集成学习模型
集成学习
概念: 通过构建并结合多个模型来共同完成学习任务
流程:
- 构建多个子学习器
- 使用某种集成策略将模型集成
- 完成学习任务
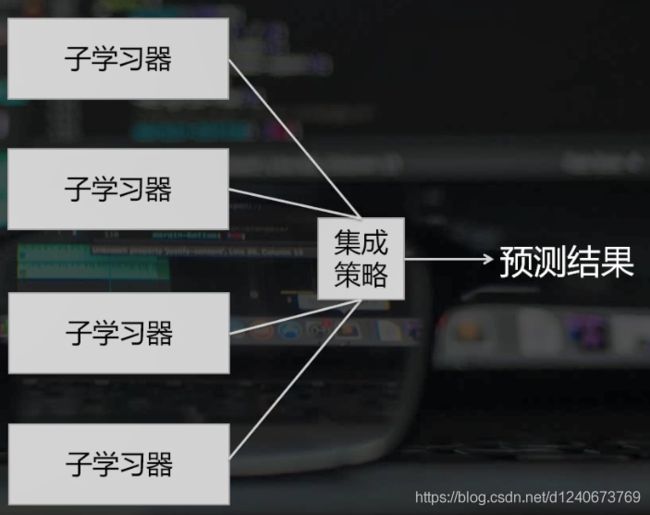
目的: 通过集成,提高多个子学习器的模型泛化能力
子学习器筛选的原则:
- 每个子学习器都要有一定的准确性
- 子学习器之间要保持相对独立性和多样性
集成学习策略
Bagging:并行式集成学习
基本原理:
同时训练多个子学习器,分别对y进行预测,最后所有子学习器以投票的形式(分类)或者均值的形式(回归),返回集成的预测结果
子学习器构建策略:
对样本按一定比例有放回的抽样,抽出m个样本子集,然后构建m个子学习器,分别在m个样本子集上进行训练
集成策略:
投票法或均值法
代表模型:随机森林
- 子学习器:决策树模型
- 子学习器构建方法:按一定比例同时对样本和特征进行有放回抽样,抽样出m个特征和样本都存在差异的样本子集,再在这m个子集上训练m个决策树模型
- 集成方法:分类问题采用投票法返回预测结果,回归采用均值法返回预测结果
Boosting:提升式集成学习
基本原理:
先训练一个子学习器,再计算子学习器的误差或残差,并以此作为下一个学习器的输入,之后不断迭代重复整个过程,使得模型损失函数不断减小
Gradient Boosting梯度提升算法:
根据当前模型损失函数的负梯度信息来训练新加入的子学习器,然后将所有训练好的子学习器以累加的形式混合到最终模型中
XGBOOST
- 基本思想:grandient boosting梯度提升
- 防止过拟合:加入L1和L2正则系数
- 子学习器:决策树模型(cart)、线性回归、线性分类器
- 集成策略:在传统梯度提升模型的基础上,融入随机森立模型对子学习器训练样本和特征进行随机取样的策略
- 优化方法:同时使用损失函数一阶、二阶导数信息,加快优化速度
- 工程优化:提高训练效率,支持并行计算
使用sklearn实现随机森林模型
用的房价预测数据:https://download.csdn.net/download/d1240673769/20910882
加载数据
import pandas as pd
import matplotlib.pyplot as plt
# 样例数据读取
df = pd.read_excel('realestate_sample_preprocessed.xlsx')
# 根据共线性矩阵,保留与房价相关性最高的日间人口,将夜间人口和20-39岁夜间人口进行比例处理
def age_percent(row):
if row['nightpop'] == 0:
return 0
else:
return row['night20-39']/row['nightpop']
df['per_a20_39'] = df.apply(age_percent,axis=1)
df = df.drop(columns=['nightpop','night20-39'])
# 制作标签变量
price_median = df['average_price'].median()
print(price_median)
df['is_high'] = df['average_price'].map(lambda x: True if x>= price_median else False)
print(df['is_high'].value_counts())
# 数据集基本情况查看
print(df.shape)
print(df.dtypes)
print(df.isnull().sum())

