逐行讲解大模型解码超参数大全(temperature、top-k、top-p等所有参数)
目录
- 简介
- 宏观概览
- 解码策略实现逻辑
- 常见的解码超参数
-
- temperature 温度系数
- top_k
- top_p
- repetition_penalty 重复惩罚
- 不常见的解码超参数
-
- min_p
- typical 解码
- ϵ 采样
- η 采样
- Classifier-Free Guidance(CFG)
- 序列偏置干预
- HammingDiversity
- 编码器重复惩罚
- n-gram重复惩罚
- 编码器n-gram重复惩罚
- bad_token惩罚
- 最小长度限制
- 最小新token长度限制
- 前缀约束生成
- 强制第一个token生成
- 强制 eos token 生成
- 处理 nan 和 inf 的 token
- 指数衰减长度惩罚
- 抑制token分数
- 抑制第一个token生成
- 文本水印
- 停止生成策略
-
- 最大长度限制
- 最大时间控制
- eos停止
- 执行顺序
- 备注
引用文章
关于大模型解码超参数是在哪里配置的可参考:逐行讲解transformers中model.generate()源码
如果文字版看不懂还有视频:
逐行讲解大模型解码所有超参数(temperature、top-k、top-p等所有参数)【上】
逐行讲解大模型解码所有超参数(temperature、top-k、top-p等所有参数)【中】
逐行讲解大模型解码所有超参数(temperature、top-k、top-p等所有参数)【下】
你知道生成解码的这些细节吗?
- temperature、top-k、top-p的执行顺序是什么?(不同的执行顺序影响巨大)
- 重复惩罚在贪婪解码时还需要处理吗?
- 除了这些参数还有哪些,能说出几种?
- 它们怎么实现的,难道用几百行放到一起吗?
- 如果你想自己额外加一个解码策略怎么加?
- 停止生成都有哪些条件,除了碰到就停止还有其他方式吗?
如果有哪一点不了解的,记得点赞收藏慢慢阅读哦~
简介
大模型在推理时,通常会逐个 token 进行生成。在模型的最后一层,会得到对应所有可能 token 的原始分数(logits)。此时可以通过调整某些超参数来修改这些原始分数,进而改变最终的概率分布。最后进行随机采样或贪婪搜索,来决定下一个 token 的生成。
本文就来讲解这些超参数各自的理论方法,以及在 transformers 上的源码实现。这些超参数除了常见的 temperature、top-k、top-p、重复惩罚,其实还有很多,学会其他参数的用法可以更灵活的控制生成,说不定衍生出一些创新的想法,或者以另一种方式解决业务中的问题,所以需要耐心看完哦~
除解码策略控制之外,本文还讲解模型停止生成的条件,以及停止生成的源码实现,例如最大长度控制、结束词控制,具体的代码实现可能会打破你以前的固有观念哦~
宏观概览
这里根据多种解码策略运行逻辑与作用的不同,进行分类简短概括。
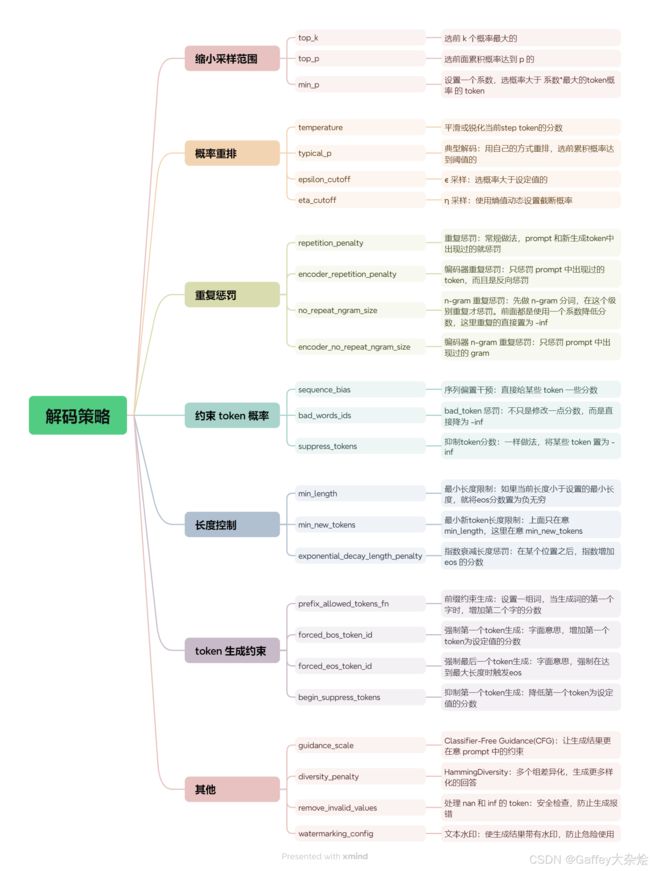
解码策略实现逻辑
所有的解码策略处理器都是一个单独的类(可以看下面温度系数的代码讲解),由__init__和__call__组成,这些小的处理器都放入了一个LogitsProcessorList类中,如下面代码所示。
它继承了list类型,所以也是一个列表。
它只有一个__call__函数(可以先通过processor=LogitsProcessorList()定义一个对象,然后使用processor()去调用__call__函数),里面会遍历自身列表内的所有子处理器,然后一个一个顺序实现。
class LogitsProcessorList(list):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.FloatTensor:
# 循环拿出自身列表中的所有子处理器
for processor in self:
# 取出子处理器的输入参数
function_args = inspect.signature(processor.__call__).parameters
# 如果需要一些额外的参数,而kwargs中未提供,则弹出异常,否则正常运行
if len(function_args) > 2:
if not all(arg in kwargs for arg in list(function_args.keys())[2:]):
raise ValueError(
f"Make sure that all the required parameters: {list(function_args.keys())} for "
f"{processor.__class__} are passed to the logits processor."
)
scores = processor(input_ids, scores, **kwargs)
else:
scores = processor(input_ids, scores)
return scores
需要注意的是,类似温度系数、top_k在贪婪解码时并不需要,而重复惩罚等操作是在任何解码方式都需要进行的。所以transformers使用LogitsProcessorList创建了两个对象,对上面两种分别进行处理,具体实现代码如下。这两个对象分别加入不同的解码处理器,后面会详细查看里面具体添加了什么。
prepared_logits_processor = self._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_length,
encoder_input_ids=inputs_tensor,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
device=inputs_tensor.device,
model_kwargs=model_kwargs,
negative_prompt_ids=negative_prompt_ids,
negative_prompt_attention_mask=negative_prompt_attention_mask,
)
prepared_logits_warper = (
self._get_logits_warper(generation_config, device=input_ids.device)
if generation_config.do_sample
else None
)
停止生成的实现逻辑也类似,每个条件的子处理器都是一个类,然后都放入一个StoppingCriteriaList类中,也是继承了列表类型。与之不同的是,解码策略每个子处理器都需要执行一遍,而停止生成的子处理器只要有一个满足,就认为应该停止了,所以需要记录每个子处理器的返回状态。
这里用is_done记录每个序列的状态,用或操作融合子处理器的返回结果,实现上面所述逻辑。除此之外还定义了一个获取最大长度的函数。
class StoppingCriteriaList(list):
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
is_done = torch.full((input_ids.shape[0],), False, device=input_ids.device, dtype=torch.bool)
for criteria in self:
is_done = is_done | criteria(input_ids, scores, **kwargs)
return is_done
@property
def max_length(self) -> Optional[int]:
for stopping_criterium in self:
if isinstance(stopping_criterium, MaxLengthCriteria):
return stopping_criterium.max_length
elif isinstance(stopping_criterium, MaxNewTokensCriteria):
return stopping_criterium.max_length
return None
常见的解码超参数
这个阶段,模型会一步一步生成下一个 token。在每一步中,模型的最后一层会生成每个 token 的原始分数(score,分数大小可能为任意值),也称为 logits,维度为[批次大小, 词表大小]。各种生成超参数就是通过各种方式改变 logits 的分布,最后再进行 softmax 得到所有 token 的概率分数(和为1)。下文在讲解时,会以 s作为最后一层的原始分数。
temperature 温度系数
-
改变最后一层 logits 的分布,控制生成多样性。
温度系数越大,分数的差距越小,多样性更强;
温度系数越小,分数的差距越大,确定性更强 -
计算方式:假设温度系数为 T,则处理后的分数为
s=s/T \text{s=s/T} s=s/T -
数值范围:
(0:+∞],浮点数,程序判断 T ≤ 0 T\leq0 T≤0 会弹出异常
示例:假设输入今天的天气是,logits 为下一步预测的 5 个 token 的原始分数,后面是温度系数为2和0.5的情况。可以看出,原始分数最大的是晴:
温度更大的时候,晴的概率降低了,就有更高的概率选中其他 token;
温度更小的时候,晴的概率变大了,就有更低的概率选中其他 token。
| 字符 | logits | 概率(T=1) | logits/T=2 | 概率(T=2) | logits/T=0.5 | 概率(T=0.5) |
|---|---|---|---|---|---|---|
晴 |
3.0 | 0.7433 | 1.5 | 0.4629 | 6.0 | 0.9678 |
阴 |
1.0 | 0.1006 | 0.5 | 0.1703 | 2.0 | 0.0177 |
雨 |
0.5 | 0.0610 | 0.25 | 0.1326 | 1.0 | 0.0065 |
雪 |
0.2 | 0.0452 | 0.1 | 0.1142 | 0.4 | 0.0036 |
风 |
0.3 | 0.0500 | 0.15 | 0.1200 | 0.6 | 0.0044 |
class TemperatureLogitsWarper(LogitsWarper):
def __init__(self, temperature: float):
# 这里判断数据类型和大小,如果小于等于0会弹出异常
if not isinstance(temperature, float) or not (temperature > 0):
except_msg = (
f"`temperature` (={temperature}) has to be a strictly positive float, otherwise your next token "
"scores will be invalid."
