机器学习之XGboost代码实现
XGboost代码实现
XGboost的原生语言是c++,所以它的运行速度比较快。这里将会举例介绍一下python中如何调用XGboost,如果想了解XGboost的理论部分,可以参考这篇博客
文章目录
-
- 例1: XGboost基本应用
- 例2: 自定义XGboost损失函数的梯度和二阶导
- 例三: 将几种算法 逻辑回归、XGboost、随机森林、bagging、adaboost作对比
例1: XGboost基本应用
数据集:以鸢尾花数据集为例
# /usr/bin/python
# -*- encoding:utf-8 -*-
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import xgboost as xgb
def show_accuracy(a, b, tip):
acc = a.ravel() == b.ravel()
print (acc)
print (tip + '正确率:\t', float(acc.sum()) / a.size)
if __name__ == "__main__":
#加载iris数据集
data=load_iris()
X=data.data
Y=data.target
X_train,X_test,y_train,y_test=train_test_split(X,Y,test_size=0.25,random_state=1) #训练集和测试集
data_train = xgb.DMatrix(X_train,label=y_train)
data_test = xgb.DMatrix(X_test,label=y_test)
print (data_train)
print (type(data_train))
# 设置参数
param = {'max_depth': 3, 'eta': 1, 'silent': 1, 'objective': 'multi:softmax','num_class': 3} # logitraw
watchlist = [(data_test, 'eval'), (data_train, 'train')]
n_round = 7
bst = xgb.train(param, data_train, num_boost_round=4, evals=watchlist)
y_hat = bst.predict(data_test)
show_accuracy(y_hat, y_test, 'XGBoost ')
结果显示:
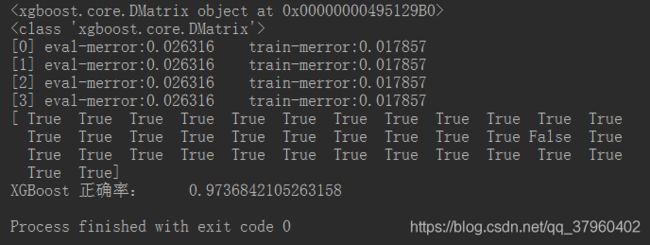
xgb.train(),bst.predicty
bst = xgb.train(param, data_train, num_boost_round=4, evals=watchlist)
y_hat = bst.predict(data_test)
xgb.train()和xgb.predict是xgboost训练和测试的方式
xgb.train()函数原型:
xgboost.train(params,dtrain,num_boost_round=10,evals=(),obj=None,feval=None,maximize=False,early_stopping_rounds=None,evals_result=None,verbose_eval=True,learning_rates=None,xgb_model=None)
1、params :这是一个字典,里面包含着训练中的参数关键字和对应的值
param = {‘max_depth’: 3, ‘eta’: 1, ‘silent’: 1, ‘objective’: ‘multi:softmax’,‘num_class’: 3}
- ‘max_depth’:树的深度,默认值是6
- ‘eta’:步长用于防止过拟合,范围是0~1,默认值0.3
- ‘silent’: 设置成1则没有运行信息输出,设置为0有运行信息输出.
- ‘objective’:指定你想要的类型的学习者,包括线性回归、逻辑回归、泊松回归等,默认值设置为reg:linear
- “reg:linear” :线性回归(默认).
