论文复现:Learning Efficient Convolutional Networks through Network Slimming
论文核心
论文提出了一种结构化剪枝策略,剪枝对象为 channel ,对 channel 重要性的评价标准使用的是 Batch Normalization 层中的缩放因子,这不会给网络带来额外的开销。

论文细节品读
带 L 1 L1 L1正则的损失函数:
首先得了解 L 1 L1 L1正则为何能带来稀疏性,相关解释链接
于是论文作者为了诱导 B N BN BN层缩放因子 γ \gamma γ产生稀疏性,对 B N BN BN层的 γ \gamma γ使用 L 1 L1 L1正则,于是更新后的损失函数如下:
L = ∑ ( x , y ) l ( f ( x , W ) , y ) + λ ∑ γ ∈ Γ g ( γ ) { L=\sum\limits_{(x,y)}l(f(x,W),y)+\lambda\sum\limits_{\gamma\in\Gamma}g(\gamma) } L=(x,y)∑l(f(x,W),y)+λγ∈Γ∑g(γ)
而这多出的 L 1 L1 L1正则化项不是处处可导的,反向传播时需要把该部分单独处理。这在论文复现部分讨论。
经典三步走:
同样采用了这里的三步走方式以获取最大剪枝率和精度,这里特点是在训练反向传播过程中加入了对 γ \gamma γ的稀疏诱导。

论文复现
准备:
模型选择resnet18,优化器选择 SGD,等等。保证和上个论文复现实验基本条件一致。上篇论文复现
γ \gamma γ处理方式:
首先对上面内容填坑,给出论文作者是如何处理 L 1 L1 L1正则化下项无法求导(严格的说是不能处处求导,在 x = 0 x=0 x=0处无法求导)从而无法使用传统的梯度下降法的。下面是源码部分:
def updateBN():
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(args.s*torch.sign(m.weight.data)) # L1
在 BN 层中先对 γ \gamma γ求导,也就是 torch.sign(m.weight.data),其实求导的值只有0,1,-1三个。然后乘以一个很小的系数,一般选择0.0001,最后再将该部分的值加入到上一次的 γ \gamma γ导数值之中。这个过程在反向传播。
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
# 反向传播时更新γ的梯度值
if args.sr:
updateBN()
optimizer.step()
Channel 剪枝:
源码是先统计所有 feature map 的总 channel 数,也就是 γ \gamma γ总个数。
由于源码给出的是 VGG 网络的剪枝,而我实验的网络为 resnet18,其中存在 Shoutcut 结构,因此不能像 VGG 一样无脑的统计所有 channel 数, 需要特殊的处理方式。因为论文中也没有提到对 Shoutcut 的特殊处理方式,所以这里就自由发挥了。
为了简化实验,我选择将 Shoutcut 连接的 feature map 不做剪枝处理,这实际是只对8个 feature map 剪枝。下图中被红色框框选的 block 是我要剪枝的目标。

下面是我关键思路的代码,这部分代码参杂较多个人修改的东西,如有不恰当的地方,请指正:
# channel 剪枝 --- Learning Efficient Convolutional Networks through Network Slimming
def prune_channel(model, prune_rates):
total = 0
count = 0
# 和shortcut不相关的block,会被裁剪
prune_block = [1, 3, 5, 8, 10, 13, 15, 18]
# basicblock 中和 shoutcut关联的block
block_basic_sc_connect = [2, 4, 6, 9, 11, 14, 16, 19]
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
if prune_block.count(count) == 1:
total += m.weight.data.shape[0]
count += 1
bn = torch.zeros(total)
index = 0
count = 0
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
if prune_block.count(count) == 1:
size = m.weight.data.shape[0]
bn[index:(index + size)] = m.weight.data.abs().clone() # 将bn中weight都取绝对值
index += size
count += 1
y, i = torch.sort(bn) # 从小到大排序
thre_index = total * prune_rates // 100
thre = y[thre_index]
pruned = 0
count = 0
cfg = []
cfg_mask = []
for k, m in enumerate(model.modules()):
if isinstance(m, nn.BatchNorm2d):
if prune_block.count(count) == 1:
weight_copy = m.weight.data.abs().clone()
mask = weight_copy.gt(thre).float()
# 基于源码修改
# 源码中修剪率较大时导致某些feature map channel数为0,破坏了模型结构 \
# 因此在此基础上略作修改,当某个BN层所有γ都小于或等于阈值时,保留最大值
if torch.sum(mask) == 0:
# 获取 weight_copy 中最大值的索引
idx = np.argmax(weight_copy.cpu().numpy())
# 使mask对应位置为True
mask[idx] = True
pruned = pruned + mask.shape[0] - torch.sum(mask)
# m.weight.data.mul_(mask)
# m.bias.data.mul_(mask)
cfg.append(int(torch.sum(mask)))
cfg_mask.append(mask.clone())
print('layer index: {:d} \t total channel: {:d} \t remaining channel: {:d}'.
