spark(day02)
案例
求中位数
package cn.tedu.wordcount
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object DriverMedian {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("median")
val sc=new SparkContext(conf)
val data=sc.textFile("D://未来/spark练习文件/median.txt", 2)
val r1=data.flatMap { line => line.split(" ") }.map { x => x.toInt }.sortBy{x=>x}
val num=r1.count().toInt
if(num%2==0){
val m=r1.take(num/2+2)
val n=r1.take(num/2)
println((m.sum-n.sum)/2.toDouble)
}else{
println(r1.take((num+1)/2).last.toDouble)
}
}
}
二次计数
package cn.tedu.wordcount
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object DriverSsort {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("median")
val sc=new SparkContext(conf)
val data=sc.textFile("D://未来/spark练习文件/ssort.txt", 1)
// --RDD[String:line]->RDD[ (Ssort,line)]->SortByKey
val r1=data.map { line =>
val info=line.split(" ")
val col1=info(0)
val col2=info(1).toInt
(new Ssort(col1,col2),line)
}
//true----按类里定义的排序规则排序
val r2=r1.sortByKey(true).map{x=>x._2}
r2.foreach(println)
}
}
package cn.tedu.wordcount
import java.io.Serializable
/*
* ssort中的两列数据
* 引入分类方法 ctrl+1
* */
class Ssort(val col1:String, val col2:Int) extends Ordered[Ssort] with Serializable{
/*
*此方法用于指定排序规则
* 目标:先按第一列做升序排序
* 再按第二列做降序排序
*/
def compare(that: Ssort): Int = {
//--获取第一列升序排序比较的结果
val result=this.col1.compareTo(that.col1)
if(result==0){
//--第一列升序排完后,按第二列做降序
that.col2.compare(this.col2)
}else{
result
}
}
}
spark环境执行代码
package cn.tedu.wordcount2
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object Driver {
def main(args: Array[String]): Unit = {
//表示将代码运行在Spark集群环境下
val conf=new SparkConf().setMaster("spark://hadoop01:7077").setAppName("wordcount2")
val sc=new SparkContext(conf)
val data=sc.textFile("hdfs://hadoop01:9000/data",3)
val result=data.flatMap { x => x.split(" ") }.map { x => (x,1) }.reduceByKey{_+_}
result.saveAsTextFile("hdfs://hadoop01:9000/result06")
}
}
步骤
1.打成jar包
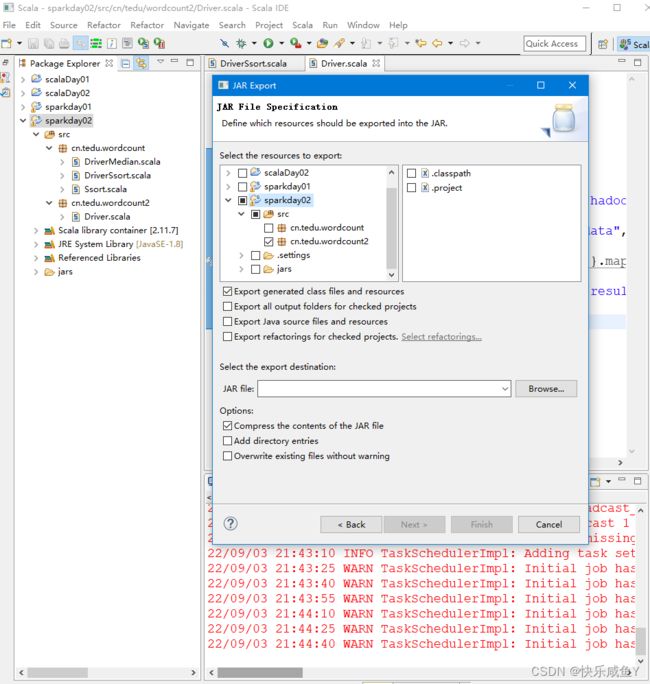
2.把jar包放到bin目录,执行指令,hafs下生成数据
[root@hadoop01 bin]# pwd
