推荐系统(九)PNN模型(Product-based Neural Networks)
推荐系统(九)PNN模型(Product-based Neural Networks)
推荐系统系列博客:
- 推荐系统(一)推荐系统整体概览
- 推荐系统(二)GBDT+LR模型
- 推荐系统(三)Factorization Machines(FM)
- 推荐系统(四)Field-aware Factorization Machines(FFM)
- 推荐系统(五)wide&deep
- 推荐系统(六)Deep & Cross Network(DCN)
- 推荐系统(七)xDeepFM模型
- 推荐系统(八)FNN模型(FM+MLP=FNN)
PNN模型(Product-based Neural Networks)和上一篇博客介绍的FNN模型一样,都是出自交大张伟楠老师及其合作者,这篇paper发表在ICDM’2016上,是个CCF-B类会议,这个模型我个人基本上没听到过工业界哪个公司在自己的场景下实践过,但我们依然可以看看这篇paper的成果,也许能为自己的业务模型提供一些参考借鉴意义。通过这个模型的名字Product-based Neural Networks,我们也基本可以略知PNN是通过引入product(可以是内积也可以是外积)来达到特征交叉的目的。
这篇博客将从动机和模型细节两方面进行介绍。
一、动机
这篇paper主要改进的是上一篇博客介绍的FNN,FNN主要存在两个缺点:
- DNN的embedding层质量受限于FM的训练质量。
- 在FM中进行特征交叉时使用的是隐向量点积,把FM预训练得到的embedding向量送入到MLP中的全链接层,MLP的全链接层本质上做的是特征间的线性加权求和,即做的是『add』的操作,这与FM有点不太统一。另外,MLP中忽略了不同的field之间的区别,全部采用线性加权求和。
论文原文为:
- the quality of embedding initialization is largely limited by the factorization machine.、
- More importantly, the “add” operations of the perceptron layer might not be useful to explore the interactions of categorical data in multiple fields. Previous work [1], [6] has shown that local dependencies between features from different fields can be effectively explored by feature vector “product” operations instead of “add” operations.
其实个人认为FNN还有个很大的局限性:FNN是个两阶段训练的模型,并不是个data-driven的end-to-end模型,FNN身上还是有浓厚的传统机器学习的影子。
二、PNN模型细节
2.1 PNN模型整体结构
PNN的网络结构如下图所示(图片摘自原论文)
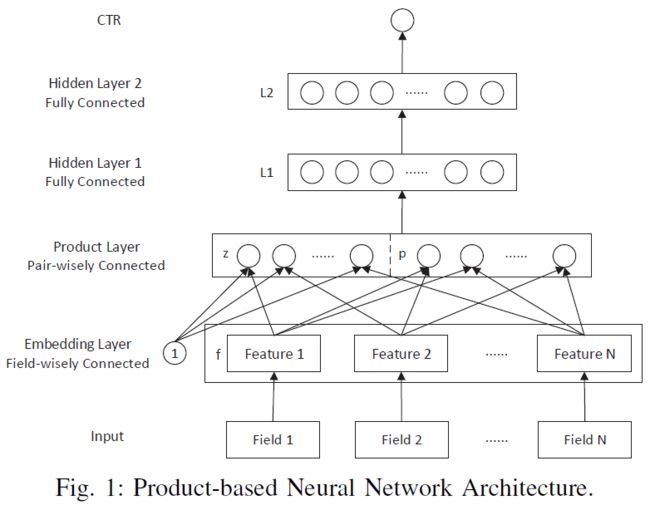
PNN模型的核心在于product layer,也就是上图中的product layer pair-wisely connected这一层。但不幸的是,原论文中给出的这张图隐藏了其中最重要的信息,看完上图的第一印象是product layer由 z z z和 p p p组成,然后直接送到上层的 L 1 L1 L1层。但实际上不是这样的,论文中所描述的是: z z z和 p p p在product layer分别又进行了全连接层的转换,分别将 z z z和 p p p映射成了 D 1 D_1 D1维度输入向量 l z l_z lz和 l p l_p lp( D 1 D_1 D1为隐藏层的神经元个数),然后再将 l z l_z lz和 l p l_p lp 叠加,然后再送入到 L 1 L_1 L1层。
所以,我自己把product layer重新画一下,看起来更详细的PNN模型结构,如下图所示:
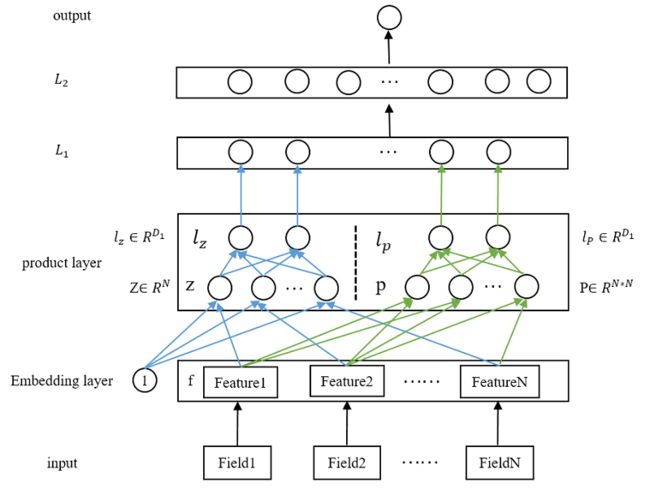
上面这个图基本上很清晰的把PNN的整体结构及核心细节都展示出来了。我们自底向上的看一看每一层