format(k, mask.shape[0], int(torch.sum(mask))))
elif block_basic_sc_connect.count(count) == 1:
weight_copy = m.weight.data.abs().clone()
mask = torch.ones(weight_copy.shape)
cfg.append(int(torch.sum(mask)))
cfg_mask.append(mask.clone())
count += 1
print(cfg)
pruned_ratio = pruned / total
return [cfg, cfg_mask, pruned_ratio]
# 剪枝后的数据拷贝 --- Learning Efficient Convolutional Networks through Network Slimming
def copy_data(model, new_model, cfg_mask, optimizer, save_path):
# 新模型拷贝原模型对应结构的参数值
count = 0
# basicblock bn index
basicblock_bn_index = [1, 2, 3, 4, 5, 6, 8, 9, 10, 11, 13, 14, 15, 16, 18, 19]
for [m0, m1] in zip(model.modules(), new_model.modules()):
if isinstance(m0, nn.BatchNorm2d):
# 先复制basicblock中BN层参数
if basicblock_bn_index.count(count) == 1:
# 找出该层非零γ的索引
idx1 = np.squeeze(np.argwhere(np.asarray(cfg_mask[basicblock_bn_index.index(count)].cpu().numpy())))
# 另外开辟一片空间来存储新模型的参数值
m1.weight.data = m0.weight.data[idx1].clone()
m1.bias.data = m0.bias.data[idx1].clone()
m1.running_mean = m0.running_mean[idx1].clone()
m1.running_var = m0.running_var[idx1].clone()
# 非basicblock中的bn层不会被剪枝,直接复制即可
else:
m1.weight.data = m0.weight.data.clone()
m1.bias.data = m0.bias.data.clone()
m1.running_mean = m0.running_mean.clone()
m1.running_var = m0.running_var.clone()
count += 1
elif isinstance(m0, nn.Conv2d):
# 先复制basicblock中Conv层参数
if basicblock_bn_index.count(count) == 1 and count != 1:
idx0 = np.squeeze(np.argwhere(np.asarray(cfg_mask[basicblock_bn_index.index(count) - 1].cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(cfg_mask[basicblock_bn_index.index(count)].cpu().numpy())))
# 第一层Conv和三层Shoutcut单独处理
else:
# 第一层卷积
if count == 0:
idx0 = np.squeeze(np.argwhere(np.asarray(torch.ones(3).cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(torch.ones(64).cpu().numpy())))
# 第一层Basicblock也需要单独处理一下
if count == 1:
idx0 = np.squeeze(np.argwhere(np.asarray(torch.ones(64).cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(cfg_mask[0].cpu().numpy())))
# 第一层Shoutcut
elif count == 7:
idx0 = np.squeeze(np.argwhere(np.asarray(cfg_mask[3].cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(cfg_mask[5].cpu().numpy())))