/home/presoftware/spark-2.0.1-bin-hadoop2.7/bin
[root@hadoop01 bin]# ll wor*
-rw-r--r--. 1 root root 4578 9月 3 2022 wordcount.jar
#提交jar包指令---执行代码
[root@hadoop01 bin]# sh spark-submit --class cn.tedu.wordcount2.Driver wordcount.jar
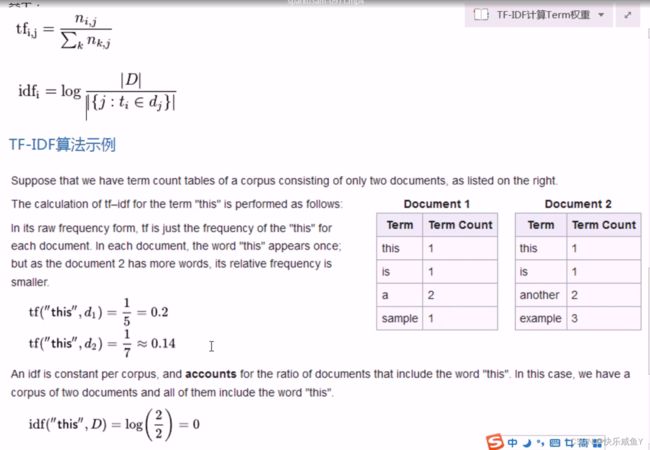
VSM(Vector Space Model)向量空间模型算法
这个算法用于文档排名
要根据相似度来实现排名。
学习VSM算法有两个基础:
①倒排索引表的概念
②相似度的概念
文档索引总的来分有两种:
①正向索引,建立的文档->词汇的索引
1.txt->hello 3; world 10
2.txt->spark 1; hive 8
②反向索引(倒排索引)
hello->1.txt 10; 3.txt 6hadoop->3.txt 5;
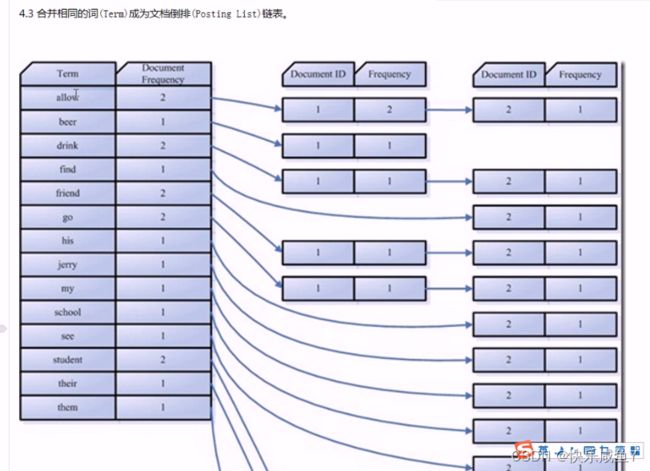
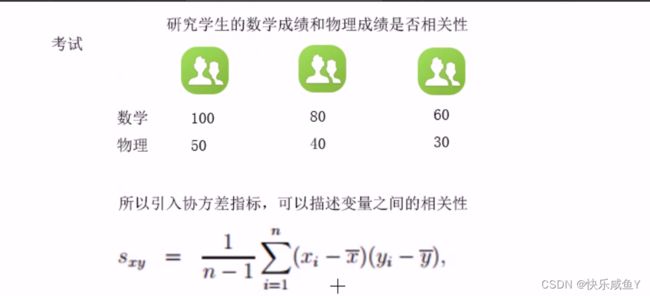
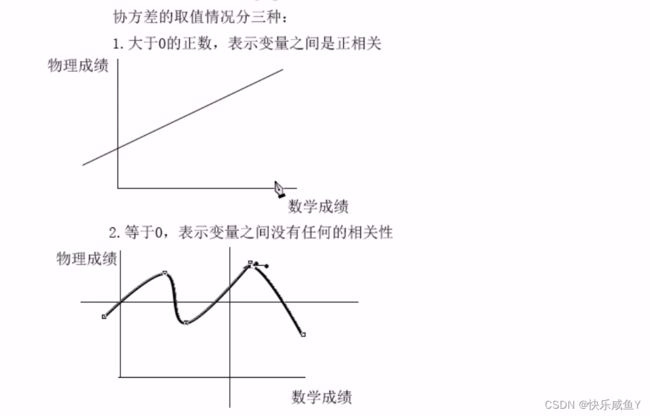
方差
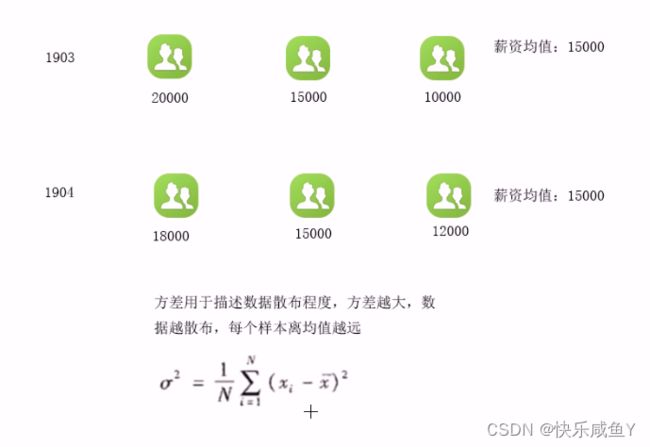






倒排索引

展示
原数据
doc1.txt
hello spark
hello hadoop
doc2.txt
hello hive
hello hbase
hello spark
doc3.txt
hadoop hbase
hive scala
package cn.tedu.inverted
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Driver {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("median")
val sc=new SparkContext(conf)
//将指定目录下的所有文件,读取到一个RDD中
//RDD[(filePath,fileText)]
val data=sc.wholeTextFiles("D://未来/spark练习文件/inverted/*")
//--要求基于data,最后返回倒排索引表的形式,比如:
// --(scala,doc3)
// --(hello,doc1,doc2)
//--实现思路:@把文件名获取到Ⅰ②把单词切出来,先按\r\n切出行,再按空格切出单词
val r1=data.map{case(filePath,fileText)=>
val fileName=filePath.split("\\/").last.dropRight(4)
(fileName,fileText)
}
//步骤2:RDD[(fileName,fileText)]->RDD[(word,fileName) ]
val r2=r1.flatMap{case(fileName,fileText)=>
fileText.split("\r\n").flatMap { line => line.split(" ") }
.map { word => (word,fileName) }
}
val r3=r2.groupByKey.map{case(word,buffer)=>(word,buffer.toList.distinct.mkString(",")}
r3.foreach{println}
// val r1=data.map{case(path,line)=>(path,line.split("\r\n").toList)}
// val r2=r1.map{case(x,y)=>(x.split("\\/").last.split("\\.")(0),y.flatMap { line => line.split(" ") })}
// val r3=r2.map{case(x,y)=>(y,x)}
// val list=List[String]()
// val r4=r3.foreach{case(x,y)=>x.foreach {m=>
// val l=list.::(m,y)
// val r5=l.toList
// r5.groupBy { x => x }
// r5.foreach { println }
// }}
}
}
扩展–算法