算法基础课【合集2】
文章目录
- 数学知识
-
- AcWing 866. 试除法判定质数
- AcWing 867. 分解质因数
- AcWing 868. 筛质数
- AcWing 869. 试除法求约数
- AcWing 870. 约数个数
- AcWing 871. 约数之和
- AcWing 872. 最大公约数
- AcWing 873. 欧拉函数
- AcWing 874. 筛法求欧拉函数
- AcWing 875. 快速幂
- AcWing 876. 快速幂求逆元
- AcWing 877. 扩展欧几里得算法
- AcWing 878. 线性同余方程
- AcWing 204. 表达整数的奇怪方式
- AcWing 883. 高斯消元解线性方程组
- AcWing 884. 高斯消元解异或线性方程组
- AcWing 885. 求组合数 I
- AcWing 886. 求组合数 II
- AcWing 887. 求组合数 III
- AcWing 888. 求组合数 IV
- AcWing 889. 满足条件的01序列
- AcWing 890. 能被整除的数
- AcWing 891. Nim游戏
- AcWing 892. 台阶-Nim游戏
- AcWing 893. 集合-Nim游戏
- AcWing 894. 拆分-Nim游戏
- 动态规划
-
- AcWing 2. 01背包问题
- AcWing 3. 完全背包问题
- AcWing 4. 多重背包问题
- AcWing 5. 多重背包问题 II
- AcWing 9. 分组背包问题
- AcWing 898. 数字三角形
- AcWing 895. 最长上升子序列
- AcWing 896. 最长上升子序列 II
- AcWing 897. 最长公共子序列
- AcWing 902. 最短编辑距离
- AcWing 899. 编辑距离
- AcWing 282. 石子合并
- AcWing 900. 整数划分
- AcWing 338. 计数问题
- AcWing 291. 蒙德里安的梦想
- AcWing 91. 最短Hamilton路径
- AcWing 285. 没有上司的舞会
- AcWing 901. 滑雪
- 贪心
-
- AcWing 905. 区间选点
- AcWing 908. 最大不相交区间数量
- AcWing 906. 区间分组
- AcWing 907. 区间覆盖
- AcWing 148. 合并果子
- AcWing 913. 排队打水
- AcWing 104. 货仓选址
- AcWing 125. 耍杂技的牛
- 时空复杂度分析
数学知识
AcWing 866. 试除法判定质数
给定 n 个正整数 ai,判定每个数是否是质数。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个正整数 ai。
输出格式
共 n 行,其中第 i 行输出第 i 个正整数 ai 是否为质数,是则输出 Yes,否则输出 No。
数据范围
1≤n≤100,
1≤ai≤ 2 31 − 1 2^{31}−1 231−1
输入样例:
2
2
6
输出样例:
Yes
No
is_pirme模板
#includeAcWing 867. 分解质因数
给定 n 个正整数 ai,将每个数分解质因数,并按照质因数从小到大的顺序输出每个质因数的底数和指数。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个正整数 ai。
输出格式
对于每个正整数 ai,按照从小到大的顺序输出其分解质因数后,每个质因数的底数和指数,每个底数和指数占一行。
每个正整数的质因数全部输出完毕后,输出一个空行。
数据范围
1≤n≤100,
2≤ai≤2× 1 0 9 10^9 109
输入样例:
2
6
8
输出样例:
2 1
3 1
2 3
divide-朴素版枚举-按顺序试除
#include AcWing 868. 筛质数
给定一个正整数 n,请你求出 1∼n 中质数的个数。
输入格式
共一行,包含整数 n。
输出格式
共一行,包含一个整数,表示 1∼n 中质数的个数。
数据范围
1≤n≤ 1 0 6 10^6 106
输入样例:
8
输出样例:
4
好总结
线性筛法核心操作分析-两种情况:
i % primes[j] == 0 primes[j]一定是i的最小质因子, 则primes[j]一定是primes[j] * i的最小质因子
i % primes[j] != 0 此时primes[j] 一定小于i的所有质因子,此时primes[j]也一定是primes[j] * i的最小质因子
综上:primes[j]一定是primes[j] * i的最小质因子:筛去primes[j] * i 标记合数为true
从小到大枚举现有质数 <= n / i : for (int j = 0; primes[j] <= n / i; j ++ )
线性筛法:质数打表【枚举区间所有质数】
#include朴素筛法
//朴素筛法 - 埃式筛法【鉴于时间复杂度:算法题就不用此筛法啦】
void get_primes(int n)
{
for (int i = 2; i <= n; i ++ )//对所有数的倍数筛除
{
if (st[i]) continue;
primes[cnt ++ ] = i;
for (int j = i + i; j <= n; j += i)
st[j] = true;
}
}
AcWing 869. 试除法求约数
给定 n 个正整数 ai,对于每个整数 ai,请你按照从小到大的顺序输出它的所有约数。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个整数 ai。
输出格式
输出共 n 行,其中第 i 行输出第 i 个整数 ai 的所有约数。
数据范围
1≤n≤100,
2≤ai≤2× 1 0 9 10^9 109
输入样例:
2
6
8
输出样例:
1 2 3 6
1 2 4 8
数论知识:若 n % b == 0 ,则 n % (n / b) == 0 : 即n整除b, 则n也整除 n b \bf\frac{n}{b} bn
[可以简单的逆推 : b * (n / b) == n一对因子]
#include AcWing 870. 约数个数
给定 n 个正整数 ai,请你输出这些数的乘积的约数个数,答案对 109+7 取模。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个整数 ai。
输出格式
输出一个整数,表示所给正整数的乘积的约数个数,答案需对 109+7 取模。
数据范围
1≤n≤100,
1≤ai≤2× 1 0 9 10^9 109
输入样例:
3
2
6
8
输出样例:
12
n个数的乘积的约数个数 - 公式
代码思想:读入n个数 : 分别计算每个数的质因子: 统计n个数的质因子【hash表:primes】
约数公式推导
原理:每个数可以拆解为n个质因子的乘积, 而质因子之间相乘得到的数就是一种因子
【n个数的乘积的值对应的约数个数 == (质因数指数 + 1)的乘积】
$x = a_1^{p_1} * a_2^{p_2} * a_3^{p_3} * a_4^{p_4} …* a_n^{p_n} $
即 x 分解成: ∑ 质因数 a i 指数 p i = = = > x 的约数个数 = ∏ ( p i + 1 ) 即x分解成:\sum质因数a_{i}^{指数p_i} ===> \color{blue}{x的约数个数 = \prod (p_i + 1)} 即x分解成:∑质因数ai指数pi===>x的约数个数=∏(pi+1)
#include divide函数封装版
#include 稍长版
void divide(int x)
{
for(int i = 2; i <= x / i; i++)
{
if(x % i == 0)
{
int s = 0;
while(x % i == 0) x /= i, s++;
primes[i] += s; //统计n个数的乘积因子个数
}
}
if(x > 1) primes[x] ++;
}
AcWing 871. 约数之和
