Learning both Weights and Connections for Efficient Neural Networks 论文pytorch复现
Learning both Weights and Connections for Efficient Neural Networks 论文pytorch复现
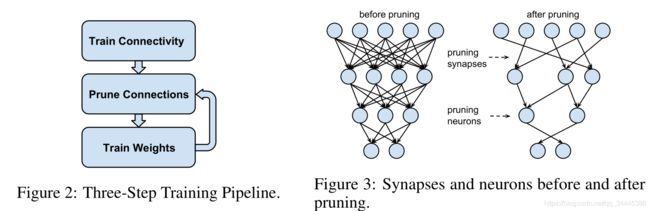
这是论文中主要的步骤,因此我们复现的时候也主要是利用这个思想。
代码编写需要两个主要部分,首先原来神经网络的训练,然后就是神经网络的裁剪。我这次实验主要是使用论文中说的Lenet-300-100网络来进行测试。
网络的定义以及初次训练
##############先导入需要的包###############################
import torch
import torch.nn as nn
from torchvision import datasets, transforms
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torch.nn.functional as F
##############导入手写数字体数据###############################
batch_size = 128
mnist_data = datasets.MNIST('./mnist_data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
]))
dataloader = torch.utils.data.DataLoader(dataset=mnist_data,
batch_size=batch_size,
shuffle=True,num_workers = 20)
##############显示手写数字体数据###############################
for i in range(10):
plt.figure()
plt.imshow(next(iter(dataloader))[0][0][0],cmap="gray")
##############定义网络Lenet-300-100网络###############################
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, 300)
self.fc2 = nn.Linear(300, 100)
self.fc3 = nn.Linear(100, 10)
def forward(self, x):
x = x.view(-1,28*28)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim=1)
def train(model, device, train_loader, optimizer, epoch, log_interval=100):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print("Train Epoch: {} [{}/{} ({:0f}%)]\tLoss: {:.6f}".format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()
))
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
##############初次训练###############################
lr = 0.01
momentum = 0.25
torch.manual_seed(53113)
batch_size = test_batch_size = 128
kwargs = {'num_workers': 40, 'pin_memory': True} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./mnist_data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./mnist_data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=test_batch_size, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
epochs = 20
for epoch in range(1, epochs + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
训练好网络信息的显示
#####################获取一张图像信息#################################
image = next(iter(dataloader))[0][0][0]
output = model.forward(image)
pred = output.argmax(dim=1, keepdim=True)
print(pred) #预测值
#####################显示这张图像#################################
plt.figure()
plt.imshow(image,cmap="gray")
plt.show()
#####################图像预处理#################################
image = image.reshape(-1,28*28)
image = image.data.numpy()
image_count = image.copy()
#####################计算图像非零点个数#################################
image_count[image_count != 0] = 1
count = np.sum(image_count)
print(count)
#####################转化到numpy对数据进行处理#################################
fc1 = model.fc1.weight.data.cpu().numpy()
fc2 = model.fc2.weight.data.cpu().numpy()
fc3 = model.fc3.weight.data.cpu().numpy()
hidden1 = image.dot(fc1.T)
hidden1 = np.maximum(0, hidden1) #激活
hidden2 = hidden1.dot(fc2.T)
hidden2 = np.maximum(0, hidden2)
hidden3 = hidden2.dot(fc3.T)
#####################第一层神经元激活的个数#################################
hidden1_count = hidden1.copy()
hidden1_count[hidden1_count > 0] = 1
count = np.sum(hidden1_count)
print(count)
#####################第二层神经元激活的个数#################################
hidden2_count = hidden2.copy()
hidden2_count[hidden2_count > 0] = 1
count = np.sum(hidden2_count)
print(count)
#####################输出预测结果#################################
out = np.exp(hidden3)
out = out / np.sum(out)
print(np.argmax(out))
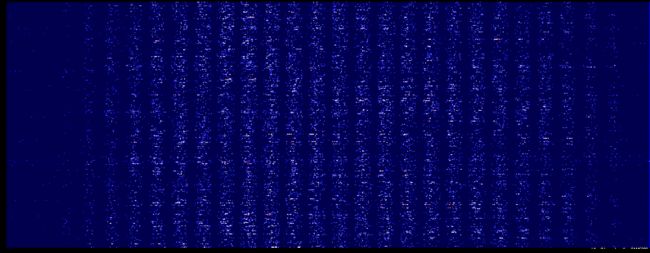
#####################第一层神经元参数信息的图像深度显示,从这里可以观测出权重的变化#################################
fc1_plt = np.abs(fc1)
print("min",np.min(fc1_plt),"max",np.max(fc1_plt))
plt.figure(figsize=(50,50))
im = plt.imshow(fc1_plt, vmin = np.min(fc1_plt), vmax = np.max(fc1_plt) ,cmap = 'seismic')
