交叉验证(Cross Validation)
一、训练集 vs. 测试集
在模式识别(pattern recognition)与机器学习(machine learning)的相关研究中,经常会将数据集(dataset)分为训练集(training set)跟测试集(testing set)这两个子集,前者用以建立模型(model),后者则用来评估该模型对未知样本进行预测时的精确度,正规的说法是泛化能力(generalization ability)。怎么将完整的数据集分为训练集跟测试集,必须遵守如下要点:
- 只有训练集才可以用在模型的训练过程中,测试集则必须在模型完成之后才被用来评估模型优劣的依据。
- 训练集中样本数量必须够多,一般至少大于总样本数的50%。
- 两组子集必须从完整集合中均匀取样。
其中最后一点特别重要,均匀取样的目的是希望减少训练集/测试集与完整集合之间的偏差(bias),但却也不易做到。一般的作法是随机取样,当样本数量足够时,便可达到均匀取样的效果,然而随机也正是此作法的盲点,也是经常是可以在数据上做手脚的地方。举例来说,当辨识率不理想时,便重新取样一组训练集/测试集,直到测试集的识别率满意为止,但严格来说这样便算是作弊了。
在机器学习里,通常来说我们不能将全部用于数据训练模型,否则我们将没有数据集对该模型进行验证,从而评估我们的模型的预测效果。为了解决这一问题,有如下常用的方法:
二、交叉验证(Cross Validation)
1.The Validation Set Approach
第一种是最简单的,也是很容易就想到的。我们可以把整个数据集分成两部分,一部分用于训练,一部分用于验证,这也就是我们经常提到的训练集(training set)和测试集(test set)。
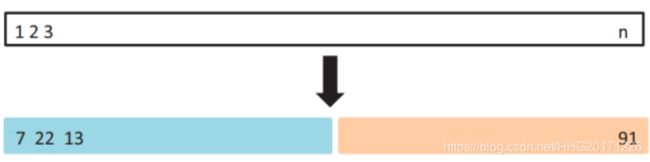
例如,如上图所示,我们可以将蓝色部分的数据作为训练集(包含7、22、13等数据),将右侧的数据作为测试集(包含91等),这样通过在蓝色的训练集上训练模型,在测试集上观察不同模型不同参数对应的MSE的大小,就可以合适选择模型和参数了。
不过,这个简单的方法存在两个弊端。
-
最终模型与参数的选取将极大程度依赖于你对训练集和测试集的划分方法。什么意思呢?我们再看一张图:
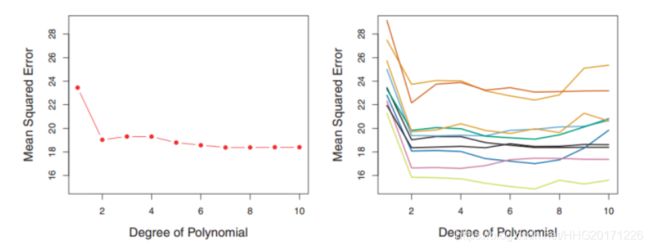
右边是十种不同的训练集和测试集划分方法得到的test MSE,可以看到,在不同的划分方法下,test MSE的变动是很大的,而且对应的最优degree也不一样。所以如果我们的训练集和测试集的划分方法不够好,很有可能无法选择到最好的模型与参数。 -
该方法只用了部分数据进行模型的训练
我们都知道,当用于模型训练的数据量越大时,训练出来的模型通常效果会越好。所以训练集和测试集的划分意味着我们无法充分利用我们手头已有的数据,所以得到的模型效果也会受到一定的影响。
基于这样的背景,有人就提出了Cross-Validation方法,也就是交叉验证。
2.Cross-Validation
2.1 LOOCV
首先,我们先介绍LOOCV方法,即(Leave-one-out cross-validation)。像Test set approach一样,LOOCV方法也包含将数据集分为训练集和测试集这一步骤。但是不同的是,我们现在只用一个数据作为测试集,其他的数据都作为训练集,并将此步骤重复N次(N为数据集的数据数量)。

