二、RNN模型 与 NLP应用 —— Simple RNN
二、RNN模型 与 NLP应用 —— Simple RNN
- 前言
- Simple RNN
- LSTM
前言
FCN和ConvNet的限制: one-to-one模型, 一个输入对一个输出
- 一次性输入的是整个样本数据
- 固定输入和输出
RNN为 many-to-one 或者 many-to-many 输入和输出的长度不固定. RNN适合小规模问题可以, 大规模问题需要用Transformer.
Simple RNN
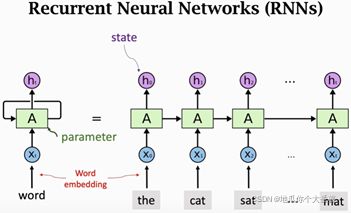
图1. Simple RNN结构. 初始节点的h输入是全0.
RNN每次看一个词, 用状态 h t h_t ht积累看过的信息. x t x_t xt为词向量, 将 x t x_t xt输入进RNN, RNN就会更新状态 h h h. h 0 h_0 h0包含了单词 “the”的信息, h 1 h_1 h1包含了 “the”和“cat”的信息, … , 最后的状态 h t h_t ht包含了之前输入的所有信息. 可以把h_t看作整句话的特征向量.
RNN更新状态 h h h时, 用到了一个可学习参数矩阵 A A A, 而这个参数矩阵 A A A从头到尾都在用, 只是内部参数通过训练数据被训练(初始化为随机值)
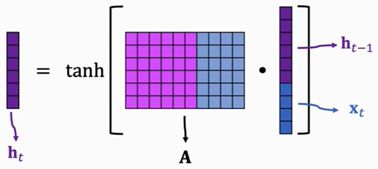
图2. A A A中的不同颜色表示矩阵是对应相乘的
上一个状态为 h t − 1 h_{t-1} ht−1, 新的输入为词向量 x t x_t xt, 将这两个向量拼接, 再与RNN参数矩阵 A A A相乘, 再用 t a n h tanh tanh激活函数对结果的每一个元素进行激活, 输出就是新的状态 h t ∈ ( − 1 , 1 ) h_t∈(-1,1) ht∈(−1,1).
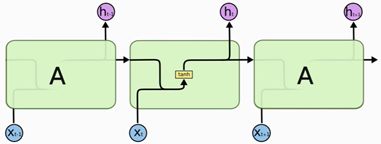
图3. 新状态 h t h_t ht是输入 x t x_t xt, 旧状态 h ( t − 1 ) h_(t-1) h(t−1)以及RNN参数A的函数
tanh激活函数的作用:
如果 x 0 = ⋯ = x 100 = 0 x_0=⋯=x_{100}=0 x0=⋯=x100=0, 则 x t x_t xt部分不起作用, 也就是矩阵 A A A的蓝色部分永远乘0. 所以 h 100 = A h 99 = A 2 h 98 = ⋯ = A 100 h 0 h_{100}=Ah_{99}=A^2 h_{98}=⋯=A^{100} h_0 h100=Ah99=A2h98=⋯=A100h0, 这时如果A中的最大值 λ m a x ( A ) < 1 λ_{max (A)}<1 λmax(A)<1则 h 100 ≈ 0 h_{100}≈0 h100≈0, 若 λ m a x ( A ) > 1 λ_{max (A)}>1 λmax(A)>1则 h 100 → ∞ h_{100}→∞ h100→∞. 所以tanh的作用就是让 A ( h + x ) A(h+x) A(h+x)恢复到 ( − 1 , 1 ) (-1,1) (−1,1)中.
RNN的参数量:
矩阵 A A A的行数与 h h h同维, A A A的列数与 h + x h+x h+x同维. 所以RNN的参数总量为:
s i z e ( A ) = s h a p e ( h ) ∗ [ s h a p e ( h ) + s h a p e ( x ) ] size(A)=shape(h)*[shape(h)+shape(x)] size(A)=shape(h)∗[shape(h)+shape(x)]

图4. 输出所有状态 h i h_i hi
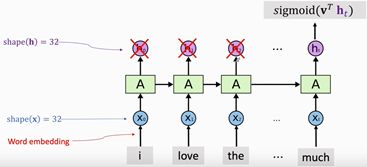
图5. 仅输出最后一个状态向量 h t h_t ht. 再将 h t h_t ht输入到另外一个分类器中, 输出为 s i g m o i d ( V T ⋅ h t ) ∈ ( 0 , 1 ) sigmoid(V^T⋅h_t )∈(0,1) sigmoid(VT⋅ht)∈(0,1), 其中0为负面评价, 1为正面评价
Simple RNN:
from keras.models import Sequential # Sequential 为将神经网络的层按顺序搭起来
from keras.layers import SimpleRNN, Dense, Embedding
vocabulary = 10000 # all words number
embedding_dim = 32 # shape(x)=32
word_num = 500 # sequence length
state_dim = 32 # shape(h)=32
model = Sequential()
model.add(Embedding(vocabulary, embedding_dim, input_length=word_num))
model.add(SimpleRNN(state_dim,return_sequences=False))
# return_sequences=True时用所有状态h_i, False时仅用最后一个状态h_t
model.add(Dense(1, activation='sigmoid')) # 仅输入最后一个状态ht, 输出(0,1)
model.summary()

图6. return_sequences=False时, RNN的总参数: 2080 = s h a p e ( h ) ∗ [ s h a p e ( h ) + s h a p e ( x ) ] = 32 ∗ ( 32 + 32 ) + 32 ( 偏 置 ) 2080 = shape(h)*[shape(h)+shape(x)]=32*(32+32)+32(偏置) 2080=shape(h)∗[shape(h)+shape(x)]=32∗(32+32)+32(偏置)

图7. return_sequences=True时, 第二层输出将500单词的状态 h i h_i hi全部输出
from keras import optimizers
epochs = 10
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=epochs,
batch_size=32, validation_data=(x_vaild, y_vaild))
loss_and_acc = model.evaluate(x_test, labels_test)
LSTM
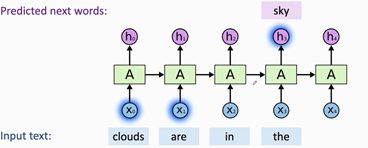
图8. 短依赖句子预测
给定半句话, 想要预测下一个单词, 在短依赖句子中Simple RNN很容易预测出来. 但是在长依赖句子中效果不好.

图9. 长依赖
因为 ∂ h 100 ∂ x 1 ≈ 0 \dfrac{∂h_{100}}{∂x_1}≈0 ∂x1∂h100≈0, 即更改了单词 x 1 x_1 x1, 不会对 h 100 h_{100} h100产生任何影响, 这是不合理的, 说明 h 100 h_{100} h100把 x 1 x_1 x1给忘记了.
LSTM详情见: 链接: 三、RNN模型 与 NLP应用 —— LSTM.