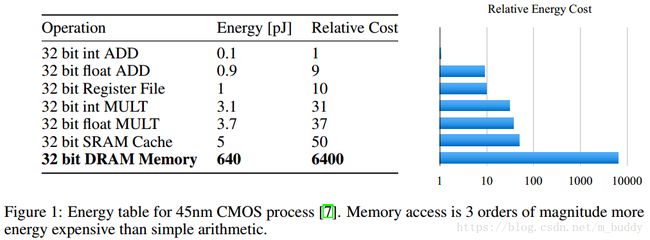
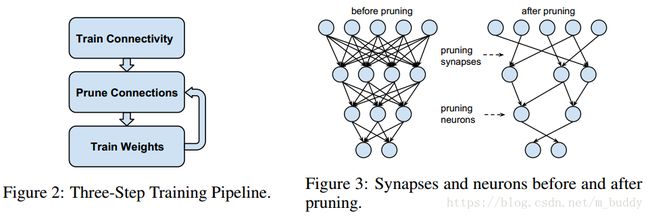
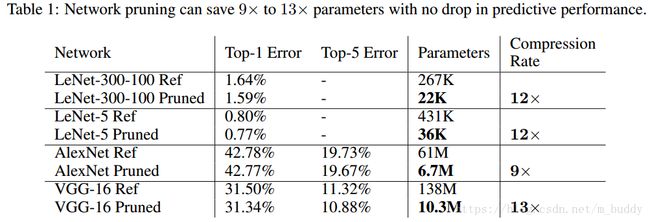
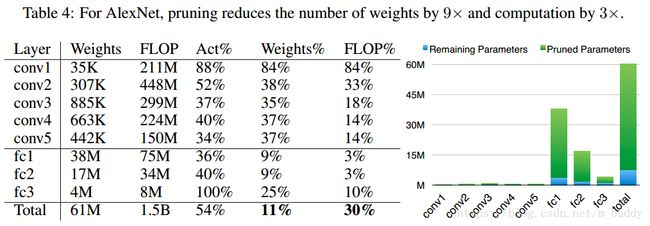
- 【iOS】MVC设计模式
Magnetic_h
iosmvc设计模式objective-c学习ui
MVC前言如何设计一个程序的结构,这是一门专门的学问,叫做"架构模式"(architecturalpattern),属于编程的方法论。MVC模式就是架构模式的一种。它是Apple官方推荐的App开发架构,也是一般开发者最先遇到、最经典的架构。MVC各层controller层Controller/ViewController/VC(控制器)负责协调Model和View,处理大部分逻辑它将数据从Mod
- git常用命令笔记
咩酱-小羊
git笔记
###用习惯了idea总是不记得git的一些常见命令,需要用到的时候总是担心旁边站了人~~~记个笔记@_@,告诉自己看笔记不丢人初始化初始化一个新的Git仓库gitinit配置配置用户信息gitconfig--globaluser.name"YourName"gitconfig--globaluser.email"
[email protected]"基本操作克隆远程仓库gitclone查看
- PHP环境搭建详细教程
好看资源平台
前端php
PHP是一个流行的服务器端脚本语言,广泛用于Web开发。为了使PHP能够在本地或服务器上运行,我们需要搭建一个合适的PHP环境。本教程将结合最新资料,介绍在不同操作系统上搭建PHP开发环境的多种方法,包括Windows、macOS和Linux系统的安装步骤,以及本地和Docker环境的配置。1.PHP环境搭建概述PHP环境的搭建主要分为以下几类:集成开发环境:例如XAMPP、WAMP、MAMP,这
- 四章-32-点要素的聚合
彩云飘过
本文基于腾讯课堂老胡的课《跟我学Openlayers--基础实例详解》做的学习笔记,使用的openlayers5.3.xapi。源码见1032.html,对应的官网示例https://openlayers.org/en/latest/examples/cluster.htmlhttps://openlayers.org/en/latest/examples/earthquake-clusters.