给定 n 个正整数 ai,请你输出这些数的乘积的约数之和,答案对 109+7 取模。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个整数 ai。
输出格式
输出一个整数,表示所给正整数的乘积的约数之和,答案需对 109+7 取模。
数据范围
1≤n≤100,
1≤ai≤2× 1 0 9 10^9 109
输入样例:
3
2
6
8
输出样例:
252

x 的约数之和 = ( p 1 0 ∗ p 1 1 ∗ p 1 2 ∗ . . . p 1 α 1 ) . . . ( p k 0 ∗ p k 1 ∗ p k 2 ∗ . . . p k α k ) x的约数之和 = (p_1^0 * p_1^1 * p_1^2 * ... p_1^{\alpha_1}) ... (p_k^0 * p_k^1 * p_k^2 * ... p_k^{\alpha_k}) x的约数之和=(p10∗p11∗p12∗...p1α1)...(pk0∗pk1∗pk2∗...pkαk)
【暴力证明】: 展开式相等, 展开后每一项对应一个约数
divide简化版
#include #include AcWing 872. 最大公约数
给定 n 对正整数 ai,bi,请你求出每对数的最大公约数。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个整数对 ai,bi。
输出格式
输出共 n 行,每行输出一个整数对的最大公约数。
数据范围
1≤n≤105,
1≤ai,bi≤2× 1 0 9 10^9 109
输入样例:
2
3 6
4 6
输出样例:
3
2
gcd模板 + algorithm有__gcd(a, b)
c[n][m] = c[n][n - m]
#include练手-不重要哦
int gcd(int a, int b)
{
//if(a % b == 0) return b;
//else gcd(b, a % b); //return 加不加都行, 递归最后都等效返回return b
//return a % b == 0 ? b : gcd(b, a % b);
//y总写法
// if(b == 0 ) return a;
// else return gcd(b, a % b);
//return b ? gcd(b, a % b) : a;
}
天梯简写:调用库
最大公约数 , 最小公倍数
#includeAcWing 873. 欧拉函数
给定 n 个正整数 ai,请你求出每个数的欧拉函数。
欧拉函数的定义
1∼N 中与 N 互质的数的个数被称为欧拉函数,记为 ϕ ( N ) \phi(N) ϕ(N)
若在算数基本定理中, N = p 1 a 1 p 2 a 2 p 3 a 3 . . . p m a m \color{black}{N= p_1^{a_1}p_2^{a_2}p_3^{a_3}...p_m^{a_m}} N=p1a1p2a2p3a3...pmam 则:
ϕ ( N ) = N × p 1 − 1 p 1 × p 2 − 1 p 2 × p 3 − 1 p 3 × . . . × p m − 1 p m {\color{black}{\phi(N) = N × \frac{p_1-1}{p_1} × \frac{p_2-1}{p_2} × \frac{p_3-1}{p_3} × ... ×\frac{p_m-1}{p_m}}} ϕ(N)=N×p1p1−1×p2p2−1×p3p3−1×...×pmpm−1
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个正整数 ai。
输出格式
输出共 n 行,每行输出一个正整数 ai 的欧拉函数。
数据范围
1≤n≤100,
1≤ai≤2× 1 0 9 10^9 109
输入样例:
3
3
6
8
输出样例:
2
2
4
欧拉函数的定义
1∼N 中与 N 互质的数的个数被称为欧拉函数,记为 ϕ ( N ) \phi(N) ϕ(N)
若在算数基本定理中, N = p 1 a 1 p 2 a 2 p 3 a 3 . . . p m a m \color{orange}{N= p_1^{a_1}p_2^{a_2}p_3^{a_3}...p_m^{a_m}} N=p1a1p2a2p3a3...pmam 则:
ϕ ( N ) = N × p 1 − 1 p 1 × p 2 − 1 p 2 × p 3 − 1 p 3 × . . . × p m − 1 p m \large{\color{blue}{\phi(N) = N × \frac{p_1-1}{p_1} × \frac{p_2-1}{p_2} × \frac{p_3-1}{p_3} × ... ×\frac{p_m-1}{p_m}}} ϕ(N)=N×p1p1−1×p2p2−1×p3p3−1×...×pmpm−1
#include AcWing 874. 筛法求欧拉函数
给定一个正整数 n,求 1∼n 中每个数的欧拉函数之和。
输入格式
共一行,包含一个整数 n。
输出格式
共一行,包含一个整数,表示 1∼n 中每个数的欧拉函数之和。
数据范围
1≤n≤ 1 0 6 10^6 106
输入样例:
6
输出样例:
12
求1~N中每个数的欧拉函数 - 线性筛法打表
① ϕ ( N ) = N × p 1 − 1 p 1 × p 2 − 1 p 2 × p 3 − 1 p 3 × . . . × p m − 1 p m \large{\color{pink}{\phi(N) = N × \frac{p_1-1}{p_1} × \frac{p_2-1}{p_2} × \frac{p_3-1}{p_3} × ... ×\frac{p_m-1}{p_m}}} ϕ(N)=N×p1p1−1×p2p2−1×p3p3−1×...×pmpm−1
展开式推导:
②i % primes[j] == 0 时:
ϕ ( p r i m e s [ j ] ∗ i ) = ϕ ( i ) ∗ ( p r i m e s [ j ] ) \huge{\color{blue}{\phi(primes[j] * i) =\phi(i) * (primes[j])} } ϕ(primes[j]∗i)=ϕ(i)∗(primes[j])
③i % primes[j] != 0 时:
ϕ ( p r i m e s [ j ] ∗ i ) = ϕ ( i ) ∗ p r i m e s [ j ] ∗ p r i m e s [ j ] − 1 p r i m e s [ j ] \huge{\color{lightblue}{\phi(primes[j] * i) = \phi(i) * primes[j] * \frac{primes[j] - 1}{primes[j]} } } ϕ(primes[j]∗i)=ϕ(i)∗primes[j]∗primes[j]primes[j]−1
ϕ ( p r i m e s [ j ] ∗ i ) = ϕ ( i ) ∗ ( p r i m e s [ j ] − 1 ) \huge{\color{blue}{\phi(primes[j] * i) =\phi(i)* (primes[j] - 1)}} ϕ(primes[j]∗i)=ϕ(i)∗(primes[j]−1)
1~N:每轮的N为自身数值 在[1, 自身值]区间: 质数互质的个数 = 自身值 - 1
代码线性筛法改造 phi[1] = 1, phi[2] = 1, phi[3] = 2, phi[5] = 4; 【与质数互质的个数 = 每轮N - 1】
int t = primes[j] * i; (简化代码)
#include y总推导
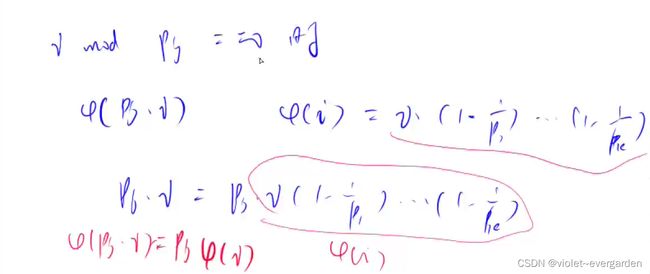

AcWing 875. 快速幂
给定 n 组 ai,bi,pi,对于每组数据,求出 abiimodpi 的值。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含三个整数 ai,bi,pi。
输出格式
对于每组数据,输出一个结果,表示 abiimodpi 的值。
每个结果占一行。
数据范围
1≤n≤100000,
1≤ai,bi,pi≤2× 1 0 9 10^9 109
输入样例:
2
3 2 5
4 3 9
输出样例:
4
1
