darknet 框架中.cfg文件的参数详解,以yolov3为例
参考:darknet中cfg文件里参数的理解_zerojava0的博客-CSDN博客
参考:【Darknet源码 】cfg文件参数详解_橘子都吃不起!的博客-CSDN博客
1.基础参数解释
batch=64 #网络积累多少样本进行一次BP,训练模型一般选择大于32 的2的n次方 检测时,batch=1;
subdivisions=4 #表示将一个batch的图分为4次完成网络的前向传播。可更改,在darknet中,batch和subdivisions是结合使用的,这里参数意思是,训练过程中将一次性加载64张图片进内存,然后分4次完成前向传播,意思是每次16张,前向传播的循环过程中累加loss求平均,待64张图片都完成前向传播后,再一次性后传更新参数。检测时,subdivisions=1;
width=416
height=416 #输入图片的宽和高,必须为32的倍数,否则网络不能加载
channels=3 #网络输入通道数为3
momentum=0.9 #动量DeepLearning1中最优化方法中的动量参数,这个值影响着梯度下降到最优值的速度
decay=0.0005 #权重衰减正则项
angle=0 #数据增强参数,通过旋转角度来生成更多训练样本
saturation=1.5#数据增强参数,通过调整饱和度来生成更多训练样本
exposure=1.5 #数据增强参数,通过调整曝光量来生成更多训练样本
hue=.1 #数据增强参数,通过调整色调来生成更多训练样本
aspect #通过方向来生成更多训练样本,默认为1
learning_rate=0.001 # 学习率决定着权值更新的速度,设置得太大会使结果超过最优值,太小会使下降速度过慢。
#刚开始训练时:学习率以0.01~0.001为宜。一定轮数过后:逐渐减缓
#接近训练结束:学习率的衰减应该在100倍以上。
#如果loss波动太大,说明学习率过大,适当减小,变为1/5,1/10均可;如果loss几乎不变,可能网络已经收敛或者陷入了局部极小,此时可以适当增大学习率,注意每次调整学习率后一定要训练久一点,充分观察。
#实际学习率与GPU的个数有关,例如你的学习率设置为0.001,如果你有4块GPU,那真实学习率为0.0014。
max_batches=500200 #训练次数达到max_batches后停止学习
policy=steps #学习率调整的策略:constant,steps,exp,poly,step,sig,RANDOM,constant等方式
steps=400000,450000
scales=.1,.1 #steps和scale是设置学习率的变化,比如迭代400000次时,学习率衰减十倍,450000次迭代时,学习率又会在前一个学习率的基础上衰减十倍
#学习率相关参数
learning_rate #基础学习率,默认为0.001
momentum #梯度下降动量,默认为0.9
decay #权重衰减正则项,防止过拟合,默认为0.0001
time_steps #时间步数,RNN/LSTM模型中参数
notruth #不清楚,没用到
random # 是否开启多尺度训练,开启后对GPU要求较高
adam #是否使用adma,默认为 0
B1 # adam 参数
B2 # adam 参数
eps # adam 参数
policy #学习率衰减策略,默认constant,
#有:random,poly,constant,step,exp,sigmoid,steps
burn_in #设置了这个参数,当update_num小于burn_in时,不是使用配置的学习速率更新策略,
#而是按照公式lr = base_lr * power(batch_num/burn_in,pwr) 更新,其背后的假设
#是:全局最优点就在网络初始位置附近,所以训练开始后的burn_in次更新,学习速率从
#小到大变化。update次数超过burn_in后,采用配置的学习速率更新策略从大到小变化,
#显然finetune时可以尝试。默认为0
power #学习率衰减公式中,幂次方参数,默认为4
step #采用step或sigmoid学习率衰减策略时的参数,默认为1
scale #采用step和steps学习率衰减策略时的参数,默认为1
steps #采用steps策略时参数,多个参数之间使用,分开,例如 10000,1000000等
scales #采用steps策略时参数,多个参数之间使用,与steps保持一致
gamma #采用exp,sigmoid时启用参数,默认为1
max_batches #最大批数量,默认为0