# 第二层Shoutcut
elif count == 12:
idx0 = np.squeeze(np.argwhere(np.asarray(cfg_mask[7].cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(cfg_mask[9].cpu().numpy())))
# 第三层Shoutcut
elif count == 17:
idx0 = np.squeeze(np.argwhere(np.asarray(cfg_mask[11].cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(cfg_mask[13].cpu().numpy())))
# 输出通道数, 输入通道数, kernel_size, kernel_size
# 去掉输入被裁剪掉的通道对应的weight(裁剪卷积核的通道数)
w = m0.weight.data[:, idx0, :, :].clone()
# 去掉输出被裁剪掉的通道对应的weight(裁剪掉卷积核的个数)
w = w[idx1, :, :, :].clone()
m1.weight.data = w.clone()
# m1.bias.data = m0.bias.data[idx1].clone()
elif isinstance(m0, nn.Linear):
idx0 = np.squeeze(np.argwhere(np.asarray(cfg_mask[15].cpu().numpy())))
# 输出特征数, 输入特征数
m1.weight.data = m0.weight.data[:, idx0].clone()
state = {
"net": new_model.state_dict(),
"optimizer": optimizer.state_dict(),
}
torch.save(state, save_path)
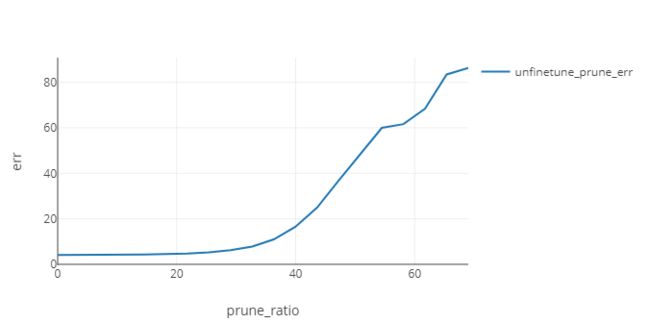
未微调前精度检测:
此处修剪比例是8个 block 中 channel 的比例,未被修剪的 block 不参与计算。从下图可见当修剪比例达到40以上时,模型精度就开始急剧下降。
微调后精度检测:
这里记录一个奇怪的实验现状,如果采用循环迭代修剪(即每次修剪是基于上一次修剪完并微调后的网络),则每次修剪都是大幅度修剪最后一个 block ,其他7个 block 几乎没有改变,这导致修剪不到20%的时候就出现最后一个 block channel 只剩一层。因此改变策略,选择每次修剪都是基于原始网络。
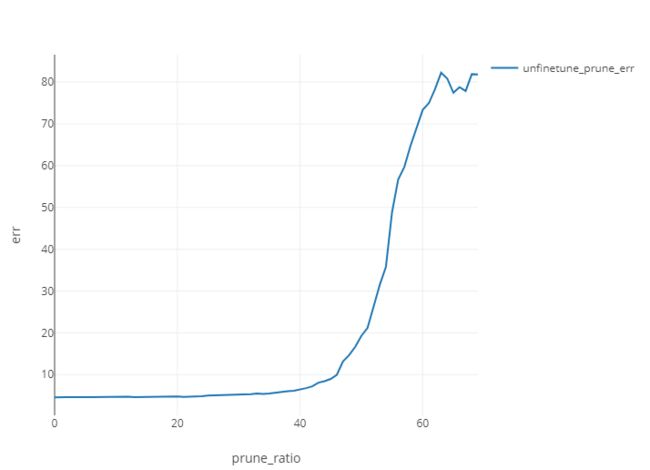
相对于微调前,模型获得了更高的准确率,在修剪率为40%之前,模型的几乎没有精度损失。通过 torchstat 来检测修剪率为40%的模型,可以观察到,模型的参数量降为5.02M,为未剪枝之前的一半,计算量为436.23MFLOPs,较之前降低了约1/5。
module name input shape output shape params memory(MB) MAdd Flops MemRead(B) MemWrite(B) duration[%] MemR+W(B)
0 conv_bn_relu.conv 3 32 32 64 32 32 1728.0 0.25 3,473,408.0 1,769,472.0 19200.0 262144.0 0.00% 281344.0
1 conv_bn_relu.bn 64 32 32 64 32 32 128.0 0.25 262,144.0 131,072.0 262656.0 262144.0 0.00% 524800.0
2 conv_bn_relu.relu 64 32 32 64 32 32 0.0 0.25 65,536.0 65,536.0 262144.0 262144.0 0.00% 524288.0
3 layer1.0.conv1.conv 64 32 32 58 32 32 33408.0 0.23 68,360,192.0 34,209,792.0 395776.0 237568.0 26.31% 633344.0
4 layer1.0.conv1.bn 58 32 32 58 32 32 116.0 0.23 237,568.0 118,784.0 238032.0 237568.0 0.00% 475600.0
5 layer1.0.conv1.relu 58 32 32 58 32 32 0.0 0.23 59,392.0 59,392.0 237568.0 237568.0 0.00% 475136.0
6 layer1.0.conv2.conv 58 32 32 64 32 32 33408.0 0.25 68,354,048.0 34,209,792.0 371200.0 262144.0 5.26% 633344.0