)
# 想让temperature == 0.0,可以设置do_sample=False实现相同功能
if isinstance(temperature, float) and temperature == 0.0:
except_msg += " If you're looking for greedy decoding strategies, set `do_sample=False`."
raise ValueError(except_msg)
self.temperature = temperature
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 这里很朴素的将原始分数除以温度系数
scores_processed = scores / self.temperature
return scores_processed
top_k
- 选出原始分数最高的 k 个 token 参与抽样,其他直接舍弃掉。舍弃的方法为将其分数置为负无穷,这样在后续的 softmax 计算时,得到的概率就为 0。
- 计算方式: t o p _ k top\_k top_k 代表 score 中概率最高的 k 个元素,其分数保持不变。
s = { s t o p _ k − ∞ o t h e r s s=\begin{cases}s&top\_k\\-\infty&others\end{cases} s={s−∞top_kothers - 数值范围:
(0:+∞],整数,程序判断 t o p _ k ≤ 0 top\_k\leq0 top_k≤0 会弹出异常
示例:同样输入今天的天气是,假设 top_k=3,后两个字的概率变为0
| 字符 | logits | 概率 | logits(top_k=3) | 概率(T=2) |
|---|---|---|---|---|
晴 |
3.0 | 0.7433 | 3.0 | 0.8214 |
阴 |
1.0 | 0.1006 | 1.0 | 0.1112 |
雨 |
0.5 | 0.0610 | 0.5 | 0.0674 |
雪 |
0.2 | 0.0452 | -inf | 0 |
风 |
0.3 | 0.0500 | -inf | 0 |
class TopKLogitsWarper(LogitsWarper):
def __init__(self, top_k: int, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1):
# 这里判断数据类型和大小,如果小于等于0会弹出异常
if not isinstance(top_k, int) or top_k <= 0:
raise ValueError(f"`top_k` has to be a strictly positive integer, but is {top_k}")
# min_tokens_to_keep 为搜索序列的个数
self.top_k = max(top_k, min_tokens_to_keep)
# 填充值,默认为负无穷
self.filter_value = filter_value
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 防止 top_k 大于词表大小
top_k = min(self.top_k, scores.size(-1)) # Safety check
# 先找到概率最大的k个索引
indices_to_remove = scores < torch.topk(scores, top_k)[0][..., -1, None]
# 将其余元素填充负无穷
scores_processed = scores.masked_fill(indices_to_remove, self.filter_value)
return scores_processed
top_p
- 现将原始分数从高到低排序,取 softmax 得到概率,从高到低累加概率,取出累加概率首次超过此阈值 p 的 token 集合。
- 实现方式:具体实现和理论相反,先将原始分数升序排列(概率小的在前面),计算累加概率,将累加概率小于等于
(1-top_p)的token概率置为0。 - 数值范围:
[0:1],浮点数,不符合范围弹出异常;但建议区间为(0:1) - 注:如果某个 token 概率过高,会把其他所有 token 都截断掉,降低了多样性,可能导致重复等问题。
示例:同样输入今天的天气是,假设 top_p=0.9,先按概率大小排序,到第三个字雨,首次累加概率超过0.9,所以舍弃后面的 token。
| 字符 | logits | 概率 | 累加概率 | 保留token |
|---|---|---|---|---|
晴 |
3.0 | 0.7433 | 0.7433 | ✅ |
阴 |
1.0 | 0.1006 | 0.8439 | ✅ |
雨 |
0.5 | 0.0610 | 0.9049 | ✅ |
风 |
0.3 | 0.0500 | 0.9549 | ❎ |
雪 |
0.2 | 0.0452 | 1 | ❎ |
class TopPLogitsWarper(LogitsWarper):
def __init__(self, top_p: float, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1):
top_p = float(top_p)
# 这里判断和异常描述不符
if top_p < 0 or top_p > 1.0:
raise ValueError(f"`top_p` has to be a float > 0 and < 1, but is {top_p}")
# 这个可能是历史遗留?外面都已经确认好了
if not isinstance(min_tokens_to_keep, int) or (min_tokens_to_keep < 1):
raise ValueError(f"`min_tokens_to_keep` has to be a positive integer, but is {min_tokens_to_keep}")
self.top_p = top_p
self.filter_value = filter_value
self.min_tokens_to_keep = min_tokens_to_keep
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 先将原始分数升序排列
sorted_logits, sorted_indices = torch.sort(scores, descending=False)
# 先取 softmax,然后计算累加值,.cumsum得到一个累加的数值列表
cumulative_probs = sorted_logits.softmax(dim=-1).cumsum(dim=-1)
# 找到累加概率小于(1 - self.top_p)的,结果为[ True, True, True,... True, False, ... False]
# True 代表要将概率置为负无穷的 token,False 代表要保留的 token
sorted_indices_to_remove = cumulative_probs <= (1 - self.top_p)
# 如果最后的 False 少于 min_tokens_to_keep 个,则设置至少保留 min_tokens_to_keep,将后面几个设为 False
sorted_indices_to_remove[..., -self.min_tokens_to_keep :] = 0
# 将位置为 True 的元素填充负无穷
indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)
scores_processed = scores.masked_fill(indices_to_remove, self.filter_value)
return scores_processed
repetition_penalty 重复惩罚
- 重复 token 惩罚,如果之前出现过某个 token(包括 prompt 和新生成的),则降低当前 step 该 token 出现的概率。
- 计算方式:先提取之前出现过的 token,假设当前 step 该 token 的原始分数为 s,重复惩罚系数为 r,则处理后的分数为
s = { s × r s < 0 s / r s ≥ 0 s= \begin{cases}s\times r&s<0\\s/r&s\geq0\end{cases} s={s×rs/rs<0s≥0 - 数值范围:
(0:+∞],由s/r可以看出惩罚系数不可为0
class RepetitionPenaltyLogitsProcessor(LogitsProcessor):
def __init__(self, penalty: float):
if not isinstance(penalty, float) or not (penalty > 0):
raise ValueError(f"`penalty` has to be a strictly positive float, but is {penalty}")
self.penalty = penalty
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
score = torch.gather(scores, 1, input_ids)
score = torch.where(score < 0, score * self.penalty, score / self.penalty)
scores_processed = scores.scatter(1, input_ids, score)
return scores_processed
不常见的解码超参数
min_p
-
min-p采样,源自论文 Min P Sampling: Balancing Creativity and Coherence at High Temperature。
优点:可以提高生成文本的质量和多样性在一次生成中,top_p 是一个定值,有时通过 top_p 来选取前几个概率大的 token 不太方便(详细理论可看论文),这里引入一个动态截断概率,提供另一种更灵活的方式控制生成。具体实现方法为:
- 将原始分数取 softmax 得到概率;
- 选取概率最大的 token,假设为 p;
- 计算截断概率: p ∗ m i n _ p p*min\_p p∗min_p;
- 将小于截断概率的 token 舍弃(舍弃方法类似 top_p);
-
数据范围:
[0, 1],通常选择为 0.01-0.2,类比于 top_p 选择 0.99-0.8
class MinPLogitsWarper(LogitsWarper):
def __init__(self, min_p: float, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1):
# 检查数值范围
if not (0 <= min_p <= 1.0):
raise ValueError(f"`min_p` has to be a float in the [0, 1] interval, but is {min_p}")
if not isinstance(min_tokens_to_keep, int) or (min_tokens_to_keep < 1):
raise ValueError(f"`min_tokens_to_keep` has to be a positive integer, but is {min_tokens_to_keep}")
self.min_p = min_p
self.filter_value = filter_value
self.min_tokens_to_keep = min_tokens_to_keep
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 1.使用softmax得到概率分布
probs = torch.softmax(scores, dim=-1)
# 2.选取每个序列概率最高的那个token的概率
top_probs, _ = probs.max(dim=-1, keepdim=True)
# 3.计算截断概率
scaled_min_p = self.min_p * top_probs
# 4.筛选出概率小于截断概率的位置,形式为 tensor([False,... True, False]),需要过滤掉的置为True
tokens_to_remove = probs < scaled_min_p
# 按降序排序,并只得到降序后的索引
# 例如返回 tensor([1, 5, 0, 4, 3, 2]),代表索引 1 的概率最大,索引 5 次之
sorted_indices = torch.argsort(scores, descending=True, dim=-1)
# torch.gather 按照给的索引 sorted_indices 从 tokens_to_remove 中取出值,例如得到 tensor([False, False, False, False, False, True])
sorted_indices_to_remove = torch.gather(tokens_to_remove, dim=-1, index=sorted_indices)
# 这里确保至少有min_tokens_to_keep个会保留
sorted_indices_to_remove[..., : self.min_tokens_to_keep] = False
# 将True的填充为负无穷,即需要过滤掉的
indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)
scores_processed = scores.masked_fill(indices_to_remove, self.filter_value)
return scores_processed
typical 解码
-
典型采样,源自论文 Locally Typical Sampling
论文认为高概率的文本很可能是枯燥或重复的,含有的信息量较少,所以这里不总从高概率的 token 中进行采样。这里从信息论的角度出发,将token含有的信息量 I ( y t ) I(y_t) I(yt)的期望定义为
H ( y t ) = E ( I ( y t ) ) = − ∑ y ∈ V p ( y t ) log p ( y t ) H(y_{t})=E(I(y_{t}))=\begin{aligned}-\sum_{y\in\mathcal{V}}p(y_t)\log p(y_t)\end{aligned} H(yt)=E(I(yt))=−y∈V∑p(yt)logp(yt)
式中: y t y_t yt代表当前时间步的 token,省略了论文中的在 y < t y_{
论文在三种任务上计算人类语言和模型生成语言的差异,使用下面公式的指标发现与人类的差距较少
ϵ = − log p ^ ( y t ∣ y < t ) − H ( y t ∣ y < t ) \epsilon=\begin{aligned}-\log\widehat{p}(y_t \mid \boldsymbol{y}_{
基于此结论,典型采样从 ϵ \epsilon ϵ 最小的词开始构建采样空间( ϵ \epsilon ϵ 越小代表越与人类语言接近),直到采样空间中所有词的概率超过阈值。 -
数据范围:
(0,1)
class TypicalLogitsWarper(LogitsWarper):
def __init__(self, mass: float = 0.9, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1):
mass = float(mass)
# 检查数值范围
if not (mass > 0 and mass < 1):
raise ValueError(f"`typical_p` has to be a float > 0 and < 1, but is {mass}")
if not isinstance(min_tokens_to_keep, int) or (min_tokens_to_keep < 1):
raise ValueError(f"`min_tokens_to_keep` has to be a positive integer, but is {min_tokens_to_keep}")
self.filter_value = filter_value
self.mass = mass
self.min_tokens_to_keep = min_tokens_to_keep
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 先求 H(y_t)
normalized = torch.nn.functional.log_softmax(scores, dim=-1) # 对数概率分数 log p(y_t)
p = torch.exp(normalized) # 概率分布 p(y_t)
ent = -(normalized * p).nansum(-1, keepdim=True) # 信息量 H(y_t), .nansum代表将非 nan 的数字求和
# 求 ϵ
shifted_scores = torch.abs((-normalized) - ent) # ϵ 公式
sorted_scores, sorted_indices = torch.sort(shifted_scores, descending=False) # 按 ϵ 大小排序并得到索引
sorted_logits = scores.gather(-1, sorted_indices) # 按照 ϵ 的大小去除 score 分数
cumulative_probs = sorted_logits.softmax(dim=-1).cumsum(dim=-1) # 将分数概率化,然后累加筛选出 采样空间词的概率超过阈值
# 将超过阈值的token分数置为负无穷,使用类似 top_k 的方法
last_ind = (cumulative_probs < self.mass).sum(dim=1)
last_ind.clamp_(max=sorted_scores.shape[-1] - 1)
sorted_indices_to_remove = sorted_scores > sorted_scores.gather(1, last_ind.view(-1, 1))
sorted_indices_to_remove[..., : self.min_tokens_to_keep] = 0
indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)
# 将True的填充为负无穷,即需要过滤掉的
scores_processed = scores.masked_fill(indices_to_remove, self.filter_value)
return scores_processed
ϵ 采样
-
ϵ 采样,源自论文 Truncation Sampling as Language Model Desmoothing。
截断概率小于 ϵ 的 token -
数据范围:
(0,1)
class EpsilonLogitsWarper(LogitsWarper):
def __init__(self, epsilon: float, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1):
epsilon = float(epsilon)
# 数值范围检查
if epsilon <= 0 or epsilon >= 1:
raise ValueError(f"`epsilon_cutoff` has to be a float > 0 and < 1, but is {epsilon}")
min_tokens_to_keep = int(min_tokens_to_keep)
if min_tokens_to_keep < 1:
raise ValueError(
f"`min_tokens_to_keep` has to be a strictly positive integer, but is {min_tokens_to_keep}"
)
self.epsilon = epsilon
self.filter_value = filter_value
self.min_tokens_to_keep = min_tokens_to_keep
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 先概率化,然后找到概率小于设定值的
probabilities = scores.softmax(dim=-1)
indices_to_remove = probabilities < self.epsilon
# 同样的方式,将其置为负无穷
top_k = min(self.min_tokens_to_keep, scores.size(-1)) # Safety check
indices_to_remove = indices_to_remove & (scores < torch.topk(scores, top_k)[0][..., -1, None])
scores_processed = scores.masked_fill(indices_to_remove, self.filter_value)
return scores_processed
η 采样
-
η 采样,源自论文 Truncation Sampling as Language Model Desmoothing (与 ϵ 采样是同一篇)
考虑了相对概率的原理,通过引入熵的方式,计算截断概率优点:解决生成长文本时质量差的问题,从而产生了更连贯、更流畅的文本,且更不容易重复。例如,如果前一个词是
Donald,top_p会将Trump之外的词全部截断,类似这种情况就很容易造成重复生成。 -
数据范围:
(0,1)
class EtaLogitsWarper(LogitsWarper):
def __init__(
self, epsilon: float, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1, device: str = "cpu"
):
epsilon = float(epsilon)
# 数值范围检查
if epsilon <= 0 or epsilon >= 1:
raise ValueError(f"`eta_cutoff` has to be a float > 0 and < 1, but is {epsilon}")
min_tokens_to_keep = int(min_tokens_to_keep)
if min_tokens_to_keep < 1:
raise ValueError(
f"`min_tokens_to_keep` has to be a strictly positive integer, but is {min_tokens_to_keep}"
)
self.epsilon = torch.tensor(epsilon, device=device)
self.filter_value = filter_value
self.min_tokens_to_keep = min_tokens_to_keep
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 先概率化
probabilities = scores.softmax(dim=-1)
# 计算原始分数的熵
entropy = torch.distributions.Categorical(logits=scores).entropy()
# 使用论文中的计算方式得到截止概率
eta = torch.min(self.epsilon, torch.sqrt(self.epsilon) * torch.exp(-entropy))[..., None]
# 筛选出小于截止概率的 token
indices_to_remove = probabilities < eta
# 相同方式,将其置为负无穷
top_k = min(self.min_tokens_to_keep, scores.size(-1)) # Safety check
indices_to_remove = indices_to_remove & (scores < torch.topk(scores, top_k)[0][..., -1, None])
scores_processed = scores.masked_fill(indices_to_remove, self.filter_value)