a *= a 不完全等价于a = a * a 【原因:类型转化精度变化造成数据不精确】 ==> 有不同类型时就老实使用a = a * a
#includemycode2022【全LL版】
#includeAcWing 876. 快速幂求逆元
给定 n 组 ai,pi,其中 pi 是质数,求 ai 模 pi 的乘法逆元,若逆元不存在则输出 impossible。
注意:请返回在 0∼p−1 之间的逆元。
乘法逆元的定义
若整数 b,m 互质,并且对于任意的整数 a,如果满足 b ∣ a b~|~a b ∣ a,则存在一个整数 x,使得 a / b ≡ a × x ( m o d m ) a/b≡a×x(mod~m) a/b≡a×x(mod m),则称 x 为 b 的模 m 乘法逆元,记为 b − 1 ( m o d m ) b−1(mod~m) b−1(mod m)。
b 存在乘法逆元的充要条件是 b 与模数 m 互质。当模数 m 为质数时, b m − 2 b^{m−2} bm−2 即为 b b b 的乘法逆元。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个数组 ai,pi,数据保证 pi 是质数。
输出格式
输出共 n 行,每组数据输出一个结果,每个结果占一行。
若 ai 模 pi 的乘法逆元存在,则输出一个整数,表示逆元,否则输出 impossible。
数据范围
1≤n≤ 1 0 5 10^5 105,
1≤ai,pi≤2∗ 1 0 9 10^9 109
输入样例:
3
4 3
8 5
6 3
输出样例:
1
2
impossible
逆元计算原理(找到一个数x满足①式)
① a b ≡ a ∗ x \color{bule}{ \huge{\frac{a}{b} \equiv a*x } } ba≡a∗x (mod m)
② a b ≡ a ∗ b − 1 \huge{\frac{a}{b} \equiv a*b^{-1} } ba≡a∗b−1 (mod m)
两边同乘b:
③ b ∗ a b ≡ a ∗ b − 1 ∗ b \huge{b * \frac{a}{b} \equiv a*b^{-1} * b } b∗ba≡a∗b−1∗b (mod m)
再消去a:
④ b − 1 ∗ b ≡ 1 \huge{b^{-1} * b \equiv 1} b−1∗b≡1 (mod m)
费马小定理

举个例子 3 ∗ 3 − 1 ≡ 1 3 * 3^{-1} \equiv 1 3∗3−1≡1 (mod 5)
求 3 − 1 3^{-1} 3−1 (mod 5): 即 3 5 − 2 3^{5-2} % 5 = 2 35−2 在mod 5中3的逆元为2 【3 * 2 % 5 == 1】
根据逆元计算原理推导:
① b ∗ x ≡ 1 \huge{\color{bule}{b * x \equiv 1} } b∗x≡1 (mod p)
② b p − 1 ≡ 1 \huge{b^{p-1} \equiv 1 } bp−1≡1 (mod p)
拆解②:
③ b ∗ b p − 2 ≡ 1 \huge{b * b^{p-2} \equiv 1 } b∗bp−2≡1 (mod p)
即 b 的逆元 x = b p − 2 ( m o d p ) \color{red}{\huge{即b的逆元x = b^{p-2} }(mod p) } 即b的逆元x=bp−2(modp)
#include mycode2022
LL qmi(int a, int k, int p) //快速幂
{
LL res = 1 % p; //小心【p == 1】
while(k)
{
if(k & 1) res = res * a % p;
a = (LL)a * a % p;
k >>= 1;
}
return res;
}


AcWing 877. 扩展欧几里得算法
给定 n 对正整数 a i , b i a_i,b_i ai,bi,对于每对数,求出一组 x i , y i x_i,y_i xi,yi,使其满足 a i × x i + b i × y i = g c d ( a i , b i ) a_i×x_i+b_i×y_i=gcd(a_i,b_i) ai×xi+bi×yi=gcd(ai,bi)。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含两个整数 a i , b i a_i,b_i ai,bi。
输出格式
输出共 n 行,对于每组 a i , b i a_i,b_i ai,bi,求出一组满足条件的 x i , y i x_i,y_i xi,yi,每组结果占一行。
本题答案不唯一,输出任意满足条件的 x i , y i x_i,y_i xi,yi均可。
数据范围
1≤n≤ 1 0 5 10^5 105,
1≤ a i , b i a_i,b_i ai,bi≤2× 1 0 9 10^9 109
输入样例:
2
4 6
8 18
输出样例:
-1 1
-2 1
斐蜀定理 :若 x ∗ a + y ∗ b = n 倍的 g c d ( a , b ) , ( n = 1 , 2 , 3... ) x * a + y * b = n倍的gcd(a, b) , (n = 1, 2, 3 ...) x∗a+y∗b=n倍的gcd(a,b),(n=1,2,3...)
必能找到一组系数解x, y 使得a与b最大公约数的倍数
a % b = a - ⌊ a b ⌋ \lfloor \frac{a}{b} \rfloor ⌊ba⌋ * b = 余数r 【原理:a / b = ⌊ a b ⌋ \lfloor \frac{a}{b} \rfloor ⌊ba⌋ + 余数r】 (注: ⌊ a b ⌋ \lfloor \frac{a}{b} \rfloor ⌊ba⌋为向下取整)
扩展欧几里得定理:用于求解方程 a x + b y = g c d ( a , b ) ax + by = gcd(a,b) ax+by=gcd(a,b) 的系数解(x, y)
详细题解
推导:
a x + b y = d ax+by=d ax+by=d
递归替换: b y + ( a % b ) x = d by+(a\%b)x=d by+(a%b)x=d
余数替换: b y + ( a − a / b ∗ b ) x = d by+(a-a/b*b)x=d by+(a−a/b∗b)x=d
整理系数: a x + b ( y − a / b ∗ x ) = d ax+b(y-a/b*x)=d ax+b(y−a/b∗x)=d
此时ax的系数x不变,by的系数y变成 y = y − a / b ∗ x y = y - a / b * x y=y−a/b∗x 即 y − = a / b ∗ x y~~-= a~/~b * x y −=a / b∗x
#include AcWing 878. 线性同余方程
给定 n 组数据 a i , b i , m i a_i,b_i,m_i ai,bi,mi,对于每组数求出一个 xi,使其满足 a i × x i ≡ b i ( m o d m i ) a_i×x_i~≡~b_i(mod~m_i) ai×xi ≡ bi(mod mi),如果无解则输出 impossible。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一组数据 a i , b i , m i a_i,b_i,m_i ai,bi,mi。
输出格式
输出共 n 行,每组数据输出一个整数表示一个满足条件的 x i x_i xi,如果无解则输出 impossible。
每组数据结果占一行,结果可能不唯一,输出任意一个满足条件的结果均可。
输出答案必须在 int 范围之内。
数据范围
1≤n≤ 1 0 5 10^5 105,
1≤ a i , b i , m i a_i,b_i,m_i ai,bi,mi≤2× 1 0 9 10^9 109
输入样例:
2
2 3 6
4 3 5
输出样例:
impossible
-3
AcWing 204. 表达整数的奇怪方式