- Faiss:高效相似性搜索与聚类的利器
网络·魚
大数据faiss
Faiss是一个针对大规模向量集合的相似性搜索库,由FacebookAIResearch开发。它提供了一系列高效的算法和数据结构,用于加速向量之间的相似性搜索,特别是在大规模数据集上。本文将介绍Faiss的原理、核心功能以及如何在实际项目中使用它。Faiss原理:近似最近邻搜索:Faiss的核心功能之一是近似最近邻搜索,它能够高效地在大规模数据集中找到与给定查询向量最相似的向量。这种搜索是近似的,
- 在Ubuntu中编译含有JSON的文件出现报错
芝麻糊76
Linuxkill_buglinuxubuntujson
在ubuntu中进行JSON相关学习的时候,我发现了一些小问题,决定与大家进行分享,减少踩坑时候出现不必要的时间耗费截取部分含有JSON部分的代码进行展示char*str="{\"title\":\"JSONExample\",\"author\":{\"name\":\"JohnDoe\",\"age\":35,\"isVerified\":true},\"tags\":[\"json\",\"
- Xinference如何注册自定义模型
玩人工智能的辣条哥
人工智能AI大模型Xinference
环境:Xinference问题描述:Xinference如何注册自定义模型解决方案:1.写个model_config.json,内容如下{"version":1,"context_length":2048,"model_name":"custom-llama-3","model_lang":["en","ch"],"model_ability":["generate","chat"],"model
- 网络编程基础
记得开心一点啊
网络
目录♫什么是网络编程♫Socket套接字♪什么是Socket套接字♪数据报套接字♪流套接字♫数据报套接字通信模型♪数据报套接字通讯模型♪DatagramSocket♪DatagramPacket♪实现UDP的服务端代码♪实现UDP的客户端代码♫流套接字通信模型♪流套接字通讯模型♪ServerSocket♪Socket♪实现TCP的服务端代码♪实现TCP的客户端代码♫什么是网络编程网络编程,指网络上
- K近邻算法_分类鸢尾花数据集
_feivirus_
算法机器学习和数学分类机器学习K近邻
importnumpyasnpimportpandasaspdfromsklearn.datasetsimportload_irisfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportaccuracy_score1.数据预处理iris=load_iris()df=pd.DataFrame(data=ir
- matlab mle 优化,MLE+: Matlab Toolbox for Integrated Modeling, Control and Optimization for Buildings...
Simon Zhong
matlabmle优化
摘要:FollowingunilateralopticnervesectioninadultPVGhoodedrat,theaxonguidancecueephrin-A2isup-regulatedincaudalbutnotrostralsuperiorcolliculus(SC)andtheEphA5receptorisdown-regulatedinaxotomisedretinalgan
- 2021-01-09 哥伦比亚 《梦中的欢快葬礼和十二个异乡故事》 加西亚·马尔克斯 著 罗秀 译
juneyale
《梦中的欢快葬礼和十二个异乡故事》哥伦比亚加西亚·马尔克斯著罗秀译序《总统先生,一路走好!》“再给我一杯咖啡。”他用纯正的法语说。随即补充道:“要意式咖啡,能让人起死回生的那种。”并没有意识到话里的双关含义。当火车开始加速,荷马突然发现总统的手杖还在自己手中,于是跑到站台尽头,把手杖用力扔过去,希望总统能在半空中接住。但是手杖掉在了铁轨上,随即被碾得粉碎。那真是恐怖的一瞬。拉萨拉看到的最后一幕是那
- 博客网站制作教程
2401_85194651
javamaven
首先就是技术框架:后端:Java+SpringBoot数据库:MySQL前端:Vue.js数据库连接:JPA(JavaPersistenceAPI)1.项目结构blog-app/├──backend/│├──src/main/java/com/example/blogapp/││├──BlogApplication.java││├──config/│││└──DatabaseConfig.java
- AI大模型的架构演进与最新发展
季风泯灭的季节
AI大模型应用技术二人工智能架构
随着深度学习的发展,AI大模型(LargeLanguageModels,LLMs)在自然语言处理、计算机视觉等领域取得了革命性的进展。本文将详细探讨AI大模型的架构演进,包括从Transformer的提出到GPT、BERT、T5等模型的历史演变,并探讨这些模型的技术细节及其在现代人工智能中的核心作用。一、基础模型介绍:Transformer的核心原理Transformer架构的背景在Transfo
- 使用由 Python 编写的 lxml 实现高性能 XML 解析
hunyxv
python笔记pythonxml