- 输入层
原始特征,没什么好说的。论文里为 N N N个特征。 - embedding层
也没什么好说的,就一普通的embedding层,维度为 D 1 D_1 D1。 - product 层
整篇论文的核心,这里分为两部分: z z z和 p p p,这两个都是从embedding层得到的。
【1. 关于 z z z】
其中 z z z是线性信号向量,其实就是直接把 N N N个特征的embedding向量直接copy过来,论文里用了个常量1,做相乘。论文中给出了形式化的定义:
z = ( z 1 , z 2 , z 3 , . . . , z N ) ≜ ( f 1 , f 2 , f 3 , . . . , f N ) (1) z = (z_1,z_2,z_3,...,z_N) \triangleq (f_1,f_2,f_3,...,f_N) \tag{1} z=(z1,z2,z3,...,zN)≜(f1,f2,f3,...,fN)(1)
其中 ≜ \triangleq ≜为恒等,所以 z z z的维度为 N ∗ M N*M N∗M。
【2. 关于 p p p】
p p p这里是真正的交叉操作,关于如何生成 p p p,论文里给出了形式化的定义: p i , j = g ( f i , f j ) p_{i,j}=g(f_i,f_j) pi,j=g(fi,fj),这里的 g g g理论上可以是任何映射函数,论文给出了两种映射:内积和外积,分别对应着IPNN和OPNN。因此:
p = { p i , j } , i = 1 , 2 , . . . , N ; j = 1 , 2 , . . . , N (2) p=\{p_{i,j}\}, i=1,2,...,N;j=1,2,...,N \tag{2} p={pi,j},i=1,2,...,N;j=1,2,...,N(2)
所以, p p p的维度为 N 2 ∗ M N^2*M N2∗M。
【3. 关于 l z l_z lz】
有了 z z z之后,通过一个全连接网络,如上图中product layer中蓝色线部分,最终被映射成 D 1 D_1 D1维(隐藏层单元的个数)的向量,形式化的表示为:
l z = ( l z 1 , l z 2 , . . . , l z k , . . . , l z D 1 ) l z k = W z k ⊙ z (3) l_z=(l_z^1,l_z^2,...,l_z^k,...,l_z^{D_1}) \ \ \ \ \ \ \ \ \ \ \ \ l_z^k=W_z^k\odot z \tag{3} lz=(lz1,lz2,...,lzk,...,lzD1) lzk=Wzk⊙z(3)
其中, ⊙ \odot ⊙为内积符号,定义为: A ⊙ B ≜ ∑ i , j A i j A i j A\odot B\triangleq \sum_{i,j}A_{ij}A_{ij} A⊙B≜∑i,jAijAij,因为 z z z的维度为 N ∗ M N*M N∗M,所以 W z k W_z^k Wzk的维度也为 N ∗ M N*M N∗M。
【4. 关于 l p l_p lp】
和 l z l_z lz一样,通过一个全连接网络,如上图中product layer中绿色线部分,最终被映射成 D 1 D_1 D1维(隐藏层单元的个数)的向量,形式化的表示为:
l p = ( l p 1 , l p 2 , . . . , l p k , . . . , l z D 1 ) l z k = W p k ⊙ p (4) l_p=(l_p^1,l_p^2,...,l_p^k,...,l_z^{D_1}) \ \ \ \ \ \ \ \ \ \ \ \ l_z^k=W_p^k\odot p \tag{4} lp=(lp1,lp2,...,lpk,...,lzD1) lzk=Wpk⊙p(4)
W p k W_p^k Wpk与 p p p的维度相同,为 N 2 ∗ M N^2*M N2∗M。 - 全连接层
这里就是普通的两层全连接层,直接上公式,简单清晰明了。
l 1 = r e l u ( l z + l p + b 1 ) (5) l_1 = relu(l_z + l_p + b_1) \tag{5} l1=relu(lz+lp+b1)(5)
l 2 = r e l u ( W 2 l 1 + b 2 ) (6) l_2 = relu(W_2l_1 + b_2) \tag{6} l2=relu(W2l1+b2)(6) - 输出层