plt.show()
剪枝操作
##########################函数定义###########################################
def expand_model(model, layers=torch.Tensor()):
for layer in model.children():
layers = torch.cat((layers.view(-1), layer.weight.view(-1))) #将所有的参数拼接在一起
return layers
def calculate_threshold(model, rate): #求取所有参数的阈值所在的数值大小
empty = torch.Tensor()
if torch.cuda.is_available():
empty = empty.cuda()
pre_abs = expand_model(model, empty) #获取所有的参数为一行
weights = torch.abs(pre_abs) #求绝对值
return np.percentile(weights.detach().cpu().numpy(), rate)
def prune(model, threshold):
model.fc1.weight.data = torch.mul(torch.gt(torch.abs(model.fc1.weight.data), threshold), model.fc1.weight.data)
model.fc2.weight.data = torch.mul(torch.gt(torch.abs(model.fc2.weight.data), threshold), model.fc2.weight.data)
model.fc3.weight.data = torch.mul(torch.gt(torch.abs(model.fc3.weight.data), threshold), model.fc3.weight.data)
def retrain(model, device, train_loader, test_loader, epochs, lr, momentum):
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
for epoch in range(1, epochs + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
##########################按百分比计算剪枝的阈值###########################################
threshold = calculate_threshold(model, 96)
print(threshold)
##########################进行剪枝操作并计算测试正确率###########################################
prune(model, threshold)
test(model, device, test_loader)
##########################剪枝操作后进行再次训练###########################################
retrain(model, device, train_loader ,test_loader, 20, 0.001, 0.25)
权重柱状图绘制
# 提取绘制的数据
def paraCount(layers, location, index):
values = []
for value in layers:
if location[index] == 0:
values.append(value)
index += 1
values = np.array(values)
return values
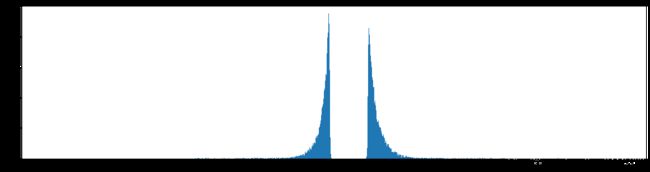
###########################绘制剪枝后的整体参数分布############################
layers = expand_model(model)
layers = layers.detach().cpu().numpy()
values = paraCount(layers, location, 0)
plt.figure(figsize=(20,5))
plt.hist(values, bins = 1000)
plt.show()
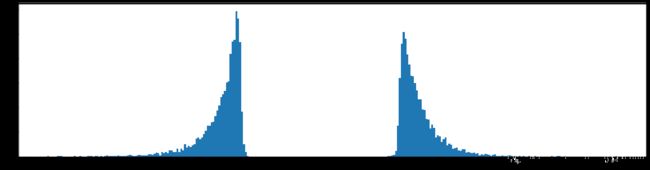
###########################绘制第一层网络参数分布############################
fc1_hist = fc1.reshape(-1)
fc1_hist = paraCount(fc1_hist, location, 0)
plt.figure(figsize=(20,5))
plt.hist(fc1_hist, bins = 300)
plt.show()
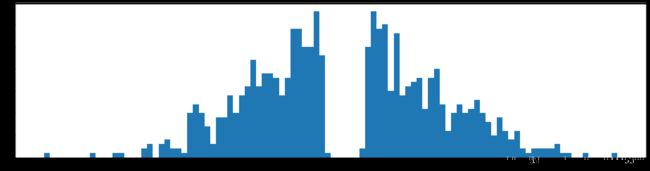
###########################绘制第二层网络参数分布############################
fc2_hist = fc2.reshape(-1)
fc2_hist = paraCount(fc2_hist, location, fc1.shape[0] * fc1.shape[1])
plt.figure(figsize=(20,5))
plt.hist(fc2_hist, bins = 100)
plt.show()
###########################绘制第三层网络参数分布############################
fc3_hist = fc3.reshape(-1)
fc3_hist = paraCount(fc3_hist,location, fc1.shape[0] * fc1.shape[1] + fc2.shape[0] * fc2.shape[1])
plt.figure(figsize=(20,5))
plt.hist(fc3_hist, bins = 100)
plt.show()
这个剪枝操作需要重复进行,这个全连接的神经网络,我可以剪枝掉98%后,正确率还是会有90%,而且经过多次剪枝操作后,网络大部分的参数接近与零,只有重要的参数才会起作用。
jupyter下实现的代码,需要的可以去下载: link.
实验
下面就是基于以上的代码,使用手写数字体的数据集进行的实验,我会记录实验过程中的数据变化过程。
初次训练网络
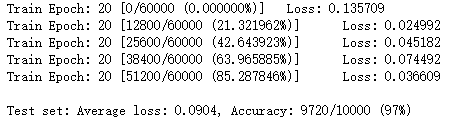
神经元激活
从上图可以看出,经过20次的迭代,网络的正确率已经到达了97%
对于数字4的图像进行识别,图像的非零点数是75个,第一层神经元激活个数169,第二层神经元激活个数70,识别结果是4正确
| 层数 | 个数 |
|---|---|
| fc1 | 169 |
| fc2 | 70 |
| fc3 | 结果是4 |
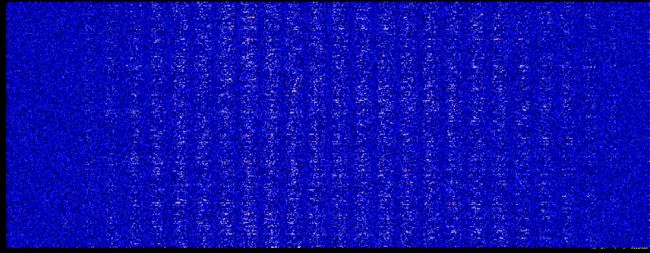
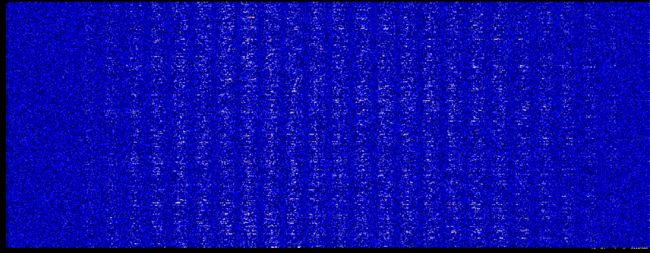
第一层权重的深度分布图
下面是初次训练第一层权重的深度分布图,从这里可以明显的看到了28的分割轮廓了,两端的参数较小,不太重要。
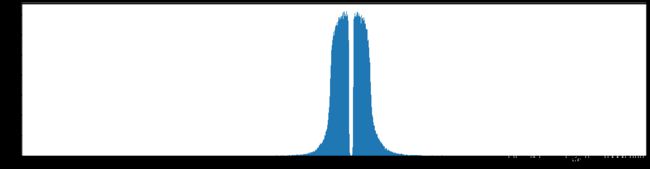
权重柱状图
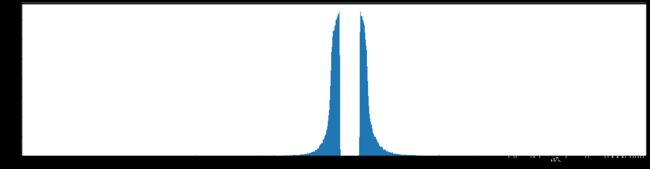
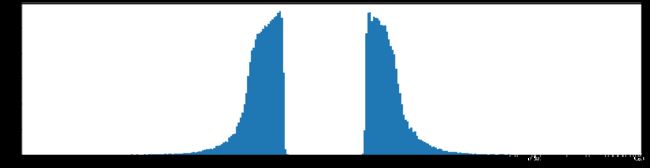
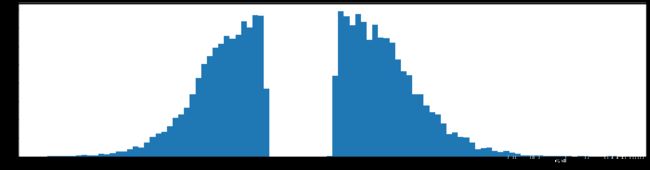
下图是全部参数的柱状图、第一层参数的柱状图、第二层参数的柱状图、第三层参数的柱状图,可以看出参数都基本集中的0附近,成中心分布的样子。
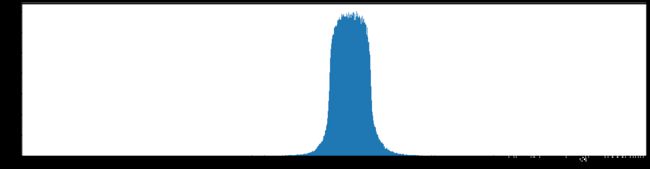
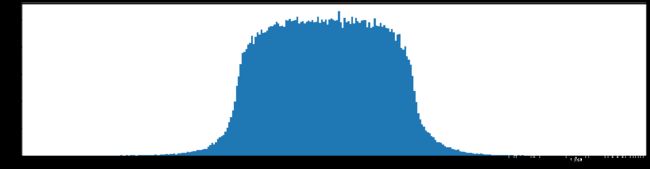
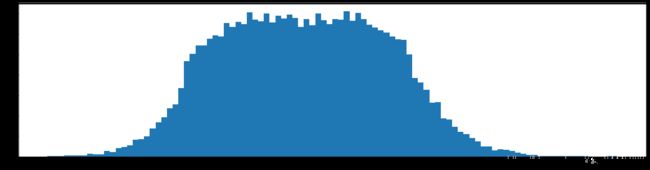
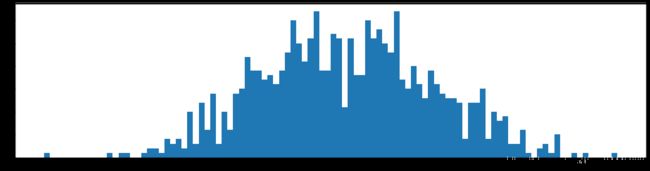
剪枝10%参数
计算出来的阈值是:0.0038155303103849293
![]()
剪枝后的正确率并没有明显的变化,仍旧是97%
然后进行再训练

