损失函数解读 之 Focal Loss
前言
Focal loss 是一个在目标检测领域常用的损失函数,它是何凯明大佬在RetinaNet网络中提出的,解决了目标检测中 正负样本极不平衡 和 难分类样本学习 的问题。
论文名称:Focal Loss for Dense Object Detection
目录
什么是正负样本极不平衡?
two-stage 样本不平衡问题
one-stage 样本不平衡问题
交叉熵 损失函数
Focal Loss
代码实现 Pytorch
什么是正负样本极不平衡?
目标检测算法为了定位目标会生成大量的anchor box(锚框),而一幅图中真实的目标(正样本)个数很少,大量的anchor box处于背景区域(负样本),这就导致了正负样本极不平衡。
简单来说,正样本是 预测的anchor box 框住了真实的目标;负样本是 预测的anchor box 没有框住真实的目标,框了背景。由于正样本的数量太少、负样本的数据量太多,导致正负样本极不平衡。
two-stage 样本不平衡问题
先看看RPN中的 anchor box ,feature maps 的每一个点都配9个锚框,作为初始的检测框。虽然这样得到的检测框很不准确,但后面可通过 bounding box regression 来修正检测框的位置。
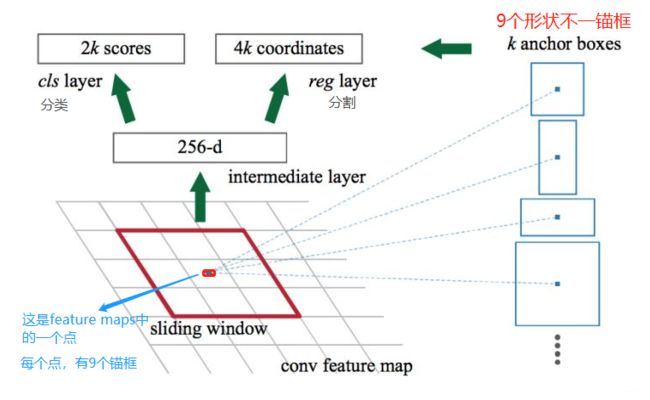
下面介绍那9个anchor boxes 锚框,先看看它的形状:
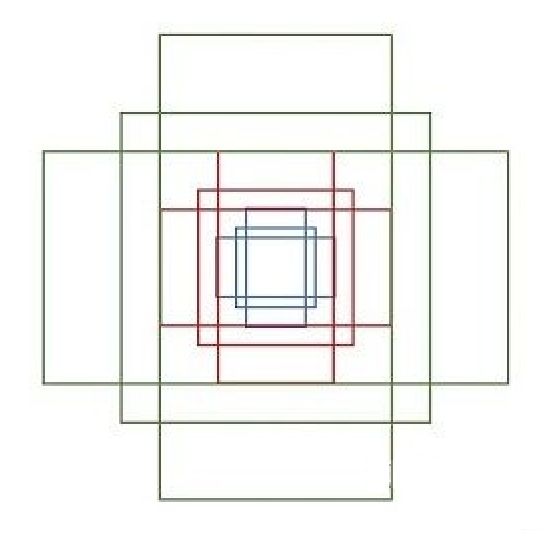
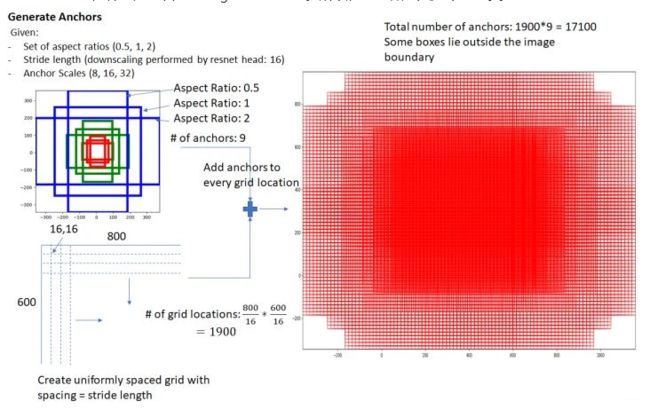
设 feature maps 的尺寸为 W*H,那么总共有 W*H*9个锚框。(W:feature maps的宽;H:feature maps 的高。)
two-stage方法在第一阶段生成候选框,RPN只是对anchor box进行简单背景和前景的区分,并不对类别进行区分,经过这一轮处理,过滤掉了大部分属于背景的anchor box,较大程度降低了anchor box正负样本的不平衡性。
注意:只是减轻了样本不平衡并没有解决样本不平衡。同时在第二阶段采用启发式采样(如:正负样本比1:3)或者OHEM进一步减轻正负样本不平衡的问题。
使用了anchor box机制的网络,通常就会出现样本不平衡问题。
one-stage 样本不平衡问题
one-stage方法为了提高检测速度,舍弃了生成候选框这一阶段,直接对anchor box进行难度更大的细分类,缺少了对anchor box的筛选过程。
看一下例子,预测了很多的框框,但正确包含物体的框框却很少。

交叉熵 损失函数
为什么要介绍交叉熵 损失函数呢?分类通常用到交叉熵的,而且Focal Loss 也是基于交叉熵进行改进的,先介绍一下交叉熵的原理,会更易于理解Focal Loss。
二分类交叉熵损失函数,公式定义如下:
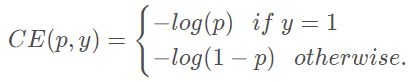
现定义如下的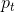
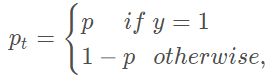
得到变形后的损失函数如下:
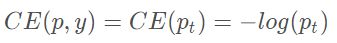
Focal Loss
由于存在正负样本极不平衡的问题,直接使用交叉熵 损失函数,得到的效果不好。于是,首先平衡交叉熵。
一般为了解决类别不平衡的问题,会在损失函数中每个类别前增加一个权重因子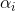 ∈ [0, 1]来协调类别不平衡。使用类似的方式定义
∈ [0, 1]来协调类别不平衡。使用类似的方式定义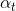 ,得到二分类平衡交叉熵损失函数:
,得到二分类平衡交叉熵损失函数:
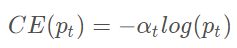
平衡交叉熵采用 平衡正负样本的重要性,但是没有区分难易样本。
平衡正负样本的重要性,但是没有区分难易样本。
然后,类间不均衡较大会导致,交叉熵损失在训练的时候收到影响。易分类的样本的分类错误的损失占了整体损失的绝大部分,并主导梯度。Focal Loss在平衡交叉熵损失函数的基础上,增加一个调节因子降低易分类样本权重,聚焦于困难样本的训练,其定义如下:
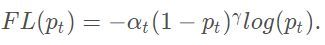
权重帮助处理了类别的 不均衡。
其中,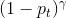 是调节因子,
是调节因子, ≥ 0是可调节的聚焦参数,下图展示了 ∈ [0, 5]不同值时focal loss曲线
≥ 0是可调节的聚焦参数,下图展示了 ∈ [0, 5]不同值时focal loss曲线
γ 控制曲线的形状. γ的值越大, 好分类样本的loss就越小, 我们就可以把模型的注意力投向那些难分类的样本. 一个大的 γ 让获得小loss的样本范围扩大了。同时,当γ=0时,这个表达式就退化成了Cross Entropy Loss (交叉熵损失函数)。

在上图中,“蓝”线代表交叉熵损失。X轴即“预测为真实标签的概率”(为简单起见,将其称为pt)。Y轴是给定pt后Focal loss和CE的loss的值。
从图像中可以看出,当模型预测为真实标签的概率为0.6左右时,交叉熵损失仍在0.5左右。因此,为了在训练过程中减少损失,我们的模型将必须以更高的概率来预测到真实标签。换句话说,交叉熵损失要求模型对自己的预测非常有信心。但这也同样会给模型表现带来负面影响。
深度学习模型会变得过度自信, 因此模型的泛化能力会下降.
当使用γ> 1的Focal Loss可以减少“分类得好的样本”或者说“模型预测正确概率大”的样本的训练损失,而对于“难以分类的示例”,比如预测概率小于0.5的,则不会减小太多损失。
Focal Loss特点:
- 当很小时(样本难分,不管分的是否正确),调节因子趋近1,损失函数中样本的权重不受影响;当很大时(样本易分,不管分的是否正确),调节因子趋近0,损失函数中样本的权重下降很多
- 聚焦参数可以调节易分类样本权重的降低程度,越大权重降低程度越大
通过分析Focal Loss函数的特点可知,该损失函数降低了易分类样本的权重,聚焦在难分类样本上。
代码实现 Pytorch
class WeightedFocalLoss(nn.Module):
"Non weighted version of Focal Loss"
def __init__(self, alpha=.25, gamma=2):
super(WeightedFocalLoss, self).__init__()
self.alpha = torch.tensor([alpha, 1-alpha]).cuda()
self.gamma = gamma
def forward(self, inputs, targets):
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction='none')
targets = targets.type(torch.long)
at = self.alpha.gather(0, targets.data.view(-1))
pt = torch.exp(-BCE_loss)
F_loss = at*(1-pt)**self.gamma * BCE_loss
return F_loss.mean()参考文章1:https://blog.csdn.net/qq_38675397/article/details/106496333
参考文章2:https://amaarora.github.io/2020/06/29/FocalLoss.html