给定 2n 个整数 a 1 , a 2 , … , a n 和 m 1 , m 2 , … , m n a_1,a_2,…,a_n 和 m_1,m_2,…,m_n a1,a2,…,an和m1,m2,…,mn,求一个最小的非负整数 x,满足 ∀ i ∈ [ 1 , n ] , x ≡ m i ( m o d a i ) ∀_i∈[1,n],x≡m_i(mod~a_i) ∀i∈[1,n],x≡mi(mod ai)。
输入格式
第 1 行包含整数 n。
第 2…n+1 行:每 i+1 行包含两个整数 ai 和 mi,数之间用空格隔开。
输出格式
输出最小非负整数 x,如果 x 不存在,则输出 −1。
如果存在 x,则数据保证 x 一定在 64 位整数范围内。
数据范围
1≤ a i a_i ai≤ 2 31 − 1 2^{31}−1 231−1,
0≤ m i m_i mi< a i a_i ai
1≤n≤25
输入样例:
2
8 7
11 9
输出样例:
31
AcWing 883. 高斯消元解线性方程组
输入一个包含 n 个方程 n 个未知数的线性方程组。
方程组中的系数为实数。
求解这个方程组。
下图为一个包含 m 个方程 n 个未知数的线性方程组示例:
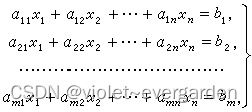
输入格式
第一行包含整数 n。
接下来 n 行,每行包含 n+1 个实数,表示一个方程的 n 个系数以及等号右侧的常数。
输出格式
如果给定线性方程组存在唯一解,则输出共 n 行,其中第 i 行输出第 i 个未知数的解,结果保留两位小数。
如果给定线性方程组存在无数解,则输出 Infinite group solutions。
如果给定线性方程组无解,则输出 No solution。
数据范围
1≤n≤100,
所有输入系数以及常数均保留两位小数,绝对值均不超过 100。
输入样例:
3
1.00 2.00 -1.00 -6.00
2.00 1.00 -3.00 -9.00
-1.00 -1.00 2.00 7.00
输出样例:
1.00
-2.00
3.00
AcWing 884. 高斯消元解异或线性方程组
输入一个包含 n 个方程 n 个未知数的异或线性方程组。
方程组中的系数和常数为 0 或 1,每个未知数的取值也为 0 或 1。
求解这个方程组。
异或线性方程组示例如下:
M[1][1]x[1] ^ M[1][2]x[2] ^ … ^ M[1][n]x[n] = B[1]
M[2][1]x[1] ^ M[2][2]x[2] ^ … ^ M[2][n]x[n] = B[2]
…
M[n][1]x[1] ^ M[n][2]x[2] ^ … ^ M[n][n]x[n] = B[n]
其中 ^ 表示异或(XOR),M[i][j] 表示第 i 个式子中 x[j] 的系数,B[i] 是第 i 个方程右端的常数,取值均为 0 或 1。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含 n+1 个整数 0 或 1,表示一个方程的 n 个系数以及等号右侧的常数。
输出格式
如果给定线性方程组存在唯一解,则输出共 n 行,其中第 i 行输出第 i 个未知数的解。
如果给定线性方程组存在多组解,则输出 Multiple sets of solutions。
如果给定线性方程组无解,则输出 No solution。
数据范围
1≤n≤100
输入样例:
3
1 1 0 1
0 1 1 0
1 0 0 1
输出样例:
1
0
0
AcWing 885. 求组合数 I
给定 n 组询问,每组询问给定两个整数 a,b,请你输出 C a b m o d ( 1 0 9 + 7 ) C^b_a ~mod(10^9+7) Cab mod(109+7) 的值。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一组 a 和 b。
输出格式
共 n 行,每行输出一个询问的解。
数据范围
1≤n≤10000,
1≤b≤a≤2000
输入样例:
3
3 1
5 3
2 2
输出样例:
3
10
1
dp法: C a b ( a , b 范围 2000 ) C_a^b(a, b范围2000) Cab(a,b范围2000)
注意: c [ n ] [ m ] : m < = n c[n][m] :m <= n c[n][m]:m<=n
上一个状态选或不选两种情况转移到下一个状态
f [ i ] [ j ] = f [ i − 1 ] [ j − 1 ] + f [ i − 1 ] [ j ] ; f[i][j] = f[i - 1][j - 1] + f[i - 1][j]; f[i][j]=f[i−1][j−1]+f[i−1][j]; 特例 i - 1不从1开始: i从
[0, N):打表
#include AcWing 886. 求组合数 II
给定 n 组询问,每组询问给定两个整数 a,b,请你输出 C a b m o d ( 1 0 9 + 7 ) C^b_a ~mod(10^9+7) Cab mod(109+7) 的值。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一组 a 和 b。
输出格式
共 n 行,每行输出一个询问的解。
数据范围
1≤n≤10000,
1≤b≤a≤ 1 0 5 10^5 105
输入样例:
3
3 1
5 3
2 2
输出样例:
3
10
1
C a b ( a , b 在 1 0 5 级别 ) C_a^b(a,b在\red{10^5}级别) Cab(a,b在105级别)
费马小定理:在(mod p)上: x的逆元: x − 1 = x p − 2 % p x^{-1} = x^{p - 2} \% p x−1=xp−2%p(mod p)
利用①组合数拆解公式 + ②阶乘预处理 + ③阶乘的逆元(费马小定理)
C a b = a ! b ! ( a − b ) ! \huge{C_a^b = \frac{a!}{b!(a-b)!}} Cab=b!(a−b)!a!
C a b = f a c t ( a ) ∗ i n f a c t ( b ) ∗ i n f a c t ( a − b ) \huge{\color{blue}{C_a^b = fact(a) * infact(b) * infact(a - b) } } Cab=fact(a)∗infact(b)∗infact(a−b)
fact(x): x的阶乘 infact(x): x阶乘的逆元 (mod 1 0 9 + 7 10^9 + 7 109+7)
( 可理解为 f a c t ( i ) 存 i ! , i n f a c t ( i ) 存 1 i ! ) 【预处理】强转 ( L L ) \color{red}{ (可理解为fact(i)存i!, infact(i)存 \frac{1}{i!})【预处理】强转(LL) } (可理解为fact(i)存i!,infact(i)存i!1)【预处理】强转(LL)
存数组:边界初始化 f a c t [ 0 ] = i n f a c t [ 0 ] = 1 ; 【乘积因子 1 】 fact[0] = infact[0] = 1; \color{green}{【乘积因子1】} fact[0]=infact[0]=1;【乘积因子1】
阶乘的逆元等效做分母 :举个例子 : 1 / x = 1 ∗ 1 x = x − 1 \color{lightgreen}{1 / x = 1 * \frac{1}{x} = x^{-1}} 1/x=1∗x1=x−1
【做分母】 如 ( x ! ) − 1 m o d ( 1 0 9 + 7 ) = 1 x ! m o d ( 1 0 9 + 7 ) \huge{(x!)^{-1} mod(10^9+7) = \frac{1}{x!} mod(10^9+7)} (x!)−1mod(109+7)=x!1mod(109+7)
#include 大佬的逆元图

LL qmi(LL a, LL k, LL p)
{
LL res = 1 % p;
while(k)
{
if( k & 1) res = res * a % p;
a = a * a % p;
k >>= 1;
}
return res % p;
}
AcWing 887. 求组合数 III
给定 n 组询问,每组询问给定三个整数 a,b,p,其中 p 是质数,请你输出 C a b m o d p C^b_a ~mod~p Cab mod p的值.
