第1周课件-全网最详细的ORB-SLAM2精讲
rgbdslam_v2在Ubuntu18.04+ROS_melodic的运行以及相关问题解决
https://blog.csdn.net/weixin_44436677/article/details/105587986
https://blog.csdn.net/XindaBlack/article/details/102499364/
目录
1. ORB_SLAM 2简介
1.1 ORB_SLAM 2简介
1.2 ORB_SLAM2 框架
主体框架
数据输入的预处理
2. TUM 数据集使用
2.1 ORB_SLAM2 在TUM数据集上的表现
2.2 TUM RGB-D 数据集 简介
2.3 运行RGBD模式时的预处理
2.4. 不同颜色地图点的含义
3. ORB 特征
3.1 FAST关键点
3.2 BRIEF 特征
3.3 ORB 特征
3.4 为什么要重载小括号运算符 operator() ?
3.5 金字塔的计算
3.6 特征点数量的分配计算
3.7 使用四叉树对图层中的特征点进行平均和分发
1. ORB_SLAM 2简介
1.1 ORB_SLAM 2简介
1.2 ORB_SLAM2 框架
主体框架

数据输入的预处理

2. TUM 数据集使用
2.1 ORB_SLAM2 在TUM数据集上的表现
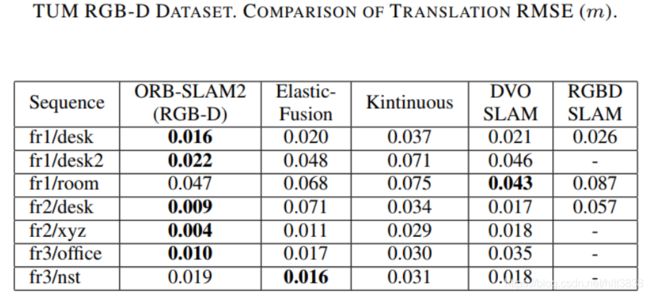
2.2 TUM RGB-D 数据集 简介

2.3 运行RGBD模式时的预处理
2.4. 不同颜色地图点的含义
void Tracking::UpdateLocalMap()
{ // This is for visualization
mpMap->SetReferenceMapPoints(mvpLocalMapPoints);
// Update UpdateLocalKeyFrames();
UpdateLocalPoints();
}

3. ORB 特征
3.1 FAST关键点

3.2 BRIEF 特征
https://blog.csdn.net/hltt3838/article/details/105912580

问题1: FAST特征点的数量很多,并且不是确定,而大多数情况下,我们希望能够固定特征点的数量。
解决方法: 在ORB当中,我们可以指定要提取的特征点数量。对原始的FAST角点分别计算Harris的响应值,然后选取前N个点具有最大相应值的角点,作为最终角点的集合。
问题2: FAST角点不具有方向信息和尺度问题。
解决方法: 尺度不变性构建的图像的金字塔,并且从每一层上面来检测角点。
灰度质心法: 质心是指以图像块灰度值作为权重的中心。(目标是为找找到方向:几何中心 ——> Q为灰度质心).
理解:为什么要考虑尺度的问题? 因为相机在运动的过程中,可能离物体越来越远或者越来越近,这时候出现的情况是:近看图像上的特征点,在远看图像上就没有啦,因为图像的平滑,那么更别说特征点的匹配了! 为了让它们能匹配上,需要对图构建尺度空间,获得图片不同尺度下的表达,并获取特征点,具体的做法就是图像的金字塔。比如:我们要提取1000个特征点,而金字塔的层数是8,把这1000个特征点按照面积比例分别在 每层图像提取,这样的话就是说在不同尺度的图片上都能提取到特征点,这样就可以解决前面说的 “相机在运动的过程中,可能离物体越来越远或者越来越近,这时候出现的情况是:近看图像上的特征点,在远看图像上就没有啦” 问题!
参考:https://blog.csdn.net/RobotLife/article/details/87194017?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.control&dist_request_id=48c2bb06-67c0-42b6-8a5d-4ead425a80a7&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.control 具体的理解可以看后面的内容+代码理解!
3.3 ORB 特征





cvFloor 返回不大于参数的最大整数值, cvCeil 返回不小于参数的最小整数值,cvRound 则是四舍五入
vmax = cvFloor(HALF_PATCH_SIZE * sqrt(2.f) / 2 + 1);
vmin = cvCeil(HALF_PATCH_SIZE * sqrt(2.f) / 2);
// 对应从D到B的红色弧线,umax坐标从D到C
for (v = 0; v <= vmax; ++v)
umax[v] = cvRound(sqrt(hp2 - v * v)); // 勾股定理,hp2 是半径
// 对应从B到E的蓝色弧线,umax坐标从C到A
for (v = HALF_PATCH_SIZE, v0 = 0; v >= vmin; --v)
{
while (umax[v0] == umax[v0 + 1]) ++v0;
umax[v] = v0;
++v0;
}
问题:Umax和Vmax这些到底有什么用?
答案:主要是确定圆内横纵坐标的边界用的,方便索引像素值。这部分有点麻烦,详见课程第2讲; 认真理解一下,我们在索引像素值的时候,一定是个 for() 循环,那这个for() 循环的的边界值是多大?就是用这个方法确定的! 有人可能会说,边界值是R呀,但是你想一下,像素点的坐标 u,v轴是存在一个关系的,没有必要每次都最大范围R的搜索!
3.4 为什么要重载小括号运算符 operator() ?
3.5 金字塔的计算


