第6周学习:Vision Transformer; Swin Transformer
Vision Transformer
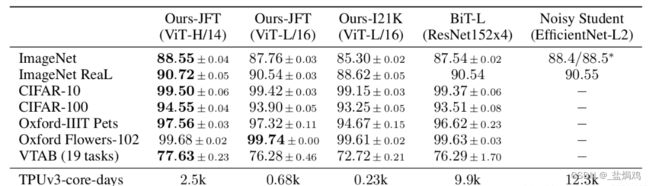
Transformer最初是应用在NLP领域的,这个模型尝试将Transformer应用到CV领域,通过这篇文章的实验,给出的最佳模型在ImageNet1K上能够达到88.55%的准确率(先在Google自家的JFT数据集上进行了预训练),说明Transformer在CV领域确实是有效的,而且效果还挺惊人。
Embedding
这个是对数据进行变换,将一个3维的矩阵化为多个Patch,再转化为一个token。实际代码中一般采用一个卷积层实现。以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
Encoder
Encoder其实就是重复堆叠Encoder Block n次。
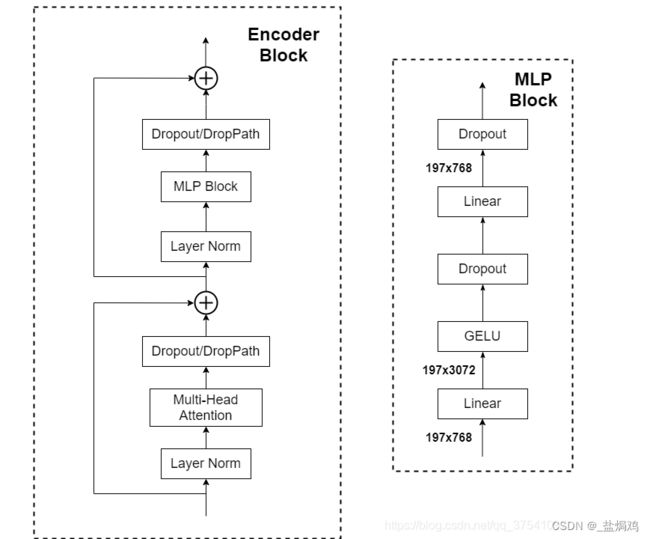
MLP Head
这里类似分类器,通过MLP Head得到最后的分类结果
Swin Transformer
ST模型是在VIT基础上的一次改进,它比VIT更适合实例分割等任务。
ST中使用了类似卷积神经网络的层次化构建方法,且使用了Windows Multi-Head Self-Attention(W-MSA)的概念。获得了更多的细节,且减少了计算量。

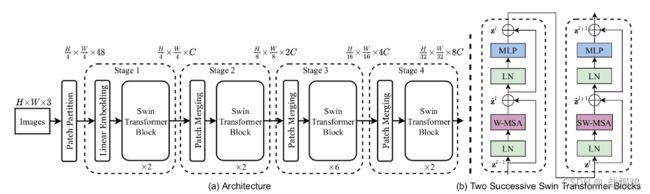
由于许多细节和VIT一样,比如Embedding层,这里只列举一些不同的地方。
Patch Merging
在每个Stage中首先要通过一个Patch Merging层进行下采样,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍。

W-MSA详解
W-MSA是为了减少计算量,个人觉得这里很像组卷积。先划分为windows,再进行self attention。下面是计算量的差距

假设feature map的h、w都为112,M=7,C=128,采用W-MSA模块相比MSA模块能够节省约40124743680 FLOPs。
SW-MSA
SW-MSA解决了W-MSA信息交流的问题,通过对窗口进行交流可以发现通过将窗口进行偏移后,由原来的4个窗口变成9个窗口了。后面又要对每个窗口内部进行MSA,这样做感觉又变麻烦了。为了解决这个麻烦,作者又提出而了Efficient batch computation for shifted configuration。
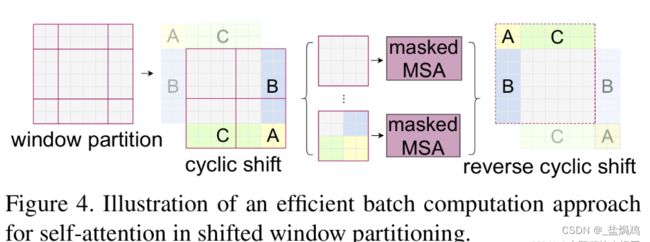
这个方法的大概含义就是将平移后的9个窗口通过位置变换重新变成4个窗口,类似于华容道的原理。
Relative Position Bias
这个相对位置偏执将正确率进一步提高了。具体的流程我是看st的