留出法进行数据集划分
# 留出法进行数据集划分
# 载入sklearn中数据集划分的方法
from sklearn.model_selection import train_test_split
# 将数据集划分成训练集和验证集:划分比例0.75训练,0.25验证
training, testing = train_test_split(df,test_size=0.25, random_state=1)
# 提取训练集中的x与y
x_train = training.copy()[['complete_year','area', 'daypop', 'sub_kde',
'bus_kde', 'kind_kde','per_a20_39']]
y_train = training.copy()['is_high']
# 提取验证集中的x与y
x_test = testing.copy()[['complete_year','area', 'daypop', 'sub_kde',
'bus_kde', 'kind_kde','per_a20_39']]
y_test = testing.copy()['is_high']
print(f'the shape of training set is: {training.shape}')
print(f'the shape of testing set is: {testing.shape}')
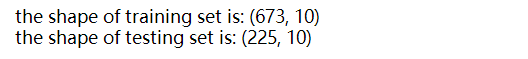
构建模型
from sklearn.preprocessing import PowerTransformer, StandardScaler, PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
rf_model = RandomForestClassifier(criterion='gini',
n_jobs=16,
max_features = 'auto',
n_estimators = 100,
max_depth = None,
random_state=133)
pipe_clf = Pipeline([
('sc',StandardScaler()),
('power_trans',PowerTransformer()),
('polynom_trans',PolynomialFeatures(degree=2)),
('rf_clf', rf_model)
])
print(pipe_clf)
随机森林模型参数
特有参数:
-
n_estimators: 也就是子学习器的个数
-
max_features: 每棵树选择的特征的最大数量,默认是"auto"
-
bootstrap: 默认True,构建决策树的时候是否使用有放回的抽样方式构建训练数据
决策树模型参数:
-
criterion:做划分时对特征的评价标准默认是基尼系数gini,另一个可选择的标准是信息增益。回归树默认是均方差mse,另一个可是绝对值差mae。
-
max_depth: 每棵树的最大深度,默认None
-
min_samples_split: 内部节点再划分所需最小样本数
-
min_samples_leaf: 叶子节点最少样本数
-
max_leaf_nodes: 最大叶子节点数
查看留出法验证集上模型的表现
# 查看留出法验证集上模型的表现
import warnings
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score
warnings.filterwarnings('ignore')
pipe_clf.fit(x_train,y_train)
y_predict = pipe_clf.predict(x_test)
print(f'accuracy score is: {accuracy_score(y_test,y_predict)}')
print(f'precision score is: {precision_score(y_test,y_predict)}')
print(f'recall score is: {recall_score(y_test,y_predict)}')
print(f'auc: {roc_auc_score(y_test,y_predict)}')

xgboost模型的sklearn api调用
加载数据
# 数据读取以及xy提取
import pandas as pd
import matplotlib.pyplot as plt
# 样例数据读取
df = pd.read_excel('realestate_sample_preprocessed.xlsx')
# 根据共线性矩阵,保留与房价相关性最高的日间人口,将夜间人口和20-39岁夜间人口进行比例处理
def age_percent(row):
if row['nightpop'] == 0:
return 0
else:
return row['night20-39']/row['nightpop']
df['per_a20_39'] = df.apply(age_percent,axis=1)
# 制作标签变量
price_median = df['average_price'].median()
df['is_high'] = df['average_price'].map(lambda x: True if x>= price_median else False)
# 划分数据集
x = df[['complete_year','area', 'daypop', 'sub_kde',
'bus_kde', 'kind_kde','nightpop','night20-39','per_a20_39']]
y = df['is_high']
构建分类模型的交叉验证策略
# 构建分类模型的交叉验证策略
from sklearn.model_selection import StratifiedKFold #适用于分类模型的交叉验证
k = 5
kf = StratifiedKFold(n_splits=k, shuffle=True)
kf.get_n_splits(x, y)
print(kf)
![]()
构建模型
from sklearn.preprocessing import PowerTransformer, StandardScaler, PolynomialFeatures
from sklearn.pipeline import Pipeline
# pip install xgboost
import xgboost as xgb
xgb_model = xgb.XGBClassifier(objective='binary:hinge',
nthread=16,
booster='gbtree',
n_estimators=500,
learning_rate=0.05,
max_depth=9,
subsample=0.8,
colsample_bytree=0.8
)
pipe_clf = Pipeline([
('sc',StandardScaler()),
('power_trans',PowerTransformer()),
('polynom_trans',PolynomialFeatures(degree=2)),
('xgb_clf', xgb_model)
])
print(pipe_clf)

xgboost模型参数
通用参数:
booster:默认gbtree
- gbtree:基于树的模型
- gbliner:线性模型
nthread:最大线程数
objective:任务类型
-
回归任务:reg:squarederror
-
二元分类任务:
- binary: logistic(输出概率)
- binary: hinge(输出分类结果)
-
其他任务类型详解:https://xgboost.readthedocs.io/en/latest/parameter.html#learning-task-parameters
训练参数,以tree booster为例:
n_estimators: 子学习器数量
learning rate:训练步长
max_depth:树最大深度
max_leaf_nodes:树最大节点或叶子数量
subsample:控制每棵树,训练样本比例
colsample_bytree:控制每棵树,训练特征比例
lambda:L2正则系数
alpha:L1正则系数
其他参数详解:https://xgboost.readthedocs.io/en/latest/python/python_api.html#module-xgboost.sklearn
查看模型表现
import warnings
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score
warnings.filterwarnings('ignore')
acc = []
precision = []
recall = []
auc = []
for train_index, test_index in kf.split(x,y): # 拆分
x_traincv, x_testcv = x.loc[train_index], x.loc[test_index]
y_traincv, y_testcv = y.loc[train_index], y.loc[test_index]
pipe_clf.fit(x_traincv, y_traincv) # 训练
y_predictcv = pipe_clf.predict(x_testcv) # 预测
k_acc = accuracy_score(y_testcv,y_predictcv)
print(f'accuracy score is: {k_acc}')
acc.append(k_acc)
k_precision = precision_score(y_testcv,y_predictcv)
print(f'precision score is: {k_precision}')
precision.append(k_precision)
k_recall = recall_score(y_testcv,y_predictcv)
print(f'recall score is: {k_recall}')
recall.append(k_recall)
k_auc = roc_auc_score(y_testcv,y_predictcv)
print(f'auc: {k_auc}')
auc.append(k_auc)
print('')
import numpy as np
print(f'-----------------------------------------------------')
print(f'average accuracy score is: {np.array(acc).mean()}')
print(f'average precision is: {np.array(precision).mean()}')
print(f'average recall is: {np.array(recall).mean()}')
print(f'average auc is: {np.array(auc).mean()}')
