泰坦尼克号幸存者的预测
机器学习案例:泰坦尼克号幸存者的预测
泰坦尼克号幸存者预测是机器学习的经典案例,其涉及了众多机器学习会遇到的问题,回归难度也比较大。本次数据集来自kaggle,可从该地址https://www.kaggle.com/competitions/titanic/data自行下载。数据集格式为csv
引入需要调取的库
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
import numpy as np
处理数据集
数据集长下面这个样子
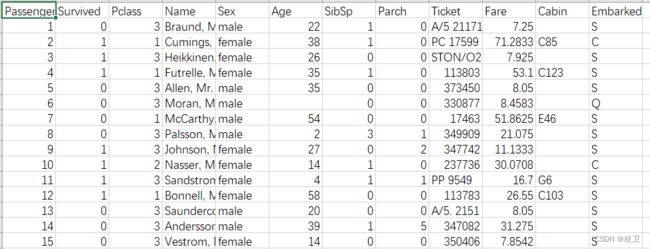
引入数据集
data = pd.read_csv('D:\\编程\\python_work\\train.csv')
print(data.info()) # 调出data数据信息
print(data.head(5)) # 调取前n行列表

该表为数据集的信息
从表中可以看出以下三个问题:
1、数据集中很多特征与幸存者数量相关性不大因此筛选特征以此提高回归准确率。
2、数据集的一些特征存在缺失值
3、数据集的特征需要统一类型为数字
筛选特征
先解决第一个问题,使用drop()函数来删除整列元素
# 筛选特征
data.drop(['Cabin', 'Name', 'Ticket'], inplace=True, axis=1) # 删除特征列表,并覆盖原表,对列操作
第一个参数是需要删除的特征列表。
inplace默认值是False,表征不覆盖原表,这里inplace=True表征覆盖原表。
axis是对轴操作,默认值是0,是对行操作,1是对列操作
处理缺失值
接下来使用fillna()函数填充缺失值,dropna()函数用于删掉有缺失值的行
# 处理缺失值
data['Age'] = data['Age'].fillna(data['Age'].mean()) # 对缺失值Age进行填充
data = data.dropna() # 删掉有缺失值的行
这里data[‘Age’]是指数据集中Age所在列,fillna是填充函数,里面的参数是填充值。dropna()用于删掉有缺失值的行,返回原表
统一数据类型
数据集中的数据类型必须为数字,embarked和sex的数据类型是对象,因此需要转换数据类型,以下介绍两种方法
# 统一类型为整型
labels = data['Embarked'].unique().tolist() # 生成一个类列表
data['Embarked'] = data['Embarked'].apply(lambda x: labels.index(x)) # 在这一列上面执行apply后面的操作
data['Sex'] = (data['Sex'] == 'male').astype('int') # 另一个处理方式
# print(data.iloc[:, 3]) # 可以更加精确地得到列表切片
unique()可以生成一个样本列表,但数据类型是’numpy.ndarray’ 这时候用tolist()转换数据类型,返回一个列表。
第二行代码执行apply后面的操作,里面使用lambda函数创建一个简单函数,将Embarked所在列表样本转换为labels的对应索引,因此实现统一数据类型
(data[‘Sex’] == ‘male’)是一个很巧妙的操作,和MATLAB有点像,它会返回布尔值如下:

然后通过astype(‘int’)转换数据类型
创建数据集
按照上述方式切片出特征和标签所在列
# print(data.iloc[:, 3]) # 可以更加精确地得到列表切片
x = data.iloc[:, data.columns != 'Survived']
y = data.iloc[:, data.columns == 'Survived']
按照这种方式是可以更加精确地得到列表切片,避免出现报红但依旧运行的情况。
然后建立经典数据集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(x, y, test_size=0.3)
# 确保数据集第一行的索引顺序而非乱序
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
种一棵树
数据已经处理完了,接下来建模三部曲
clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
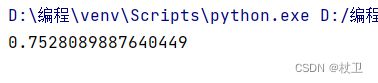
绘制超参数的学习曲线
0.75的评分显然拟合效果不是很好,因此需要调整参数,这里先对max_depth进行调参,开始绘制学习曲线
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25,max_depth=i+1)
clf = clf.fit(Xtrain, Ytrain)
score_tr = clf.score(Xtest, Ytest)
score_te = cross_val_score(clf, x, y, cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1,11),tr, color='red',label='train')
plt.plot(range(1,11),te, color='blue',label='test')
plt.xticks(range(1, 11))
plt.legend()
plt.show()
为了避免过拟合的情况,我们也进行了交叉验证。这里交叉验证的曲线表征测试集的效果,正常训练得到的结果用于表征训练集的效果。
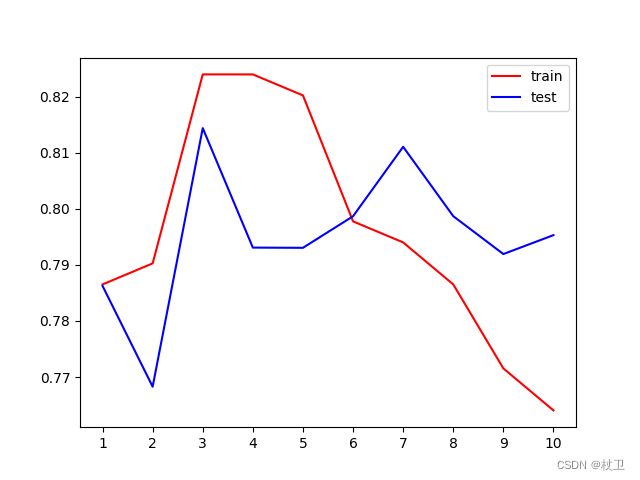
最大score=0.8143896833503576
证明调参有效
浅说下我的理解,对于机械而言,如果他对训练集的那部分知识点掌握透彻了,但对其他知识点半知半解那么这就是过拟合,欠拟合就是训练集的那部分知识他都还没学好,因此交叉验证就可以理解成对所有知识进行考察。
因此如果正常训练的效果比交叉验证的效果好,那就是过拟合,反之则是欠拟合。
调整criterion=‘entropy’
clf = DecisionTreeClassifier(criterion='entropy',random_state=25,max_depth=i+1)

最大score=0.8166624106230849
大差不差,第一个图有点过拟合,第二个图有点欠拟合
网格搜索
超参数的学习曲线已经不能满足我们对于调参的需求,这个时候我们需要剪枝了,在此引入网格搜索
网格搜索:能够帮助我们同时调整多个参数的技术,枚举技术
重点还是在于探索的参数的取值范围
# 网格搜索:能够帮助我们同时调整多个参数的技术,枚举技术\
gini_thresholds = np.linspace(0, 0.5, 50) # 基尼系数的边界
entropy_thresholds = np.linspace(0, 0.5, 50) # 信息熵的边界
# 一串参数和这些参数对应的,我们希望网格搜索来探索的参数的取值范围
parameters = {'criterion': ('gini', 'entropy')
, 'splitter': ('best', 'random')
, 'max_depth': [*range(1, 10)]
, 'min_samples_leaf': [*range(1, 50, 5)]
, 'min_impurity_decrease': [*np.linspace(0, 0.5, 50)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS = GS.fit(Xtrain, Ytrain)
print(GS.best_params_) # 从我们输入的参数和参数取值的列表中,返回最佳组合
print(GS.best_score_) # 网格搜索后的模型的评判标准
时间会有点慢,通常我们需要考虑探索哪些参数,并不是都探索一遍就能找到最佳的范围,因为网格搜索是找到最佳的范围组合,有时候为了配合其他参数会对最终score有影响。
这里得到的结果如下
clf = DecisionTreeClassifier(criterion='gini', random_state=25, splitter='best', max_depth=6, min_impurity_decrease=0, min_samples_leaf=6)
score=0.777
效果不是很好,甚至还没有剪枝前的score高,因此还需要去考量参数的范围及选取。
总结
关于本次预测,我觉得印象最深的还是网格搜索,网格搜索底层逻辑就是每一个参数试过来,所以会消耗大量时间,所以调参是一个漫长的过程,但网格搜索确实能够很好地帮助我们找到最佳的组合,所以每次需要思考清楚参数及其调参范围。