7 layer1.0.conv2.bn 64 32 32 64 32 32 128.0 0.25 262,144.0 131,072.0 262656.0 262144.0 0.00% 524800.0
8 layer1.0.conv2.relu 64 32 32 64 32 32 0.0 0.25 0.0 0.0 0.0 0.0 0.00% 0.0
9 layer1.0.shortcut 64 32 32 64 32 32 0.0 0.25 0.0 0.0 0.0 0.0 0.00% 0.0
10 layer1.1.conv1.conv 64 32 32 62 32 32 35712.0 0.24 73,074,688.0 36,569,088.0 404992.0 253952.0 5.26% 658944.0
11 layer1.1.conv1.bn 62 32 32 62 32 32 124.0 0.24 253,952.0 126,976.0 254448.0 253952.0 0.00% 508400.0
12 layer1.1.conv1.relu 62 32 32 62 32 32 0.0 0.24 63,488.0 63,488.0 253952.0 253952.0 5.26% 507904.0
13 layer1.1.conv2.conv 62 32 32 64 32 32 35712.0 0.25 73,072,640.0 36,569,088.0 396800.0 262144.0 0.00% 658944.0
14 layer1.1.conv2.bn 64 32 32 64 32 32 128.0 0.25 262,144.0 131,072.0 262656.0 262144.0 0.00% 524800.0
15 layer1.1.conv2.relu 64 32 32 64 32 32 0.0 0.25 0.0 0.0 0.0 0.0 0.00% 0.0
16 layer1.1.shortcut 64 32 32 64 32 32 0.0 0.25 0.0 0.0 0.0 0.0 0.00% 0.0
17 layer2.0.conv1.conv 64 32 32 128 16 16 73728.0 0.12 37,715,968.0 18,874,368.0 557056.0 131072.0 0.00% 688128.0
18 layer2.0.conv1.bn 128 16 16 128 16 16 256.0 0.12 131,072.0 65,536.0 132096.0 131072.0 0.00% 263168.0
19 layer2.0.conv1.relu 128 16 16 128 16 16 0.0 0.12 32,768.0 32,768.0 131072.0 131072.0 0.00% 262144.0
20 layer2.0.conv2.conv 128 16 16 128 16 16 147456.0 0.12 75,464,704.0 37,748,736.0 720896.0 131072.0 5.27% 851968.0
21 layer2.0.conv2.bn 128 16 16 128 16 16 256.0 0.12 131,072.0 65,536.0 132096.0 131072.0 0.00% 263168.0
22 layer2.0.conv2.relu 128 16 16 128 16 16 0.0 0.12 0.0 0.0 0.0 0.0 0.00% 0.0
23 layer2.0.shortcut.conv_bn.conv 64 32 32 128 16 16 8192.0 0.12 4,161,536.0 2,097,152.0 294912.0 131072.0 5.26% 425984.0
24 layer2.0.shortcut.conv_bn.bn 128 16 16 128 16 16 256.0 0.12 131,072.0 65,536.0 132096.0 131072.0 0.00% 263168.0
25 layer2.0.shortcut.conv_bn.relu 128 16 16 128 16 16 0.0 0.12 0.0 0.0 0.0 0.0 0.00% 0.0
26 layer2.1.conv1.conv 128 16 16 115 16 16 132480.0 0.11 67,800,320.0 33,914,880.0 660992.0 117760.0 0.00% 778752.0
27 layer2.1.conv1.bn 115 16 16 115 16 16 230.0 0.11 117,760.0 58,880.0 118680.0 117760.0 0.00% 236440.0