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一组 a,b,p。
输出格式
共 n 行,每行输出一个询问的解。
数据范围
1≤n≤20,
1≤b≤a≤ 1 0 1 8 10^18 1018,
1≤p≤ 1 0 5 10^5 105,
输入样例:
3
5 3 7
3 1 5
6 4 13
输出样例:
3
3
2
C a b % p C_a^b \, \% \, p Cab%p (a, b为 1 0 18 10^{18} 1018级别)
卢卡斯定理 C a b ≡ C a % p b % p C a / p b / p ( m o d p ) \huge{\color{blue}{C_{a}^{b} \equiv C_{a\%p}^{b\%p} C_{a / p}^{b / p} }(mod \quad p)} Cab≡Ca%pb%pCa/pb/p(modp)
【不想那么容易写错 - 全部long long就好了】
#include 纯LL版
#include AcWing 888. 求组合数 IV
输入 a,b,求 C a b C^b_a Cab 的值。
注意结果可能很大,需要使用高精度计算。
输入格式
共一行,包含两个整数 a 和 b。
输出格式
共一行,输出 C a b C^b_a Cab 的值。
数据范围
1≤b≤a≤5000
输入样例:
5 3
输出样例:
10
精准值 C a b C_a^b Cab (a, b <= 5000)
双指针枚举即可 for(int i = 1, j = a; i <= b; i++, j--)【加高精度乘除法】
C a b = a ! b ! ( a − b ) ! = a ∗ ( a − 1 ) . . . . . . ( a − b + 2 ) ∗ ( a − b + 1 ) b ! C_a^b = \frac{a!}{b!(a-b)!} = \frac{a * (a - 1) ......(a - b + 2) * (a - b + 1)}{b!} Cab=b!(a−b)!a!=b!a∗(a−1)......(a−b+2)∗(a−b+1)
但是这样运行效率慢, 进一步优化:【分解质因数】
①分解质因数
x = p 1 α 1 p 2 α 2 p 3 α 3 . . . p n α n \color{lightblue}{x = p_1^{\alpha_1} p_2^{\alpha_2} p_3^{\alpha_3} ... p_{n}^{\alpha_n} } x=p1α1p2α2p3α3...pnαn
a ! = ⌊ a p ⌋ + ⌊ a p 2 ⌋ + . . . + ⌊ a p n ⌋ \color{blue}{a! = \lfloor \frac{a}{p} \rfloor + \lfloor \frac{a}{p^2} \rfloor + ... + \lfloor \frac{a}{p^n} \rfloor} a!=⌊pa⌋+⌊p2a⌋+...+⌊pna⌋
用分母取出的 p i p^i pi的个数 减去 分子取出的 p i p^i pi的个数 再相乘
即 组合数 = ∏ i ( 分母的 p i 个数 − 分子的 p i 个数 ) 组合数 = \prod_{i}^{} ({分母的p_i个数 - 分子的p_i个数}) 组合数=∏i(分母的pi个数−分子的pi个数)
不错的解释
代码:
①get_primes(a), C a b C_a^b Cab, a >= b >= 所有质因数【线性筛法-质数打表】 (枚举到a即可,N也行但没必要)
②get(n, p)求每个质数在n中的次数
③vectormul高精度乘法求$组合数 = \prod_{i}^{} ({分母的p_i个数 - 分子的p_i个数}) $
sum[i] = get(a, p) - get(a - b, p) - get(b, p) 【分母 p i − 分子 p i p_i - 分子p_i pi−分子pi = C a b C_a^b Cab中 p i p_i pi的幂】
#include AcWing 889. 满足条件的01序列
给定 n 个 0 和 n 个 1,它们将按照某种顺序排成长度为 2n 的序列,求它们能排列成的所有序列中,能够满足任意前缀序列中 0 的个数都不少于 1 的个数的序列有多少个。
输出的答案对 1 0 9 + 7 10^9 + 7 109+7取模。
输入格式
共一行,包含整数 n。
输出格式
共一行,包含一个整数,表示答案。
数据范围
1≤n≤ 1 0 5 10^5 105
输入样例:
3
输出样例:
5
满足卡特兰数 Cat(n) = C 2 n n n + 1 \frac{C_{2n}^n}{n + 1} n+1C2nn
C a b ( a , b 在 1 0 5 级别 ) C_a^b(a,b在10^5级别) Cab(a,b在105级别)
利用①组合数拆解公式 + ②阶乘预处理 + ③阶乘的逆元(费马小定理)
C a b = a ! b ! ( a − b ) ! C_a^b = \frac{a!}{b!(a-b)!} Cab=b!(a−b)!a!
C a b = f a c t ( a ) ∗ i n f a c t ( b ) ∗ i n f a c t ( a − b ) \color{blue}{C_a^b = fact(a) * infact(b) * infact(a - b) } Cab=fact(a)∗infact(b)∗infact(a−b)
【代码】
逆元简写版函数**
C(a, b, mod)** , 求逆元快速幂**qmi(n + 1, mod - 2, mod)**
LL res = C(a, b, mod) * qmi(n + 1, mod - 2, mod) % mod;
封装版 - mycode2022【通用简记】
#include 疑惑
res * (i, p - 2, p)结果 $ = 0$ 不会报错 [猜测,分割表达式,使用最后一个表达式的值, p % p == 0]
res * (i, p - 2) 结果 $ \neq 0$ 证实用 p - 2 % p , 即表达式的选用
原版 - 简写版
#include AcWing 890. 能被整除的数
给定一个整数 n 和 m 个不同的质数 p1,p2,…,pm。
请你求出 1∼n 中能被 p1,p2,…,pm 中的至少一个数整除的整数有多少个。
输入格式
第一行包含整数 n 和 m。
第二行包含 m 个质数。
输出格式
输出一个整数,表示满足条件的整数的个数。
数据范围
1≤m≤16,
1≤n,pi≤ 1 0 9 10^9 109
输入样例:
10 2
2 3
输出样例:
7
AcWing 891. Nim游戏
给定 n 堆石子,两位玩家轮流操作,每次操作可以从任意一堆石子中拿走任意数量的石子(可以拿完,但不能不拿),最后无法进行操作的人视为失败。
问如果两人都采用最优策略,先手是否必胜。
输入格式
第一行包含整数 n。
第二行包含 n 个数字,其中第 i 个数字表示第 i 堆石子的数量。
输出格式
如果先手方必胜,则输出 Yes。
否则,输出 No。
数据范围
1≤n≤ 1 0 5 10^5 105,
1≤每堆石子数≤ 1 0 9 10^9 109
输入样例:
2
2 3
输出样例:
Yes
AcWing 892. 台阶-Nim游戏
现在,有一个 n 级台阶的楼梯,每级台阶上都有若干个石子,其中第 i 级台阶上有 ai 个石子(i≥1)。
两位玩家轮流操作,每次操作可以从任意一级台阶上拿若干个石子放到下一级台阶中(不能不拿)。
已经拿到地面上的石子不能再拿,最后无法进行操作的人视为失败。
问如果两人都采用最优策略,先手是否必胜。
输入格式
第一行包含整数 n。
第二行包含 n 个整数,其中第 i 个整数表示第 i 级台阶上的石子数 ai。
输出格式
如果先手方必胜,则输出 Yes。
否则,输出 No。
数据范围
1≤n≤ 1 0 5 10^5 105,
1≤ai≤ 1 0 9 10^9 109
输入样例:
3
2 1 3
输出样例:
Yes
AcWing 893. 集合-Nim游戏
给定 n 堆石子以及一个由 k 个不同正整数构成的数字集合 S。
现在有两位玩家轮流操作,每次操作可以从任意一堆石子中拿取石子,每次拿取的石子数量必须包含于集合 S,最后无法进行操作的人视为失败。
问如果两人都采用最优策略,先手是否必胜。
