神经网络AlexNet训练CIFAR数据集
AlexNet神经网络结构
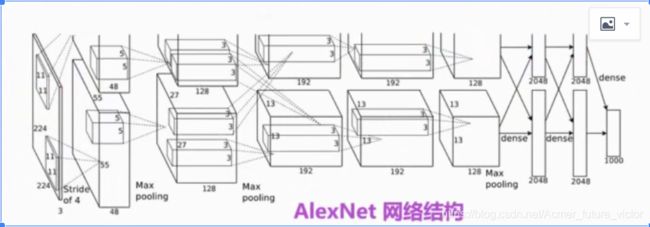
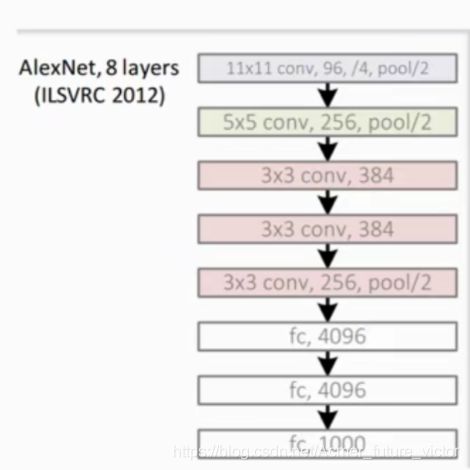
第一幅图的网络结构可以简化为第二幅图的网络结构。(但是,我没有算出和上图一样的特征图大小来,欢迎大佬指教)。
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np
from torch.autograd import Variable
from torchvision.datasets import CIFAR10
from torchvision import transforms
from utils import train
# CIFAR10中的数据是32*32*3大小的
# 定义AlexNet
class AlexNet(nn.Module):
def __init__(self):
super().__init__()
# 第一层是5*5的卷积,输入的channels是3,输出的channels
# 是64,步长是1,没有padding
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 5),
nn.ReLU(True)
)
# 第二层是3*3的池化,步长是2,没有padding
self.max_pool1 = nn.MaxPool2d(3, 2)
# 第三层是5*5的卷积,输入的channels是64,输出的
# channels是64,步长是1,没有padding
self.conv2 = nn.Sequential(
nn.Conv2d(64, 64, 5, 1),
nn.ReLU(True)
)
# 第四层是3*3的池化,步长是2,没有padding
self.max_pool2 = nn.MaxPool2d(3, 2)
# 第五层是全连接层,输入是1024,输出是384
self.fc1 = nn.Sequential(
nn.Linear(1024, 384),
nn.ReLU(True)
)
# 第六层是全连接层,输入是384, 输出是192
self.fc2 = nn.Sequential(
nn.Linear(384, 192),
nn.ReLU(True)
)
# 第七层是全连接层,输入是192,输出是10
self.fc3 = nn.Linear(192, 10)
def forward(self, x):
x = self.conv1(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = self.max_pool2(x)
# 将矩阵拉平
x = x.view(x.shape[0], -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化
x = x.transpose((2, 0, 1)) # 将channel放到第一维,只是pytorch要求的输入方式
x = torch.from_numpy(x)
return x
train_set = CIFAR10('./data', train=True, transform=data_tf, download=False)
train_data = torch.utils.data.DataLoader(train_set, batch_size=16, shuffle=True)
test_set = CIFAR10('./data', train=False, transform=data_tf, download=False)
test_data = torch.utils.data.DataLoader(test_set, batch_size=16, shuffle=False)
alexnet = AlexNet().cuda()
optimizer = torch.optim.SGD(alexnet.parameters(), lr=1e-2)
criterion = nn.CrossEntropyLoss()
train(alexnet, train_data, test_data, 10, optimizer, criterion)
utils.py
from datetime import datetime
import torch
import torch.nn.functional as F
from torch import nn
from torch.autograd import Variable
def get_acc(output, label):
total = output.shape[0]
_, pred_label = output.max(1)
num_correct = (pred_label == label).sum().data[0]
return num_correct / total
def train(net, train_data, valid_data, num_epochs, optimizer, criterion):
if torch.cuda.is_available():
net = net.cuda()
prev_time = datetime.now()
for epoch in range(num_epochs):
train_loss = 0
train_acc = 0
net = net.train()
for im, label in train_data:
if torch.cuda.is_available():
im = Variable(im.cuda()) # (bs, 3, h, w)
label = Variable(label.cuda()) # (bs, h, w)
else:
im = Variable(im)
label = Variable(label)
# forward
output = net(im)
loss = criterion(output, label)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.data[0]
train_acc += get_acc(output, label)
cur_time = datetime.now()
h, remainder = divmod((cur_time - prev_time).seconds, 3600)
m, s = divmod(remainder, 60)
time_str = "Time %02d:%02d:%02d" % (h, m, s)
if valid_data is not None:
valid_loss = 0
valid_acc = 0
net = net.eval()
for im, label in valid_data:
if torch.cuda.is_available():
im = Variable(im.cuda(), volatile=True)
label = Variable(label.cuda(), volatile=True)
else:
im = Variable(im, volatile=True)
label = Variable(label, volatile=True)
output = net(im)
loss = criterion(output, label)
valid_loss += loss.data[0]
valid_acc += get_acc(output, label)
epoch_str = (
"Epoch %d. Train Loss: %f, Train Acc: %f, Valid Loss: %f, Valid Acc: %f, "
% (epoch, train_loss / len(train_data),
train_acc / len(train_data), valid_loss / len(valid_data),
valid_acc / len(valid_data)))
else:
epoch_str = ("Epoch %d. Train Loss: %f, Train Acc: %f, " %
(epoch, train_loss / len(train_data),
train_acc / len(train_data)))
prev_time = cur_time
print(epoch_str + time_str)
训练结果:
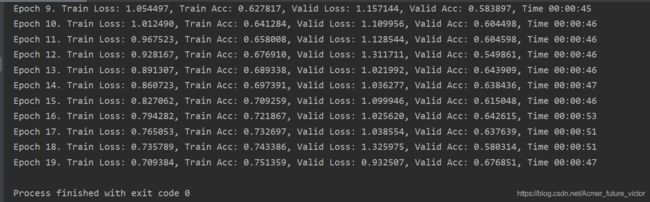
(这里的训练结果是在epoch=20,batch_size=64的情况下训练出来的)