转载自:文章lxml简介Python从来不出现XML库短缺的情况。从2.0版本开始,它就附带了xml.dom.minidom和相关的pulldom以及SimpleAPIforXML(SAX)模块。从2.4开始,它附带了流行的ElementTreeAPI。此外,很多第三方库可以提供更高级别的或更具有python风格的接口。尽管任何XML库都足够处理简单的DocumentObjectModel(DOM
- LeetCode 53. Maximum Subarray
枯萎的海风
算法与OJC/C++leetcode
1.题目描述Findthecontiguoussubarraywithinanarray(containingatleastonenumber)whichhasthelargestsum.Forexample,giventhearray[−2,1,−3,4,−1,2,1,−5,4],thecontiguoussubarray[4,−1,2,1]hasthelargestsum=6.clicktos
- 助力新能源汽车产业发展,2025第五届广州国际新能源汽车产业智能制造技术展览会将于11月在广州召开
ws201907
制造汽车
助力新能源汽车产业发展,2025第五届广州国际新能源汽车产业智能制造技术展览会将于11月在广州召开伴随着全球新一轮科技革命和产业变革,汽车与能源、半导体、物联网等领域有关技术加速融合,新能源汽车已成为全球汽车产业转型升级的主要方向。近年来,在相关政策的影响下,新能源汽车市场呈现出快速增长的态势,市场规模不断扩大。截至2020年,中国新能源汽车保有量已超过500万辆,成为全球最大的新能源汽车市场。随
- 【LeetCode】53. Maximum Subarray
墨染百城
LeetCodeleetcode
问题描述问题链接:https://leetcode.com/problems/maximum-subarray/#/descriptionFindthecontiguoussubarraywithinanarray(containingatleastonenumber)whichhasthelargestsum.Forexample,giventhearray[-2,1,-3,4,-1,2,1,-
- LeetCode 673. Number of Longest Increasing Subsequence (Java版; Meidum)
littlehaes
字符串动态规划算法leetcode数据结构
welcometomyblogLeetCode673.NumberofLongestIncreasingSubsequence(Java版;Meidum)题目描述Givenanunsortedarrayofintegers,findthenumberoflongestincreasingsubsequence.Example1:Input:[1,3,5,4,7]Output:2Explanatio
- Kubernetes 自定义控制器开发
IT回忆录
Kubeneteskubernetes
目录前言一、CRD二、创建数据库表(Mysql)二、控制器开发1.使用kubernetes的examplecontroller模板2.在controller.go中新增数据表监听方法3.修改tools工具生成资源对象结构体定义这里记录开发k8s控制器的一般方式,controller开发主要使用k8s提供的client-go库进行。前言Controller监听集群内部资源对象的变化,编辑资源对象(增
- 陈悦 | 科学学的起源及其发展
斐夷所非
sciencehistory科学学
作者|陈悦20世纪初,随着科学技术的迅猛发展和科学社会学的兴起,科学学逐渐得到关注和研究。经过百年的发展,科学学正成为一门重要的交叉学科,对科技发展和社会进步产生了深远影响。面对百年未有之大变局加速演进,尤其是世界各国都把目光聚焦于科技,希望通过科技创新找到适应变局的出路时,科学学更凸显其必要性。因此,《世界科学》杂志开设“科学学探索”栏目。一方面,促进更多的人加入科学学的研究和讨论中,深入探讨科
- 前端three.js的Sprite模拟下雪动画效果
qq_35430208
three.js前端javascript三维场景中下雪效果threejs实现下雪效果
一、效果如图所示:二、原理同下雨一样三、完整代码:index.jsimport*asTHREEfrom'three';import{OrbitControls}from'three/addons/controls/OrbitControls.js';importmodelfrom'./model.js';//模型对象//场景constscene=newTHREE.Scene();scene.add
- 2018-08-16【Swift 4.1】 关于Swift4.0以后调用MJExtension无法模型转换问题
码农happy
1、本人使用swift4.1,弄了一晚上才弄好,结果还是一个小问题真是尴尬,要在model中每个属性前面加上@objcimportUIKitclassUserModel:NSObject{@objcvardix=String()}letdic=["dix":"ffffff"]asNSDictionaryletmodel=UserModel.mj_object(withKeyValues:dic)!
