【笔记】YOLOv3+darknet实现目标识别
目录
- 一、安装OPENCV3.4
-
- 1、安装配置相关工具及依赖库
- 2、从官网下载源码
- 3、安装过程
-
- (1)将zip文件解压到当前目录
- (2)进入解压后的文件夹
- (3)创建一个编译需要的临时文件夹build,并进入
- (4)cmake一下
- (5)进行make编译,需要很久,静静等待
- (6)进行make install安装
- 二、编译darknet
-
- 1、首先要安装Darknet,拷贝他们的github:
- 2、修改Makefile
- 3、修改.weights文件保存时机
- 4、然后进入` darknet/`文件夹进行编译:
- 5、下载在ImageNet预训练过的网络参数weight,选择YOLOv3-tiny版本的:
- 6、测试`darknet`,用`data/`文件夹里的测试图进行测试:
- 三、创建自定义数据集
-
- 1、获取训练集样本
- 2、利用LabelImg标记训练样本,获得每张图片对应的.txt文件
-
- (1)添加自己的类
- (2)打开工具,标记生成对应文件
- 3、汇总.txt文件
- 四、训练YOLOv3-tiny模型
-
- 1、获取训练所必须的文件
-
- (1)`yolov3-tiny.conv.15`
- (2)`yolov3-tiny-bot.cfg`
- (3)`bot.data`
- (4)`bot.names`
- 2、开始训练
- 3、输出日记解释
- 五、结果测试
- 后记
-
- 1、断点继续训练
- 2、Nan
- 3、训练日志可视化
- 4、YOLOV3无法加载图片"cannot load image"
- 参考资料
本文中的YOLOv3是在Linux下进行测试的,如不需要OPENCV,可以不安装,Makefile中的对应选项也不用更改
一、安装OPENCV3.4
目前darknet c框架只支持opencv2.x和3.x。如果想要运行在opencv4.x上,需要首先修改Makefile来显性指定opencv版本为4.x,具体办法请自行百度,这里我们直接用OPENCV3.4.7
1、安装配置相关工具及依赖库
sudo apt-get install build-essential #必须的,gcc编译环境
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev #必须的,包括cmake等工具
sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
#可选的,看个人需要,总共5M左右
如出现无法定位软件包:libjasper-dev,在代码中把这个删掉再执行
2、从官网下载源码
官网地址:https://opencv.org/releases.html
3、安装过程
这是官方的安装教程,但是执行的时候有些地方需要更改
(1)将zip文件解压到当前目录
unzip opencv-3.4.7.zip -d .
(2)进入解压后的文件夹
cd opencv-3.4.7
(3)创建一个编译需要的临时文件夹build,并进入
mkdir build
cd build/
(4)cmake一下
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr ..
这里cmake命令执行会下载ippicv,需要等待比较长时间才能下载完成
(5)进行make编译,需要很久,静静等待
make -j7 # runs 7 jobs in parallel
(6)进行make install安装
sudo make install
安装完成后,可以用
whereis opencv
查看opencv的安装路径,如果没安装错的话,应该会返回
opencv:/usr/include/opencv
二、编译darknet
1、首先要安装Darknet,拷贝他们的github:
git clone https://github.com/pjreddie/darknet
2、修改Makefile
将OPENCV=0,OPENMP=0的值都改为1

OpenMP是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受,用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案(Compiler Directive),把OPENMP的值改为1,实测训练速度会快一些,如不需要,可以不作更改,但每次更改,都需要重新Make一下darknet
3、修改.weights文件保存时机
原版的.weights文件是当训练次数小于1000时,每隔100次保存一次,大于1000是每10000次保存一次,这对于检测类别数较少或者数据集太少的情况是很难受的,那么可以修改源代码,使得每隔1000次保存一次。
打开darknet/example/detector.c
把第138行的if(i%10000== 0 || (i < 1000 && i%100 == 0))修改为if(i%1000==0),就是每隔1000次迭代保存一次.weights文件了

4、然后进入darknet/文件夹进行编译:
cd darknet
make
5、下载在ImageNet预训练过的网络参数weight,选择YOLOv3-tiny版本的:
wget https://pjreddie.com/media/files/yolov3-tiny.weights
6、测试darknet,用data/文件夹里的测试图进行测试:
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg

三、创建自定义数据集
基本上所有的机器学习方法的首要前提是需要提供数据集来训练我们的神经网络,要么是已经采集好而且开源的数据集(如手写数字MINST集、ImagNet数据集、COCO数据集等等…),要么就需要自己采集数据创建一个自己的训练集。
使用图片标记工具labelImg可以帮助我们快速制作自己的数据集
1、获取训练集样本
在darknet/文件夹下创建bot文件夹,再创建一个用来存放数据集(图片)的文件夹
我这里训练集只有一个类,共162张图片
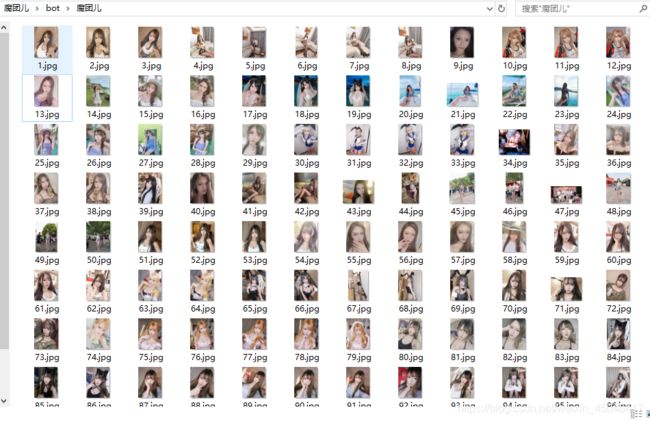
2、利用LabelImg标记训练样本,获得每张图片对应的.txt文件
(1)添加自己的类
打开labelImg-master\data\predefined_classes.txt

修改为futuaner

(2)打开工具,标记生成对应文件


直接按快捷键W,标记目标区域

点击futuaner,然后点OK

修改保存格式,我们需要的是YOLO的格式
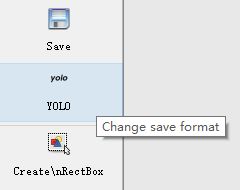
然后点保存

会生成一个与图片名字相同的txt文件
YOLO的格式:
[category number] [object center in X] [object center in Y] [object width in X] [object width in Y]

之后按快捷键D到下一张,同样的操作

3、汇总.txt文件
每一张标记号的训练图片都会对应相同名字的.txt文件作为目标的label单独保存,所以我们还需要一个train.txt和test.txt来汇总这些单独的文件以便读取。我们可以直接用python来帮助我们生成这两个汇总文件,代码如下(参照了这里):
import glob, os
# Current directory
current_dir = r'C:\Users\liuruimin\Desktop\腐团儿\bot\腐团儿'##这里改为训练集的绝对路径
# Directory where the data will reside, relative to 'darknet.exe'
path_data = '/home/liuruimin/桌面/腐团儿/bot/'
# Percentage of images to be used for the test set
percentage_test = 10;
# Create and/or truncate train.txt and test.txt
file_train = open('train.txt', 'w')
file_test = open('test.txt', 'w')
# Populate train.txt and test.txt
counter = 1
index_test = round(100 / percentage_test)
for pathAndFilename in glob.iglob(os.path.join(current_dir, "*.jpg")):
title, ext = os.path.splitext(os.path.basename(pathAndFilename))
if counter == index_test:
counter = 1
file_test.write(path_data + '腐团儿/' + title + '.jpg' + "\n")
else:
file_train.write(path_data + '腐团儿/' + title + '.jpg' + "\n")
counter = counter + 1
运行完这段代码以后,在当前文件夹会生成train.txt和test.txt两个文件

四、训练YOLOv3-tiny模型
1、获取训练所必须的文件
要在Darknet框架下训练YOLO模型,我们总共需要以下文件:
yolov3-tiny.conv.15
yolov3-tiny-bot.cfg
bot.data
bot.names
train.txt
test.txt
我们统一将这些文件放到命名为bot/的文件夹里。
(1)yolov3-tiny.conv.15
已经预训练过的网络可以使用迁移学习(Transfer Learning)来减少训练时间。简单来说我们只使用前面15层的卷积层来提取图像特征,这15层是不用训练的,我们着重训练后面几层全连接层来让我们自己的数据和对应的标签对接。我们可以用下面的代码来提取原先网络的前15层的参数weight,然后生成一个yolov3-tiny.conv.15文件:
./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15
(2)yolov3-tiny-bot.cfg
我们可以复制cfg/文件夹里原来的yolov3-tiny.cfg文件将其命名为yolov3-tiny-bot.cfg,在这个文件里的以下几行进行改动:
第3行:batch = 1
第4行:subdivision = 1
第127行和第171行:filters = 18
第135行和第177行:classes = 1
我们对应我们的数据设定classes的数量为1,filters的值就为(classes+ 5)*3 = 18
batch,表示网络积累多少个样本后进行一次BP
subdivision,这个参数表示将一个batch的图片分sub次完成网络的前向传播
例如:
batch = 64
subdivision = 16
表示训练的过程中将一次性加载64张图片进内存,然后分16次完成前向传播,意思是每次4张,前向传播的循环过程中累加loss求平均,待64张图片都完成前向传播后,再一次性后传更新参数,即是在训练输出中,用来减轻内存占用的压力;通常情况下batch越大,训练效果越好,subdivision越大,占用内存压力越小
sub一般设置16,不能太大或太小,且为8的倍数,其实也没啥硬性规定,看着舒服就好, batch的值可以根据显存占用情况动态调整,一次性加减sub大小即可,还需注意一点,在测试的时候batch和sub都设置为1,避免发生神秘错误
我这里设置为batch = 1,subdivision = 1,实测训练可行
(3)bot.data
我们可以复制cfg/文件夹里原来的voc.data文件将其命名为bot.data,并做以下修改
classes = 1
train = /home/liuruimin/桌面/腐团儿/bot/train.txt
valid = /home/liuruimin/桌面/腐团儿/bot/test.txt
names = bot/bot.names
backup = backup/
train.txt和test.txt就是前面我们生成的两个汇总文件,而backup就是我们训练过的weight自动保存的路径
(4)bot.names
同样,我们可以复制data/文件夹里原来的voc.names文件将其命名为bot.names,并改为我们自己的class名称,与之前的predefined_classes.txt一样共1类,如果你是多个class,需要与之前的predefined_classes.txt文件中的class一一对应

