收藏!从十篇顶会论文解读计算机视觉的未来之路!
点上方蓝字计算机视觉联盟获取更多干货
在右上方 ··· 设为星标 ★,与你不见不散
感谢联盟成员翻译总结笔记
正文共:14646 字 24 图 预计阅读时间: 37 分钟
本文带来的是近期热度最高的10篇计算机视觉论文,联盟通过对这10篇论文的解读,观测计算机视觉未来发展趋势在何方
1.Learning Individual Styles of Conversational Gesture
Paper: https://www.profillic.com/paper/arxiv:1906.04160
TLDR: Given audio speech input, they generate plausible gestures to go along with the sound and synthesize a corresponding video of the speaker.
Model/Architecture used: Speech to gesture translation model. A convolutional audio encoder downsamples the 2D spectrogram and transforms it to a 1D signal. The translation model, G, then predicts a corresponding temporal stack of 2D poses. L1 regression to the ground truth poses provides a training signal, while an adversarial discriminator, D, ensures that the predicted motion is both temporally coherent and in the style of the speaker
Model accuracy: Researchers qualitatively compare speech to gesture translation results to the baselines and the ground truth gesture sequences (tables presented by the author show lower loss and higher PCK of the new model)
Datasets used: Speaker-specific gesture dataset taken by querying youtube. In total, there are 144 hours of video. They split the data into 80% train, 10% validation, and 10% test sets, such that each source video only appears in one set.
联盟解读
![]()
鉴于音频语音输入,产生合理的姿态去声音和合成相应的演讲者的视频。
使用模型/体系结构翻译:演讲手势模型。卷积音频编码器downsamples二维谱图和转换到一个一维信号。翻译模型中,G,然后预测相应的时间堆2 d的姿势。L1回归到地面真理构成训练提供了一个信号,而一个敌对的鉴别器,D,确保预测的运动是暂时的连贯和演讲者的风格
模型的准确性:研究人员定性比较演讲手势翻译结果基线和地面实况手势序列(表由作者显示低损耗和高PCK的新模型)
数据集使用:Speaker-specific姿态数据集查询youtube。总共有144小时的视频。他们把数据分割成80%的训练,10%的验证,和10%的测试集,这样每个源视频只出现在一个组。

----------------------------------------------------------------
2.Textured Neural Avatars
Paper: https://www.profillic.com/paper/arxiv:1905.08776
TLDR: The researchers present a system for learning full-body neural avatars, i.e. deep networks that produce full-body renderings of a person for varying body pose and camera position. A neural free-viewpoint rendering of human avatars without reconstructing geometry
Model/Architecture used: The overview of the textured neural avatar system. The input pose is defined as a stack of ”bone” rasterizations (one bone per channel). The input is processed by the fully-convolutional network (generator) to produce the body part assignment map stack and the body part coordinate map stack. These stacks are then used to sample the body texture maps at the locations prescribed by the part coordinate stack with the weights prescribed by the part assignment stack to produce the RGB image. In addition, the last body assignment stack map corresponds to the background probability. During learning, the mask and the RGB image are compared with ground-truth and the resulting losses are backpropagated through the sampling operation into the fully-convolutional network and onto the texture, resulting in their updates.
Model accuracy: Outperforms the other two in terms of structured self-similarity (SSIM) and underperforms V2V in terms of Frechet Inception Distance (FID)
Datasets used:
- 2 subsets from the CMU Panoptic dataset collection.
- captured our own multi-view sequences of three subjects using a rig of seven cameras, spanning approximately 30 degrees. - 2 short monocular sequences from another paper and a Youtube video
联盟解读
![]()
研究人员提供一个系统学习全身神经化身,即深层网络产生全身呈现一个人对不同的身体姿势和摄像机的位置。一个神经free-viewpoint没有重建几何渲染人类的化身
使用模型/体系结构:变形神经阿凡达系统的概述。输入构成的定义是一堆“骨头”光栅化(每个通道一个骨头)。输入是由fully-convolutional处理网络(发电机)产生的身体部分地图任务堆栈和身体部分坐标映射堆栈。然后使用这些栈身体样本纹理映射在规定的位置坐标堆栈一部分部分规定的权重分配堆栈生产RGB图像。此外,最后身体分配堆栈映射对应于背景概率。在学习过程中,面具和RGB图像与真实和由此产生的损失通过采样操作到fully-convolutional backpropagated网络和纹理,导致他们的更新。
模型的准确性:优于其他两个结构化的自相似性(SSIM)和表现不佳V2V邻的初始距离(FID)
使用数据集:
- 2 CMU展示全景的数据集的子集集合。
——捕捉自己的多视点的三个主题序列使用平台的七个摄像头,横跨大约30度。- 2短单眼序列从另一篇论文和一个Youtube视频

