论文阅读笔记 :FCOS:Fully Convolutional One-Stage Object Detection
论文链接:https://arxiv.org/abs/1904.01355
本文是自己阅读完论文后为了方便回顾整理的笔记,如果有错误的地方欢迎在评论区指出。
文章目录
-
- 一、FCOS是什么?
- 二、为什么提出FCOS(优点)
- 三、整体框架
- 四、算法实现细节
-
-
- 1、训练样本及回归目标
- 2、网络输出
- 3、损失函数
- 4、测试
- 5、FPN多级预测
- 6、center-ness
-
- 五、对FCOS进行的无成本改进:
基于锚点检测器的缺点:
1、锚框的尺寸、长宽比和数量等对检测性能有很大影响。
2、由于锚框的比例和长宽比保持固定,检测器在处理形状变化较大的候选对象时遇到困难,特别是对于小对象。预定义的锚框也妨碍了检测器的泛化能力,因为它们需要针对具有不同对象大小或长宽比的新检测任务进行重新设计。
3、为了实现高召回率,需要基于锚的检测器在输入图像上密集放置锚框。在训练过程中,这些锚定框大多被标记为负样本。负面样本数量过多,加剧了训练中正负样本的不平衡。
4、锚框还涉及复杂的计算,例如计算与真实边界框的交并比(IoU)分数。
基于FCN的框架进行对象检测的缺点:
1、必须对图像金字塔检测,违背了FCN所有卷积一次计算的理念。
2、应用于具有高度重叠边界框的通用对象时效果不佳。高度重叠的边界框导致了模糊性:对于重叠区域中的像素,不清楚要回归哪个边界框。
FCOS:利用gt box中的所有点来预测边界框,可能会在远离目标物体中心的位置产生一些低质量的预测边界框。为了抑制这些低质量的检测,引入了一个只有一层的”中心度“分支来预测一个像素点对其相应边界框中心的偏差。这个分数被用来降低低质量的检测边界框的权重,并在NMS中合并检测结果。
一、FCOS是什么?
FCOS是一个基于anchor-free的单阶段目标检测算法,一种完全卷积的无锚框和proposal的单阶段目标检测器,以逐像素预测的方式解决目标检测,类似于语义分割。
二、为什么提出FCOS(优点)
①检测无anchor无proposal,减少了设计参数的数量。
②避免了与anchor box有关的复杂计算:如IOU计算和anchor box与gt box之间的匹配。加快速度,减少内存。
③FCOS可以作为两阶段检测器中的RPN,甚至比RPN更好的性能
④可以立即扩展到解决其他视觉任务,包括实例分割和关键点检测等。
⑤可以利用尽可能多的前景样本来训练回归器,而基于anchor的检测器仅将达到一定IOU的anchor box视为正样本。
三、整体框架
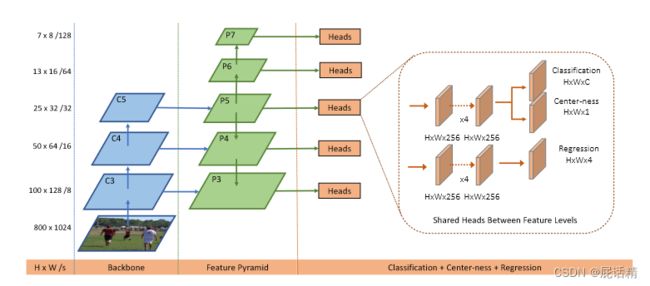
- 搭建如图所示的网络架构,将预处理后的图片送入backbone得到feature map,在feature map的每个像素点上面进行回归操作,训练网络获取网络模型;
- 得到网络模型后进行测试,从特征金字塔的多个Head中获得预测的结果;
- 使用NMS等后处理操作获得最终的结果。
四、算法实现细节
1、训练样本及回归目标
1)关于特征图上每个像素映射到原输入图像后的点:基于anchor的检测器将其视为(多个)anchor box的中心,并以这些anchor box为参考对目标边界框进行回归;FCOS直接回归该位置的目标边界框,回归量是该点到框的四条边的距离(图3中的4个量)。换句话说,FCOS直接将位置视为训练样本,而不是锚框。