28 layer2.1.conv1.relu 115 16 16 115 16 16 0.0 0.11 29,440.0 29,440.0 117760.0 117760.0 0.00% 235520.0
29 layer2.1.conv2.conv 115 16 16 128 16 16 132480.0 0.12 67,796,992.0 33,914,880.0 647680.0 131072.0 5.26% 778752.0
30 layer2.1.conv2.bn 128 16 16 128 16 16 256.0 0.12 131,072.0 65,536.0 132096.0 131072.0 0.00% 263168.0
31 layer2.1.conv2.relu 128 16 16 128 16 16 0.0 0.12 0.0 0.0 0.0 0.0 0.00% 0.0
32 layer2.1.shortcut 128 16 16 128 16 16 0.0 0.12 0.0 0.0 0.0 0.0 0.00% 0.0
33 layer3.0.conv1.conv 128 16 16 256 8 8 294912.0 0.06 37,732,352.0 18,874,368.0 1310720.0 65536.0 5.26% 1376256.0
34 layer3.0.conv1.bn 256 8 8 256 8 8 512.0 0.06 65,536.0 32,768.0 67584.0 65536.0 0.00% 133120.0
35 layer3.0.conv1.relu 256 8 8 256 8 8 0.0 0.06 16,384.0 16,384.0 65536.0 65536.0 0.00% 131072.0
36 layer3.0.conv2.conv 256 8 8 256 8 8 589824.0 0.06 75,481,088.0 37,748,736.0 2424832.0 65536.0 5.26% 2490368.0
37 layer3.0.conv2.bn 256 8 8 256 8 8 512.0 0.06 65,536.0 32,768.0 67584.0 65536.0 0.00% 133120.0
38 layer3.0.conv2.relu 256 8 8 256 8 8 0.0 0.06 0.0 0.0 0.0 0.0 0.00% 0.0
39 layer3.0.shortcut.conv_bn.conv 128 16 16 256 8 8 32768.0 0.06 4,177,920.0 2,097,152.0 262144.0 65536.0 5.26% 327680.0
40 layer3.0.shortcut.conv_bn.bn 256 8 8 256 8 8 512.0 0.06 65,536.0 32,768.0 67584.0 65536.0 0.00% 133120.0
41 layer3.0.shortcut.conv_bn.relu 256 8 8 256 8 8 0.0 0.06 0.0 0.0 0.0 0.0 0.00% 0.0
42 layer3.1.conv1.conv 256 8 8 230 8 8 529920.0 0.06 67,815,040.0 33,914,880.0 2185216.0 58880.0 5.26% 2244096.0
43 layer3.1.conv1.bn 230 8 8 230 8 8 460.0 0.06 58,880.0 29,440.0 60720.0 58880.0 0.00% 119600.0
44 layer3.1.conv1.relu 230 8 8 230 8 8 0.0 0.06 14,720.0 14,720.0 58880.0 58880.0 0.00% 117760.0
45 layer3.1.conv2.conv 230 8 8 256 8 8 529920.0 0.06 67,813,376.0 33,914,880.0 2178560.0 65536.0 5.26% 2244096.0
46 layer3.1.conv2.bn 256 8 8 256 8 8 512.0 0.06 65,536.0 32,768.0 67584.0 65536.0 0.00% 133120.0
47 layer3.1.conv2.relu 256 8 8 256 8 8 0.0 0.06 0.0 0.0 0.0 0.0 0.00% 0.0
48 layer3.1.shortcut 256 8 8 256 8 8 0.0 0.06 0.0 0.0 0.0 0.0 0.00% 0.0
49 layer4.0.conv1.conv 256 8 8 225 4 4 518400.0 0.01 16,585,200.0 8,294,400.0 2139136.0 14400.0 0.00% 2153536.0