因为场景是CTR预估,所以是二分类的,激活函数直接sigmoid,
y ^ = σ ( W 3 l 2 + b 3 ) (6) \hat{y} = \sigma(W_3l_2 + b_3) \tag{6} y^=σ(W3l2+b3)(6) - 损失函数
交叉熵走起,
L ( y , y ^ ) = − y log y ^ − ( 1 − y ) log ( 1 − y ) ^ (7) L(y,\hat{y}) = -y\log\hat{y} - (1-y)\log\hat{(1-y)} \tag{7} L(y,y^)=−ylogy^−(1−y)log(1−y)^(7)
2.2 IPNN
在product层,对特征embedding向量做交叉,理论上可以是任何操作,这篇paper给出了两种方式:内积和外积,分别对应IPNN和OPNN。从复杂度的角度来看,IPNN复杂度低于OPNN,因此如果打算工业落地的话,就不要考虑OPNN了,因此我会比较详细的介绍IPNN。
IPNN,即在product层做内积操作,依据上面给出的内积定义,能够看出两个向量的内积结果为一个标量。形式化的表示为:
g ( f i , f j ) = < f i , f j > (8) g(f_i,f_j) =
我们来分析下IPNN的时间复杂度,在明确下几个变量的维度:embedding维度为 M M M,特征个数为 N N N, l p l_p lp 和 l z l_z lz的维度为 D 1 D_1 D1。因为需要对特征两两交叉,所以 p p p的大小为 N ∗ N N*N N∗N,所以得到 p p p的时间复杂度为 N ∗ N ∗ M N*N*M N∗N∗M,有了 p p p,经过映射得到 l p l_p lp的时间复杂度为 N ∗ N ∗ D 1 N*N*D_1 N∗N∗D1,因此对于IPNN,整个product层的时间复杂度为 O ( N ∗ N ( D 1 + M ) ) O(N*N(D1+M)) O(N∗N(D1+M)),这个时间复杂度是很高的,因此需要优化,论文中采用了矩阵分解的技巧,把时间复杂度降低到 D 1 ∗ M ∗ N D1*M*N D1∗M∗N。来看看论文是怎么做的:
因为特征两两做交叉,因此 p p p显然是个 N ∗ N N*N N∗N的对称矩阵,则 W p k W_p^k Wpk也是个 N ∗ N N*N N∗N的对称矩阵,显然 W p k W_p^k Wpk是可以分解成两个 N N N维向量相乘的,假设 W p k = θ k ( θ k ) T W_p^k=\theta^k(\theta^k)^T Wpk=θk(θk)T,其中 θ k ∈ R N \theta^k\in R^N θk∈RN。
因此,我们有:
W p k ⊙ p = ∑ i = 1 N ∑ j = 1 N θ i k θ j k < f i , f j > = < ∑ i = 1 N θ i k f i , ∑ j = 1 N θ j k f j > (9) W_p^k \odot p = \sum_{i=1}^N\sum_{j=1}^N\theta^k_i\theta^k_j
如果我们记作 δ i k = θ i k f i \delta_i^k=\theta^k_if_i δik=θikfi,则 δ i k ∈ R M \delta_i^k \in R^M δik∈RM, δ i k = ( δ 1 k , δ 2 k , . . . , δ N k ) ∈ R N ∗ M \delta_i^k=(\delta_1^k,\delta_2^k,...,\delta_N^k) \in R^{N*M} δik=(δ1k,δ2k,...,δNk)∈RN∗M。
所以 l p l_p lp为:
l p = ( ∣ ∣ ∑ i δ i 1 ∣ ∣ , . . . . , ∣ ∣ ∑ i δ i D 1 ∣ ∣ ) (10) l_p = (||\sum_i\delta_i^1||,....,||\sum_i\delta_i^{D_{1}}||) \tag{10} lp=(∣∣i∑δi1∣∣,....,∣∣i∑δiD1∣∣)(10)
上面这一串公式一上,估计还有兴趣看这篇博客的人不足10%了,太晦涩难懂了。想要别人看的懂,最简单的办法就是举例子,咱们直接上例子,假设咱们样本有3个特征,每个特征的embedding维度为2,即 N = 3 , M = 2 N=3, M=2 N=3,M=2,所以咱们有如下一条样本:
| 特征(field) | embedding向量 |
|---|---|
| f 1 f_1 f1 | [1,2] |
| f 2 f_2 f2 | [3,4] |
| f 1 f_1 f1 | [5,6] |
用矩阵表示为:
[ 1 2 3 4 5 6 ] (11) \begin{bmatrix} 1& 2 \\ 3&4 \\ 5&6 \\ \end{bmatrix} \tag{11} ⎣⎡135246⎦⎤(11)
再来定义 W p 1 W_p^1 Wp1:
W p 1 = [ 1 2 3 2 4 6 3 6 9 ] (12) W_p^1 = \begin{bmatrix} 1& 2 & 3\\ 2&4 & 6\\ 3&6 &9 \\ \end{bmatrix} \tag{12} Wp1=⎣⎡123246369⎦⎤(12)
咱们分别按照分解前(复杂度为 O ( N ∗ N ( D 1 + M ) ) O(N*N(D1+M)) O(N∗N(D1+M)))和分解后来计算下,大家一对比就发现了其中的奥妙。
- 分解前
直接对 ( f 1 , f 2 , f 3 ) (f_1,f_2,f_3) (f1,f2,f3)两两做内积得到矩阵 p p p,计算过程如下:
p = [ 1 2 3 4 5 6 ] ⋅ [ 1 3 5 2 4 6 ] = [ 5 11 17 11 25 39 17 39 61 ] (13) p = \begin{bmatrix} 1& 2 \\ 3&4 \\ 5&6 \\ \end{bmatrix} \cdot \begin{bmatrix} 1& 3 & 5 \\ 2&4 & 6 \\ \end{bmatrix} = \begin{bmatrix} 5& 11 & 17 \\ 11& 25 & 39 \\ 17& 39 & 61 \\ \end{bmatrix} \tag{13} p=⎣⎡135246⎦⎤⋅[123456]=⎣⎡51117112539173961⎦⎤(13)
其中 p i j = f i ⊙ f j p_{ij} = f_i \odot f_j pij=fi⊙fj。
有了 p p p,咱们来计算 l p 1 l_p^1 lp1,其实就是算图2中product层中 l p l_p lp(绿色部分)的第一个元素的值,有:
W p 1 ⊙ p = [ 1 2 3 2 4 6 3 6 9 ] ⊙ [ 5 11 17 11 25 39 17 39 61 ] = s u m ( [ 5 22 51 22 100 234 51 234 549 ] ) = 1268 (14) W_p^1 \odot p = \begin{bmatrix} 1& 2 & 3\\ 2&4 & 6\\ 3&6 &9 \\ \end{bmatrix} \odot \begin{bmatrix} 5& 11 & 17 \\ 11& 25 & 39 \\ 17& 39 & 61 \\ \end{bmatrix} = sum(\begin{bmatrix} 5 &22 & 51 \\ 22 &100 &234 \\ 51 &234 &549 \\ \end{bmatrix}) = 1268 \tag{14} Wp1⊙p=⎣⎡123246369⎦⎤⊙⎣⎡51117112539173961⎦⎤=sum(⎣⎡522512210023451234549⎦⎤)=1268(14) - 分解后
W p 1 W_p^1 Wp1显然是可以分解的,可以分解为:
W p 1 = [ 1 2 3 2 4 6 3 6 9 ] = [ 1 2 3 ] [ 1 2 3 ] = θ 1 ( θ 1 ) T (15) W_p^1 = \begin{bmatrix} 1& 2 & 3\\ 2&4 & 6\\ 3&6 &9 \\ \end{bmatrix} = \begin{bmatrix} 1\\ 2\\ 3 \\ \end{bmatrix} \begin{bmatrix} 1&2&3\\ \end{bmatrix} = \theta^1 (\theta^1)^T \tag{15} Wp1=⎣⎡123246369⎦⎤=⎣⎡123⎦⎤[123]=θ1(θ1)T(15)
因此按照公式 δ i 1 = θ i 1 f i \delta_i^1=\theta^1_if_i δi1=θi1fi,我们来计算 δ i 1 \delta_i^1 δi1,见下表:
| 特征(field) | embedding向量 | θ i 1 \theta^1_i θi1 | δ i 1 \delta_i^1 δi1 |
|---|---|---|---|
| f 1 f_1 f1 | [1,2] | 1 | [1,2] |
| f 2 f_2 f2 | [3,4] | 2 | [6,8] |
| f 1 f_1 f1 | [5,6] | 3 | [15,18] |
因为还要做一步 ∑ i = 1 N δ i 1 \sum_{i=1}^N\delta_i^1 ∑i=1Nδi1,所以,最终我们得到向量 δ 1 \delta^1 δ1:
δ 1 = ∑ i = 1 N δ i 1 = [ 22 28 ] (16) \delta^1 = \sum_{i=1}^N\delta_i^1 = \begin{bmatrix} 22& 28 \end{bmatrix} \tag{16} δ1=i=1∑Nδi1=[2228](16)
所以最终有:
< δ 1 , δ 1 > = δ 1 ⊙ δ 1 = [ 22 28 ] ⊙ [ 22 28 ] = 1268 (17) <\delta^1, \delta^1> = \delta^1 \odot \delta^1 = \begin{bmatrix} \tag{17} 22& 28 \end{bmatrix} \odot \begin{bmatrix} 22& 28 \end{bmatrix} = 1268 <δ1,δ1>=δ1⊙δ1=[2228]⊙[2228]=1268(17)
所以,最终我们能够发现,分解前和分解后计算得到的 l p l_p lp的第一个元素值是相同的,而分解后的时间复杂度仅仅为 O ( D 1 ∗ M ∗ N ) O(D1*M*N) O(D1∗M∗N)。
因此,我们在实现IPNN的时候,线性部分和交叉部分的参数矩阵维度为:
- 对线性权重矩阵 W z W_z Wz 来说,大小为 D 1 ∗ N ∗ M D_1 * N * M D1∗N∗M。
- 对交叉(平方)权重矩阵 W p W_p Wp 来说,大小为 D 1 ∗ N D_1 * N D1∗N。
2.3 OPNN
OPNN和IPNN唯一的区别是把product layer中计算 l p l_p lp 时由内积变成了外积,由于外积操作得到的是一个 M ∗ M M*M M∗M的矩阵,即:
g ( f i , f j ) = f i f j T (18) g(f_i,f_j) = f_if_j^T \tag{18} g(fi,fj)=fifjT(18)
因此,OPNN整个的时间复杂为 O ( D 1 M 2 N 2 ) O(D1M^2N^2) O(D1M2N2),这个时间复杂度同样很高,因此,论文中提出了一种 叠加(superposition)的方法,来降低时间复杂度,具体来看看公式:
p = ∑ i = 1 N ∑ j = 1 N f i f j T = f ∑ ( f ∑ ) T (19) p = \sum_{i=1}^N \sum_{j=1}^N f_i f_j^T = f_{\sum}(f_{\sum})^T \tag{19} p=i=1∑Nj=1∑NfifjT=f∑(f∑)T(19)
其中, f ∑ = ∑ i = 1 N f i f_{\sum} = \sum_{i=1}^Nf_i f∑=∑i=1Nfi 。
经过上面的简化,OPNN的时间复杂度降低至 O ( D 1 M ( M + N ) ) O(D1M(M + N)) O(D1M(M+N))。
但我们观察上面的公式(19), f ∑ = ∑ i = 1 N f i f_{\sum} = \sum_{i=1}^Nf_i f∑=∑i=1Nfi,这相当于对所有特征做了一个sum pooling,也就是把不同特征的对应维度元素相加,这么做在实际业务中可能会存在一点问题,比如两个特征:年龄和性别,这两个特征的embedding向量本来就不在一个向量空间中,这样强行做sum pooling可能导致一些意想不到的问题。我们通过只会对多值特征,比如用户历史点击的item的embedding向量做pooling,这样做是没问题的,因为item本就在同一个向量空间中,并且具有实际意义。
在实践落地中,个人建议用IPNN。
参考文献
[1]: Yanru Qu et al. Product-Based Neural Networks for User Response Prediction. ICDM 2016: 1149-1154