2、开始训练
所有这些文件都统一放到bot/文件夹以后,就可以开始我们的训练了,输入以下代码:
./darknet detector train bot/bot.data bot/yolov3-tiny-bot.cfg bot/yolov3-tiny.conv.15

如果没有出错的话,训练就自动开始了。一般来讲训练的时间会取决于你的硬件配置以及你数据集的大小,正常的话你需要大概每个class至少有300个数据才可以有一个比较准确的结果。结果会显示在每个batch结束时,一般着重看averge loss也就是avg参数,avg值越小准确率就越高。Darknet不会自动停止训练,当你观察到avg值比较小时(比如0.3),你就可以手动停止训练了。训练时网络的参数weight会自动保存至backup设置的路径
3、输出日记解释
如上图
一个批次有1*2条信息,每组包含2条信息,分别是:
Region 16 Avg IOU:
Region 23 Avg IOU:
其中Region 16 行的参数意义如下:
Avg IOU:当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class: 标注物体的分类准确率,越大越好,期望数值为1;
obj: 越大越好,期望数值为1;
No obj: 越小越好;
.5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
.75R: 以IOU=0.75为阈值时候的recall;
count:正样本数目
注:Region 23 行存在nan值说明该子批次没有预测到正样本,在训练开始时候有出现是正常现象(只要其中一个Region行是有输出的就行)
每个批次最后都会有一个输出行
15006:0.054513,0.090221 avg,0.001000 rate,1.826643 seconds,15006 images
各部分代表意义如下:
第几批次,总损失,平均损失,当前学习率,当前批次训练时间,目前为止参与训练的图片总数
五、结果测试
另外找一张用于检测的图片,保存在darknet/的根目录下,运行以下代码即可进行测试
./darknet detector test bot/bot.data bot/yolov3-tiny-bot.cfg backup/yolov3-tiny-bot_15000.weights tset.jpg

