pytorch训练分类器
Training a Classifier
前面学习到如何定义神经网络,计算损失并且对网络权重进行更新
What about data?
通常,当你必须处理图像,文本,音频或视频时,你可以使用能将数据加载到numpy数组的标准python包,然后将该数组转化成torch.*Tensor
- 图像:Pillow, OpenCV
- 音频:scipy,librosa
- 文本:基于python或cython的原始加载,或者NLTK和SpaCy
专门针对视觉,创建了名为torchvision的包,包含常见数据集(ImageNet, CIFAR10, MNIST)的加载器,以及用于图像的数据转换器(torchvision.datasets和torch.utils.data.DataLoader)
提供极大便利,避免编写样板代码
使用CIFAR10数据集,有分类:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’,‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。CIFAR-10中的图像尺寸为3x32x32,即尺寸为32x32像素的3通道彩色图像
图像的4D张量为(B,C,H,W)
- B:batch size
- C:channel
- H:height
- W:width
Training an image classifier
- 1.使用
torchvision加载并标准化CIFAR10训练和测试数据集 - 2.定义卷积神经网络
- 3.定义损失函数
- 4.基于训练数据训练网络
- 5.基于测试数据测试网络
1.加载并标准化CIFAR10
torchvision库包括数据集,模型以及针对计算机视觉的图像转换器,是pytorch的一个图形。torchvision包括以下:
torchvision.datasets: 一些加载数据的函数及常用的数据集接口torchvision.models:包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等torchvision.transforms:常用的图片变换,例如裁剪、旋转等torchvision.utils:其他的一些有用的方法
import torch
import torchvision
import torchvision.transforms as transforms
torchvision数据集输出是[0,1]范围的PILImage图像,需要转换为标准化范围的[-1,1]张量
torchvision.transforms.Compose合并多个图像变换的操作,常见transforms操作有:
- ToTensor:把灰度范围从0-255变换到0-1之间
- Normalize:用均值和标准差归一化张量图像
- CenterCrop:在图片的中间区域进行裁剪
Python图像库PIL(Python Image Library)是python的第三方图像处理库
PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口,该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入,因此该接口有点承上启下的作用,比较重要。
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 取消证书验证
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# transforms.Normalize(mean,std),图像尺寸为3*32*32,保持一致
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,shuffle=False, num_workers=2)
# DataLoader数据迭代器,用来封装数据,num_workers读取数据的线程数,shuffle设置为True表示在每个epoch重新洗牌数据
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Files already downloaded and verified
Files already downloaded and verified
Let us show some of the training images, for fun.
迭代是Python最强大的功能之一,是访问集合元素的一种方式。字符串,列表,元组都可以用于创建迭代器。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束包括两种方法:
iter()创建一个迭代器next()返回迭代器的下一个项目。
list1=[1,2,3,4]
it=iter(list1)
for x in it:
print(x,end=' ')
1 2 3 4
展示一些训练图像
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy() # PIL image转换成numpy array
plt.imshow(np.transpose(npimg, (1, 2, 0))) # np.transpose反转或置换数组的轴
plt.show()
# get some random training images
# trainloader相当于一个包含images和labels的列表,前面shuffle设置为True,因此每次运行都会结果不同
dataiter = iter(trainloader)
images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
# torchvision.utils.make_grid将若干张图像拼成一张网格
# print labels
print(' '.join(f'{classes[labels[j]]:5s}' for j in range(batch_size)))

horse bird deer truck
2.定义卷积神经网络
从之前部分复制神经网络代码,将图像改为3通道
nn.Conv2d:在由多个输入平面组成的输入信号上应用二维卷积
nn.Conv2d(in_channels,out_channels,kernel_size)
nn.MaxPool2d:在由几个输入平面组成的输入信号上应用一个2D max池
nn.MaxPool2d(kernel_size,stride)
nn.Linear:对输入的数据应用线性转换 y = x A T + b y=xA^T+b y=xAT+b
nn.Linear(in_features,out_features)
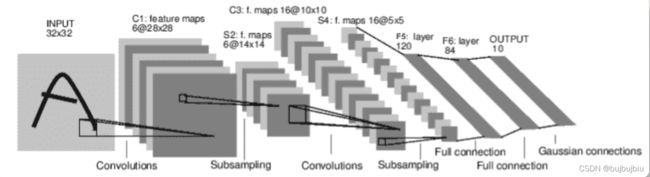
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)# 卷积计算
# 3channel的32*32原始图像经过6个5*5的filters卷积计算后变成6channel的28*28图像
self.pool = nn.MaxPool2d(2, 2)# 池化
# 6channel的28*28图像以2*2进行pooling操作变为14*14,stride=kernel_size表示没有重复部分,28/2=14
self.conv2 = nn.Conv2d(6, 16, 5)# 卷积计算
# 6channel的14*14图像经过16个5*5的filters卷积计算后变成16channel的10*10图像
#self.pool = nn.MaxPool2d(2, 2)
# 16channel的10*10图像以2*2进行pooling变为5*5,10/2=5
self.fc1 = nn.Linear(16 * 5 * 5, 120)# 线性变换
# 16channel的5*5平铺即16 * 5 * 5,作为FC首层的输入F5
self.fc2 = nn.Linear(120, 84)
# FC第二层F6
self.fc3 = nn.Linear(84, 10)
# FC第三层高斯层output
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))# 卷积->激活->池化
x = self.pool(F.relu(self.conv2(x)))# 卷积->激活->池化
x = torch.flatten(x, 1) # 除了batch维度均平铺
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)# 最后一层为高斯连接
return x
net = Net()
2.定义损失函数和优化器
使用分类交叉熵损失和动量SGD
torch.nn.CrossEntropyLoss:计算输入与目标值间的交叉熵损失,适合带有C个类别的分类问题,输入是每个类原始无标准化的分数
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