输入格式
第一行包含整数 k,表示数字集合 S 中数字的个数。
第二行包含 k 个整数,其中第 i 个整数表示数字集合 S 中的第 i 个数 si。
第三行包含整数 n。
第四行包含 n 个整数,其中第 i 个整数表示第 i 堆石子的数量 hi。
输出格式
如果先手方必胜,则输出 Yes。
否则,输出 No。
数据范围
1≤n,k≤100,
1≤si,hi≤10000
输入样例:
2
2 5
3
2 4 7
输出样例:
Yes
AcWing 894. 拆分-Nim游戏
给定 n 堆石子以及一个由 k 个不同正整数构成的数字集合 S。
现在有两位玩家轮流操作,每次操作可以从任意一堆石子中拿取石子,每次拿取的石子数量必须包含于集合 S,最后无法进行操作的人视为失败。
问如果两人都采用最优策略,先手是否必胜。
输入格式
第一行包含整数 k,表示数字集合 S 中数字的个数。
第二行包含 k 个整数,其中第 i 个整数表示数字集合 S 中的第 i 个数 si。
第三行包含整数 n。
第四行包含 n 个整数,其中第 i 个整数表示第 i 堆石子的数量 hi。
输出格式
如果先手方必胜,则输出 Yes。
否则,输出 No。
数据范围
1≤n,k≤100,
1≤si,hi≤10000
输入样例:
2
2 5
3
2 4 7
输出样例:
Yes
动态规划
AcWing 2. 01背包问题
给定 n 堆石子以及一个由 k 个不同正整数构成的数字集合 S。
现在有两位玩家轮流操作,每次操作可以从任意一堆石子中拿取石子,每次拿取的石子数量必须包含于集合 S,最后无法进行操作的人视为失败。
问如果两人都采用最优策略,先手是否必胜。
输入格式
第一行包含整数 k,表示数字集合 S 中数字的个数。
第二行包含 k 个整数,其中第 i 个整数表示数字集合 S 中的第 i 个数 si。
第三行包含整数 n。
第四行包含 n 个整数,其中第 i 个整数表示第 i 堆石子的数量 hi。
输出格式
如果先手方必胜,则输出 Yes。
否则,输出 No。
数据范围
1≤n,k≤100,
1≤si,hi≤10000
输入样例:
2
2 5
3
2 4 7
输出样例:
Yes
AcWing 3. 完全背包问题
有 N 种物品和一个容量是 V 的背包,每种物品都有无限件可用。
第 i 种物品的体积是 vi,价值是 wi。
求解将哪些物品装入背包,可使这些物品的总体积不超过背包容量,且总价值最大。
输出最大价值。
输入格式
第一行两个整数,N,V,用空格隔开,分别表示物品种数和背包容积。
接下来有 N 行,每行两个整数 vi,wi,用空格隔开,分别表示第 i 种物品的体积和价值。
输出格式
输出一个整数,表示最大价值。
数据范围
0
4 5
1 2
2 4
3 4
4 5
输出样例:
10
AcWing 4. 多重背包问题
有 N 种物品和一个容量是 V 的背包。
第 i 种物品最多有 si 件,每件体积是 vi,价值是 wi。
求解将哪些物品装入背包,可使物品体积总和不超过背包容量,且价值总和最大。
输出最大价值。
输入格式
第一行两个整数,N,V,用空格隔开,分别表示物品种数和背包容积。
接下来有 N 行,每行三个整数 vi,wi,si,用空格隔开,分别表示第 i 种物品的体积、价值和数量。
输出格式
输出一个整数,表示最大价值。
数据范围
0
4 5
1 2 3
2 4 1
3 4 3
4 5 2
输出样例:
10
AcWing 5. 多重背包问题 II
有 N 种物品和一个容量是 V 的背包。
第 i 种物品最多有 si 件,每件体积是 vi,价值是 wi。
求解将哪些物品装入背包,可使物品体积总和不超过背包容量,且价值总和最大。
输出最大价值。
输入格式
第一行两个整数,N,V,用空格隔开,分别表示物品种数和背包容积。
接下来有 N 行,每行三个整数 vi,wi,si,用空格隔开,分别表示第 i 种物品的体积、价值和数量。
输出格式
输出一个整数,表示最大价值。
数据范围
0
本题考查多重背包的二进制优化方法。
输入样例
4 5
1 2 3
2 4 1
3 4 3
4 5 2
输出样例:
10
AcWing 9. 分组背包问题
有 N 组物品和一个容量是 V 的背包。
每组物品有若干个,同一组内的物品最多只能选一个。
每件物品的体积是 vij,价值是 wij,其中 i 是组号,j 是组内编号。
求解将哪些物品装入背包,可使物品总体积不超过背包容量,且总价值最大。
输出最大价值。
输入格式
第一行有两个整数 N,V,用空格隔开,分别表示物品组数和背包容量。
接下来有 N 组数据:
每组数据第一行有一个整数 Si,表示第 i 个物品组的物品数量;
每组数据接下来有 Si 行,每行有两个整数 vij,wij,用空格隔开,分别表示第 i 个物品组的第 j 个物品的体积和价值;
输出格式
输出一个整数,表示最大价值。
数据范围
0
3 5
2
1 2
2 4
1
3 4
1
4 5
输出样例:
8
AcWing 898. 数字三角形
给定一个如下图所示的数字三角形,从顶部出发,在每一结点可以选择移动至其左下方的结点或移动至其右下方的结点,一直走到底层,要求找出一条路径,使路径上的数字的和最大。
7
3 8
8 1 0
2 7 4 4
4 5 2 6 5
输入格式
第一行包含整数 n,表示数字三角形的层数。
接下来 n 行,每行包含若干整数,其中第 i 行表示数字三角形第 i 层包含的整数。
输出格式
输出一个整数,表示最大的路径数字和。
数据范围
1≤n≤500,
−10000≤三角形中的整数≤10000
输入样例:
5
7
3 8
8 1 0
2 7 4 4
4 5 2 6 5
输出样例:
30
AcWing 895. 最长上升子序列
给定一个长度为 N 的数列,求数值严格单调递增的子序列的长度最长是多少。
输入格式
第一行包含整数 N。
第二行包含 N 个整数,表示完整序列。
输出格式
输出一个整数,表示最大长度。
数据范围
1≤N≤1000,
−109≤数列中的数≤ 1 0 9 10^9 109
输入样例:
7
3 1 2 1 8 5 6
输出样例:
4
AcWing 896. 最长上升子序列 II
给定一个长度为 N 的数列,求数值严格单调递增的子序列的长度最长是多少。
输入格式
第一行包含整数 N。
第二行包含 N 个整数,表示完整序列。
输出格式
输出一个整数,表示最大长度。
数据范围
1≤N≤100000,
−109≤数列中的数≤ 1 0 9 10^9 109
输入样例:
7
3 1 2 1 8 5 6
输出样例:
4
AcWing 897. 最长公共子序列
给定两个长度分别为 N 和 M 的字符串 A 和 B,求既是 A 的子序列又是 B 的子序列的字符串长度最长是多少。
输入格式
第一行包含两个整数 N 和 M。
第二行包含一个长度为 N 的字符串,表示字符串 A。
第三行包含一个长度为 M 的字符串,表示字符串 B。
字符串均由小写字母构成。
输出格式
输出一个整数,表示最大长度。
数据范围
1≤N,M≤1000
输入样例:
4 5
acbd
abedc
输出样例:
3
AcWing 902. 最短编辑距离
给定两个字符串 A 和 B,现在要将 A 经过若干操作变为 B,可进行的操作有:
删除–将字符串 A 中的某个字符删除。
插入–在字符串 A 的某个位置插入某个字符。
替换–将字符串 A 中的某个字符替换为另一个字符。
现在请你求出,将 A 变为 B 至少需要进行多少次操作。
输入格式
第一行包含整数 n,表示字符串 A 的长度。
第二行包含一个长度为 n 的字符串 A。
第三行包含整数 m,表示字符串 B 的长度。
第四行包含一个长度为 m 的字符串 B。
字符串中均只包含大小写字母。
输出格式
输出一个整数,表示最少操作次数。
数据范围
1≤n,m≤1000
输入样例:
10
AGTCTGACGC
11
AGTAAGTAGGC
输出样例:
4
AcWing 899. 编辑距离
给定 n 个长度不超过 10 的字符串以及 m 次询问,每次询问给出一个字符串和一个操作次数上限。
对于每次询问,请你求出给定的 n 个字符串中有多少个字符串可以在上限操作次数内经过操作变成询问给出的字符串。
每个对字符串进行的单个字符的插入、删除或替换算作一次操作。
输入格式
第一行包含两个整数 n 和 m。
接下来 n 行,每行包含一个字符串,表示给定的字符串。
再接下来 m 行,每行包含一个字符串和一个整数,表示一次询问。