- PAT Advanced 1015. Reversible Primes (C语言实现)
OliverLew
我的PAT系列文章更新重心已移至Github,欢迎来看PAT题解的小伙伴请到GithubPages浏览最新内容。此处文章目前已更新至与GithubPages同步。欢迎star我的repo。题目Areversibleprimeinanynumbersystemisaprimewhose"reverse"inthatnumbersystemisalsoaprime.Forexampleinthedec
- 增长黑客和最小可复制的内核
爱思考的糖
五段-增长黑客的三大步骤生活就像逆水行舟,加入你不能加速,现实中最好的情况,你也就处在一种原地打转的状况。增长,就像一辆车里的加速器。围棋爱好者,水平一直没有进步的原因。是因为没有找到提高下棋水平的增长模式有三个办法可以提高:做死活题,练习做关键决策的能力;打谱,复盘经典案例;找AI陪练。增长黑客的三个实战步骤:第一步,假设:建立最小闭环。从笨办法开始,不怕犯错,代价并不高,你可以勇敢尝试。想知道
- ComfyUI中的sam模型国内下载方法
jayli517
ComfyUIpythonstablediffusion
was-node-suite-comfyui这个节点安装的时候,有它内部的config配置文件,里面其实给了一些下载地址,配置文件里是这么写的:"sam_model_vith_url":"https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth","sam_model_vitl_url":"https://dl.fba
- java的四个层级结构
活跃家族
JAVA
java的四个层级结构首先,最底层的就是dto层,dto层就是所谓的model,dto中定义的是实体类,也就是.class文件,该文件中包含实体类的属性和对应属性的get、set方法;其次,是dao层(dao层的文件习惯以*Mapper命名),dao层会调用dto层,dao层中会定义实际使用到的方法,比如增删改查。一般在dao层下还会有个叫做sqlmap的包,该包下有xml文件,文件内容正是根据之
- 小白 | 华为云docker设置镜像加速器
伏一
工具安装华为云docker容器
一、操作场景通过dockerpull命令下载镜像中心的公有镜像时,往往会因为网络原因而需要很长时间,甚至可能因超时而下载失败。为此,容器镜像服务提供了镜像下载加速功能,帮助您获得更快的下载体验。二、约束与限制构建镜像的客户端所安装的容器引擎(Docker)版本必须为1.11.2及以上。“华北-乌兰察布一”、“亚太-雅加达”、“拉美-墨西哥城一”、“拉美-墨西哥城二”和“拉美-圣保罗一”区域不支持该
- tf.get_collection()
yalesaleng
此函数有两个参数,key和scope。Args:1.key:Thekeyforthecollection.Forexample,theGraphKeysclasscontainsmanystandardnamesforcollections.2.scope:(Optional.)Ifsupplied,theresultinglistisfilteredtoincludeonlyitemswhose
- 基于高通主板的ARM架构服务器
问就是想睡觉
arm开发服务器运维
一、ARM架构服务器的崛起(一)市场需求推动消费市场寒冬,全球消费电子需求下行,服务器成半导体核心动力之一。Arm加速布局服务器领域,如9月推出NeoverseV2。长久以来,x86架构主导服务器市场,现面临挑战。Arm2008年入服务器领域,虽因性能与生态问题未大突破,但近几年重新冲刺。(二)技术创新引领Arm的Neoverse平台不断发展。2018年推出参考架构,2020年衍生出E、N、V系列
- SQLite的入门级项目学习记录(二)
深蓝海拓
SQLite学习笔记sqlite学习数据库
再补充一些基础知识:并行操作的问题1、可以多游标同时运行SQLite,对于同一个连接sqlite3.connect(db_file),可以同时创建多个游标,每个游标都是独立的,可以执行各自的SQL命令序列。importsqlite3#创建数据库连接conn=sqlite3.connect('example.db')#创建第一个游标cursor1=conn.cursor()cursor1.execu
- Spring的注解积累
yijiesuifeng
spring注解
用注解来向Spring容器注册Bean。
需要在applicationContext.xml中注册:
<context:component-scan base-package=”pagkage1[,pagkage2,…,pagkageN]”/>。
如:在base-package指明一个包
<context:component-sc
- 传感器
百合不是茶
android传感器
android传感器的作用主要就是来获取数据,根据得到的数据来触发某种事件
下面就以重力传感器为例;
1,在onCreate中获得传感器服务
private SensorManager sm;// 获得系统的服务
private Sensor sensor;// 创建传感器实例
@Override
protected void
- [光磁与探测]金吕玉衣的意义
comsci
这是一个古代人的秘密:现在告诉大家
信不信由你们:
穿上金律玉衣的人,如果处于灵魂出窍的状态,可以飞到宇宙中去看星星
这就是为什么古代
- 精简的反序打印某个数
沐刃青蛟
打印
以前看到一些让求反序打印某个数的程序。
比如:输入123,输出321。
记得以前是告诉你是几位数的,当时就抓耳挠腮,完全没有思路。
似乎最后是用到%和/方法解决的。
而今突然想到一个简短的方法,就可以实现任意位数的反序打印(但是如果是首位数或者尾位数为0时就没有打印出来了)
代码如下:
long num, num1=0;
- PHP:6种方法获取文件的扩展名
IT独行者
PHP扩展名
PHP:6种方法获取文件的扩展名
1、字符串查找和截取的方法
1
$extension
=
substr
(
strrchr
(
$file
,
'.'
), 1);
2、字符串查找和截取的方法二
1
$extension
=
substr
- 面试111
文强chu
面试
1事务隔离级别有那些 ,事务特性是什么(问到一次)
2 spring aop 如何管理事务的,如何实现的。动态代理如何实现,jdk怎么实现动态代理的,ioc是怎么实现的,spring是单例还是多例,有那些初始化bean的方式,各有什么区别(经常问)
3 struts默认提供了那些拦截器 (一次)
4 过滤器和拦截器的区别 (频率也挺高)
5 final,finally final
- XML的四种解析方式
小桔子
domjdomdom4jsax
在平时工作中,难免会遇到把 XML 作为数据存储格式。面对目前种类繁多的解决方案,哪个最适合我们呢?在这篇文章中,我对这四种主流方案做一个不完全评测,仅仅针对遍历 XML 这块来测试,因为遍历 XML 是工作中使用最多的(至少我认为)。 预 备 测试环境: AMD 毒龙1.4G OC 1.5G、256M DDR333、Windows2000 Server
- wordpress中常见的操作
aichenglong
中文注册wordpress移除菜单
1 wordpress中使用中文名注册解决办法
1)使用插件
2)修改wp源代码
进入到wp-include/formatting.php文件中找到
function sanitize_user( $username, $strict = false
- 小飞飞学管理-1
alafqq
管理
项目管理的下午题,其实就在提出问题(挑刺),分析问题,解决问题。
今天我随意看下10年上半年的第一题。主要就是项目经理的提拨和培养。
结合我自己经历写下心得
对于公司选拔和培养项目经理的制度有什么毛病呢?