2.#一层卷积层的配置说明

[convolutional]
batch_normalize=1 #是否进行BN处理,1:是,0:不是
filters=16 #卷积核个数,也是输出通道数
size=3 #卷积核尺寸
stride=1 #卷积步长
pad=1 #当pad=1的时候,padding = (kernel-1) // 2;当pad=0的时候,padding就是依据给出的padding值。在yolov3的cfg文件中,pad都是为1的情况。
activation=leaky //网络激活函数
//卷积核尺寸3*3配合padding且步长为1时,不改变feature map的大小
3.#Downsample
[convolutional] #下采样层的配置说明
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky #卷积核尺寸为3*3,配合padding且步长为2时,feature map变为原来的一半大小
4.[shortcut] #shortcut层配置说明 shortcut 融合做加法,要求两个层的输入特征维度一致,相当于做了加法
from=3 /#与前面的多少次进行融合,-3表示前面第三层
activation=linear #层次激活函数
5.[convolutional] #YOLO层前面一层卷积层配置说明

size=1
stride=1
pad=1
filters=255 #filters=num(预测框个数)*(classes+5),5的意义是4个坐标加一个置信度,classes为类别数,coco为80,num表示YOLO中每个cell预测的框的个数,YOLOV3中为3,自己使用时,此处的值一定要根据自己的数据集进行更改,例如你识别4个类, #则 :filters=3(4+5)=27,三个filters都需要修改,切记
activation=linear
6.[yolo] #YOLO层配置说明

mask=0,1,2 //使用anchor的索引,0,1,2表示使用下面定义的anchors中的前三个anchor
anchors=10,14, 23,27 37,58, 81,82, 135,169 , 344,319
classes=80 #类别说明
num=6 #每个grid cell总共预测几个box,和anchors的数量一致。当想要使用更多anchors时需要调大num
jitter=.3 #数据增强手段,此处jitter为随机调整宽高比的范围
ignore_thresh=.7
truth_thresh=1 #参与计算的IOU阈值大小。当预测的检测框与ground true的IOU大于ignore_thresh的时候,参与loss的计算,否则,检测框的不参与损失计算。目的是控制参与loss计算的检测框的规模,当ignore_thresh过于大,接近1的时候,那么参与检测框回归loss的个数就会比较少,同时也容易造成过拟合;而如果ignore_thresh设置的过于小,那么参与计算的数量规模就会很大。同时也容易在进行检测框回归的时候造成欠拟合。
参数设置:一般选取0.5~0.7之间的一个值,之前的计算基础都是小尺度(13*13)用的是0.7(26*26)用的是0.5.
random=1 #为1打开随机多尺度训练,为0则关闭,当打开随机多尺度训练时,前面设置的网络尺寸width和height其实就不起作用了,width会在320到608之间随机取值,每10轮随机改变一次,一般建议可以根据自己需要修改随机尺寸训练的范围,这样可以增大batch。
7.route #route层配置说明

layers=-4 #从上一个网络开始倒数到第4个,复制这一层,作为该层的下一个分支,比如route上一个模型时yolo,操作结果如下所示
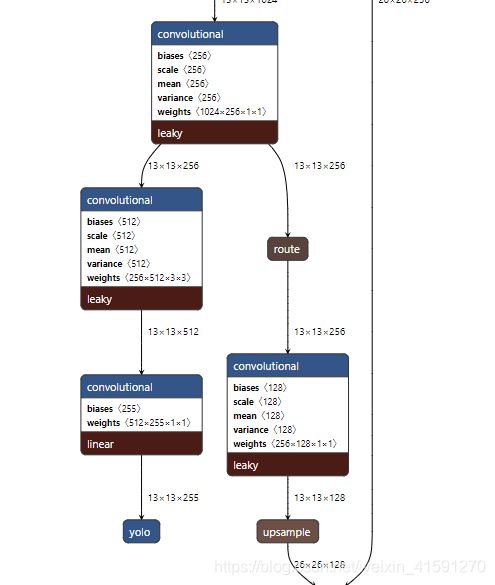

