GANs实现(GAN、DCGAN、WGAN、WGAN-GP,pix2pix)
GAN是Generative Adversarial Networks的简称,通过一个判别模型(Discriminator)和一个生成模型(Generator)之间互相博弈来完成最后的目标。
下面简要描述下GAN的训练思路和过程。
假设我们手里有很多同一风格的动漫头像数据,客观上,这些数据必然满足一个概率分布 P d a t a P_{data} Pdata,只不过这个概率分布太过复杂,没办法直接求出。

直接计算的方法走不通,或许可以换一种思路。我们都知道神经网络在理论上可以拟合任意的函数,那么对于数据的概率分布函数也应该可以拟合出来。而生成模型就是从这个想法出发,从一个简单分布中随机取样一个点,这个简单分布可以是高斯分布,均匀分布等,生成模型通过学习将这个简单分布映射成我们想要的数据的概率分布。
用 Z Z Z表示一个简单分布, G G G为生成模型拟合的函数, G ( Z ) = P z G(Z) = P_z G(Z)=Pz,我们希望 P z 与 P d a t a P_z与P_{data} Pz与Pdata越接近越好。可是单单有一个生成模型,它并不知道自己生成的分布距离真实的分布有多远。所以还需要一个判别模型,这个判别模型大多数情况下是在做一个二分类任务,真实的图片判别为真(输出1),生成器生成的图片判别为假(输出为0)。生成器为了欺骗过判别器必须将自己生成的概率分布与真实的概率分布不断靠近,而判别器也需要不断进步来识破出生成器的假照片。
生成器与判别器之间的博弈就被称为生成对抗网络,不得不说这是一种启发式的思路。
可以这种博弈虽然想法很棒,可以在实现时,如何衡量 P z 与 P d a t a P_{z}与P_{data} Pz与Pdata的距离呢?常见的办法有KL散度,JS散度,而GAN一开始的损失函数就是由JS散度设计而来。

这里的 V ( D , G ) V(D,G) V(D,G)可以看作是JS散度的变式,至于是怎么推导的,我认为对于刚刚接触GAN不是很重要。现在我们只需要知道这个 V ( D , G ) V(D,G) V(D,G)可以衡量 P z , P d a t a P_z,P_{data} Pz,Pdata之间的距离。前面的max代表,我们要找到一个判别器,它能够最好的分辨 P z 和 P d a t a P_z和P_{data} Pz和Pdata。而最前面的min则表示生成器的目标是让判别器能找到的两个分布最大距离最小。
这个目标函数很完美的解释了判别器和生成器之间的博弈,下面就可以考虑具体实现了。
最初GAN的实现