比初次训练的正确个数还多了,说不定这个可以增加泛化能力。
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 167 |
| fc2 | 71 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,亮的地方变的更亮了一点。
权重柱状图
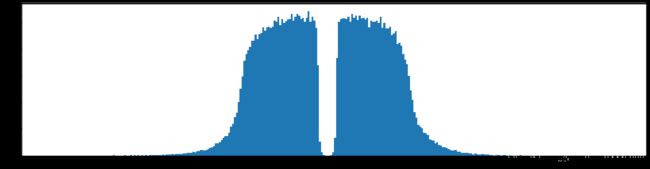
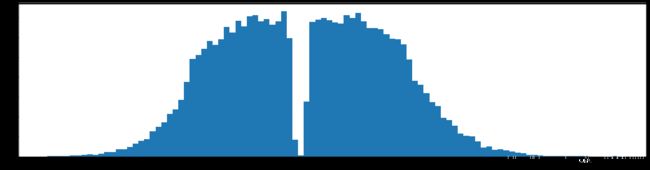
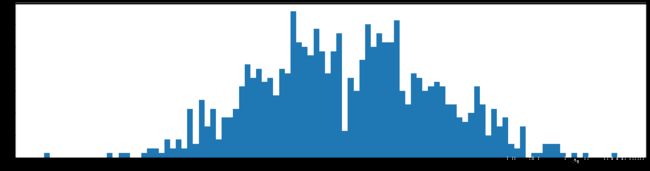
剪枝20%参数
计算出来的阈值是:0.007650174759328366
![]()
剪枝后的正确率并没有明显的变化,仍旧是97%
然后进行再训练
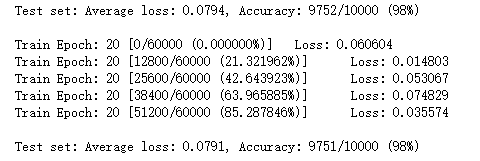
比上训练的正确个数还多了,又增加泛化能力。
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 172 |
| fc2 | 73 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方增多了
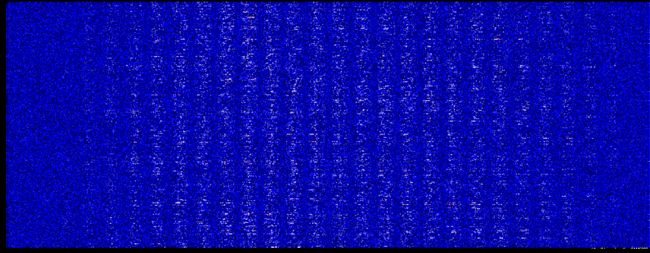
权重柱状图
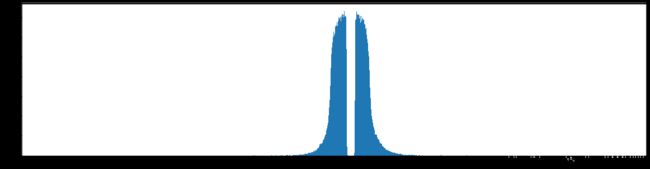
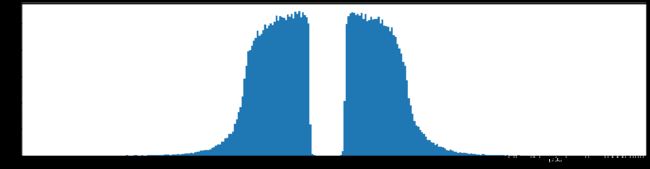
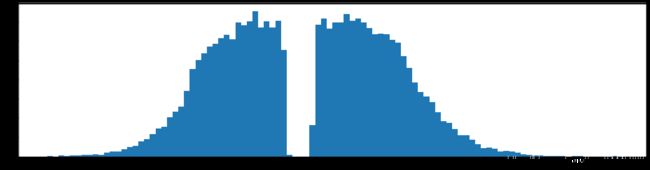
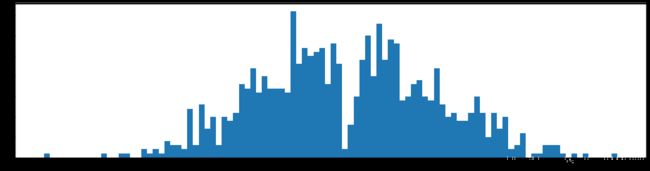
剪枝30%参数
计算出来的阈值是:0.01150485947728157
![]()
剪枝后的正确率并没有明显的变化,仍旧是97%
然后进行再训练