criterion type:
loss type:
3.训练网络
遍历数据迭代器,将输入馈送到网络并进行优化
enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中,语法enumerate(sequence, [start=0]):
- sequence: 一个序列、迭代器或其他支持迭代对象
- start:下标起始为止
# 普通for循环
i=0
sequence=['one','two','three']
for e in sequence:
print(i,sequence[i])
i+=1
# 使用enumerate的for循环
for i,e in enumerate(sequence,0):
print(i,e)
0 one
1 two
2 three
0 one
1 two
2 three
for epoch in range(2):
run_loss = 0.0 # 计算平均误差
# 获取inputs,data是一个列表[inputs,labels]
for i,data in enumerate(trainloader,0):
inputs,labels = data
# 梯度清0
optimizer.zero_grad()
# forward+loss+backward+optimize
outputs = net(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
# 如果使用run_loss+=run_loss,会导致内存爆炸,此处loss是变量
run_loss += loss.item()
if i%2000 == 1999: # 输出每2000个mini-batches
print(f'[{epoch+1},{i+1:5d}],loss:{run_loss/2000:.3f}')
run_loss = 0.0
[1, 2000],loss:2.268
[1, 4000],loss:2.029
[1, 6000],loss:1.834
[1, 8000],loss:1.666
[1,10000],loss:1.598
[1,12000],loss:1.517
[2, 2000],loss:1.459
[2, 4000],loss:1.418
[2, 6000],loss:1.373
[2, 8000],loss:1.355
[2,10000],loss:1.349
[2,12000],loss:1.306
保存训练过的模型
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
pytorch更多模型here https://pytorch.org/docs/stable/notes/serialization.html
5.基于测试数据测试网络
基于训练数据对网络进行2次训练,为了检测网络性能,通过预测将神经网络输出的类别标签并且与实际对比,如果预测正确,将该样本添加到正确预测表中
首先,显示几张测试集中的图像
dataitertest =iter(testloader)
images,labels = dataitertest.next()
print(labels)
# 此处的labels是数字代表的类别
imshow(torchvision.utils.make_grid(images))
print('groundtruth:',' '.join(f'{classes[labels[j]]:5s}' for j in range(4)))
tensor([3, 8, 8, 0])

groundtruth: cat ship ship plane
接下来重新加载保存的模型(实际不需要,此处展示如何保存)
net = Net()
net.load_state_dict(torch.load(PATH))
现在看看神经网络对以上样例的预测
outputs = net(images)
print(outputs)
tensor([[-0.5511, -1.2592, 1.0451, 1.7341, 0.2255, 1.0719, 0.3474, -0.0722,
-0.7703, -1.7738],
[ 2.9296, 4.5538, -0.4796, -1.7549, -2.4294, -2.7830, -3.4919, -3.0665,
4.3148, 2.5193],
[ 2.0322, 2.4424, 0.4408, -1.1508, -1.1923, -1.9300, -2.9568, -1.5784,
2.8175, 2.0967],
[ 3.1805, 2.2340, 0.1468, -1.6451, -0.8934, -2.9459, -3.4108, -2.2368,
4.2390, 2.2832]], grad_fn=)
输出是4张图像10个类别的能量,某个类的能量越高,代表网络倾向于认为该图像属于该类别,因此让我们获取最高能量的指数
torch.max(input, dim, keepdim=False, out=None):返回输入tensor中所有元素的最大值
torch.max(tensor,0):返回每一列(1行)中最大值的那个元素,且返回索引(返回最大元素在这一列的行索引)
_,predicted = torch.max(outputs,1)
print("predicted:",''.join('%5s'%classes[predicted[j]] for j in range(4)))
predicted: cat car ship ship
正确率75%
接下来看网络在整个数据集上的表现
totalnum = 0
correctnum = 0
# 没有训练,因此不需要计算输出的梯度
with torch.no_grad():
for data in testloader:
images,labels = data
# 前向传播
outputs = net(images)
_,predicted = torch.max(outputs,1)
# totalnum所有测试图像数量,correctnum预测准确图像数量
totalnum += labels.size(0)
correctnum += (predicted==labels).sum().item()
print("Accuracy of the network on the 10000 test images:%d %%"%(100*correctnum/totalnum))
Accuracy of the network on the 10000 test images:55 %
随机选择一个类,准确率为10%,因此神经网络训练比随机更好。接下来分析网络在哪些类表现好,哪些类表现不好
zip([iterable,...])函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。使用 list() 转换来输出列表
ex=[1,2,3]
ex1=[4,5,6]
m=zip(ex,ex1)
print(list(m))
# 出现list is not callable,表明有变量名被命名成了list,注意命名规范!
[(1, 4), (2, 5), (3, 6)]
# 字典存储每个类别预测正确的数量和总数量
correct_pred = {classname:0 for classname in classes}
total_pred = {classname:0 for classname in classes}
# 预测并计数
with torch.no_grad():
for data in testloader:
images,labels = data
outputs = net(images)
_,predictions = torch.max(outputs,1)
for label,prediction in zip(labels,predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
for classname,correct_count in correct_pred.items():
accuracy = 100*float(correct_count)/total_pred[classname]
print('accuracy of %5s:%2d %%'%(classname,accuracy))
accuracy of plane:54 %
accuracy of car:74 %
accuracy of bird:49 %
accuracy of cat:31 %
accuracy of deer:53 %
accuracy of dog:47 %
accuracy of frog:60 %
accuracy of horse:58 %
accuracy of ship:69 %
accuracy of truck:54 %
Training on GPU
GPU图像处理器:专门做图像和图形相关运算工作的微处理器。就像张量可以转移到GPU一样,神经网络也可以,此处没有CUDA设备无法实现