1,公司考察,选拔项目经理,只关注技术能力,而很少或没有关注管理方面的经验,能力。
2,公司对项目经理缺乏必要的项目管理知识和技能方面的培训。
3,公司对项目经理的工作缺乏进行指
- IO输入输出部分探讨
百合不是茶
IO
//文件处理 在处理文件输入输出时要引入java.IO这个包;
/*
1,运用File类对文件目录和属性进行操作
2,理解流,理解输入输出流的概念
3,使用字节/符流对文件进行读/写操作
4,了解标准的I/O
5,了解对象序列化
*/
//1,运用File类对文件目录和属性进行操作
//在工程中线创建一个text.txt
- getElementById的用法
bijian1013
element
getElementById是通过Id来设置/返回HTML标签的属性及调用其事件与方法。用这个方法基本上可以控制页面所有标签,条件很简单,就是给每个标签分配一个ID号。
返回具有指定ID属性值的第一个对象的一个引用。
语法:
&n
- 励志经典语录
bijian1013
励志人生
经典语录1:
哈佛有一个著名的理论:人的差别在于业余时间,而一个人的命运决定于晚上8点到10点之间。每晚抽出2个小时的时间用来阅读、进修、思考或参加有意的演讲、讨论,你会发现,你的人生正在发生改变,坚持数年之后,成功会向你招手。不要每天抱着QQ/MSN/游戏/电影/肥皂剧……奋斗到12点都舍不得休息,看就看一些励志的影视或者文章,不要当作消遣;学会思考人生,学会感悟人生
- [MongoDB学习笔记三]MongoDB分片
bit1129
mongodb
MongoDB的副本集(Replica Set)一方面解决了数据的备份和数据的可靠性问题,另一方面也提升了数据的读写性能。MongoDB分片(Sharding)则解决了数据的扩容问题,MongoDB作为云计算时代的分布式数据库,大容量数据存储,高效并发的数据存取,自动容错等是MongoDB的关键指标。
本篇介绍MongoDB的切片(Sharding)
1.何时需要分片
&nbs
- 【Spark八十三】BlockManager在Spark中的使用场景
bit1129
manager
1. Broadcast变量的存储,在HttpBroadcast类中可以知道
2. RDD通过CacheManager存储RDD中的数据,CacheManager也是通过BlockManager进行存储的
3. ShuffleMapTask得到的结果数据,是通过FileShuffleBlockManager进行管理的,而FileShuffleBlockManager最终也是使用BlockMan
- yum方式部署zabbix
ronin47
yum方式部署zabbix
安装网络yum库#rpm -ivh http://repo.zabbix.com/zabbix/2.4/rhel/6/x86_64/zabbix-release-2.4-1.el6.noarch.rpm 通过yum装mysql和zabbix调用的插件还有agent代理#yum install zabbix-server-mysql zabbix-web-mysql mysql-
- Hibernate4和MySQL5.5自动创建表失败问题解决方法
byalias
J2EEHibernate4
今天初学Hibernate4,了解了使用Hibernate的过程。大体分为4个步骤:
①创建hibernate.cfg.xml文件
②创建持久化对象
③创建*.hbm.xml映射文件
④编写hibernate相应代码
在第四步中,进行了单元测试,测试预期结果是hibernate自动帮助在数据库中创建数据表,结果JUnit单元测试没有问题,在控制台打印了创建数据表的SQL语句,但在数据库中
- Netty源码学习-FrameDecoder
bylijinnan
javanetty
Netty 3.x的user guide里FrameDecoder的例子,有几个疑问:
1.文档说:FrameDecoder calls decode method with an internally maintained cumulative buffer whenever new data is received.
为什么每次有新数据到达时,都会调用decode方法?