如上图所示,假设我们现在有n个数据组成的数据集,那么LOOCV的方法就是每次取出一个数据作为测试集的唯一元素,而其他n-1个数据都作为训练集用于训练模型和调参。结果就是我们最终训练了n个模型,每次都能得到一个MSE。而计算最终test MSE则就是将这n个MSE取平均。
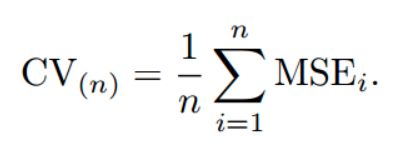
yi比起test set approach,LOOCV有很多优点。首先它不受测试集合训练集划分方法的影响,因为每一个数据都单独的做过测试集。同时,其用了n-1个数据训练模型,也几乎用到了所有的数据,保证了模型的bias更小。不过LOOCV的缺点也很明显,那就是计算量过于大,是test set approach耗时的n-1倍。
为了解决计算成本太大的弊端,又有人提供了下面的式子,使得LOOCV计算成本和只训练一个模型一样快。
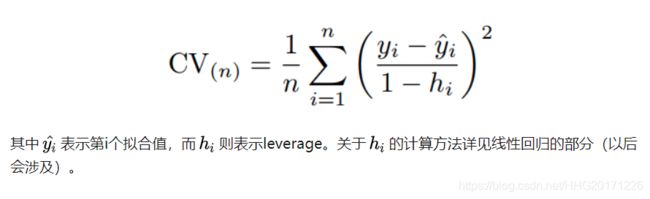
2.2 K-fold Cross Validation
将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标。K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2。K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性。
K折交叉验证,和LOOCV的不同在于,我们每次的测试集将不再只包含一个数据,而是多个,具体数目将根据K的选取决定。比如,如果K=5,那么我们利用五折交叉验证的步骤就是:
1.将所有数据集分成5份
2.不重复地每次取其中一份做测试集,用其他四份做训练集训练模型,之后计算该模型在测试集上的MSEi

不难理解,其实LOOCV是一种特殊的K-fold Cross Validation(K=N)。再来看一组图:
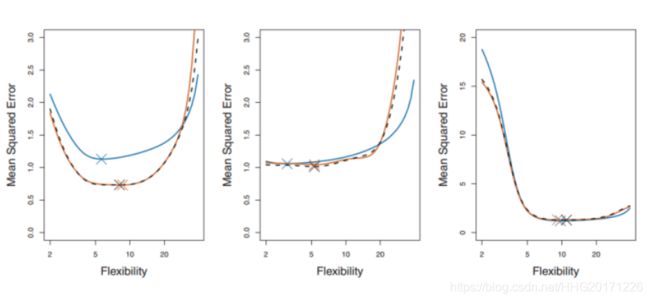
每一幅图种蓝色表示的真实的test MSE,而黑色虚线和橙线则分贝表示的是LOOCV方法和10-fold CV方法得到的test MSE。我们可以看到事实上LOOCV和10-fold CV对test MSE的估计是很相似的,但是相比LOOCV,10-fold CV的计算成本却小了很多,耗时更少。
2.3 Bias-Variance Trade-Off for k-Fold Cross-Validation
最后,我们要说说K的选取。事实上,和开头给出的文章里的部分内容一样,K的选取是一个Bias和Variance的trade-off。
K越大,每次投入的训练集的数据越多,模型的Bias越小。但是K越大,又意味着每一次选取的训练集之前的相关性越大(考虑最极端的例子,当k=N,也就是在LOOCV里,每次都训练数据几乎是一样的)。而这种大相关性会导致最终的test error具有更大的Variance。
一般来说,根据经验我们一般选择k=5或10。
2.4 Cross-Validation on Classification Problems
上面我们讲的都是回归问题,所以用MSE来衡量test error。如果是分类问题,那么我们可以用以下式子来衡量Cross-Validation的test error:
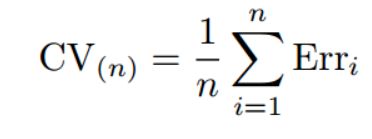
其中Erri表示的是第i个模型在第i组测试集上的分类错误的个数。
cross_val_score
交叉验证优点:
1:交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。
2:还可以从有限的数据中获取尽可能多的有效信息
def cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv='warn',
n_jobs=None, verbose=0, fit_params=None,
pre_dispatch='2*n_jobs', error_score='raise-deprecating'):
estimator:估计方法对象(分类器)
X:数据特征(Features)
y:数据标签(Labels)
soring:调用方法(包括accuracy和mean_squared_error等等)
cv:几折交叉验证
n_jobs:同时工作的cpu个数(-1代表全部)
fit_params:字典,将估计器中fit方法的参数通过字典传递
scoring参数值解析

这里文档对分类、聚类和回归三种问题下可以使用的参数进行了说明
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
boston = load_boston()
regressor = DecisionTreeRegressor(random_state=321)
# 交叉验证cross_val_score的用法
cross_val_score(regressor, boston.data, boston.target
, cv=10
, scoring='neg_mean_squared_error')