layers=-1,8 #将第8层(从第0层卷积开始数)和route 的上一层融合(二者), 两层channels可以不一致。
[route] # 用来合并前面若干层的输出,作为一个新层,其本质上就是一个复制操作
layer # 将多个层输出拼接在一起,如果为负数,则表示该层的前几层
# 例如输入层1:26*26*256 输入层2:26*26*128 则route layer输出为:26*26*(256+128)
8. max_crop #输入图的最小边需要在[min_crop,max_crop]区间内,如果输入和这个不符合,则通过缩
#放使之符合。默认为 2*输入宽度w
min_crop #默认为 输入宽度w
max_ratio #与max_crop/min_crop类似, 默认为max_crop / w
min_ratio #默认为 min_crop / w
center #暂不清楚,默认为 0
clip #可能和图片裁剪有关,默认为 0
[conv]/[convolutional] #该部分为卷积层参数,在parse_convolutional()中解析
filters #卷积核个数,默认为1
size #获取卷积核尺寸,默认为1
stride #卷积跨度,默认为1
pad #是否在输入图像四周补0,若需要补0,值为1,默认为0
padding #四周补0的长度,默认为size/2,向下取整
groups #分组卷积(深度卷积),组数,默认为1
activation #激活函数,默认为logistic,其他还有: logistic,loggy,relu,elu,selu,relie,
#plse,hardtan,lhtan,linear,ramp,leaky,tanh,stair
batch_normalize #是否进行规范化,1表示进行规范化,默认为0
binary #是否对权重进行二值化,1表示进行二值化,默认为0
xnor #是否对权重以及输入进行二值化,1表示是,默认为0
flipped #是否翻转,默认为0
dot #暂不清楚,默认为0,此变量已无使用
[shortcut] #捷径层,与卷积层一起构建残差模块,parse_shortcut()中解析
from #表示当前层与前面的多少层进行叠加,-3表示前面第三层。没有默认参数,必须制定
activation #激活函数,一般为 leaky,ReLU,默认为linear
alpha #叠加权重,默认为1
beta #叠加权重,默认为1
#注意[shortcut]层与[convolutional]层可以组成残差模块
# Residual Block
# [convolutional]
# batch_normalize=1
# filters=64
# size=3
# stride=1
# pad=1
# activation=leaky
#
# [convolutional]
# batch_normalize=1
# filters=64
# size=3
# stride=1
# pad=1
# activation=linear
#
# [shortcut]
# activation=leaky
# from=-3
#
[avg]/[avgpool] #均值池化层,一般接在最后softmax层前,替代全连接层,减少计算量
#相关参数根据上一层输出自动生成,在parse_avgpool()中解析
[softmax] #池化层,网络最后输出预测的概率分布,在parse_softmax()中解析
groups #分组数,softmax计算量较大,分为多组计算,默认为1
temperature #softmax的温度参数,当temperature很大时,即趋于正无穷时,所有的激活值对应的激
#活概率趋近于相同(激活概率差异性较小);而当temperature很低时,即趋于0时,不同
#的激活值对应的激活概率差异也就越大。默认为1
tree #softmax计算量较大,按照树结构计算??,默认为0
spatial #与GPU计算相关,分组计算默认为0
noloss #是否不计算损失(交叉熵),默认计算,默认为0
[cost] #代价层函数,在目标探测中计算预测值与真实值得总体损失,在parse_cost()中解析
type #代价函数类型,默认了为sse,其他有:seg,sse,masked,smooth,L1,wgan
scale #缩放尺度,默认为1
ratio #暂不清楚,与GPU计算有关,默认为0
noobj #noobject_scale,暂不清楚,与GPU计算有关,默认为1
thresh #iou阈值,当best_iou大于阈值时,损失系数置0,默认为0
*****************************************************************/
什么时候停止训练:当loss不在下降或者下降极慢的情况可以停止训练,一般loss=0.7左右就可以了。
在训练集上测试正确率很高,在其他测试集上测试效果很差,说明过拟合了:提前停止训练,或者增大样本数量训练。
如何提高目标检测正确率包括IOU,分类正确率:1.设置yolo层random=1,增加不同的分辨率。2.或者增大图片本身分辨率。3.或者根据你自身定义的数据集去重新计算anchor尺寸。
如何增加训练样本:样本特点尽量多样化,亮度,旋转,背景,目标位置,尺寸,添加没有标注框的图片和其空的txt文件,作为negative数据。
训练的图片较小,但是实际检测图片大,怎么检测小目标:使用416*416训练完之后,也可以在cfg文件中设置较大的width和height,增加网络对图像的分辨率,从而更可能检测出图像中的小目标,而不需要重新训练;或者:set ‘[route] layers = -1,11’
set ‘[upsample] stride = 4’
多GPU怎么训练:
1.首先用一个gpu训练1000次迭代后的网络;
2.再用多gpu训练; 命令:
darknet.exe detector train data/voc.data cfg/yolov3-voc.cfg /backup/yolov3-voc_1000.weights-gpus 0,1,2,3
有哪些命令行来对神经网络进行训练和测试:
1.检测图片: build\darknet\x64\darknet.exe detector test data/coco.data cfg/yolov3.cfg yolov3.weights -thresh 0.25 xxx.jpg
2.检测视频:将test 改为 demo ; xxx.jpg 改为xxx.mp4
3.调用网络摄像头:将xxx.mp4 改为 http://192.168.0.80:8080/video?dummy=x.mjpg -i 0
4.批量检测:-dont_show -ext_output < data/train.txt > result.txt
5.手持端网络摄像头:下载mjpeg-stream 软件, xxx.jpg 改为 IP Webcam / Smart WebCam
如何评价模型好坏:
build\darknet\x64\darknet.exe detector map data\defect.data cfg\yolov3.cfg backup\yolov3.weights
利用上面命令计算各权重文件,选择具有最高IoU(联合的交集)和mAP(平均精度)的权重文件