2.Dec
- SQL行列转换方法
chicony
行列转换
create table tb(终端名称 varchar(10) , CEI分值 varchar(10) , 终端数量 int)
insert into tb values('三星' , '0-5' , 74)
insert into tb values('三星' , '10-15' , 83)
insert into tb values('苹果' , '0-5' , 93)
- 中文编码测试
ctrain
编码
循环打印转换编码
String[] codes = {
"iso-8859-1",
"utf-8",
"gbk",
"unicode"
};
for (int i = 0; i < codes.length; i++) {
for (int j
- hive 客户端查询报堆内存溢出解决方法
daizj
hive堆内存溢出
hive> select * from t_test where ds=20150323 limit 2;
OK
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
问题原因: hive堆内存默认为256M
这个问题的解决方法为:
修改/us
- 人有多大懒,才有多大闲 (评论『卓有成效的程序员』)
dcj3sjt126com
程序员
卓有成效的程序员给我的震撼很大,程序员作为特殊的群体,有的人可以这么懒, 懒到事情都交给机器去做 ,而有的人又可以那么勤奋,每天都孜孜不倦得做着重复单调的工作。
在看这本书之前,我属于勤奋的人,而看完这本书以后,我要努力变成懒惰的人。
不要在去庞大的开始菜单里面一项一项搜索自己的应用程序,也不要在自己的桌面上放置眼花缭乱的快捷图标
- Eclipse简单有用的配置
dcj3sjt126com
eclipse
1、显示行号 Window -- Prefences -- General -- Editors -- Text Editors -- show line numbers
2、代码提示字符 Window ->Perferences,并依次展开 Java -> Editor -> Content Assist,最下面一栏 auto-Activation
- 在tomcat上面安装solr4.8.0全过程
eksliang
Solrsolr4.0后的版本安装solr4.8.0安装
转载请出自出处:
http://eksliang.iteye.com/blog/2096478
首先solr是一个基于java的web的应用,所以安装solr之前必须先安装JDK和tomcat,我这里就先省略安装tomcat和jdk了
第一步:当然是下载去官网上下载最新的solr版本,下载地址
- Android APP通用型拒绝服务、漏洞分析报告
gg163
漏洞androidAPP分析
点评:记得曾经有段时间很多SRC平台被刷了大量APP本地拒绝服务漏洞,移动安全团队爱内测(ineice.com)发现了一个安卓客户端的通用型拒绝服务漏洞,来看看他们的详细分析吧。
0xr0ot和Xbalien交流所有可能导致应用拒绝服务的异常类型时,发现了一处通用的本地拒绝服务漏洞。该通用型本地拒绝服务可以造成大面积的app拒绝服务。
针对序列化对象而出现的拒绝服务主要
- HoverTree项目已经实现分层
hvt
编程.netWebC#ASP.ENT
HoverTree项目已经初步实现分层,源代码已经上传到 http://hovertree.codeplex.com请到SOURCE CODE查看。在本地用SQL Server 2008 数据库测试成功。数据库和表请参考:http://keleyi.com/a/bjae/ue6stb42.htmHoverTree是一个ASP.NET 开源项目,希望对你学习ASP.NET或者C#语言有帮助,如果你对
- Google Maps API v3: Remove Markers 移除标记
天梯梦
google maps api
Simply do the following:
I. Declare a global variable:
var markersArray = [];
II. Define a function:
function clearOverlays() {
for (var i = 0; i < markersArray.length; i++ )
- jQuery选择器总结
lq38366
jquery选择器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
- 基础数据结构和算法六:Quick sort
sunwinner
AlgorithmQuicksort
Quick sort is probably used more widely than any other. It is popular because it is not difficult to implement, works well for a variety of different kinds of input data, and is substantially faster t
- 如何让Flash不遮挡HTML div元素的技巧_HTML/Xhtml_网页制作
刘星宇
htmlWeb
今天在写一个flash广告代码的时候,因为flash自带的链接,容易被当成弹出广告,所以做了一个div层放到flash上面,这样链接都是a触发的不会被拦截,但发现flash一直处于div层上面,原来flash需要加个参数才可以。
让flash置于DIV层之下的方法,让flash不挡住飘浮层或下拉菜单,让Flash不档住浮动对象或层的关键参数:wmode=opaque。
方法如下:
- Mybatis实用Mapper SQL汇总示例
wdmcygah
sqlmysqlmybatis实用
Mybatis作为一个非常好用的持久层框架,相关资料真的是少得可怜,所幸的是官方文档还算详细。本博文主要列举一些个人感觉比较常用的场景及相应的Mapper SQL写法,希望能够对大家有所帮助。
不少持久层框架对动态SQL的支持不足,在SQL需要动态拼接时非常苦恼,而Mybatis很好地解决了这个问题,算是框架的一大亮点。对于常见的场景,例如:批量插入/更新/删除,模糊查询,多条件查询,联表查询,