输入数据中的每个词对目标文本中的每个词的支持度,接着我们计算出输入数据整体对每个目标词的支持度为 。我们优化的目标即是最大化正负样本的支持度差异 。除此之外,我们还提出了另外两个优化目标,其一是词一致性损失(word-consistent loss):
![]()
它的含义是,如果输入三元组和目标文本中含有相同的词,那么矩阵 对应的元素会变大。另一个是集中损失(concentration loss):
![]()
这项损失防止三元组中的某个词支持太多的目标文本词。最后,总体的优化目标是以上损失的加权组合:
![]()

S2SG 模块主要负责文本生成,我们通过 Transformer [3] 来实现。
SA 模块将 SE 模块得出的支持度适配到 S2SG 的每个词的损失上
![]()
其中 是三元组对第 i 个目标词的支持度,而 则是第 i 个词对应的损失。
RBS 模块主要应用在生成环节,我们对每一个词计算一个输入三元组的支持度 ,然后我们重新计算每个词的概率为 ,其中 是一个可调的参数。
2.4 主要实验结果
下表是主要实验结果,我们对比了一些常见的生成模型,其中 S2S [4] 采用基于 LSTM 的 sequence-to-sequence 模型,而 S2ST [3,5] 则是基于 Transformer 的生成模型,DSG-A 和 DSG-H 则是分别采用 Attention Adaptor 和 Hard Adaptor。
通过对比,我们发现,加入 Supportiveness Adaptor 之后,系统的性能都有所提升,而我们提出支持度计算和适配的方法取得了最好的效果。通过消融实验,我们可以观察到 RBS 和 SA 都明显地提升了模型效果。
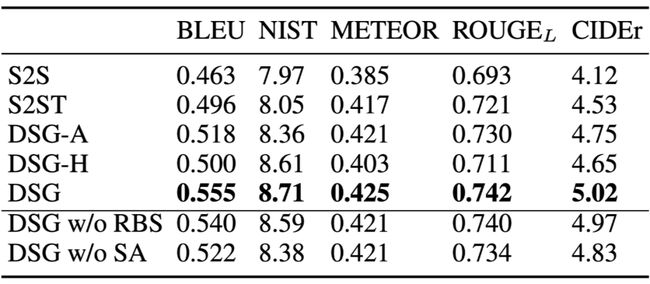
下图是对比了我们的支持度和传统注意力值的热力图。我们可以看到,因为注意力机制本身有归一化的约束,导致了一个词的支持度之和是固定的,这样,如果有很多词支持,就会分散支持的权重,因而我们的支持度计算方法比直接用注意力当支持度能更好地反应支持度的强弱。

为了更直观地展示 DSG 模型能很好地解决过度生成问题。我们采样了一些输出结果作对比,通过把和输入不相关的生成部分用红字标出,可以发现,如果直接用 WITA 数据来训练传统的 S2ST 模型,生成的时候会产生很严重的过度生成的问题,而我们提出的 DSG 模型则能很好地解决这个问题,取得好的生成效果。

参考文献
[1] Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017. Creating training corpora for nlg micro-planners. ACL.
[2] Remi Lebret, David Grangier, and Michael Auli. 2016. Neural text generation from structured data with application to the biography domain. EMNLP.
[3] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. NIPS.
[4] Anastasia Shimorina and Claire Gardent. 2018. Handling rare items in data-to-text generation. INLG.
[5] Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli. 2019. fairseq: A fast, extensible toolkit for sequence modeling. NAACL.

轻量、动态图卷积网络及其在文本生成中的应用

论文标题:
Lightweight, Dynamic Graph Convolutional Networks for AMR-to-Text Generation.
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.169.pdf
代码链接:
https://github.com/yanzhangnlp/LDGCNs
3.1 简介
图神经网络(Graph Neural Networks)是学习图表示的一类强大方法,已应用于许多自然语言处理任务中,例如信息抽取,情感识别和文本生成。图卷积网络(Graph Convolutional Networks),是图神经网络中的一种。
相比于图循环网络(Graph Recurrent Networks) 以及最近的图变换网络(Graph Transformer Networks), 图卷积网络具有更好的计算效率。但由于图卷积网络遵循邻接信息(First-order)传递机制,对高阶信息的融合不如图循环网络和图变换网络。
为此,我们提出了一种动态融合机制,可以有效的融合图结构中来自不同阶节点的信息。具体地,我们利用了门控机制动态接受图结构中不同阶节点的信息流,从而可以同时融合低阶和高阶的信息。例外,我们还提出了两种参数共享机制,减少了模型的复杂度,提高了模型的效率。
结合动态融合机制和参数共享机制的图卷积网络,我们称之为轻量、动态图卷积网络(Lightweight, Dynamic Graph Convolutional Networks),简称 LDGCN。
我们在 AMR-to-Text Generation 这一类文本生成任务中进行了实验。AMR(Abstract Meaning Representation)是一种将句子的语义抽象表示的有根有向图(rooted directed graph),其中节点(nodes)是概念(concept),边(edges)是语义关系(semantic relations)。
AMR-to-Text Generation 是将 AMR 图编码并解码成表达其含义的文本。这个任务的关键挑战在于如何有效捕获基于图的数据中存储的复杂结构信息。实验结果表明,我们的模型 LDGCN, 不仅性能优于其他图神经网络模型,而且模型十分轻便,参数量远少于性能最好的图变换网络模型。
3.2 模型框架
3.2.1 动态融合机制

传统的图卷积网络受限于邻接信息传递机制,忽略了高阶有效信息,受门控线性单元(Gated Linear Units)的启发 [1],我们提出了动态融合机制。该机制可以让图卷积网络融合来自不同阶节点的信息同时保留模型的非线性特性。如上图所示,模型工作流程如下。每一个图卷积层均以 k 个 k 阶邻接矩阵为输入(这里 k=3), 动态融合机制,利用门控方式,整合从 1 到 k 跳邻居的信息,其函数表示如下:
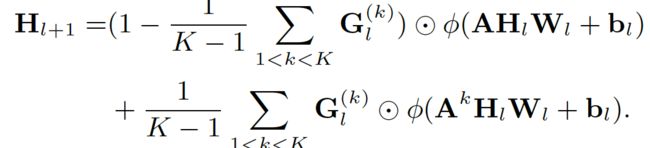
其中, G 是一个基于高阶邻接矩阵信息的门控矩阵,表示为:
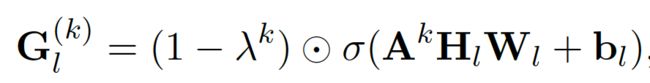
3.2.2 参数共享机制
深度图卷积网络一般能够表现出更好的性能,但越深的网络也会导致更多的参数,从而增加了计算上的复杂度。为了提高模型的效率,我们提出了图分组卷积(Group Graph Convolution)和权重绑定卷积(Weight Tied Convolutions)两种参数共享机制。其中,图分组卷积用于减少每一层图卷积网络的参数而权重绑定卷积则用于层与层之间参数的共享。
受分组卷积 [2] 的启发,我们提出了两种在图卷积网络上的拓展,即深度图分组卷积(Deepthwise Group Graph Convolution)和层级图分组卷积(Layerwise Group Graph Convolution).

如上图所示,对于深度图分组卷积,输入表示和输出表示被分成了不相交的 n 组(这里 n=3)进行计算。将三组表示拼接则为输出层表示。这样每一层的参数可以减少 n 倍。
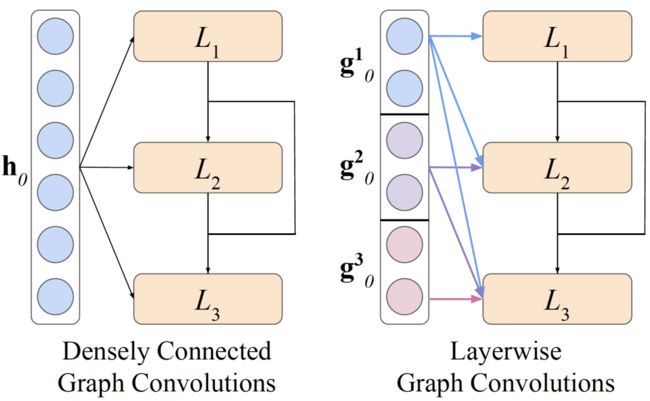
层级图分组卷积是基于最近的密集连接图卷积网络 [3] 提出的。如上图所示,在密集连接图卷积中,每一层的输入来自于之前所有卷积层输出拼接而成。而层级图分组卷积在此基础之上,还将输入表示分成了 n 组(这里 n=3)进行计算。
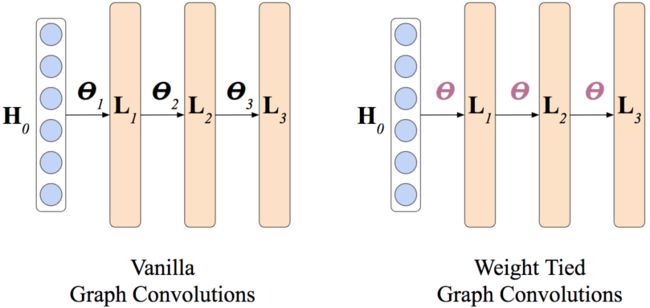
启发于最近的权重绑定自注意力网络 [4],我们提出了权重绑定图卷积。如上图所示,在权重绑定图卷积中,每一层都使用相同的参数。从而较大地节省了模型的参数。
3.3 主要实验结果