比上训练的正确个数还多了,又增加泛化能力。
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 169 |
| fc2 | 74 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
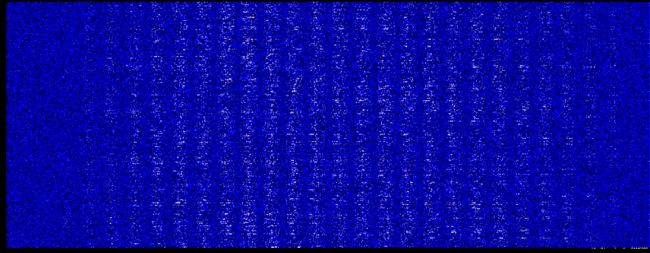
权重柱状图

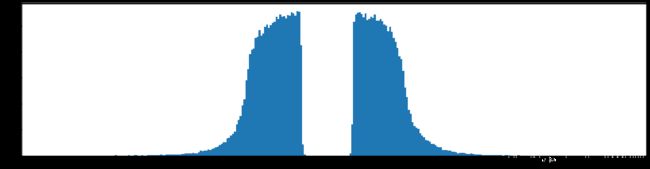
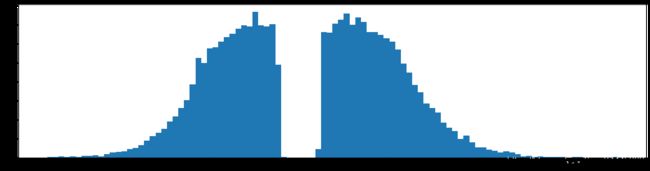
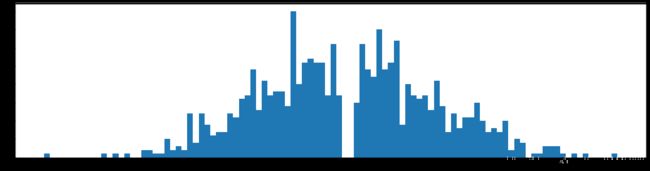
剪枝40%参数
计算出来的阈值是:0.01536105088889599
![]()
剪枝后的正确率并没有明显的变化,仍旧是97%
然后进行再训练

比上训练的正确个数还多了,又增加泛化能力。
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 167 |
| fc2 | 73 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
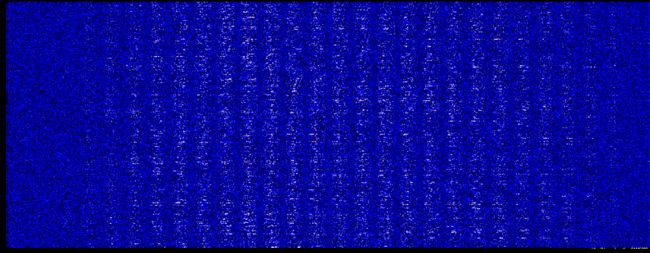
权重柱状图

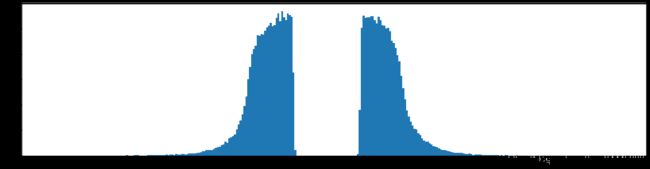
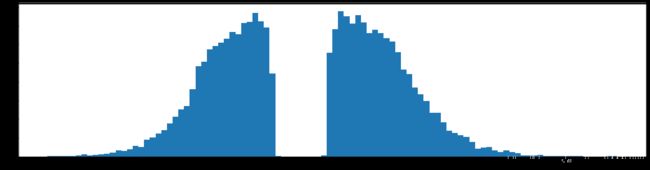
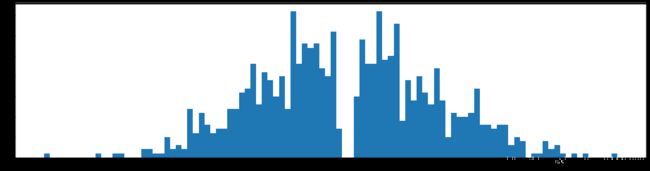
剪枝50%参数
计算出来的阈值是:0.019335072487592697
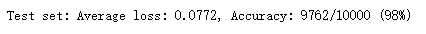
剪枝后的正确率并没有明显的变化,仍旧是97%
然后进行再训练