return scores_processed
Classifier-Free Guidance(CFG)
- 源自论文:Stay on topic with Classifier-Free Guidance
借鉴文本到图像生成领域的方法,可参考 Classifier-Free Guidance的前世今生,及如何调教生成的“抽卡”过程
通过对比有提示词时的生成和无提示词时的生成的差异,让模型更注重提示词的内容,引导模型往正确的方向生成。 - 处理流程
- 得到有提示词的概率化输出
- 得到无提示词的概率化输出
- 将二者的差异缩放 guidance_scale,补偿到无提示词生成结果上(此时又非概率化了)
class UnbatchedClassifierFreeGuidanceLogitsProcessor(LogitsProcessor):
def __init__(
self,
guidance_scale: float,
model,
unconditional_ids: Optional[torch.LongTensor] = None,
unconditional_attention_mask: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = True,
):
self.guidance_scale = guidance_scale
self.model = model
self.unconditional_context = {
"input_ids": unconditional_ids,
"attention_mask": unconditional_attention_mask,
"use_cache": use_cache,
"past_key_values": None,
"first_pass": True,
}
def get_unconditional_logits(self, input_ids):
# 检查是不是生成第一个token
if self.unconditional_context["first_pass"]:
# 如果是第一个 token,根据 input_ids 去掉提示词部分,作为无提示生成的输入
# 这里整理 input_ids 和 attention_mask
if self.unconditional_context["input_ids"] is None:
self.unconditional_context["input_ids"] = input_ids[:, -1:]
if self.unconditional_context["attention_mask"] is None:
self.unconditional_context["attention_mask"] = torch.ones_like(
self.unconditional_context["input_ids"], dtype=torch.long
)
input_ids = self.unconditional_context["input_ids"]
attention_mask = self.unconditional_context["attention_mask"]
# 判断是不是生成第一个 token 的标志位
self.unconditional_context["first_pass"] = False
else:
# 如果不是生成第一个token,则使用之前的结果
attention_mask = torch.cat(
[
self.unconditional_context["attention_mask"],
torch.ones_like(input_ids[:, -1:], dtype=torch.long),
],
dim=1,
)
# 这里也使用了kv-cache,所以只取了 input_ids 最后一个,跟主模型同样的原理
if not self.unconditional_context["use_cache"]:
input_ids = torch.cat([self.unconditional_context["input_ids"], input_ids[:, -1:]], dim=1)
else:
input_ids = input_ids[:, -1:]
self.unconditional_context["input_ids"] = input_ids
self.unconditional_context["attention_mask"] = attention_mask
# 无提示词模型生成一份结果
out = self.model(
input_ids,
attention_mask=attention_mask,
use_cache=self.unconditional_context["use_cache"],
past_key_values=self.unconditional_context["past_key_values"],
)
self.unconditional_context["past_key_values"] = out.get("past_key_values", None)
# 将结果返回
return out.logits
def __call__(self, input_ids, scores):
# 主模型的原始分数概率化
scores = torch.nn.functional.log_softmax(scores, dim=-1)
# 这里属于冗余判断了,如果等于1就不会进来这里
if self.guidance_scale == 1:
return scores
# 得到无提示的输出原始分数
logits = self.get_unconditional_logits(input_ids)
# 当前 step 的 token 同样概率化
unconditional_logits = torch.nn.functional.log_softmax(logits[:, -1], dim=-1)
# 使用论文中的计算方式,将两者的差异缩放后补偿到无提示生成结果上
scores_processed = self.guidance_scale * (scores - unconditional_logits) + unconditional_logits
return scores_processed
序列偏置干预
- 原理:直接给某些 token 一些偏置分数,正偏置则提高该 token 的概率,负 token 降低该 token 概率。
- 输入形式:Dict[Tuple[int], float],输入是一个字典,其中的 key 为 tuple 形式,里面可以有多个值,存储 token_id;value 为偏置值,例如 -10。
- 注意:干预的
token是可以n-gram的,如果输入的key是(0, 3),那么只有在前一个token是0的时候,当前step会干预索引为3的token,此时执行的是2-gram。
class SequenceBiasLogitsProcessor(LogitsProcessor):
def __init__(self, sequence_bias: Dict[Tuple[int], float]):
self.sequence_bias = sequence_bias
# 验证一下输入格式是否正确
self._validate_arguments()
# Bias variables that will be populated on the first call (for retrocompatibility purposes, the vocabulary size
# is infered in the first usage, which inhibits initializing here)
self.length_1_bias = None
self.prepared_bias_variables = False
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 1 - 准备偏置,只在第一次生成时运行,
if not self.prepared_bias_variables:
self._prepare_bias_variables(scores)
# 2 - 准备一个空的数组用于存储偏置
bias = torch.zeros_like(scores)
# 3 - 先将长度为 1 的偏置加上
bias += self.length_1_bias
# 4 - 将长度大于 1 的偏置加上
for sequence_ids, sequence_bias in self.sequence_bias.items():
if len(sequence_ids) == 1: # the sequence is of length 1, already applied
continue
if len(sequence_ids) > input_ids.shape[1]: # the sequence is longer than the context, ignore
continue
prefix_length = len(sequence_ids) - 1
last_token = sequence_ids[-1]
matching_rows = torch.eq(
input_ids[:, -prefix_length:],
torch.tensor(sequence_ids[:-1], dtype=input_ids.dtype, device=input_ids.device),
).prod(dim=1)
bias[:, last_token] += torch.where(
matching_rows.bool(),
torch.tensor(sequence_bias, device=input_ids.device),
torch.tensor(0.0, device=input_ids.device),
)
# 5 - 将偏置加到原始分数上
scores_processed = scores + bias
return scores_processed
def _prepare_bias_variables(self, scores: torch.FloatTensor):
# 获取词表大小
vocabulary_size = scores.shape[-1]
# 检查超过范围的 token_id
invalid_biases = []
for sequence_ids in self.sequence_bias:
for token_id in sequence_ids:
if token_id >= vocabulary_size:
invalid_biases.append(token_id)
# 如果存在检查超过范围的 token_id,则弹出异常
if len(invalid_biases) > 0:
raise ValueError(
f"The model vocabulary size is {vocabulary_size}, but the following tokens were being biased: "
f"{invalid_biases}"
)
# 将 key 中长度为 1 的 tuple 放入到一个序列中,可以更方便计算
self.length_1_bias = torch.zeros((vocabulary_size,), dtype=torch.float).to(scores.device)
for sequence_ids, bias in self.sequence_bias.items():
if len(sequence_ids) == 1:
self.length_1_bias[sequence_ids[-1]] = bias
self.prepared_bias_variables = True
def _validate_arguments(self):
sequence_bias = self.sequence_bias
# 验证是否是字典,字典里面是不是 tuple 等
if not isinstance(sequence_bias, dict) or len(sequence_bias) == 0:
raise ValueError(f"`sequence_bias` has to be a non-empty dictionary, but is {sequence_bias}.")
