数据分析(2)——pandas库、sklearn库的简单说明
python之pandas用法详解(转载)
pandas用法总结(转载)
Pandas速查手册中文版(转载)
sklearn 中文文档(转载)
非常详细的sklearn介绍(转载)
Python之Sklearn使用教程(转载)
一、pandas
pandas是基于numpy构建的,使得数据分析工作变得更快更简单的高级数据结构和操作工具。
1、 Series与Datafame
Series是一种类似于一维数组的对象,它由一维数组和索引列组成。
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型,DataFrame既有行索引也有列索引。
import pandas as pd
airport=pd.Series([
'Seattle-Tacoma',
'Dulles',
'London Heathrow',
'Schiphol'
])
print(airport)
'''
0 Seattle-Tacoma
1 Dulles
2 London Heathrow
3 Schiphol
dtype: object
'''
print(airport[2])#查找第二项London Heathrow
for value in airport:#遍历每一项
print(value)
'''
Seattle-Tacoma
Dulles
London Heathrow
Schiphol
'''
airport1=pd.DataFrame([
['Seattle-Tacoma','Seattle','USA'],
['Dulles','Washington','USA'],
['London Heathrow','London','UK'],
['Schiphol','Amsterdam','Netherlands']],
columns=['Name','City','Country']#设置列表名
)
print(airport1)
'''
Name City Country
0 Seattle-Tacoma Seattle USA
1 Dulles Washington USA
2 London Heathrow London UK
3 Schiphol Amsterdam Netherlands
'''
print(airport1.head(3))#显示前三行,不指定数字的话,默认是前5行
'''
Name City Country
0 Seattle-Tacoma Seattle USA
1 Dulles Washington USA
2 London Heathrow London UK
'''
print(airport1.tail(3))#显示后三行
'''
Nmae City Country
1 Dulles Washington USA
2 London Heathrow London UK
3 Schiphol Amsterdam Netherlands
'''
print(airport1.shape)#显示维度(行数和列数,不包括索引和列表名称)(4,3)
print(airport1.info())#显示数据表基本信息
'''
RangeIndex: 4 entries, 0 to 3
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Nmae 4 non-null object
1 City 4 non-null object
2 Country 4 non-null object
dtypes: object(3)
memory usage: 112.0+ bytes
None
'''
print(airport1['City'])#抓取指定列
'''
0 Seattle
1 Washington
2 London
3 Amsterdam
Name: City, dtype: object
'''
print(airport1[['Name','Country']])#利用索引抓取多列
'''
Name Country
0 Seattle-Tacoma USA
1 Dulles USA
2 London Heathrow UK
3 Schiphol Netherlands
'''
print(airport1.iloc[0,0])#根据指定位置(行和列的索引)抓取数据Seattle-Tacoma
print(airport1.iloc[:,:])#抓取所有数据
print(airport1.iloc[0:2,:])#返回前两行数据
print(airport1.iloc[:,[0,2]])#返回第0列和第二列数据
print(airport1.loc[:,['Name','Country']])#通过名字查找数据
2、csv文件的读取
csv文件的特点:第一行为数据列名,后面的每组数据均用逗号隔开。

如上图所示,该语句自动创建了一个Dataframe。
#读入csv文件(从csv文件到DataFrame)当数据缺失时会自动填充为Nan
airport1_df=pd.read_csv('Data/airport1.csv',error_bad_lines=False)#跳过错误行
airport1_df=pd.read_csv('Data/airport1.csv',header=None,names=['Name','City','Country'])#指定列标题为空时添加列标题,系默认填充1、2、3、、,也可以自己指定
#写入csv文件(从DataFrame到csv文件)
airport1_df.to_csv('Data/MyNewCSVFile.csv',index=False)#index为False可以让索引不显现到csv文件中
3、DataFrame中的一些操作