ConvNeXt
在VIT大放异彩的同时,卷积神经网络仍能有一席之地,ConvNeXt纯卷积神经网络,它对标的是2021年非常火的Swin Transformer,通过一系列实验比对,在相同的FLOPs下,ConvNeXt相比Swin Transformer拥有更快的推理速度以及更高的准确率,在ImageNet 22K上ConvNeXt-XL达到了87.8%的准确率。
模型结构
这里的模型并没有什么创新,而是利用了VIT的训练方法和架构去搭建网络。
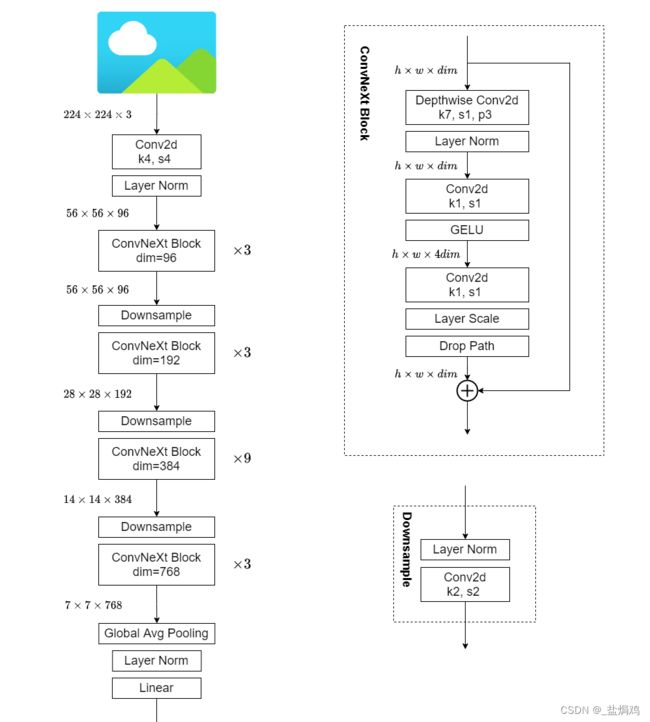
训练方法
作者利用VIT的训练策略去训练原始的ResNet50,发现效果很好。
macro design
- 这部分主要更换了堆叠次数,ResNet50中的堆叠次数由(3, 4, 6, 3)调整成(3, 3, 9, 3),和Swin-T拥有相似的FLOPs。进行调整后,准确率由78.8%提升到了79.4%。
- 同时,作者吧ResNet中的stem也换成了和Swin Transformer一样的patchify。替换后准确率从79.4% 提升到79.5%,并且FLOPs也降低了一点
接下来作者在聚焦到一些更细小的差异,比如激活函数以及Normalization。 - 在使用了更少激活函数后,发现准确率从80.6%增长到81.3%
- 使用更少的Normalization,准确率已经达到了81.4%,已经超过了Swin-T
- 把BN替换为LN,准确率达到了81.5%
- 使用单独的下采样层,,就是通过一个Laryer Normalization加上一个卷积核大小为2步距为2的卷积层构成。更改后准确率就提升到了82.0%。
ResNeXt-ify
利用了DW卷积,将最初的通道数从64调整为96,最终准确率达到了80.5%。
inverted bottleneck
作者认为Transformer block中的MLP模块非常像MobileNetV2中的Inverted Bottleneck模块,即两头细中间粗。作者采用Inverted Bottleneck模块后,在较小的模型上准确率由80.5%提升到了80.6%,在较大的模型上准确率由81.9%提升到82.6%。
large kerner size
在Transformer中一般都是对全局做self-attention,比如Vision Transformer。即使是Swin Transformer也有7x7大小的窗口。但现在主流的卷积神经网络都是采用3x3大小的窗口,因为之前VGG论文中说通过堆叠多个3x3的窗口可以替代一个更大的窗口,而且现在的GPU设备针对3x3大小的卷积核做了很多的优化,所以会更高效。接着作者做了如下两个改动:Dwconv上移和更改卷积核大小。
总结
我感觉ConvNeXt就是对ST和VIT的一次翻译,将Transformer翻译成卷积神经网络的形式。同时,采用了各种方法进行调参以提高成功率。但这样的网络一些的部分是为了NLP任务而存在的,对于CV任务却获得了更好的结果emmm,感觉是工程科学了。