if any(not isinstance(sequence_ids, tuple) for sequence_ids in sequence_bias.keys()):
raise ValueError(f"`sequence_bias` has to be a dict with tuples as keys, but is {sequence_bias}.")
if any(
any((not isinstance(token_id, (int, np.integer)) or token_id < 0) for token_id in sequence_ids)
or len(sequence_ids) == 0
for sequence_ids in sequence_bias.keys()
):
raise ValueError(
f"Each key in `sequence_bias` has to be a non-empty tuple of positive integers, but is "
f"{sequence_bias}."
)
# 偏置都得是 float 型
if any(not isinstance(bias, float) for bias in sequence_bias.values()):
raise ValueError(f"`sequence_bias` has to be a dict with floats as values, but is {sequence_bias}.")
HammingDiversity
- 源自论文:Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models
- 原理:group beam search 是在多个组上依次生成,不同的组内独立进行 beam search,期望得到多样性的回答。
但是,不同的组之间生成的结果往往差异性很小,生成的多个答案都比较相似,所以使用该方法跨组惩罚相似的 token,即进行第二个组生成时,降低前面组选中 token 的概率。
惩罚的方式为:前面出现过的token,原始分数 -= 权重 * 该token出现次数 - 输入参数:num_beam_groups(分组数量),num_beams(分支数量,这个为所有组加起来的分支),diversity_penalty(组间相同token惩罚系数)
- 数值范围:
num_beam_groups(int,>=2),num_beams(int,>=2),diversity_penalty(float,> 0.0) - 注:
num_beam_groups需要能被num_beams整除,虽然下面代码没有判断,但其他文件判断并会弹出异常
class HammingDiversityLogitsProcessor(LogitsProcessor):
def __init__(self, diversity_penalty: float, num_beams: int, num_beam_groups: int):
# 检查参数格式
if not isinstance(diversity_penalty, float) or (not diversity_penalty > 0.0):
raise ValueError("`diversity_penalty` should be a float strictly larger than 0.")
self._diversity_penalty = diversity_penalty
if not isinstance(num_beams, int) or num_beams < 2:
raise ValueError("`num_beams` should be an integer strictly larger than 1.")
self._num_beams = num_beams
if not isinstance(num_beam_groups, int) or num_beam_groups < 2:
raise ValueError("`num_beam_groups` should be an integer strictly larger than 1.")
if num_beam_groups > num_beams:
raise ValueError("`beam_groups` has to be smaller or equal to `num_beams`.")
# 每个组内的束搜索分支数量
self._num_sub_beams = num_beams // num_beam_groups
def __call__(
self,
input_ids: torch.LongTensor,
scores: torch.FloatTensor,
current_tokens: torch.LongTensor,
beam_group_idx: int,
) -> torch.FloatTensor:
# 长度为 num_beams * batch,前 _num_sub_beams 个代表第1组内的分支选择的token,以此类推
# 注意多个batch数据会拼接到一起,所以 num_beams + _num_sub_beams 索引的数据是第二个batch token的开始
batch_size = current_tokens.shape[0] // self._num_beams
# beam_group_idx为当前是第几组,这里找到当前组current_tokens开始的索引
group_start_idx = beam_group_idx * self._num_sub_beams
# 找到结束的索引,这里认为如果 num_beams 不能整除 num_beam_groups 的时候,会超出范围,所以做了min判断
group_end_idx = min(group_start_idx + self._num_sub_beams, self._num_beams)
group_size = group_end_idx - group_start_idx
vocab_size = scores.shape[-1]
# 如果是第一组,自然不用做惩罚
if group_start_idx == 0:
return scores
scores_processed = scores.clone()
# 批次内挨个处理
for batch_idx in range(batch_size):
# 得到前面组的token
previous_group_tokens = current_tokens[
batch_idx * self._num_beams : batch_idx * self._num_beams + group_start_idx
]
# 得到vocab_size大小的序列,前面选中的token_id位置 置为该token出现的次数
token_frequency = torch.bincount(previous_group_tokens, minlength=vocab_size).to(scores.device)
# 将前面选中的token根据数量惩罚 _diversity_penalty * token_frequency 分数
scores_processed[batch_idx * group_size : (batch_idx + 1) * group_size] -= (
self._diversity_penalty * token_frequency
)
return scores_processed
编码器重复惩罚
-
原理:与重复惩罚类似,只不过只对prompt中出现过的token进行惩罚,而且是“反向”惩罚,惩罚方式也是一样的 s = { s / r s < 0 s × r s ≥ 0 s= \begin{cases}s/ r&s<0\\s \times r&s\geq0\end{cases} s={s/rs×rs<0s≥0
-
反向惩罚:大于1会增加
prompt中出现过的token概率,鼓励重复,小于1降低。
class EncoderRepetitionPenaltyLogitsProcessor(LogitsProcessor):
def __init__(self, penalty: float, encoder_input_ids: torch.LongTensor):
if not isinstance(penalty, float) or not (penalty > 0):
raise ValueError(f"`penalty` has to be a strictly positive float, but is {penalty}")
# 反向惩罚,先取倒数
self.penalty = 1 / penalty
# 提前记录prompt中的id
self.encoder_input_ids = encoder_input_ids
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 先取出token_id为prompt的原始分数
score = torch.gather(scores, 1, self.encoder_input_ids)
# 做惩罚
score = torch.where(score < 0, score * self.penalty, score / self.penalty)
# 将分数替换回去
scores_processed = scores.scatter(1, self.encoder_input_ids, score)
return scores_processed
n-gram重复惩罚
- 原理:与之前惩罚都类似,只不过这个使用n-gram的级别,之前的惩罚相当于uni-gram,且这里直接将出现过的token分数置为负无穷,不只是做一些惩罚。
谨慎使用,容易造成某个词全文只会出现一次。 - 数值范围:
[1:+∞],整形
class NoRepeatNGramLogitsProcessor(LogitsProcessor):
def __init__(self, ngram_size: int):
if not isinstance(ngram_size, int) or ngram_size <= 0:
raise ValueError(f"`ngram_size` has to be a strictly positive integer, but is {ngram_size}")
self.ngram_size = ngram_size
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
num_batch_hypotheses = scores.shape[0] # batch_size
cur_len = input_ids.shape[-1] # 序列长度
scores_processed = scores.clone() # 复制出来一份原始分数
# 这里先得到所有 n-gram,再看当前step的gram之前是否出现过,得到之前出现过的token,具体函数在下面
banned_batch_tokens = _calc_banned_ngram_tokens(self.ngram_size, input_ids, num_batch_hypotheses, cur_len)
# 将这些token概率之后置为负无穷
for i, banned_tokens in enumerate(banned_batch_tokens):
scores_processed[i, banned_tokens] = -float("inf")
return scores_processed
def _calc_banned_ngram_tokens(
ngram_size: int, prev_input_ids: torch.Tensor, num_hypos: int, cur_len: int
) -> List[Iterable[int]]:
# 如果序列长度小于ngram_size,就没必要分gram了
if cur_len + 1 < ngram_size:
return [[] for _ in range(num_hypos)]
# 这里先分gram,这里每个batch返回一个字典,key是n-gram中第一个token_id,value当前gram后面的值
# 因为可能存在 (21, 15), (21, 51) 这两组gram的情况,第一个token相同,后面token不同,这时候就将后面的token整合放到一个列表中
# 返回举例:{(151643,): [151643, 151644], (151644,): [8948, 872, 77091]}
generated_ngrams = _get_ngrams(ngram_size, prev_input_ids, num_hypos)