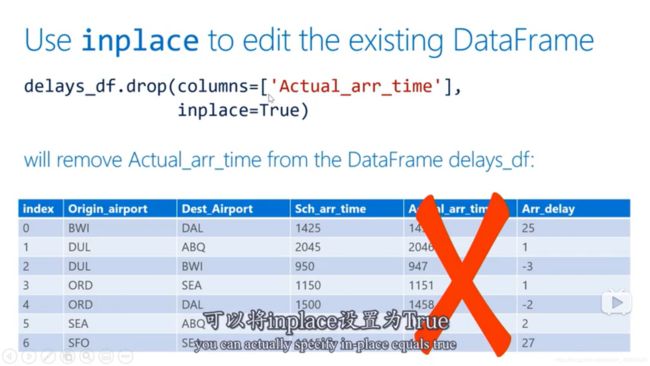
drop可以去除指定列,当inplace为true时,说明可以直接修改原来的数据表,不用将它再赋值到新的数据表了。
airport1_df.info()#可以查看是否包括空值
#删除含有缺失值或空值的行
airport1_no_nulls_df=airport1_df.dropna()#删除含有缺失值或空值的行并赋给新的数据表
airport1_df.dropna(inplace=True)#直接删除该表含有缺失值或空值的行
#必须是行重复才算重复
airport1_df.duplicated()#如果上下两行重复则算重复输出为True,否则为False
#删除重复行
airport1_df.drop_duplicates(inplace=True)
二、sklearn
Sklearn (全称 Scikit-Learn) 是基于 Python 语言的机器学习工具,是机器学习中的常用第三方模块。它建立在 NumPy, SciPy, Pandas 和 Matplotlib 之上,里面的 API 的设计非常好,所有对象的接口简单,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。
1、利用sklearn设置数据
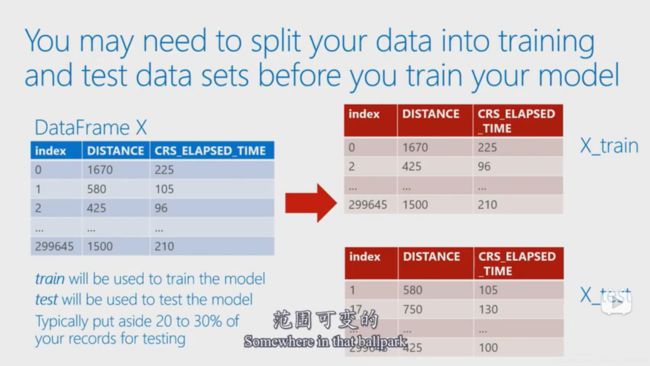
这里的训练集和测试集的分配是随机的(观察index)。sklearn提供了一个函数可以分离这些数据成为训练集和测试集。


x是特征数据,y是标签,test_size是测试数据的比例,random_state是用来保证随机数不变。
2、一个利用sklearn训练模型的小例子
数据分类如下,这是一个关于飞机延迟时间的例子,这里我们用线性回归。
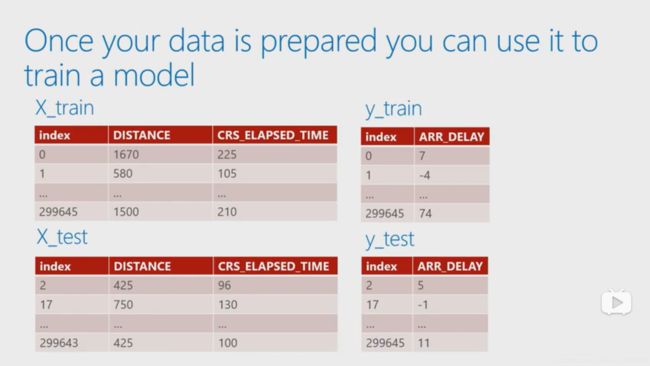
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import pandas as pd
delay_df=pd.read_csv('Data/Lots_of_flight_data.csv')
delay_df.dropna(inplace=True)
X=delay_df.loc[:,['DISTANCE','CRS_ELAPSED_TIME']]
y=delay_df.loc[:,['ARR_DELAY']]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=42)
#训练模型
regressor=LinearRegression()#创建一个实例
regressor.fit(X_train,y_rain)#运用拟合函数
#测试模型(预测)
y_pred=regressor.predict(X_test)#对测试数据进行预测结果
#可以评估模型的准确性(比较y_test和y_pred)
#均方误差:MSE=mean((actual-predicted)**2)
from sklearn import metrics
print(metrics.mean_squared_error(y_test,y_pred))
#均方根误差:sqrt(MSE)
import numpy as np
print(np.sqrt(metrics.mean_squared_error(y_test,y_pred)))
#平均绝对误差MAE=mean(abs(actual-predicted))
print(metrics.mean_absolute_error(y_test,y_pred))
#R平方
print(metrics.r2_score(y_test,y_pred))