2)如果位置(x,y)落入任何gt box,并且该位置的类标签c**是gt box的类标签,则将其视为正样本,否则为负样本,c*=0(背景类)。除了用于分类的标签,还有一个4D实数向量t*=(l*,t*,r*,b*)作为该位置的回归目标。l*,t*,r*,b*是位置到边界框四个边的距离。如果一个位置落入多个边界框,则将其视为模糊样本。我们只需选择面积最小的边界框作为其回归目标,比如说图2的点同时落入两个框内,选择蓝色的那个作为回归目标。通过多级FPN预测,模糊样本的数量可以大大减少,因此它们几乎不影响检测性能。形式上,如果位置(x,y)与一个边界框Bi相关联,那么该位置的训练回归目标可以表示为:

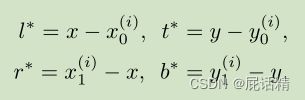
2、网络输出
网络输出在特征图之后添加了4个卷积层,用于分类和回归。此外,由于回归目标总是正数,我们采用exp(x)将任何实数映射到回归分支的顶部(0, ∞)。FCOS的网络输出变量比每个位置有9个锚框的基于anchor的检测器要少9倍。
3、损失函数

Lcls:focal loss,Lreg:IOU loss。Npos:正样本的数量。λ:1。Lreg的平衡权重。指示函数1{c*>0}=1,c*<0时该指示函数为0。
4、测试
p>0.05视为正样本。根据反转方程(1)获得预测边界框。
5、FPN多级预测
使用FPN可以降低模糊样本的比例,因为大多数重叠的对象被分配到不同的特征级别。
1)、定义了5个级别的特征图,在不同级别的特征图上检测不同大小的对象。P3、P4、P5由主干CNN的特征图C3、C4、C5生成,然后是1*1卷积层。P5应用一个步长为2的卷积层得到P6,P6应用一个步长为2的卷积层得到P7。各特征图步幅分别为:8、16、32、64、128。
2)、在不同的特征级别之间共享头部,不同的特征级别需要回归不同的尺寸范围。因此,对不同的特征级别使用相同的头是不合理的。因此,FCOS没有使用标准的exp(x),而是使用exp(six),用一个可训练的标量si来自动调整特征级别Pi的指数函数的基数。
3)、同一类别的物体之间的重叠所导致的模糊样本并不重要。如果具有相同类别的对象A和B由重叠,无论重叠部分的位置预测哪个对象,预测都是正确的。遗漏的对象可以通过只属于它的位置进行预测。因此,只计算不同类别的边界框之间重叠的模糊样本。
举个例子:A、B都是狮子,发生了重叠,重叠的位置预测哪个框的类别都是狮子,假设预测的A,那么遗漏的B这个框由不与A发生重叠部分的点产生预测框来进行预测。
6、center-ness
在使用FPN后,FCOS和基于锚的检测器之间仍然存在性能差距,这是优于原理对象中心的位置产生了许多低质量的预测边界框。
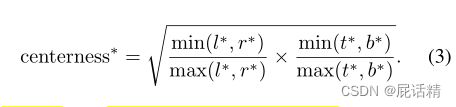
图3中,红色表示1,蓝色表示0,其他颜色表示1、0之间的值。中心度由公式(3)计算,描述了从位置到该位置负责的对象中心的归一化距离。并随着位置偏离物体中心而从1衰减到0。测试时,最终分数=预测的中心度*相应的分类分数,低质量边界框的最终分数会被降低,很有可能被NMS过滤掉。
 中心度的一个替代方法:仅使用gt box的中心部分作为正样本,代价是一个额外的超参数。
中心度的一个替代方法:仅使用gt box的中心部分作为正样本,代价是一个额外的超参数。
五、对FCOS进行的无成本改进:
1、ctr.on reg.:将中心度分支移到回归分支
2、ctr.sampling:只对gt box的中心部分采样为正样本。
3、GIoU:在IoU Loss 中惩罚外接矩形区域上的联合区域。
4、Normalization:用FPN水平的跨度对公式(1)中的回归目标进行归一化。
参考:
1、https://blog.csdn.net/WZZ18191171661/article/details/89258086
2、霹雳吧啦Wz
3、https://blog.csdn.net/weixin_44751294/article/details/119585952