# 搜索当前step的gram是否在之前出现过,如果出现过就提取出对应value值
banned_tokens = [
_get_generated_ngrams(generated_ngrams[hypo_idx], prev_input_ids[hypo_idx], ngram_size, cur_len)
for hypo_idx in range(num_hypos)
]
return banned_tokens
编码器n-gram重复惩罚
- 原理:与上一个n-gram重复惩罚类似,只不过这里只惩罚prompt中出现过的,用于在多轮对话中防止出现前几轮中的词,促进模型的健谈性。
- 数值范围:
[1:+∞],整形
class EncoderNoRepeatNGramLogitsProcessor(LogitsProcessor):
def __init__(self, encoder_ngram_size: int, encoder_input_ids: torch.LongTensor):
if not isinstance(encoder_ngram_size, int) or encoder_ngram_size <= 0:
raise ValueError(
f"`encoder_ngram_size` has to be a strictly positive integer, but is {encoder_ngram_size}"
)
self.ngram_size = encoder_ngram_size
if len(encoder_input_ids.shape) == 1:
encoder_input_ids = encoder_input_ids.unsqueeze(0)
self.batch_size = encoder_input_ids.shape[0]
# 这里提前建立好prompt中的n-gram词组
self.generated_ngrams = _get_ngrams(encoder_ngram_size, encoder_input_ids, self.batch_size)
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# B x num_beams
num_hypos = scores.shape[0]
num_beams = num_hypos // self.batch_size
cur_len = input_ids.shape[-1]
scores_processed = scores.clone()
# 直接搜索当前step出现的n-gram
banned_batch_tokens = [
_get_generated_ngrams(
self.generated_ngrams[hypo_idx // num_beams], input_ids[hypo_idx], self.ngram_size, cur_len
)
for hypo_idx in range(num_hypos)
]
# 进行惩罚
for i, banned_tokens in enumerate(banned_batch_tokens):
scores_processed[i, banned_tokens] = -float("inf")
return scores_processed
bad_token惩罚
- 原理:与之前的序列偏置干预类似,并且也是继承了序列偏置干预的类。
序列偏置干预是对某些token设置一些可调的分数增减,而bad_token惩罚直接将某些token的概率降到负无穷,保证输出不会出现该token。 - 注意:也是可以执行
n-gram方式,它的输入是 List[List[int]],相当于序列偏置干预输入Dict[Tuple[int], float]中的Tuple[int],只是默认将value值设置成-inf - 数值类型:List[List[int]]
# 继承了SequenceBiasLogitsProcessor类
class NoBadWordsLogitsProcessor(SequenceBiasLogitsProcessor):
def __init__(
self, bad_words_ids: List[List[int]], eos_token_id: Optional[Union[int, List[int], torch.Tensor]] = None
):
self.bad_word_ids = bad_words_ids
# 验证输入参数是否符合要求
self._validate_arguments()
# 防止 bad_word_ids 中出现 eos,要将其过滤掉
if eos_token_id is not None:
if not isinstance(eos_token_id, torch.Tensor):
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
eos_token_id = torch.tensor(eos_token_id)
bad_words_ids = list(
filter(lambda bad_token_seq: all(bad_token_seq != [i] for i in eos_token_id), bad_words_ids)
)
# 将某些token设为负无穷,然后父类初始化,就会运行父类的__call__了
sequence_bias = {tuple(sequence): float("-inf") for sequence in bad_words_ids}
super().__init__(sequence_bias=sequence_bias)
def _validate_arguments(self):
bad_words_ids = self.bad_word_ids
if not isinstance(bad_words_ids, list) or len(bad_words_ids) == 0:
raise ValueError(f"`bad_words_ids` has to be a non-empty list, but is {bad_words_ids}.")
if any(not isinstance(bad_word_ids, list) for bad_word_ids in bad_words_ids):
raise ValueError(f"`bad_words_ids` has to be a list of lists, but is {bad_words_ids}.")
if any(
any((not isinstance(token_id, (int, np.integer)) or token_id < 0) for token_id in bad_word_ids)
for bad_word_ids in bad_words_ids
):
raise ValueError(
f"Each list in `bad_words_ids` has to be a list of positive integers, but is {bad_words_ids}."
)
最小长度限制
- 原理:如果当前长度小于设置的最小长度,就将eos分数置为负无穷。
- 注:这里的最小长度包括prompt
class MinLengthLogitsProcessor(LogitsProcessor):
def __init__(self, min_length: int, eos_token_id: Union[int, List[int], torch.Tensor]):
if not isinstance(min_length, int) or min_length < 0:
raise ValueError(f"`min_length` has to be a non-negative integer, but is {min_length}")
# 检查eos token
if not isinstance(eos_token_id, torch.Tensor):
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
eos_token_id = torch.tensor(eos_token_id)
self.min_length = min_length
self.eos_token_id = eos_token_id
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 实现方法有点怪,直接将索引为eos的分数修改就可以了,弄了这么多
# 创建一个vocab大小的顺序索引列表
vocab_tensor = torch.arange(scores.shape[-1], device=scores.device)
self.eos_token_id = self.eos_token_id.to(scores.device)
# 将索引是eos的token设为True,其余为False
eos_token_mask = torch.isin(vocab_tensor, self.eos_token_id)
scores_processed = scores.clone()
# 如果长度没达到最小长度要求,就将其置为负无穷
if input_ids.shape[-1] < self.min_length:
scores_processed = torch.where(eos_token_mask, -math.inf, scores)
return scores_processed
最小新token长度限制
- 原理:与最小长度限制一样,只不是这里减去了prompt的长度,只有新生成token的长度小于设置值才将eos分数置为负无穷。
- 注:代码与上面几乎完全一样,就不再赘述了。
前缀约束生成
- 原理:自定义一个函数,当前面的token为某个值时,将当前生成的token限制在某几个。例如想要生成人名 Bob Marley,那么当前一个 token 是 Bob 时,限制后一个token只能是 Marley,以此生成想要的词组。
- 注:需要传入一个约束函数,例如下面代码中的 prefix_allowed_tokens_fn,需要传入batch_id(当前第几个batch)和 input_ids,提前设置一些规则,当触发某些条件,返回允许生成的 token_id。
def prefix_allowed_tokens_fn(batch_id, input_ids):
# 演示用例。尝试生成 Bob Marley
entity = tokenizer("Bob Marley", return_tensors="pt").input_ids[0]
if input_ids[-1] == entity[0]:
return [entity[1].item()]
elif input_ids[-2] == entity[0] and input_ids[-1] == entity[1]:
return [entity[2].item()]
return list(range(tokenizer.vocab_size))
class PrefixConstrainedLogitsProcessor(LogitsProcessor):
def __init__(self, prefix_allowed_tokens_fn: Callable[[int, torch.Tensor], List[int]], num_beams: int):
# 提前传入约束函数
self._prefix_allowed_tokens_fn = prefix_allowed_tokens_fn
self._num_beams = num_beams
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 使用mask的方式选择遮蔽token
mask = torch.full_like(scores, -math.inf)
# 一个批次一个批次处理
for batch_id, beam_sent in enumerate(input_ids.view(-1, self._num_beams, input_ids.shape[-1])):
# 束搜索处理
for beam_id, sent in enumerate(beam_sent):
# 得到允许生成的token
prefix_allowed_tokens = self._prefix_allowed_tokens_fn(batch_id, sent)
# 如果返回为空,弹出异常
if len(prefix_allowed_tokens) == 0:
raise ValueError(
f"`prefix_allowed_tokens_fn` returned an empty list for batch ID {batch_id}."
f"This means that the constraint is unsatisfiable. Please check your implementation"
f"of `prefix_allowed_tokens_fn` "
)
mask[batch_id * self._num_beams + beam_id, prefix_allowed_tokens] = 0
# 不被允许生成的token分数加上负无穷
scores_processed = scores + mask
return scores_processed
强制第一个token生成
- 原理:强制限制第一个生成的token_id
- 注:只在 encoder-decoder 模型使用,因为代码中判断在长度为1时触发此规则。
class ForcedBOSTokenLogitsProcessor(LogitsProcessor):
def __init__(self, bos_token_id: int):
# 指定第一个生成的 token_id
self.bos_token_id = bos_token_id
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 获取生成token的长度
cur_len = input_ids.shape[-1]
scores_processed = scores
# 只有长度为1时触发,但decoder-only模型一般都有prompt,很难触发
if cur_len == 1:
scores_processed = torch.full_like(scores, -math.inf)
scores_processed[:, self.bos_token_id] = 0
return scores_processed
强制 eos token 生成
- 原理:强制在达到最大长度时触发eos
- 注:只在达到最大长度 max_length 时触发
class ForcedEOSTokenLogitsProcessor(LogitsProcessor):
def __init__(self, max_length: int, eos_token_id: Union[int, List[int], torch.Tensor]):
self.max_length = max_length
# 整理eos格式
if not isinstance(eos_token_id, torch.Tensor):
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
eos_token_id = torch.tensor(eos_token_id)
self.eos_token_id = eos_token_id
# 验证eos数值
if torch.is_floating_point(eos_token_id) or (eos_token_id < 0).any():
raise ValueError(f"`eos_token_id` has to be a list of positive integers, but is {eos_token_id}")
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 获取生成token的长度
cur_len = input_ids.shape[-1]
self.eos_token_id = self.eos_token_id.to(scores.device)
scores_processed = scores
# 只在达到最大长度时触发
if cur_len == self.max_length - 1:
scores_processed = torch.full_like(scores, -math.inf)
scores_processed[:, self.eos_token_id] = 0
return scores_processed
处理 nan 和 inf 的 token
- 原理:将所有nan替换为0,将所有正无穷替换为当前数据类型的最大值,将负无穷替换为当前数据类型的最小值,防止生成失败。
class InfNanRemoveLogitsProcessor(LogitsProcessor):
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# nan 设置为 0
scores_processed = torch.where(scores != scores, 0.0, scores)
# +/-inf 设置成当前数据类型的最大/最小值
scores_processed = torch.where(scores == float("inf"), torch.finfo(scores.dtype).max, scores_processed)
scores_processed = torch.where(scores == -float("inf"), torch.finfo(scores.dtype).min, scores_processed)
return scores_processed
指数衰减长度惩罚
- 原理:在新生成token的某个位置之后,指数级增加 eos 的分数。增加数值为 r l r^l rl,r代表惩罚因子,l 代表从设置的开始位置到当前的token数,将该值加到eos的分数上。
- 计算公式: s c o r e e o s + = ∣ s c o r e e o s ∣ × ( r l − 1 ) score_{eos} += |score_{eos}|\times(r^{l}-1) scoreeos+=∣scoreeos∣×(rl−1)
class ExponentialDecayLengthPenalty(LogitsProcessor):
def __init__(
self,
exponential_decay_length_penalty: Tuple[int, float],
eos_token_id: Union[int, List[int], torch.Tensor],
input_ids_seq_length: int,
):
# 输入exponential_decay_length_penalty是一个元组,第一个元素代表从哪个位置开始惩罚,此处加上prompt的长度,代表设置的开始索引是新生成的token数
self.regulation_start = exponential_decay_length_penalty[0] + input_ids_seq_length
# 第二个代表惩罚因子
self.regulation_factor = exponential_decay_length_penalty[1]
# 整理eos
if not isinstance(eos_token_id, torch.Tensor):
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
eos_token_id = torch.tensor(eos_token_id)
self.eos_token_id = eos_token_id
if torch.is_floating_point(eos_token_id) or (eos_token_id < 0).any():
raise ValueError(f"`eos_token_id` has to be a list of positive integers, but is {eos_token_id}")
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 获取当前长度
cur_len = input_ids.shape[-1]
self.eos_token_id = self.eos_token_id.to(scores.device)
# 初始化一个值为零的向量
penalties = torch.zeros_like(scores)
scores_processed = scores
# 长度大于设置值后开始惩罚
if cur_len > self.regulation_start:
# 获取惩罚的数值,代表从惩罚位置开始又生成了几个token
penalty_idx = cur_len - self.regulation_start
# 这里先取eos的绝对值,再乘上长度,防止负增益
penalty = torch.abs(scores[:, self.eos_token_id]) * (pow(self.regulation_factor, penalty_idx) - 1)
# 将eos位置的分数替换
penalties[:, self.eos_token_id] = penalty
# 加到原始分数上
scores_processed = scores + penalties
return scores_processed
抑制token分数
- 原理:与序列偏置干预的方法类似,只不过取消了
n-gram,只能执行uni-gram,将设置的 token 分数直接设为负无穷
class SuppressTokensLogitsProcessor(LogitsProcessor):
def __init__(self, suppress_tokens):
# 抑制的 token
self.suppress_tokens = torch.tensor(list(suppress_tokens))
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 通常使用麻烦的方法修改token分数
vocab_tensor = torch.arange(scores.shape[-1], device=scores.device)
self.suppress_tokens = self.suppress_tokens.to(scores.device)
# 选出抑制token的id位置,将其设为True
suppress_token_mask = torch.isin(vocab_tensor, self.suppress_tokens)
# 将对应位置设为 -inf
scores = torch.where(suppress_token_mask, -float("inf"), scores)
return scores
抑制第一个token生成
- 原理:在第一个step时,强制降低某些 token 的分数,防止它在第一步生成。可以在 encoder-decoder 模型和 decoder-only 模型中使用。
class SuppressTokensAtBeginLogitsProcessor(LogitsProcessor):
def __init__(self, begin_suppress_tokens, begin_index):
# 设置某些token需要在第一步抑制
self.begin_suppress_tokens = torch.tensor(list(begin_suppress_tokens))
# 提前记录第一步token的序列长度
self.begin_index = begin_index
# 没有用到
def set_begin_index(self, begin_index):
self.begin_index = begin_index
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 先初始化词表大小的顺序列表
vocab_tensor = torch.arange(scores.shape[-1], device=scores.device)
self.begin_suppress_tokens = self.begin_suppress_tokens.to(scores.device)
# 将需要抑制的token选出来,对应位置设为True
suppress_token_mask = torch.isin(vocab_tensor, self.begin_suppress_tokens)
scores_processed = scores
# 如果是第一步,就将设置的token分数设为负无穷
# 这一步应该放在最开始,要不每个step都要运行上面代码初始化变量,浪费时间
if input_ids.shape[-1] == self.begin_index:
scores_processed = torch.where(suppress_token_mask, -float("inf"), scores)
return scores_processed
文本水印
- 源自论文:On the Reliability of Watermarks for Large Language Models
- github:https://github.com/jwkirchenbauer/lm-watermarking/tree/main
- 原理:通过修改文本生成时的概率添加水印,有多种实现方式及变体,具体请查看论文。
- 所需参数:
bias:将选中的 token 增加 bias 的分数,即水印context_width:利用当前 token 之前的 context_width 个窗口词,来创建随机种子数seeding_scheme:计算随机种子数的方式,lefthash或selfhashgreenlist_ratio:选取 green token 占总词表大小的比例(这里被选中的可能作为水印的 token 称为 green token)
- 实现步骤:
- 得到当前 step 所有 token 的分数,按分数大小降序排列
- 逐个取前 40 个分数最大的 token 获取 green token 名单(第3、4、5步),也就是说每个 token 都有一个名单,40是个任意数字,综合考虑效果和计算时间
- 设置随机种子,取当前 token_id 和之前的窗口词作为输入,根据不同的哈希算法得到一个随机种子数
- 摇随机数之后,按这个随机策略重排词表索引,得到词表大小但乱序的 token_id