字符串中只包含小写字母,且长度均不超过 10。
输出格式
输出共 m 行,每行输出一个整数作为结果,表示一次询问中满足条件的字符串个数。
数据范围
1≤n,m≤1000,
输入样例:
3 2
abc
acd
bcd
ab 1
acbd 2
输出样例:
1
3
AcWing 282. 石子合并
设有 N 堆石子排成一排,其编号为 1,2,3,…,N。
每堆石子有一定的质量,可以用一个整数来描述,现在要将这 N 堆石子合并成为一堆。
每次只能合并相邻的两堆,合并的代价为这两堆石子的质量之和,合并后与这两堆石子相邻的石子将和新堆相邻,合并时由于选择的顺序不同,合并的总代价也不相同。
例如有 4 堆石子分别为 1 3 5 2, 我们可以先合并 1、2 堆,代价为 4,得到 4 5 2, 又合并 1,2 堆,代价为 9,得到 9 2 ,再合并得到 11,总代价为 4+9+11=24;
如果第二步是先合并 2,3 堆,则代价为 7,得到 4 7,最后一次合并代价为 11,总代价为 4+7+11=22。
问题是:找出一种合理的方法,使总的代价最小,输出最小代价。
输入格式
第一行一个数 N 表示石子的堆数 N。
第二行 N 个数,表示每堆石子的质量(均不超过 1000)。
输出格式
输出一个整数,表示最小代价。
数据范围
1≤N≤300
输入样例:
4
1 3 5 2
输出样例:
22
AcWing 900. 整数划分
一个正整数 n 可以表示成若干个正整数之和,形如: n = n 1 + n 2 + … + n k n=n_1+n_2+…+n_k n=n1+n2+…+nk,其中 n 1 ≥ n 2 ≥ … ≥ n k , k ≥ 1 n_1≥n_2≥…≥n_k,~k≥1 n1≥n2≥…≥nk, k≥1。
我们将这样的一种表示称为正整数 n 的一种划分。
现在给定一个正整数 n,请你求出 n 共有多少种不同的划分方法。
输入格式
共一行,包含一个整数 n。
输出格式
共一行,包含一个整数,表示总划分数量。
由于答案可能很大,输出结果请对 1 0 9 + 7 10^9+7 109+7 取模。
数据范围
1≤n≤1000
输入样例:
5
输出样例:
7
AcWing 338. 计数问题
给定两个整数 a 和 b,求 a 和 b 之间的所有数字中 0∼9 的出现次数。
例如,a=1024,b=1032,则 a 和 b 之间共有 9 个数如下:
1024 1025 1026 1027 1028 1029 1030 1031 1032
其中 0 出现 10 次,1 出现 10 次,2 出现 7 次,3 出现 3 次等等…
输入格式
输入包含多组测试数据。
每组测试数据占一行,包含两个整数 a 和 b。
当读入一行为 0 0 时,表示输入终止,且该行不作处理。
输出格式
每组数据输出一个结果,每个结果占一行。
每个结果包含十个用空格隔开的数字,第一个数字表示 0 出现的次数,第二个数字表示 1 出现的次数,以此类推。
数据范围
0
1 10
44 497
346 542
1199 1748
1496 1403
1004 503
1714 190
1317 854
1976 494
1001 1960
0 0
输出样例:
1 2 1 1 1 1 1 1 1 1
85 185 185 185 190 96 96 96 95 93
40 40 40 93 136 82 40 40 40 40
115 666 215 215 214 205 205 154 105 106
16 113 19 20 114 20 20 19 19 16
107 105 100 101 101 197 200 200 200 200
413 1133 503 503 503 502 502 417 402 412
196 512 186 104 87 93 97 97 142 196
398 1375 398 398 405 499 499 495 488 471
294 1256 296 296 296 296 287 286 286 247
AcWing 291. 蒙德里安的梦想
求把 N×M 的棋盘分割成若干个 1×2 的长方形,有多少种方案。
例如当 N=2,M=4 时,共有 5 种方案。当 N=2,M=3 时,共有 3 种方案。
如下图所示:
![]()
输入格式
输入包含多组测试用例。
每组测试用例占一行,包含两个整数 N 和 M。
当输入用例 N=0,M=0 时,表示输入终止,且该用例无需处理。
输出格式
每个测试用例输出一个结果,每个结果占一行。
数据范围
1≤N,M≤11
输入样例:
1 2
1 3
1 4
2 2
2 3
2 4
2 11
4 11
0 0
输出样例:
1
0
1
2
3
5
144
51205
AcWing 91. 最短Hamilton路径
给定一张 n 个点的带权无向图,点从 0∼n−1 标号,求起点 0 到终点 n−1 的最短 Hamilton 路径。
Hamilton 路径的定义是从 0 到 n−1 不重不漏地经过每个点恰好一次。
输入格式
第一行输入整数 n。
接下来 n 行每行 n 个整数,其中第 i 行第 j 个整数表示点 i 到 j 的距离(记为 a[i,j])。
对于任意的 x,y,z,数据保证 a[x,x]=0,a[x,y]=a[y,x] 并且 a[x,y]+a[y,z]≥a[x,z]。
输出格式
输出一个整数,表示最短 Hamilton 路径的长度。
数据范围
1≤n≤20
0≤a[i,j]≤ 1 0 7 10^7 107
输入样例:
5
0 2 4 5 1
2 0 6 5 3
4 6 0 8 3
5 5 8 0 5
1 3 3 5 0
输出样例:
18
AcWing 285. 没有上司的舞会
给定一张 n 个点的带权无向图,点从 0∼n−1 标号,求起点 0 到终点 n−1 的最短 Hamilton 路径。
Hamilton 路径的定义是从 0 到 n−1 不重不漏地经过每个点恰好一次。
输入格式
第一行输入整数 n。
接下来 n 行每行 n 个整数,其中第 i 行第 j 个整数表示点 i 到 j 的距离(记为 a[i,j])。
对于任意的 x,y,z,数据保证 a[x,x]=0,a[x,y]=a[y,x] 并且 a[x,y]+a[y,z]≥a[x,z]。
输出格式
输出一个整数,表示最短 Hamilton 路径的长度。
数据范围
1≤n≤20
0≤a[i,j]≤ 1 0 7 10^7 107
输入样例:
5
0 2 4 5 1
2 0 6 5 3
4 6 0 8 3
5 5 8 0 5
1 3 3 5 0
输出样例:
18
AcWing 901. 滑雪
给定一张 n 个点的带权无向图,点从 0∼n−1 标号,求起点 0 到终点 n−1 的最短 Hamilton 路径。
Hamilton 路径的定义是从 0 到 n−1 不重不漏地经过每个点恰好一次。
输入格式
第一行输入整数 n。
接下来 n 行每行 n 个整数,其中第 i 行第 j 个整数表示点 i 到 j 的距离(记为 a[i,j])。
对于任意的 x,y,z,数据保证 a[x,x]=0,a[x,y]=a[y,x] 并且 a[x,y]+a[y,z]≥a[x,z]。
输出格式
输出一个整数,表示最短 Hamilton 路径的长度。
数据范围
1≤n≤20
0≤a[i,j]≤ 1 0 7 10^7 107
输入样例:
5
0 2 4 5 1
2 0 6 5 3
4 6 0 8 3
5 5 8 0 5
1 3 3 5 0
输出样例:
18
贪心
AcWing 905. 区间选点
给定 N 个闭区间 [ai,bi],请你在数轴上选择尽量少的点,使得每个区间内至少包含一个选出的点。
输出选择的点的最小数量。
位于区间端点上的点也算作区间内。
输入格式
第一行包含整数 N,表示区间数。
接下来 N 行,每行包含两个整数 ai,bi,表示一个区间的两个端点。
输出格式
输出一个整数,表示所需的点的最小数量。
数据范围
1≤N≤ 1 0 5 10^5 105,
−109≤ai≤bi≤ 1 0 9 10^9 109
输入样例:
3
-1 1
2 4
3 5
输出样例:
2
AcWing 908. 最大不相交区间数量
给定 N 个闭区间 [ai,bi],请你在数轴上选择若干区间,使得选中的区间之间互不相交(包括端点)。
输出可选取区间的最大数量。
输入格式
第一行包含整数 N,表示区间数。
接下来 N 行,每行包含两个整数 ai,bi,表示一个区间的两个端点。
输出格式
输出一个整数,表示可选取区间的最大数量。
数据范围
1≤N≤ 1 0 5 10^5 105,
− 1 0 9 10^9 109≤ai≤bi≤ 1 0 9 10^9 109
输入样例:
3
-1 1
2 4
3 5
输出样例:
2
AcWing 906. 区间分组
给定 N 个闭区间 [ai,bi],请你将这些区间分成若干组,使得每组内部的区间两两之间(包括端点)没有交集,并使得组数尽可能小。
输出最小组数。
输入格式
第一行包含整数 N,表示区间数。
接下来 N 行,每行包含两个整数 ai,bi,表示一个区间的两个端点。
输出格式
输出一个整数,表示最小组数。
数据范围
1≤N≤ 1 0 5 10^5 105,
− 1 0 9 10^9 109≤ai≤bi≤ 1 0 9 10^9 109
输入样例:
3
-1 1
2 4
3 5
输出样例:
2
AcWing 907. 区间覆盖
给定 N 个闭区间 [ai,bi] 以及一个线段区间 [s,t],请你选择尽量少的区间,将指定线段区间完全覆盖。
输出最少区间数,如果无法完全覆盖则输出 −1。
输入格式
第一行包含两个整数 s 和 t,表示给定线段区间的两个端点。
第二行包含整数 N,表示给定区间数。
接下来 N 行,每行包含两个整数 ai,bi,表示一个区间的两个端点。
输出格式
输出一个整数,表示所需最少区间数。
如果无解,则输出 −1。
数据范围
1≤N≤ 1 0 5 10^5 105,
− 1 0 9 10^9 109≤ai≤bi≤ 1 0 9 10^9 109,
− 1 0 9 10^9 109≤s≤t≤ 1 0 9 10^9 109
输入样例:
1 5
3
-1 3
2 4
3 5
输出样例:
2
AcWing 148. 合并果子
在一个果园里,达达已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。
达达决定把所有的果子合成一堆。
每一次合并,达达可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。
可以看出,所有的果子经过 n−1 次合并之后,就只剩下一堆了。
达达在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以达达在合并果子时要尽可能地节省体力。
假定每个果子重量都为 1,并且已知果子的种类数和每种果子的数目,你的任务是设计出合并的次序方案,使达达耗费的体力最少,并输出这个最小的体力耗费值。
例如有 3 种果子,数目依次为 1,2,9。
可以先将 1、2 堆合并,新堆数目为 3,耗费体力为 3。
接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 12,耗费体力为 12。
所以达达总共耗费体力=3+12=15。
可以证明 15 为最小的体力耗费值。
输入格式
输入包括两行,第一行是一个整数 n,表示果子的种类数。
第二行包含 n 个整数,用空格分隔,第 i 个整数 ai 是第 i 种果子的数目。
输出格式
输出包括一行,这一行只包含一个整数,也就是最小的体力耗费值。
输入数据保证这个值小于 231。
数据范围
1≤n≤10000,
1≤ai≤20000
输入样例:
3
1 2 9
输出样例:
15
AcWing 913. 排队打水
有 n 个人排队到 1 个水龙头处打水,第 i 个人装满水桶所需的时间是 ti,请问如何安排他们的打水顺序才能使所有人的等待时间之和最小?
输入格式
第一行包含整数 n。
第二行包含 n 个整数,其中第 i 个整数表示第 i 个人装满水桶所花费的时间 ti。
输出格式
输出一个整数,表示最小的等待时间之和。
数据范围
1≤n≤ 1 0 5 10^5 105,
1≤ti≤ 1 0 4 10^4 104
输入样例:
7
3 6 1 4 2 5 7
输出样例:
56
AcWing 104. 货仓选址
在一条数轴上有 N 家商店,它们的坐标分别为 A1∼AN。
现在需要在数轴上建立一家货仓,每天清晨,从货仓到每家商店都要运送一车商品。
为了提高效率,求把货仓建在何处,可以使得货仓到每家商店的距离之和最小。
输入格式
第一行输入整数 N。
第二行 N 个整数 A1∼AN。
输出格式
输出一个整数,表示距离之和的最小值。
数据范围
1≤N≤100000,
0≤Ai≤40000
输入样例:
4
6 2 9 1
输出样例:
12
AcWing 125. 耍杂技的牛
农民约翰的 N 头奶牛(编号为 1…N)计划逃跑并加入马戏团,为此它们决定练习表演杂技。
奶牛们不是非常有创意,只提出了一个杂技表演:
叠罗汉,表演时,奶牛们站在彼此的身上,形成一个高高的垂直堆叠。
奶牛们正在试图找到自己在这个堆叠中应该所处的位置顺序。
这 N 头奶牛中的每一头都有着自己的重量 Wi 以及自己的强壮程度 Si。
一头牛支撑不住的可能性取决于它头上所有牛的总重量(不包括它自己)减去它的身体强壮程度的值,现在称该数值为风险值,风险值越大,这只牛撑不住的可能性越高。
您的任务是确定奶牛的排序,使得所有奶牛的风险值中的最大值尽可能的小。
输入格式
第一行输入整数 N,表示奶牛数量。
接下来 N 行,每行输入两个整数,表示牛的重量和强壮程度,第 i 行表示第 i 头牛的重量 Wi 以及它的强壮程度 Si。
输出格式
输出一个整数,表示最大风险值的最小可能值。
数据范围
1≤N≤50000,
1≤Wi≤10,000,
1≤Si≤1,000,000,000
输入样例:
3
10 3
2 5
3 3
输出样例:
2
时空复杂度分析
一般ACM或者笔试题的时间限制是1秒或2秒。
在这种情况下,C++代码中的操作次数控制在 1 0 7 ∼ 1 0 8 10^7∼10^8 107∼108 为最佳。
下面给出在不同数据范围下,代码的时间复杂度和算法该如何选择:
1. n ≤ 30 n≤30 n≤30, 指数级别, dfs+剪枝,状态压缩dp
2. n ≤ 100 n≤100 n≤100 => O ( n 3 ) O(n^3) O(n3),floyd,dp,高斯消元
3. n ≤ 1000 n≤1000 n≤1000 => O ( n 2 ) , O ( n 2 l o g n ) O(n2),O(n^2logn) O(n2),O(n2logn),dp,二分,朴素版Dijkstra、朴素版Prim、Bellman-Ford
4. n ≤ 10000 n≤10000 n≤10000 => O ( n ∗ n ) O(n∗\sqrt n) O(n∗n),块状链表、分块、莫队
5. n ≤ 100000 n≤100000 n≤100000 => O ( n l o g n ) O(nlogn) O(nlogn) => 各种sort,线段树、树状数组、set/map、heap、拓扑排序、dijkstra+heap、prim+heap、Kruskal、spfa、求凸包、求半平面交、二分、CDQ分治、整体二分、后缀数组、树链剖分、动态树
6. n ≤ 1000000 n≤1000000 n≤1000000 => O ( n ) O(n) O(n), 以及常数较小的 O ( n l o g n ) O(nlogn) O(nlogn)算法 => 单调队列、 hash、双指针扫描、并查集,kmp、AC自动机,常数比较小的 O ( n l o g n ) O(nlogn) O(nlogn) 的做法:sort、树状数组、heap、dijkstra、spfa
7. n ≤ 1 0 7 n≤10^7 n≤107 => O ( n ) O(n) O(n),双指针扫描、kmp、AC自动机、线性筛素数
8. n ≤ 1 0 9 = > O ( n ) n≤10^9 => O(\sqrt n) n≤109=>O(n),判断质数
9. n ≤ 1 0 18 n≤10^{18} n≤1018 => O ( l o g n ) O(logn) O(logn),最大公约数,快速幂,数位DP
10. n ≤ 101000 n≤101000 n≤101000 => O ( ( l o g n ) 2 ) O((logn)^2) O((logn)2),高精度加减乘除
11. n ≤ 10100000 n≤10100000 n≤10100000 => O ( l o g k × l o g l o g k ) O(logk×loglogk) O(logk×loglogk),k表示位数,高精度加减、FFT/NTT