比上训练的正确个数还多了,又增加泛化能力。
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 171 |
| fc2 | 73 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
权重柱状图
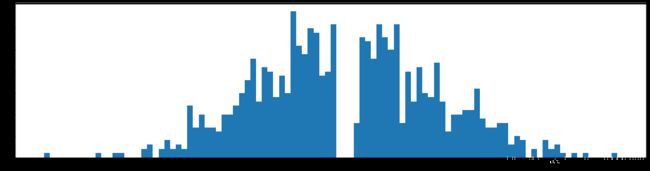
剪枝60%参数
计算出来的阈值是:0.023352954909205435
![]()
剪枝后的正确率并没有明显的变化,仍旧是97%
然后进行再训练

比上训练的正确个数还多了,又增加泛化能力。
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 176 |
| fc2 | 74 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
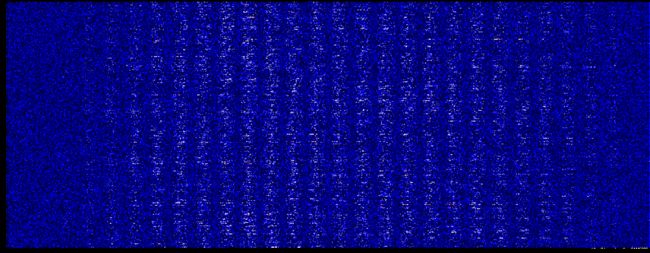
权重柱状图
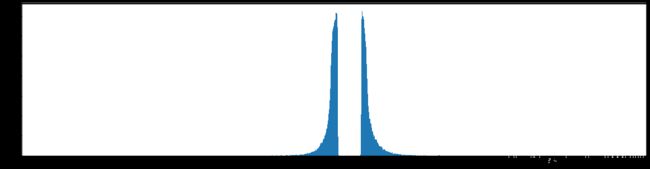
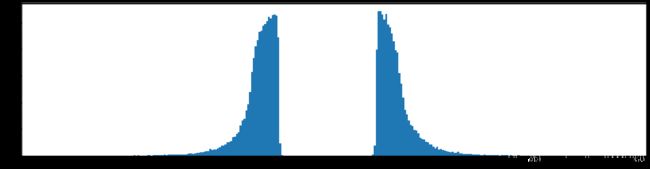
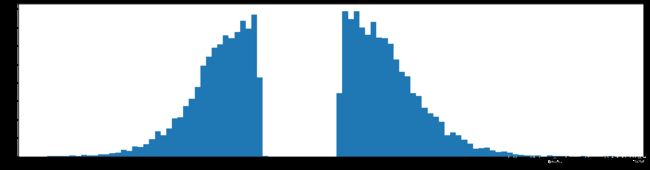
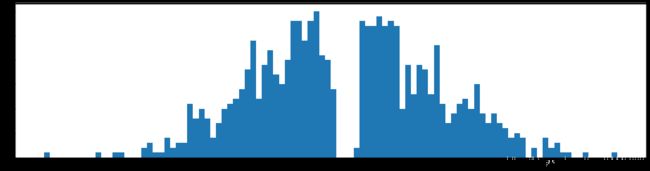
剪枝70%参数
计算出来的阈值是:0.02758437413722277
![]()
剪枝后的正确率并没有明显的变化,仍旧是97%
然后进行再训练

比上训练的正确个数还多了,又增加泛化能力。
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 174 |
| fc2 | 73 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
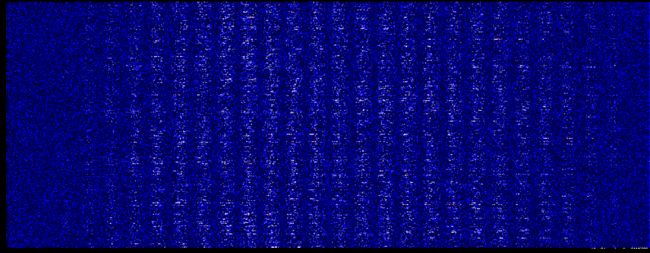
权重柱状图
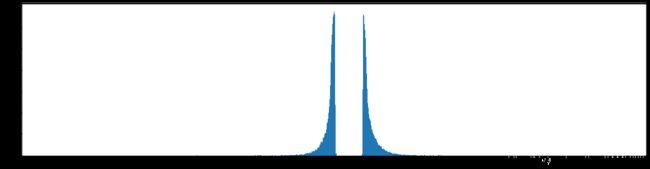
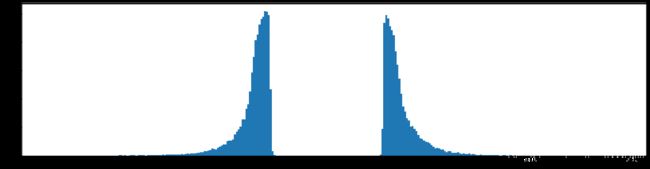
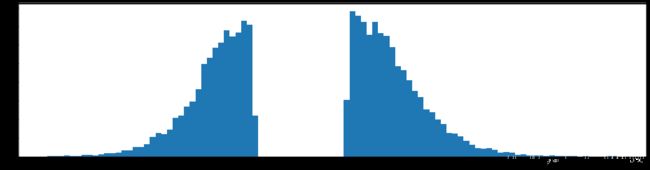
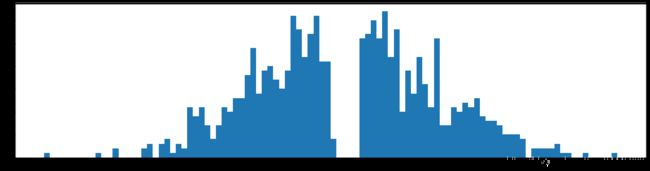
剪枝80%参数
计算出来的阈值是:0.03225095123052597
![]()
剪枝后的正确率并没有明显的变化,仍旧是97%
然后进行再训练