上面是最初的GAN的训练算法。使用的Minibatch的SGD算法。每次训练判别器(discriminator)的K是一个超参数,这里设置为1,代表每轮仅训练一次discriminator
训练discriminator时,从noise分布中(可以使用高斯分布)取样一个minibatch的数据 z z z,再取样一个minibatch的真实数据 x x x。获得数据以后利用对应的目标函数来更新discriminator。
训练generator时从noise中sample数据,并利用目标函数更新generator。
网络结构
Discriminator和Generator都由两层全连接层组成,第一层的激活函数使用LeakyReLU,scope值取0.1
#model.py
import torch
from torch import nn
class Discriminator(nn.Module):
def __init__(self,img_dim):
#img_dim代表图片展平以后的向量维度
super().__init__()
self.disc = nn.Sequential(
nn.Linear(img_dim, 128),
nn.LeakyReLU(0.1),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.disc(x)
class Generator(nn.Module):
def __init__(self, noise_dim, img_dim):
#noise_dim noise分布的维度
super().__init__()
self.gen= nn.Sequential(
nn.Linear(z_dim, 256),
nn.LeakyReLU(0.1),
nn.Linear(256, img_dim),
nn.Tanh()
)
def forward(self, x):
return self.gen(x)
训练算法的实现
import torch
from torch import nn, optim
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import Discriminator, Generator
from tqdm import tqdm
#超参数设置
lr = 3e-4
batch_size = 32
num_epochs = 10
noise_dim = 64
img_dim = 1 * 28 * 28 #使用的MNIST的手写数字
device = 'cuda' if torch.cuda.is_available() else 'cpu'
#初始化需要的模型和数据
disc = Discriminator(img_dim).to(device)
gen = Generator(noise_dim, img_dim).to(device)
opt_disc = optim.SGD(disc.parameters(), lr=lr)
opt_gen = optim.SGD(gen.parameters(), lr=lr)
criterion = nn.BCELoss()
writer_fake = SummaryWriter("logs/fake")
writer_real = SummaryWriter("logs/real")
step = 1#这是SummerWriter中要使用的
fixed_noise = torch.randn(batch_size, noise_dim).to(device) #后面检验generator效果使用的数据
transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
dataset = datasets.MNIST(root='../data', download=True, transform=transforms)
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(num_epochs):
loop = tqdm(loader, leave=True) #可视化训练进度
loop.set_discription("Epoch:%d"%epoch)
for idx, (real, _) in enumerate(loop):
noise = torch.randn(batch_size, noise_dim).to(device)
real = real.flatten(start_dim=1).to(device)
fake = gen(noise)
#Training discriminator max log(D(x)) + log(1 - D(G(z)))
disc_real = disc(real).reshape(-1)
disc_fake = disc(fake.detach()).reshape(-1) #detach是为了截断流向generator的梯度,防止其计算图被释放
lossD_real = criterion(disc_real, torch.ones_like(disc_real)) #-log(D(x))
lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake))# -log(1 - D(G(z)))
lossD = (lossD_real + lossD_fake) / 2
opt_disc.zero_grad()
lossD.backward()
opt_disc.step()
#Traning discriminator min log(1 - D(G(z))) <--> max log(D(G(z)))
output = disc(fake).reshape(-1)
lossG = criterion(output, torch.ones_like(output)) #- log(D(G(z)))
opt_gen.zero_grad()
lossG.backward()
opt_gen.step()
#一个epoch训练完以后测试下generator的效果
if idx == len(loader) - 1:
with torch.no_grad():
fake = gen(fixed_noise).reshape(-1, 1, 28, 28)
real = real.reshape(-1, 1, 28, 28)
img_grid_fake = torchvision.utisl.make_grid(fake, normalize=True)#normalize将值变到(0,1)之间
img_grid_real = torchvision.utils.make_grid(real, normalize=True)
writer_fake.add_image('GAN fake image', img_grid_fake, global_step=step)
writer_real.add_image('GAN real image', img_grid_real, global_step=step)
step +=1
DCGAN
一开始CNN火的时候,主要是在监督学习领域,你给神经网络图像和label,它告诉你分类的类别。而DCGAN做出的贡献是在无监督学习领域的GAN中使用了CNN,相比于全连接神经网络,CNN无疑更加有利于图片信息的提取。

关于超参数的设置
- All models were trained with mini-batch(128) SGD
- All weights were initialized from a zero-centered Normal distribution with standard deviation 0.02
- In the LeakyReLU, the slope of leaky was set to 0.2
- Adam optimizer:learning rate 2e-4, β 0.5 \beta \ 0.5 β 0.5