--------------------------------------------------------------
3.DSFD: Dual Shot Face Detector
Paper: https://www.profillic.com/paper/arxiv:1810.10220
TLDR: They propose a novel face detection network with three novel contributions that address three key aspects of face detection, including better feature learning, progressive loss design and anchor assign based data augmentation, respectively.
Model/Architecture used: DSFD framework uses a Feature Enhance Module on top of a feedforward VGG/ResNet architecture to generate the enhanced features from the original features (a), along with two loss layers named first shot PAL for the original features and second shot PAL for the enchanted features.
Model accuracy: Extensive experiments on popular benchmarks: WIDER FACE and FDDB demonstrate the superiority of DSFD (Dual Shot face Detector) over the state-of-the-art face detectors (e.g., PyramidBox and SRN)
Datasets used: WIDER FACE and FDDB
联盟解读
![]()
他们提出了一个新颖的人脸检测网络小说有三个地址人脸检测的三个关键方面的贡献,包括更好的学习功能,设计和基于锚分配的数据增加,逐步丧失。
使用模型/体系结构:DSFD框架使用一个特性增强模块的前馈VGG / ResNet架构生成增强功能从原始特征(a),连同两层命名为第一枪的朋友损失的原始特性和第二枪PAL迷人的特性。
模型的准确性:广泛流行的基准:实验更广泛的脸和FDDB证明DSFD的优越性(双枪人脸检测器)最先进的脸上探测器(如PyramidBox和SRN)
使用数据集:广泛的脸和FDDB

------------------------------------------------------------------
4.GANFIT: Generative Adversarial Network Fitting for High Fidelity 3D Face Reconstruction
Paper: https://www.profillic.com/paper/arxiv:1902.05978
TLDR: The proposed deep fitting approach can reconstruct high-quality texture and geometry from a single image with precise identity recovery. The reconstructions in the figure and the rest of the paper are represented by a vector of size 700 floating points and rendered without any special effects.(the depicted texture is reconstructed by the model and none of the features taken directly from the image)
Model/Architecture used: A 3D face reconstruction is rendered by a differentiable renderer. Cost functions are mainly formulated by means of identity features on a pretrained face recognition network and they are optimized by flowing the error all the way back to the latent parameters with gradient descent optimization. End-to-end differentiable architecture enables us to use computationally cheap and reliable first order derivatives for optimization thus making it possible to employ deep networks as a generator (i.e,. statistical model) or as a cost function.
Model accuracy: Accuracy results for the meshes on the MICC Dataset using point-to-plane distance. The table reports the mean error (Mean), the standard deviation (Std.).are lowest for the proposed model.
Datasets used: MoFA-Test, MICC, Labelled Faces in the Wild (LFW) dataset, BAM dataset
联盟解读
![]()
提出深度拟合方法可以从单个图像重建高质量纹理和几何精确身份复苏。图中的重建和剩下的纸是由一个向量的大小700浮动点没有任何特效和渲染。(描述纹理重建的模型并没有特性直接取自图像)
使用模型/体系结构:一个3 d的脸呈现重建可微的渲染器。成本函数主要是通过制定pretrained身份特征的人脸识别网络和优化它们的错误一路回到了潜在的流动参数与梯度下降优化。端到端可微体系结构使我们能够使用廉价和可靠的一阶导数计算优化因此能够使用网络作为发电机(即深处。统计模型)或作为一个成本函数。
模型的准确性:准确结果的网格MICC数据集使用point-to-plane距离。表报告平均误差(平均),标准偏差(Std)。是该模型的最低。
使用数据集:MICC MoFA-Test标签面临在野外数据集,伦敦时装周开幕BAM数据集