和上次训练的正确个数差不多,网络性能没有增加了
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 181 |
| fc2 | 77 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
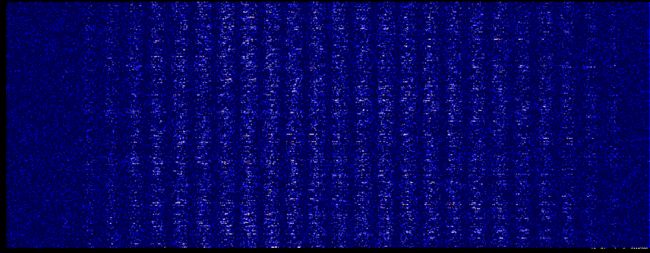
权重柱状图
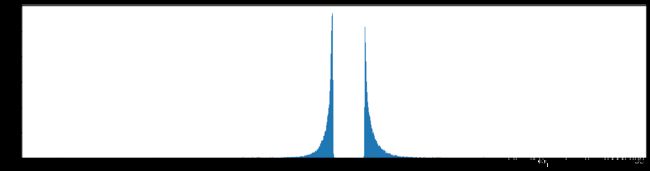
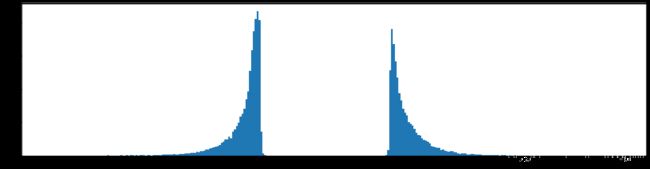
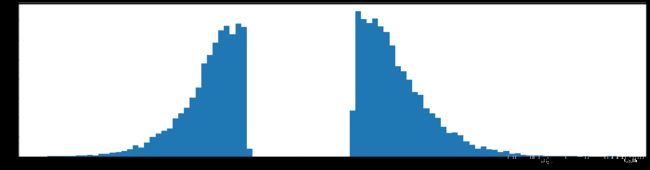
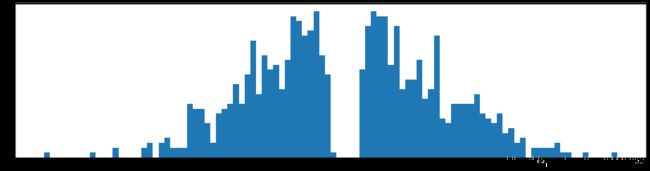
剪枝90%参数
计算出来的阈值是:0.039930999279022224
![]()
剪枝后的正确率发生了变化,下降到了93%
然后进行再训练

和上次训练的正确个数差不多,网络性能没有增加了
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 184 |
| fc2 | 78 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
权重柱状图

剪枝95%参数
计算出来的阈值是:0.05171532221138477
![]()
剪枝后的正确率发生了变化,下降到了85%
然后进行再训练

和上次训练的正确个数差不多,网络性能没有增加了
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 189 |
| fc2 | 84 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了

权重柱状图
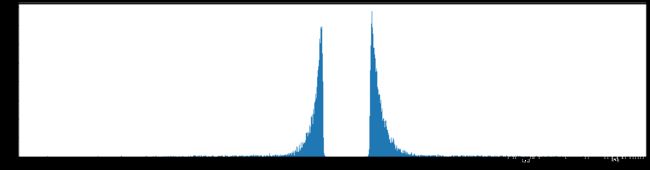


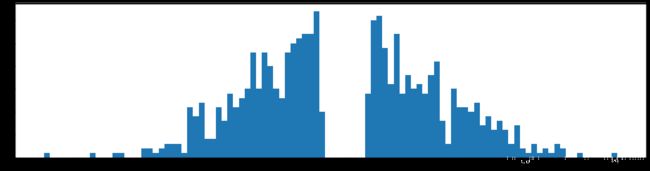
剪枝98%参数
计算出来的阈值是:0.07121909260749816
![]()
剪枝后的正确率降到了很低,下降到了60%
然后进行再训练

和上次训练的正确个数差不多,网络性还是能够恢复的
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 174 |
| fc2 | 76 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
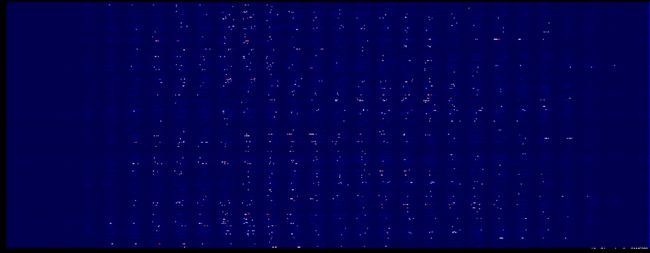
权重柱状图
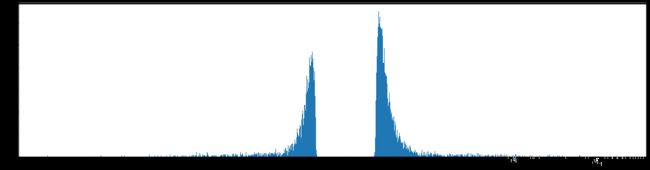


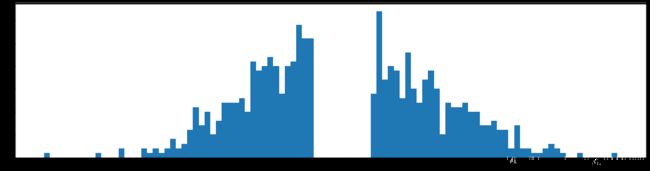
剪枝99%参数
计算出来的阈值是:0.091620362251997
![]()
剪枝后的正确率降到了很低,下降到了46%
然后进行再训练