- “reg:logistic”:逻辑回归
- “binary:logistic”:二分类的逻辑回归------输出概率值
- “binary:logitraw”:二分类的逻辑回归,输出的结果为wTx。
- “multi:softmax”:使用SoftMax进行多分类
- “num_class”:设置类的数量。 仅用于多类目标。
- “multi:softprob”:与softmax类似,预测输出ndata * nclass元素的向量,结果包含属于每个类的每个数据点的预测概率。
- “rank:pairwise”:set xgboost to do ranking task by minimizing the pairwise loss
2、 dtrain :训练的数据
3、num_boost_round:提升迭代的个数
4、evals :用于对训练过程中进行评估列表中的元素。形式是evals = [(dtrain,’train’), (dval,’val’)]或者是evals = [ (dtrain,’train’)]
5、obj:自定义目标函数
6、feval:自定义评估函数
7、maximize: 是否对评估函数进行最大化
8、early_stopping_rounds:早期停止次数 ,假设为100,验证集的误差迭代到一定程度在100次内不能再继续降低,就停止迭代。
9、evals_result :字典,存储在watchlist 中的元素的评估结果
10、verbose_eval(可以输入布尔型或数值型):如果为True, 则对evals中元素的评估结果会输出在结果中;如果输入数字,假设为5,则每隔5个迭代输出一次。
11、learning_rates :每一次提升的学习率的列表
12、xgb_model:在训练之前用于加载的xgb model
去掉evals,结果变为:
watchlist = [(data_test, ‘eval’), (data_train, ‘train’)]
evals=watchlist
#bst = xgb.train(param, data_train, num_boost_round=4, evals=watchlist)
bst = xgb.train(param, data_train, num_boost_round=4) #去掉watchlist
结果如下:
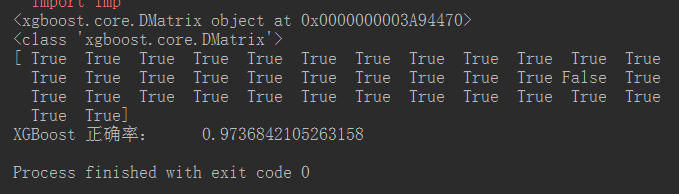
例2: 自定义XGboost损失函数的梯度和二阶导
我们要自定义损失函数的梯度和二阶导,这里不使用iris数据集了,因为样本数量至于150个,太少了。这里来预测蘑菇是否有毒。
代码如下:
# /usr/bin/python
# -*- encoding:utf-8 -*-
import xgboost as xgb
import numpy as np
# 1、xgBoost的基本使用
# 2、自定义损失函数的梯度和二阶导
# 3、binary:logistic/logitraw
# 定义f: theta * x
def log_reg(y_hat, y):
p = 1.0 / (1.0 + np.exp(-y_hat)) #认为自定义损失函数
g = p - y.get_label() #一阶导
h = p * (1.0-p) #二阶导
return g, h
def error_rate(y_hat, y):
return 'error', float(sum(y.get_label() != (y_hat > 0.5))) / len(y_hat)
if __name__ == "__main__":
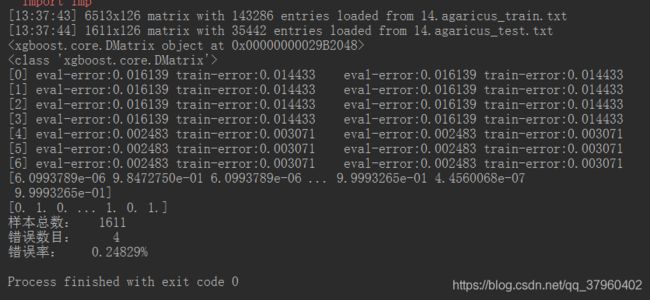
# 读取数据
data_train = xgb.DMatrix('14.agaricus_train.txt')
data_test = xgb.DMatrix('14.agaricus_test.txt')
print (data_train)
print (type(data_train))
# 设置参数
param = {'max_depth': 3, 'eta': 1, 'silent': 1, 'objective': 'binary:logistic'} # logitraw
watchlist = [(data_test, 'eval'), (data_train, 'train')]
n_round = 7
bst = xgb.train(param, data_train, num_boost_round=n_round, evals=watchlist, obj=log_reg, feval=error_rate)#feval 误差率
# 计算错误率
y_hat = bst.predict(data_test)
y = data_test.get_label()
print (y_hat)
print (y)
error = sum(y != (y_hat > 0.5))
error_rate = float(error) / len(y_hat)
print ('样本总数:\t', len(y_hat))
print ('错误数目:\t%4d' % error)
print ('错误率:\t%.5f%%' % (100*error_rate))
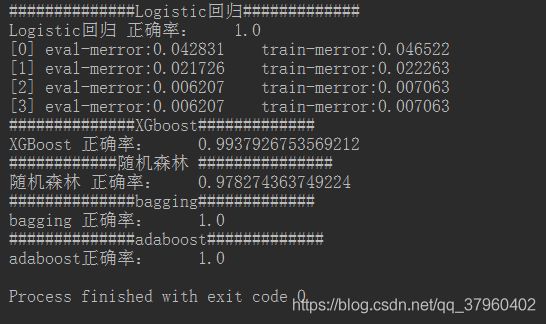
例三: 将几种算法 逻辑回归、XGboost、随机森林、bagging、adaboost作对比
注:所得结果不能作为评判这些算法好坏的标准。