网络结构
import torch
from torch import nn
class Discrinimator(nn.Module):
def __init__(self, img_channels,):
super().__init__()
#discriminator的第一层没有batchnorm
self.Conv = nn.Sequential(
nn.Conv2d(img_channels, 128, 4, 2, 1),
nn.LeakyReLU(0.2)
)
self.disc = nn.Sequential(
self.Conv,
self._block(128, 256, 4, 2, 1),
self._block(256, 512, 4, 2, 1),
self._block(512, 1024, 4, 2, 1),
nn.Conv2d(1024, 1, 4, 2, 0),
nn.Sigmoid()
)
def _block(self, in_channels, out_chaneels, kernel_size, stride, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.2)
)
def forward(self, x):
#x[N, img_channels, 64, 64]
return self.disc(x)
class Generator(nn.Module):
def __init__(self, z_dim, img_channels):
super().__init__()
self.gen = nn.Sequential(
self._block(z_dim, 1024, 4, 2, 0),
self._block(1024, 512, 4, 2, 1),
self._block(512, 256, 4, 2, 1),
self._block(256, 128, 4, 2, 1),
nn.ConvTranspose2d(128, img_channels, 4, 2, 1),
nn.Tanh()
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride,
padding
),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def forward(self, x):
#x[N, z_dim, 1, 1]
return self.gen(x)
还需要实现将网络中的所有参数初始化为均值为0,标准差为0.02的初始化函数
def init_weight(model):
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):
nn.init.normal_(m.weight.data, (0.0, 0.02))
训练过程
训练过程和GAN的绝大部分代码都是相同的
import torch
from torch import nn, optim
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import Discriminator, Generator, init_weight
from tqdm import tqdm
#超参数设置
lr = 2e-4
batch_size = 128
num_epochs = 10
z_dim= 100
img_channels = 1
img_size = 64
device = 'cuda' if torch.cuda.is_available() else 'cpu'
#初始化需要的模型和数据
disc = Discriminator(img_channels).to(device)
gen = Generator(z_dim, img_channels).to(device)
#多了参数初始化
init_weight(disc)
init_weight(gen)
#换成了Adam
opt_disc = optim.Adam(disc.parameters(), lr=lr, beta=(0.5,0.99))
opt_gen = optim.SGD(gen.parameters(), lr=lr, beta=(0.5, 0.99))
criterion = nn.BCELoss()
writer_fake = SummaryWriter("logs/fake")
writer_real = SummaryWriter("logs/real")
step = 1#这是SummerWriter中要使用的
#注意形状的变化
fixed_noise = torch.randn(32, z_dim, 1, 1).to(device) #后面检验generator效果使用的数据
transforms = transforms.Compose([
transforms.Resize(img_size, img_size),
transforms.ToTensor(),
transforms.Normalize([0.5 for _ in range(img_channels)], [0.5 for _ in range(img_channels)])
])
dataset = datasets.MNIST(root='../data', download=True, transform=transforms)
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(num_epochs):
loop = tqdm(loader, leave=True) #可视化训练进度
loop.set_discription("Epoch:%d"%epoch)
for idx, (real, _) in enumerate(loop):
noise = torch.randn(batch_size, z_dim, 1, 1).to(device)
real = real.to(device)
fake = gen(noise)
#Training discriminator max log(D(x)) + log(1 - D(G(z)))
disc_real = disc(real).reshape(-1)
disc_fake = disc(fake.detach()).reshape(-1) #detach是为了截断流向generator的梯度,防止其计算图被释放
lossD_real = criterion(disc_real, torch.ones_like(disc_real)) #-log(D(x))
lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake))# -log(1 - D(G(z)))
lossD = (lossD_real + lossD_fake) / 2
opt_disc.zero_grad()
lossD.backward()
opt_disc.step()
#Traning discriminator min log(1 - D(G(z))) <--> max log(D(G(z)))
output = disc(fake).reshape(-1)
lossG = criterion(output, torch.ones_like(output)) #- log(D(G(z)))
opt_gen.zero_grad()
lossG.backward()
opt_gen.step()
#一个epoch训练完以后测试下generator的效果
if idx == len(loader) - 1:
with torch.no_grad():
fake = gen(fixed_noise)
img_grid_fake = torchvision.utisl.make_grid(fake, normalize=True)#normalize将值变到(0,1)之间
img_grid_real = torchvision.utils.make_grid(real[:32], normalize=True)
writer_fake.add_image('GAN fake image', img_grid_fake, global_step=step)
writer_real.add_image('GAN real image', img_grid_real, global_step=step)
step +=1
WGAN
GAN的目标函数可以推导成JS散度,而JS散度用来训练效果不是很好,它不是能够很好的衡量两个分布之间的距离,这导致了GAN对超参数的设置非常敏感,网络难以训练。WGAN更改了目标函数
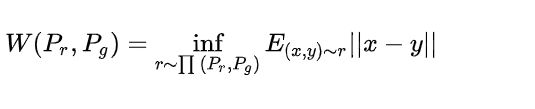
可以推导成下面的简洁形式

∣ ∣ f ∣ ∣ L ≤ 1 ||f||_{L\le1} ∣∣f∣∣L≤1表示函数要满足1-lipschitz连续,直观的理解就是梯度是受限的,防止梯度爆炸。
在实践当中,我们在每次梯度更新后,将参数裁剪到一定范围内。