和上次训练的正确个数下降一个百分点,网络性还是能够恢复的,但是恢复的性能略有下降
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 169 |
| fc2 | 74 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
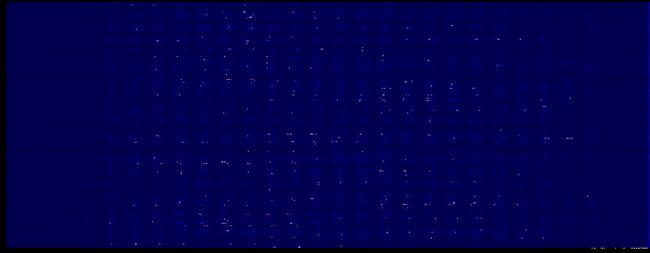
权重柱状图
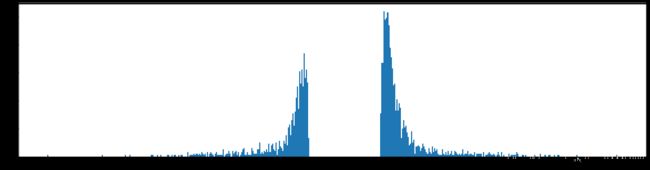


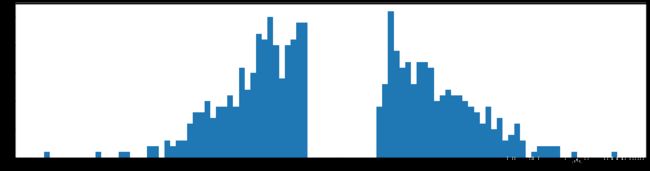
剪枝99%参数
计算出来的阈值是:0.04240277148829452
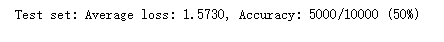
剪枝后的正确率降到了很低,下降到了50%
然后进行再训练

和上次训练的正确个数下降一个百分点,网络性还是能够恢复的,但是恢复的性能略有下降
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 167 |
| fc2 | 75 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
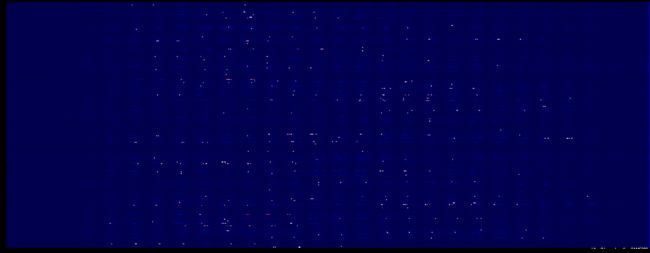
权重柱状图
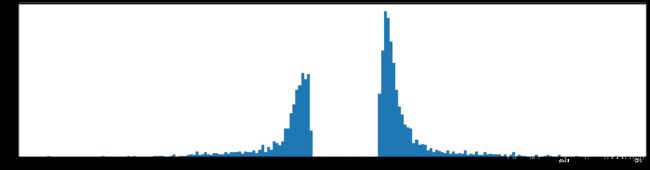


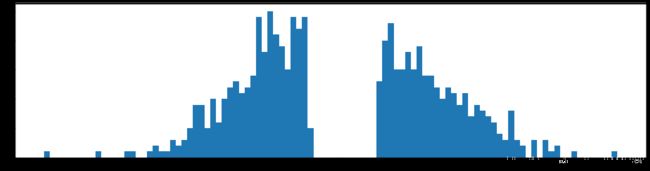
剪枝99%参数
计算出来的阈值是:0.04132488820748184
![]()
剪枝后的正确率降到了很低,下降到了50%
然后进行再训练

和上次训练的正确个数下降一个百分点,网络性还是能够恢复的,但是恢复的性能略有下降
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 167 |
| fc2 | 77 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
权重柱状图
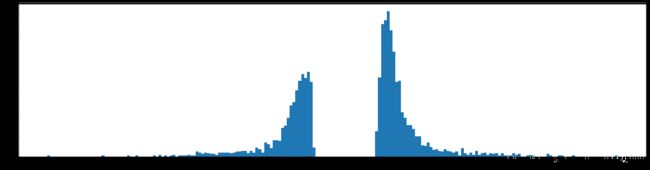

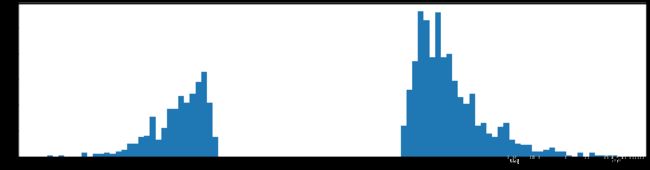
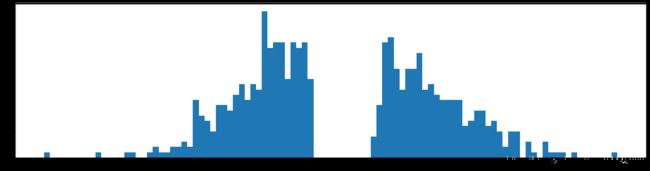
剪枝99%参数
计算出来的阈值是:0.04077488094611925
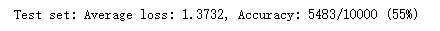
剪枝后的正确率降到了很低,下降到了50%
然后进行再训练

和上次训练的正确个数下降一个百分点,网络性还是能够恢复的,但是恢复的性能略有下降
神经元激活
| 层数 | 个数 |
|---|---|
| fc1 | 167 |
| fc2 | 77 |
| fc3 | 结果是4 |
第一层权重的深度分布图
仔细对比可以发现,这次好像图像暗的地方更暗了
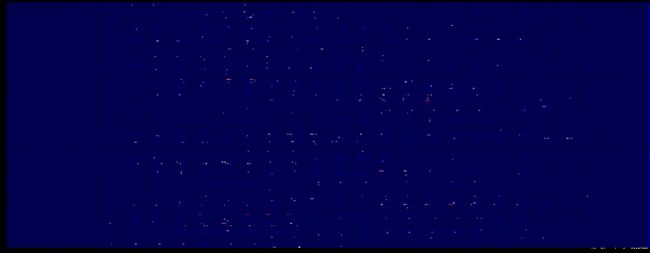
权重柱状图
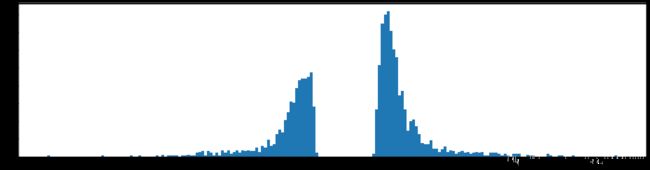
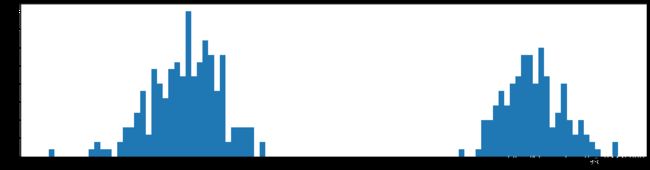
剪枝99%参数
经过非常多次剪枝99%然后参数再训练,整个网络的性能还是会慢慢提升的
计算出来的阈值是:0.025321735092738397
![]()
剪枝后的正确率降到了很低,下降到了65%,但是比刚开始还是有明显的提高
然后进行再训练