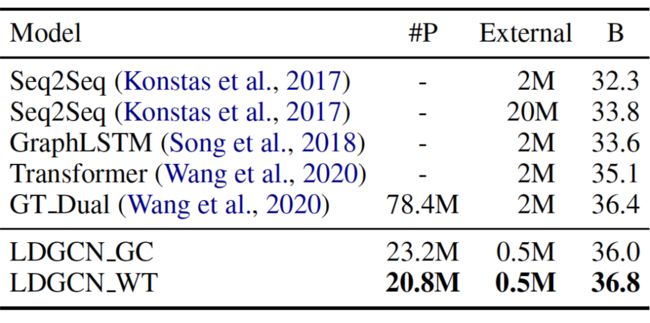
基于不同的参数共享机制,我们分别命名为 LDGCN_WT(Weight Tied)和LDGCN_GC(Group Convolution)。我们主要在两个标准的 AMR 数据集上进行了实验, 即 AMR2015(LDC2015E86)和 AMR2017(LDC2017T10)。
上面表 1 展示了两个数据集上的结果(B, C, M 和 #P 分别代表 BLEU, CHRF++, METEOR 和模型的参数量)。我们的模型 LDGCN_GC 在两个数据集上都取得了最好的结果。而且相比当前最好的图变换网络模型 GT_SAN,我们的模型只需要大约五分之一的参数。而相比于其他图卷积网络,我们的模型也都远远强于当前最好的模型 DCGCN 以及 DualGraph。
表 2 展示了模型在大规模数据集上的结果。可以看到,我们模型 LDGCN_WT,优于当前最好的 Transformer 模型,且只使用了其四分之一数据(0.5M)。而与表1结果不同的是,在使用较大数据的情况下,LDGCN_WT 效果优于 LDGCN_GC。我们推测,足够的数据可以提供足够的正则化来减少震荡,稳定 LDGCN_WT 的训练过程。
参考文献
[1] Yann Dauphin, Angela Fan, Michael Auli, and David Grangier. 2016. Language modeling with gated convolutional networks. In Proc. of ICML.
[2] Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. 2017. Mobilenets: Efficient convolutional neural networks for mobile vision applications. ArXiv, abs/1704.04861.
[3] Zhijiang Guo, Yan Zhang, Zhiyang Teng, and Wei Lu. 2019b. Densely connected graph convolutional networks for graph-to-sequence learning. Transactions of the Association for Computational Linguistics, 7:297–312.
[4] Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. 2019a. Deep equilibrium models. In Proc. of NeurIPS.

总结
文本生成作为近年来引起广泛关注的研究课题,有着丰富的应用场景。基于结构化数据和知识的文本生成是一个重要的研究方向。本文探索的非严格对齐的文本生成任务设定,给基于知识的文本生成任务引入了更实用化的新发展,我们公布了两个新数据集以支持这方面的研究。另外,本文介绍的轻量、动态 GCN 模型 LDGCN,不但可以有效的融合图结构中来自不同阶节点的信息,还可以通过参数共享机制,提高 GCN 模型的效率。
本文由阿里巴巴达摩院新加坡 NLP 团队邴立东、程丽颖、张琰,香港中文大学付子豪共同整理而成。由 PaperWeekly 编辑进行了校对和格式调整。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