---------------------------------------------------------------
5.DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images
Paper: https://www.profillic.com/paper/arxiv:1901.07973
TLDR: Deepfashion 2 provides a new benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images
Model/Architecture used: Match R-CNN contains three main components including a feature extraction network (FN), a perception network (PN), and a match network (MN).
Model accuracy: Match R-CNN achieves a top-20 accuracy of less than 0.7 with ground-truth bounding boxes provided, indicating that the retrieval benchmark is challenging.
Datasets used: The DeepFashion2 dataset contains 491K diverse images of 13 popular clothing categories from both commercial shopping stores and consumers
联盟解读
![]()
Deepfashion 2提供了一个新的基准检测、姿态估计,分类和鉴定的服装图片
使用模型/体系结构:匹配R-CNN包含三个主要组件包括特征提取网络(FN),感知网络(PN)和匹配网络(MN)。
模型的准确性:匹配R-CNN达到排名前20位的精度小于0.7的真实边界框,表明检索基准是具有挑战性的。
使用数据集:DeepFashion2数据集包含491 k不同图像的13类流行的服装商业购物商店和消费者

---------------------------------------------------
6.Inverse Cooking: Recipe Generation from Food Images
Paper: https://www.profillic.com/paper/arxiv:1812.06164
TLDR: Facebook researchers use AI to generate recipes from food images
Model/Architecture used: Recipe generation model- They extract image features with the image encoder. Ingredients are predicted by Ingredient Decoder, and encoded into ingredient embeddings with ingredient encoder. The cooking instruction decoder generates a recipe title and a sequence of cooking steps by attending to image embeddings, ingredient embeddings, and previously predicted words.
Model accuracy: The user study results demonstrate the superiority of their system against state-of-the-art image-to-recipe retrieval approaches. (outperforms both human baseline and retrieval based systems obtaining F1 of 49.08%)(good F1 score means that you have low false positives and low false negatives)
Datasets used: They evaluate the whole system on the large-scale Recipe1M dataset
联盟解读
![]()
Facebook研究者使用人工智能生成食谱从食物im年龄
使用模型/体系结构:配方生成模型,他们提取图像特征与图像编码器。原料成分预测的译码器,编码器编码为成分嵌入的成分。烹饪指令译码器生成一个食谱标题和通过参加烹饪步骤的序列图像嵌入,嵌入的原料,和先前预测的单词。
模型的准确性:用户研究结果证明他们的系统的优越性与最先进的image-to-recipe检索方法。(优于人类基于基线和检索的系统获得F1(49.08%)(良好的F1评分意味着你有较低的假阳性和假阴性)
使用数据集:他们评估整个系统在大规模Recipe1M数据集

---------------------------------------------------------------
7. ArcFace: Additive Angular Margin Loss for Deep Face Recognition
Paper: https://arxiv.org/pdf/1801.07698.pdf
TLDR: ArcFace can obtain more discriminative deep features and shows state-of-art performance in the MegaFace Challenge in a reproducible way.
Model/Architecture used: To enhance intraclass compactness and inter-class discrepancy they propose Additive Angular Margin Loss (ArcFace)- inserting a geodesic distance margin between the sample and centres. This is done to enhance the discriminative power of face recognition model
Model accuracy: Comprehensive experiments reported demonstrate that ArcFace consistently outperforms the state-of-the-art!
Datasets used: They employ CASIA, VGGFace2, MS1MV2 and DeepGlint-Face (including MS1M-DeepGlint and Asian-DeepGlint) as training data in order to conduct a fair comparison with other methods. Other datasets used- LFW, CFP-FP, AgeDB-30, CPLFW, CALFW, YTF, MegaFace, IJB-B, IJB-C, Trillion-Pairs, iQIYI-VID
联盟解读
![]()
ArcFace可以获得更多歧视深功能和显示技术发展水平表现MegaFace挑战通过创新的方式。
使用模型/体系结构他们建议:加强组内密实度和类的差异添加剂角保证金损失(ArcFace)——插入样本之间的测地距离边缘和中心。这样做是为了提高人脸识别模型的辨别力
模型的准确性:综合实验报道证明ArcFace始终优于最先进的!
使用数据集:他们雇佣CASIA、VGGFace2 MS1MV2和DeepGlint-Face(包括MS1M-DeepGlint和Asian-DeepGlint)作为训练数据,以便与其他方法进行公平的比较。其他数据集使用——LFW CFP-FP、AgeDB-30 CPLFW, CALFW, YTF, MegaFace, IJB-B, IJB-C, Trillion-Pairs iQIYI-VID

----------------------------------------------------------------
8.Fast Online Object Tracking and Segmentation: A Unifying Approach
Paper: https://www.profillic.com/paper/arxiv:1812.05050
TLDR: The method, dubbed SiamMask, improves the offline training procedure of popular fully-convolutional Siamese approaches for object tracking by augmenting their loss with a binary segmentation task.
Model/Architecture used: SiamMask aims at the interp between the tasks of visual tracking and video object segmentation to achieve high practical convenience. Like conventional object trackers, it relies on a simple bounding box initialisation and operates online. Differently, from state-of-the-art trackers such as ECO, SiamMask is able to produce binary segmentation masks, which can more accurately describe the target object. SiamMask has 2 variants: three-branch architecture, two-branch architecture (see paper for more details)
Model accuracy: Qualitative results of SiamMask for both VOT(visual object tracking) and DAVIS (Densely Annotated VIdeo Segmentation) sequences are shown in the paper. Despite the high speed, SiamMask produces accurate segmentation masks even in the presence of distractors.
Datasets used: VOT2016, VOT-2018, DAVIS-2016, DAVIS-2017 and YouTube-VOS
联盟解读
![]()
称为SiamMask,提高离线训练过程的流行fully-convolutional暹罗方法对象跟踪,向他们的损失一个二元分割的任务。
使用模型/体系结构:SiamMask目标视觉跟踪的任务之间的交叉和视频对象分割实现高实用方便。像传统的对象跟踪器,它依赖于一个简单的边界框初始化和在线运行。等先进的追踪者的不同,生态,SiamMask能够产生二元分割面具,可以更准确地描述目标对象。SiamMask有2个变种:三路架构,两个分校架构(见论文更多细节)
模型的准确性:定性结果的SiamMask嗓音起始时间(视觉物体跟踪)和戴维斯(密集带注释的视频分割)序列所示。尽管高速,SiamMask产生准确分割面具即使在干扰物的存在。
使用数据集戴维斯:VOT2016,嗓音起始时间- 2018,- 2016,戴维斯- 2017和YouTube-VOS

-----------------------------------------------------------
9. Revealing Scenes by Inverting Structure from Motion Reconstructions
Paper: https://www.profillic.com/paper/arxiv:1904.03303
TLDR: A team of scientists at Microsoft and academic collaborators reconstruct color images of a scene from the point cloud.
Model/Architecture used: Our method is based on a cascaded U-Net that takes as input, a 2D multichannel image of the points rendered from a specific viewpoint containing point depth and optionally color and SIFT descriptors and outputs a color image of the scene from that viewpoint.
Their network has 3 sub-networks – VISIBNET, COARSENET and REFINENET. The input to their network is a multi-dimensional nD array. The paper explores network variants where the inputs are different subsets of depth, color and SIFT descriptors. The 3 sub-networks have similar architectures. They are U-Nets with encoder and decoder layers with symmetric skip connections. The extra layers at the end of the decoder layers are there to help with high-dimensional inputs
Model accuracy: The paper demonstrated that surprisingly high quality images can be reconstructed from the limited amount of information stored along with sparse 3D point cloud models
Dataset used: trained on 700+ indoor and outdoor SfM reconstructions generated from 500k+ multi-view images taken from the NYU2 and MegaDepth datasets
联盟解读
![]()
微软的一组科学家和学术合作者重建彩色图像的点云的一个场景。
使用模型/体系结构:我们的方法是基于一个级联U-Net作为输入,2 d点的多通道图像呈现从特定的角度包含点深度和可选颜色和筛选描述符和输出彩色图像场景的观点。
他们的网络有三个子网,VISIBNET COARSENET REFINENET。网络的输入是一个多维数组。本文探讨网络变量的输入是不同子集的深度,颜色和筛选描述符。3个子网有类似的架构。他们是U-Nets与编码器和译码器层对称跳过连接。额外的层末端的译码器层有帮助高维输入
模型的准确性:本文证明了惊人的高质量图像可以从有限的信息重构存储稀疏的三维点云模型
使用数据集

--------------------------------------------------------
10. Semantic Image Synthesis with Spatially-Adaptive Normalization
Paper: https://www.profillic.com/paper/arxiv:1903.07291
TLDR: Turning Doodles into Stunning, Photorealistic Landscapes! NVIDIA research harnesses generative adversarial networks to create highly realistic scenes. Artists can use paintbrush and paint bucket tools to design their own landscapes with labels like river, rock and cloud
Model/Architecture used:
n SPADE, the mask is first projected onto an embedding space, and then convolved to produce the modulation parameters γ and β. Unlike prior conditional normalization methods, γ and β are not vectors, but tensors with spatial dimensions. The produced γ and β are multiplied and added to the normalized activation element-wise.
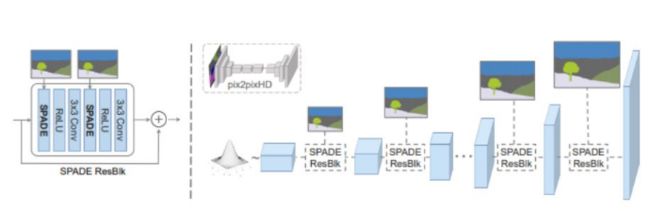
In the SPADE generator, each normalization layer uses the segmentation mask to modulate the layer activations. (left) Structure of one residual block with SPADE. (right) The generator contains a series of SPADE residual blocks with upsampling layers.
Model accuracy: Our architecture achieves better performance with a smaller number of parameters by removing the downsampling layers of leading image-to-image translation networks. Our method successfully generates realistic images in diverse scenes ranging from animals to sports activities.
Dataset used: COCO-Stuff, ADE20K, Cityscapes, Flickr Landscape
联盟解读
![]()
涂鸦变成了惊人的,逼真的风景! NVIDIA的研究利用生成对抗网络创建高度逼真的场景。艺术家可以使用画笔和油漆桶工具来设计自己的风景与河等标签,岩石和云
使用模型/体系结构:
在铲,面具是首先投射到一个嵌入空间,然后生成卷积调制参数γ和β。与之前的条件归一化方法,γ和β不是向量,但张量空间维度。γ和β增加,添加到激活element-wise正常化。在铲生成器,每个标准化层使用分割掩模来调节激活。(左)与铲一个残块的结构。(右)发电机包含一系列的铁锹upsampling层的残块。
模型的准确性:我们的架构实现更好的性能用较少的参数通过移除downsampling层领导image-to-image翻译网络。我们的方法成功地生成逼真的图像在不同场景从动物到体育活动。
使用数据集
END
声明:本文来源于联盟翻译总结笔记
加群交流
欢迎加入CV联盟群获取CV和ML等领域前沿资讯
扫描添加CV联盟微信拉你进群,备注:CV联盟

最新热文荐读
LeetCode刷题记录专栏
TensorFlow零基础入门——计算模型、数据模型、运行模型!
深度学习在计算机视觉领域的应用一览!超全总结!
Google学术发布2019年最有影响力的7篇论文!
手把手教你安装配置最新2019Pycharm,亲测有效!
2019年中国科学院院士增选初步候选人名单公布!
国际顶级人工智能专家--颜水成老师水平有多高?
拿到华为200万年薪的8个人到底是何方神圣?
陈天奇回忆--机器学习科研的十年

点个好看支持一下吧