- 按照 green token 比例获取前 n 个 token 作为 green token 名单
- 如果当前的 token 在 green token 名单中,就将其作为候选
- 重复这 40 次,得到最终所有的候选名单,将它们的分数加上 bias
class WatermarkLogitsProcessor(LogitsProcessor):
def __init__(
self,
vocab_size,
device,
greenlist_ratio: float = 0.25,
bias: float = 2.0,
hashing_key: int = 15485863,
seeding_scheme: str = "lefthash",
context_width: int = 1,
):
if seeding_scheme not in ["selfhash", "lefthash"]:
raise ValueError(f"seeding_scheme has to be one of [`selfhash`, `lefthash`], but found {seeding_scheme}")
if greenlist_ratio >= 1.0 or greenlist_ratio <= 0.0:
raise ValueError(
f"greenlist_ratio has be in range between 0.0 and 1.0, exclusively. but found {greenlist_ratio}"
)
self.vocab_size = vocab_size
# 按比例得到应该选择的绿色token数量
self.greenlist_size = int(self.vocab_size * greenlist_ratio)
self.bias = bias
self.seeding_scheme = seeding_scheme
self.rng = torch.Generator(device=device)
self.hash_key = hashing_key
self.context_width = context_width
self.rng.manual_seed(hashing_key)
self.table_size = 1_000_003
self.fixed_table = torch.randperm(self.table_size, generator=self.rng, device=device)
def set_seed(self, input_seq: torch.LongTensor):
# 取出窗口大小的token
input_seq = input_seq[-self.context_width :]
# 不同算法使用不同的hash方式得到种子数
if self.seeding_scheme == "selfhash":
# selfhash 利用的当前词和窗口词
a = self.fixed_table[input_seq % self.table_size] + 1
b = self.fixed_table[input_seq[-1] % self.table_size] + 1
seed = (self.hash_key * a * b).min().item()
else:
# lefthash 只利用最后一个token
seed = self.hash_key * input_seq[-1].item()
self.rng.manual_seed(seed % (2**64 - 1))
def _get_greenlist_ids(self, input_seq: torch.LongTensor) -> torch.LongTensor:
# 根据输入序列确定随机种子
self.set_seed(input_seq)
# 按这个随机种子随机排序词表,得到词表大小但乱序的 token_id
vocab_permutation = torch.randperm(self.vocab_size, device=input_seq.device, generator=self.rng)
# 按照比例取前面的token作为绿色token名单
greenlist_ids = vocab_permutation[: self.greenlist_size]
return greenlist_ids
def _score_rejection_sampling(self, input_seq: torch.LongTensor, scores: torch.FloatTensor) -> torch.LongTensor:
"""
Generate greenlist based on current candidate next token. Reject and move on if necessary.
Runs for a fixed number of steps only for efficiency, since the methods is not batched.
"""
final_greenlist = []
# 将当前 step 所有 token 的分数按分数大小降序排列,得到排序之后的索引值
_, greedy_predictions = scores.sort(dim=-1, descending=True)
# 40是个任意数字,使用概率最大的前40个token处理水印
for i in range(40):
# 每个token都有一个自己的绿色token名单,这里将输入序列和当前选中的token拼接输入
greenlist_ids = self._get_greenlist_ids(torch.cat([input_seq, greedy_predictions[i, None]], dim=-1))
# 如果当前token在名单中,将其加入到候选里
if greedy_predictions[i] in greenlist_ids:
final_greenlist.append(greedy_predictions[i])
return torch.tensor(final_greenlist, device=input_seq.device)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# 序列长度要大于窗口大小
if input_ids.shape[-1] < self.context_width:
logger.warning(
f"`input_ids` should have at least `{self.context_width}` tokens but has {input_ids.shape[-1]}. "
"The seeding will be skipped for this generation step!"
)
return scores
# 克隆一份分数
scores_processed = scores.clone()
# 批次内一个序列一个序列处理
for b_idx, input_seq in enumerate(input_ids):
# 两种处理算法
if self.seeding_scheme == "selfhash":
greenlist_ids = self._score_rejection_sampling(input_seq, scores[b_idx])
else:
greenlist_ids = self._get_greenlist_ids(input_seq)
# 得到候选token之后,将这些token的分数加上bias偏差
scores_processed[b_idx, greenlist_ids] = scores_processed[b_idx, greenlist_ids] + self.bias
return scores_processed
停止生成策略
最大长度限制
- 原理:当达到设置的最大长度 max_length 时,返回True,用于提示主函数中该序列结束生成。
- 注:这里传入 max_length 和 max_position_embeddings ,后者为预训练模型位置编码的最大长度。在推理时,如果超过了该长度可以继续生成,但效果难以保证,所以会弹出警告,提醒用户。
class MaxLengthCriteria(StoppingCriteria):
def __init__(self, max_length: int, max_position_embeddings: Optional[int] = None):
# 传入两种长度
self.max_length = max_length
self.max_position_embeddings = max_position_embeddings
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
# 获得当前序列长度
cur_len = input_ids.shape[-1]
# 判断是否超过最大长度,返回True或False
is_done = cur_len >= self.max_length
# 达成上面说的情况,弹出警告
if self.max_position_embeddings is not None and not is_done and cur_len >= self.max_position_embeddings:
logger.warning_once(
"This is a friendly reminder - the current text generation call will exceed the model's predefined "
f"maximum length ({self.max_position_embeddings}). Depending on the model, you may observe "
"exceptions, performance degradation, or nothing at all."
)
# 返回batch大小的序列,里面存入 is_done,用于提示是否结束生成,is_done的后续使用可以查看上文·解码策略实现逻辑·
return torch.full((input_ids.shape[0],), is_done, device=input_ids.device, dtype=torch.bool)
最大时间控制
- 原理:控制生成的最长时间,如果达到该时间则认为结束,防止一直生成无法反馈。
- 注:传入最长时间单位为 秒
class MaxTimeCriteria(StoppingCriteria):
def __init__(self, max_time: float, initial_timestamp: Optional[float] = None):
# 传入最大时间
self.max_time = max_time
# 如果传入开始时间则直接使用,否则以运行当前行时间为开始
self.initial_timestamp = time.time() if initial_timestamp is None else initial_timestamp
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
# 同样方法,判断是否超过限定时间,返回 is_done
is_done = time.time() - self.initial_timestamp > self.max_time
return torch.full((input_ids.shape[0],), is_done, device=input_ids.device, dtype=torch.bool)
eos停止
- 原理:当前token如果是eos,就认为生成结束
class EosTokenCriteria(StoppingCriteria):
def __init__(self, eos_token_id: Union[int, List[int], torch.Tensor]):
if not isinstance(eos_token_id, torch.Tensor):
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
eos_token_id = torch.tensor(eos_token_id)
self.eos_token_id = eos_token_id
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
self.eos_token_id = self.eos_token_id.to(input_ids.device)
# 苹果电脑的mps设备
if input_ids.device.type == "mps":
# https://github.com/pytorch/pytorch/issues/77764#issuecomment-2067838075
is_done = (
input_ids[:, -1]
.tile(self.eos_token_id.shape[0], 1)
.eq(self.eos_token_id.unsqueeze(1))
.sum(dim=0)
.bool()
.squeeze()
)
else:
# 查看最后一个token是不是eos
is_done = torch.isin(input_ids[:, -1], self.eos_token_id)
return is_done
执行顺序
- _get_logits_warper 中的处理器的执行顺序如下
- temperature
- top_k
- top_p
- min_p
- typical 解码
- ϵ 采样
- η 采样
- _get_logits_processor 中的处理器执行顺序与目录相符
备注
本篇文章是拆解 transformers 源码逐行解析的,随着版本更新也会增加其他的处理器,我会及时补充。如有不对也请指出,我及时改正,谢谢。