50 layer4.0.conv1.bn 225 4 4 225 4 4 450.0 0.01 14,400.0 7,200.0 16200.0 14400.0 0.00% 30600.0
51 layer4.0.conv1.relu 225 4 4 225 4 4 0.0 0.01 3,600.0 3,600.0 14400.0 14400.0 0.00% 28800.0
52 layer4.0.conv2.conv 225 4 4 512 4 4 1036800.0 0.03 33,169,408.0 16,588,800.0 4161600.0 32768.0 0.00% 4194368.0
53 layer4.0.conv2.bn 512 4 4 512 4 4 1024.0 0.03 32,768.0 16,384.0 36864.0 32768.0 0.00% 69632.0
54 layer4.0.conv2.relu 512 4 4 512 4 4 0.0 0.03 0.0 0.0 0.0 0.0 0.00% 0.0
55 layer4.0.shortcut.conv_bn.conv 256 8 8 512 4 4 131072.0 0.03 4,186,112.0 2,097,152.0 589824.0 32768.0 0.00% 622592.0
56 layer4.0.shortcut.conv_bn.bn 512 4 4 512 4 4 1024.0 0.03 32,768.0 16,384.0 36864.0 32768.0 5.26% 69632.0
57 layer4.0.shortcut.conv_bn.relu 512 4 4 512 4 4 0.0 0.03 0.0 0.0 0.0 0.0 0.00% 0.0
58 layer4.1.conv1.conv 512 4 4 77 4 4 354816.0 0.00 11,352,880.0 5,677,056.0 1452032.0 4928.0 5.26% 1456960.0
59 layer4.1.conv1.bn 77 4 4 77 4 4 154.0 0.00 4,928.0 2,464.0 5544.0 4928.0 5.26% 10472.0
60 layer4.1.conv1.relu 77 4 4 77 4 4 0.0 0.00 1,232.0 1,232.0 4928.0 4928.0 0.00% 9856.0
61 layer4.1.conv2.conv 77 4 4 512 4 4 354816.0 0.03 11,345,920.0 5,677,056.0 1424192.0 32768.0 0.00% 1456960.0
62 layer4.1.conv2.bn 512 4 4 512 4 4 1024.0 0.03 32,768.0 16,384.0 36864.0 32768.0 0.00% 69632.0
63 layer4.1.conv2.relu 512 4 4 512 4 4 0.0 0.03 0.0 0.0 0.0 0.0 0.00% 0.0
64 layer4.1.shortcut 512 4 4 512 4 4 0.0 0.03 0.0 0.0 0.0 0.0 0.00% 0.0
65 linear 512 10 5130.0 0.00 10,230.0 5,120.0 22568.0 40.0 0.00% 22608.0
total 5020744.0 7.47 871,589,238.0 436,232,736.0 22568.0 40.0 100.00% 32021064.0
====================================================================================================================================================================
Total params: 5,020,744
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
Total memory: 7.47MB
Total MAdd: 871.59MMAdd
Total Flops: 436.23MFlops
Total MemR+W: 30.54MB
总结
该次论文复现,个人在代码部分改动较大,因为源码不适合 resnet18 的网络结构,因此无法和论文原文中结果进行比较(论文中有在resnet164 中进行修剪,但是个人电脑拉跨,我就不跑 resnet164 了)。总的来说,虽然实验只是简单的对8个 block 进行了剪枝,但是剪枝结果还是挺不错的,在几乎没有损坏精度的前提下,模型的参数量和计算量都得到了大幅度的降低。后续有时间也会对剪枝方案进行改进,针对更多的 block 进行剪枝。此次实验到此结束,后续会继续更新其他论文的剪枝方案及其复现过程。