和上次训练的正确个数下降一个百分点,网络性还是能够恢复的,还是快恢复到了巅峰时期
然后剪枝80%
计算出来的阈值是:0.0012542949290946129
![]()
| 层数 | 个数 |
|---|---|
| fc1 | 124 |
| fc2 | 69 |
| fc3 | 结果是4 |
然后剪枝90%
计算出来的阈值是:0.0027993932599201803
![]()
| 层数 | 个数 |
|---|---|
| fc1 | 101 |
| fc2 | 66 |
| fc3 | 结果是4 |
然后剪枝95%
计算出来的阈值是:0.005025399965234099
![]()
| 层数 | 个数 |
|---|---|
| fc1 | 78 |
| fc2 | 64 |
| fc3 | 结果是4 |
然后剪枝99%
计算出来的阈值是:0.02462294178083847
![]()
| 层数 | 个数 |
|---|---|
| fc1 | 25 |
| fc2 | 56 |
| fc3 | 结果是1 |
通过上面的一系列数据,其实可以发现,网络中90的参数可以删掉,几乎不会影响准确性。95%的删掉,准确性还是可以接受。但是相对于参数的减少,在实际运算过程中,激活神经元的减少数量其实没有那么明显,当删除95% 的参数时,才会减少一半左右的神经元,当删除99%的参数时,神经元能够大幅度减少,但是可以发现现在的预测准确性已经无法接受。
同时,也可以发现,当前可以删除的神经元是在第一层全连接层,而第二层全连接层明显变化没有第一层剧烈。
思考:
神经网络的结构是每递进一层深度,所获得的信息就会更加抽象,说明在深层处抽象的特征多余的较少。
第一层权重的深度分布图
仔细对比可以发现,图片里面亮起来的点已经非常少了,基本上就是亮的和不亮的了。

权重柱状图
99%裁剪的情况下,一共使用了2662参数。
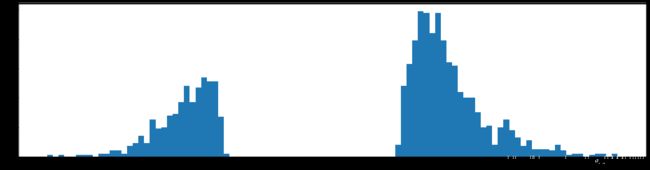
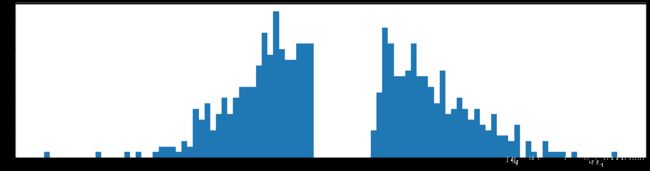
第一层一共使用了379个参数,此时和刚开始2828300=235200,减少了620倍,在浅层的多余参数这么多的嘛。而且,也可以看到,参数大量集中到了0.2左右的中心分布,偏离了原来以0为中心分布的情况。
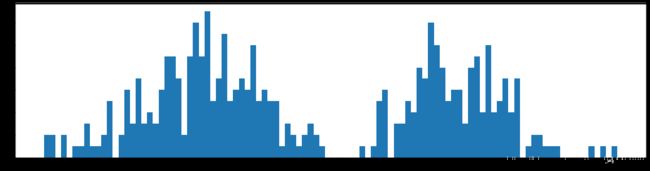
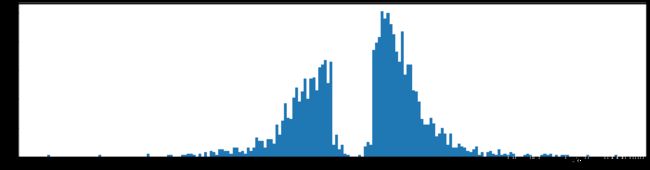
第二层一共使用了1654个参数,此时和刚开始100*300=30000,减少了18倍。参数几乎还是以零为中心在分布。
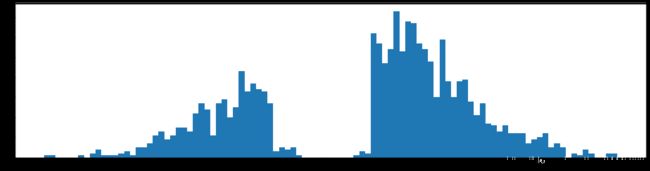
第三层一共使用了629个参数,此时和刚开始100*10=1000,减少了1.59倍。可见参数其实减少的非常少。
思考与提问
从上面的分析,可以发现,越深层的参数和神经元越重要,从参数的大小和被裁剪的多少都可以明显的看出。这里我们是按照所有层的参数放在一起按百分比进行裁剪,如果是按照每一层自己的百分比进行裁剪,是不是整个训练精度就会下降很多,明显不如这一个?下面可以做一个实验测试一下。
还有就是,现在我们第一层的神经元是300个,底层每次要激活170个左右,大概是在50%的激活率,如果我们把第一层的神经元个数增加到600个,那么每次激活的个数还是50%左右还是170吗?,如果我们进行同样的剪枝操作之后激活的个数或者百分比有什么变化?