# /usr/bin/python
# -*- coding:utf-8 -*-
import xgboost as xgb
import numpy as np
import scipy.sparse
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
#稀疏数据存储
def read_data(path):
y = []
row = []
col = []
values = []
r = 0 # 首行
for d in open(path):
d = d.strip().split() # 以空格分开
y.append(int(d[0]))
d = d[1:]
for c in d:
key, value = c.split(':')
row.append(r)
col.append(int(key))
values.append(float(value))
r += 1
x = scipy.sparse.csr_matrix((values, (row, col))).toarray()
y = np.array(y)
return x, y
def show_accuracy(a, b, tip):
acc = a.ravel() == b.ravel()
#print (acc)
print (tip + '正确率:\t', float(acc.sum()) / a.size)
if __name__ == '__main__':
x_train, y_train = read_data('14.agaricus_train.txt')
x_test, y_test = read_data('14.agaricus_test.txt')
#x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, train_size=0.6)
# Logistic回归
lr = LogisticRegression(penalty='l1')
lr.fit(x_train, y_train.ravel())
y_hat = lr.predict(x_test)
print ("##############Logistic回归#############")
show_accuracy(y_hat, y_test, 'Logistic回归 ')
# XGBoost
data_train = xgb.DMatrix(x_train, label=y_train)
data_test = xgb.DMatrix(x_test, label=y_test)
watch_list = [(data_test, 'eval'), (data_train, 'train')]
param = {'max_depth': 2, 'eta': 1, 'silent': 0, 'objective': 'multi:softmax', 'num_class': 3}
bst = xgb.train(param, data_train, num_boost_round=4, evals=watch_list) #evals=watch_list动态卡一看
y_hat = bst.predict(data_test)
print("##############XGboost#############")
show_accuracy(y_hat, y_test, 'XGBoost ')
#随机森林
rnd_clf = RandomForestClassifier(n_estimators=10, max_leaf_nodes=7, n_jobs=1)
rnd_clf.fit(x_train, y_train)
y_hat = rnd_clf.predict(x_test)
print("############随机森林 ###############")
show_accuracy(y_hat, y_test, '随机森林 ')
#bagging
tree = DecisionTreeClassifier(criterion='entropy', max_depth=None)
clf = BaggingClassifier(base_estimator=tree, n_estimators=6, max_samples=1.0, max_features=1.0, bootstrap=True,
bootstrap_features=False, n_jobs=1, random_state=1)
clf.fit(x_train, y_train)
y_hat = clf.predict(x_test)
print("##############bagging#############")
show_accuracy(y_hat, y_test, 'bagging ')
#adaboost
ada_real = AdaBoostClassifier(base_estimator=tree, learning_rate=0.5,
n_estimators=6, algorithm='SAMME.R') # 相比于ada_discrete只改变了Algorithm参数
ada_real.fit(x_train, y_train)
y_hat = clf.predict(x_test)
print("##############adaboost#############")
show_accuracy(y_hat, y_test, 'adaboost')
结果如下