网络模型
WGAN的网络结构沿用了DCGAN,不同之处是将Discriminator中最后一层Sigmoid操作拿掉了,并将Discriminator改名为Critic
训练过程
import torch
from torch import optim
from torchvision import datasets, transforms
from model import Critic, Generator,init_weight
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
lr = 5e-5
batch_size = 64
critic_iterations = 5 #一轮更新,critic要训练几次
z_dim = 100
img_channels = 3
img_size = 64
weight_clip = 0.01
num_epochs = 10
critic = Critic(img_channels)
gen = Generator(img_channels, z_dim)
init_weight(critic)
init_weight(gen)
opt_crit = optim.RMSprop(critic.parameters(), lr=lr)
opt_gen = optim.RMSprop(gen.parameters(), lr=lr)
transforms = transforms.Compose([
transforms.Resize(img_size, img_size),
transforms.Normalize([0.5 for _ in range(img_channels)], [0.5 for _ in range(img_channels)])
transforms.ToTensor()
])
dataset = datasets.MNIST(root='../data',download=True, transform=transforms)
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
fixed_noise = torch.randn(batch_size, img_channels, 1, 1)
writer_fake = SummaryWriter("logs/fake")
writer_real = SummaryWriter("logs/real")
step = 1
for epoch in range(num_epochs):
loop = tqdm(loader, leave=True) #可视化训练进度
loop.set_discription("Epoch:%d"%epoch)
for idx, (real, _) in enumerate(loop):
for _ in range(critic_iterations):
noise = torch.randn(batch_size, z_dim, 1, 1).to(device)
real = real.to(device)
fake = gen(noise)
#Training discriminator max E(D(x)) - E( D(G(z))) <--> min - (E(D(x)) - E(D(G(z))))
disc_real = disc(real)
disc_fake = disc(fake.detach()) #detach是为了截断流向generator的梯度,防止其计算图被释放
lossD_real = torch.mean(disc_real) #E(D(x))
lossD_fake = torch.mean(disc_fake)#
lossD = -(lossD_real - lossD_fake)
opt_disc.zero_grad()
lossD.backward()
opt_disc.step()
#梯度更新完以后对参数值进行裁剪
for p in critic.parameters():
p.data.clamp_(-weight_clip, weight_clamp)
#Traning discriminator min -E(D(G(z)))
output = disc(fake)
lossG = - torch.mean(output)
opt_gen.zero_grad()
lossG.backward()
opt_gen.step()
#一个epoch训练完以后测试下generator的效果
if idx == len(loader) - 1:
with torch.no_grad():
fake = gen(fixed_noise)
img_grid_fake = torchvision.utisl.make_grid(fake, normalize=True)#normalize将值变到(0,1)之间
img_grid_real = torchvision.utils.make_grid(real[:32], normalize=True)
writer_fake.add_image('GAN fake image', img_grid_fake, global_step=step)
writer_real.add_image('GAN real image', img_grid_real, global_step=step)
step +=1
WGAN-GP
如果直接对网络参数进行裁剪,效果并没有想象中那么好,考虑引入梯度惩罚正则项来进行约束。

![]()
该正则项表示神经网络的输出对输入的梯度尽可能接近1,这样就满足了1-lipstchitz约束,作者还对 P d a t a 和 P z P_{data}和P_z Pdata和Pz之间做了插值,这样选取出来的x兼顾了随机性和代表性。
作者还将RMSprop换回成了Adam。
def gradient_penalty(critic, real, fake, device='cpu'):
batch_size, c, h, w= real.shape
epsilon = torch,rand(batch_size,1, 1, 1).repeat(1, C, H, W)
#计算插值以后的结果,并且需要detach掉,防止影响之前的计算图
interpolated_image = real.detach() * epsilon + fake.detach() * (1 - epsilon)
mix_scores = critic(interpolated_image)
#计算D(x)对x的梯度
gradient = torch.autograd_grad(
inputs=interpolated_image,
outputs=mix_scores,
grad_outputs=torch.ones_like(mix_scores),
create_graph=True,
retain_graph=True
)
#L2范数
gradient_norm = torch.norm(2, dim=1)
gradient_penalty = torch.mean((gradient_norm - 1) ** 2)
return gradient_penalty
训练过程
相同的代码就不写了,主要是在每轮训练的时候发生了一些改变
lambda_gp = 10
for epoch in range(num_epochs):
loop = tqdm(loadr, leave=True)
loop.set_discription("Epoch:%d" % epoch)
for idx, (real, _) in enumerate(loop):
real = real.to(device)
noise = torch.randn(batch_size, z_dim, 1, 1).to(device)
fake = gen(noise)
for _ in range(critic_iterations):
critic_real = critic(real.detach())
critic_fake = critic(fake.detach())
gp = gradient_penalty(critic, real, fake, device)
lossD = - (torch.mean(critic_real) - torch.mean(critic_fake)) + lambda_gp * gp
opt_critic.zero_grad()
lossD.backward()
opt_critic.step()
output = critic(fake)
lossG = -torch.mean(output)
opt_gen.zero_grad()
lossG.backward()
opt_gen.step()
pix2pix
最后一块内容主要是图像风格转换(对仅有线条的图片进行上色),下面放出我实际做出的效果。具体内容参照我另一篇博客内容。