后记
1、断点继续训练
如果想继续训练,就要保证backup下的yolov3-tiny-bot.backup还在
./darknet detector train bot/bot.data bot/yolov3-tiny-bot.cfg backup/yolov3-tiny-bot.backup
2、Nan
训练过程中nan的屏幕占比30%是正常的,如果太大,全是nan,那就是训练过程出了问题。
减少nan
(1)调高darknet/bot/yolov3-tiny-bot.cfg中的batch,注意得是32的整数倍。
(2)增加数据集规模,162张图片的训练集,有点小了,实在不行,就做数据增强,可以把数据集增加到原来的十几倍
3、训练日志可视化
前提是训练过程中保存了训练日志xxx.log
运行下面的脚本,会在同一目录下生成2个txt文件和显示2张图片
./darknet detector train bot/bot.data bot/yolov3-tiny-bot.cfg bot/yolov3-tiny.conv.15 | tee bot/训练可视化/train_yolov3-tiny-bot.log
# -*- coding: utf-8 -*-
# @Time : 2018/12/30 16:26
# @Author : lazerliu
# @File : vis_yolov3_log.py
# @Func :yolov3 训练日志可视化,把该脚本和日志文件放在同一目录下运行。
import pandas as pd
import matplotlib.pyplot as plt
import os
# ==================可能需要修改的地方=====================================#
g_log_path = "train_yolov3-tiny-bot.log" # 此处修改为你的训练日志文件名
# ==========================================================================#
def extract_log(log_file, new_log_file, key_word):
'''
:param log_file:日志文件
:param new_log_file:挑选出可用信息的日志文件
:param key_word:根据关键词提取日志信息
:return:
'''
with open(log_file, "r") as f:
with open(new_log_file, "w") as train_log:
for line in f:
# 去除多gpu的同步log
if "Syncing" in line:
continue
# 去除nan log
if "nan" in line:
continue
if key_word in line:
train_log.write(line)
f.close()
train_log.close()
def drawAvgLoss(loss_log_path):
'''
:param loss_log_path: 提取到的loss日志信息文件
:return: 画loss曲线图
'''
line_cnt = 0
for count, line in enumerate(open(loss_log_path, "rU")):
line_cnt += 1
result = pd.read_csv(loss_log_path, skiprows=[iter_num for iter_num in range(line_cnt) if ((iter_num < 500))],
error_bad_lines=False,
names=["loss", "avg", "rate", "seconds", "images"])
result["avg"] = result["avg"].str.split(" ").str.get(1)
result["avg"] = pd.to_numeric(result["avg"])
fig = plt.figure(1, figsize=(6, 4))
ax = fig.add_subplot(1, 1, 1)
ax.plot(result["avg"].values, label="Avg Loss", color="#ff7043")
ax.legend(loc="best")
ax.set_title("Avg Loss Curve")
ax.set_xlabel("Batches")
ax.set_ylabel("Avg Loss")
def drawIOU(iou_log_path):
'''
:param iou_log_path: 提取到的iou日志信息文件
:return: 画iou曲线图
'''
line_cnt = 0
for count, line in enumerate(open(iou_log_path, "rU")):
line_cnt += 1
result = pd.read_csv(iou_log_path, skiprows=[x for x in range(line_cnt) if (x % 39 != 0 | (x < 5000))],
error_bad_lines=False,
names=["Region Avg IOU", "Class", "Obj", "No Obj", "Avg Recall", "count"])
result["Region Avg IOU"] = result["Region Avg IOU"].str.split(": ").str.get(1)
result["Region Avg IOU"] = pd.to_numeric(result["Region Avg IOU"])
result_iou = result["Region Avg IOU"].values
# 平滑iou曲线
for i in range(len(result_iou) - 1):
iou = result_iou[i]
iou_next = result_iou[i + 1]
if abs(iou - iou_next) > 0.2:
result_iou[i] = (iou + iou_next) / 2
fig = plt.figure(2, figsize=(6, 4))
ax = fig.add_subplot(1, 1, 1)
ax.plot(result_iou, label="Region Avg IOU", color="#ff7043")
ax.legend(loc="best")
ax.set_title("Avg IOU Curve")
ax.set_xlabel("Batches")
ax.set_ylabel("Avg IOU")
if __name__ == "__main__":
loss_log_path = "train_log_loss.txt"
iou_log_path = "train_log_iou.txt"
if os.path.exists(g_log_path) is False:
exit(-1)
if os.path.exists(loss_log_path) is False:
extract_log(g_log_path, loss_log_path, "images")
if os.path.exists(iou_log_path) is False:
extract_log(g_log_path, iou_log_path, "IOU")
drawAvgLoss(loss_log_path)
drawIOU(iou_log_path)
plt.show()


训练过程中,训练日志xxx.log是不断写入的,该脚本只能显示此时的图像信息,如果你需要看到最新的图像信息,需要删除生成的2个txt文件,再运行该脚本
4、YOLOV3无法加载图片"cannot load image"
如果你是用Windows来汇总.txt文件的,有可能会出现这种情况
解决办法:
用Notepad++ 打开train.txt
(1)视图→显示符号→显示所有符号;
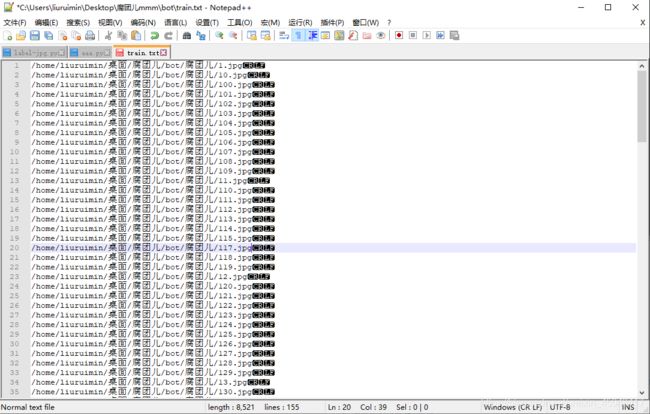
(2)编辑→文档格式转换→转换为Unix(LF)

如果还是不行,出现cannot open image或权限不够的情况,建议在linux下汇总这些文件,这样就避免了这些问题
参考资料
1、基于YOLO目标检测及OpenCV实现的游戏代玩人工智能体(Auto Gaming Agent) [3]
2、【笔记】YOLOv3训练自己的数据集(3)——小技巧和训练日志可视化
3、YOLOV3中Darknet中cfg文件说明和理解
4、YOLOV3无法加载图片"cannot load image"
5、yolo训练日志分析