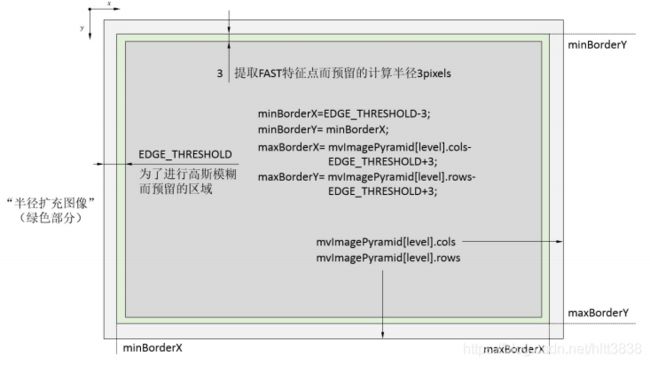


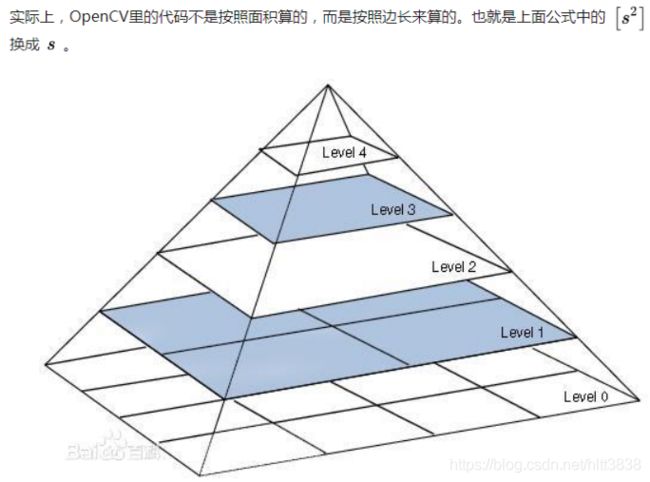
尺度不变的理解:在orb_slam2中,为了实现特征尺度不变性采用了图像金字塔,金字塔的缩放因子为1.2, 其思路就是对原始图形(第0层)依次进行1/1.2缩放比例进行降采样得到共计8张图片(包括原始图像),然后分别对得到的图像进行特征提取,并记录特征所在金字塔的第几层,这样得到一帧图像的特征点。现在假设在第二层中有一特征点F,为了避免缩放带来特征点F在纵向的移动,为简化叙述,选择的特征点F位于图像中心。根据相机成像 “物近像大,物远像小” 的原理,假设 摄像机原始图像即金字塔第0层对应图2中成像视野I0 ,则图像金字塔第2层图像可以相应对应于图中成像视野I2 。其中特征点F所在patch的相应关系。根据得到 结论1: d2 / d0 = 1.22 。
有了以上铺垫现在,来说说,尺度不变性,这里不直接说明,而是看看对于第m层上的一个特征点,其对应尺度不变时相机与特征点对应空间位置之间距离(简称物距)的范围。假设第m层上有一特征点Fm,其空间位置与拍摄时相机中心的位置为dm ,显然这是原始图像缩放1/1.2m倍后得到的特征点patch,考虑 “物远像小” 的成像特点,要使得该第m层特征点对应patch变为图像金字塔第0层中同样大小的patch,其相机与空间点的距离d=dm * 1.2m ,即尺度不变的最大物距 dmax = dm*1.2m 。要求尺度不变的最小物距则这样考虑:根据 “物近像大” 的成像特点,使得当前第m层的特征点移到第7层上则,真实相机成像图像得放大1.27-m倍,故对应最小物距dmin=dm *1.2m-7 。
3.6 特征点数量的分配计算

3.7 使用四叉树对金字塔每一图层中的特征点进行平均和分发





理解:
ORB-SLAM中并没有使用OpenCV的实现,因为OpenCV的版本提取的ORB特征过于集中,会出现扎堆的现象。这会降低SLAM的精度,对于闭环来说,也会降低一幅图像上的信息量。具体的对ORB-SLAM的影响可以参考我的另一篇文章 杨小东:[ORB-SLAM2] ORB特征提取策略对ORB-SLAM2性能的影响;ORB-SLAM中的实现提高了特征分布的均匀性。最简单的一种方法是把图像划分成若干小格子,每个小格子里面保留质量最好的n个特征点。这种方法看似不错,实际上会有一些问题。当有些格子里面能够提取的数量不足n个的时候(无纹理区域),整幅图上提取的特征总量就达不到我们想要的数量。严重的情况下,SLAM就会跟丢喽,ORB-SLAM中的实现就解决了这么一个问题,当一个格子提取不到FAST点的时候,自动降低阈值。ORB-SLAM主要改进了FAST角点提取步骤。
上面步骤的内容理解如下:
