机器学习笔记之深度信念网络(二)模型构建思想(RBM叠加结构)
机器学习笔记之深度信念网络——模型构建思想
- 引言
-
- 回顾:深度信念网络的结构表示
- 解析RBM隐变量的先验概率
- 通过模型学习隐变量的先验概率
引言
上一节介绍了深度信念网络的模型表示,本节将介绍深度信念网络的模型构建思想——受限玻尔兹曼机叠加结构的基本逻辑。
回顾:深度信念网络的结构表示
深度信念网络是一个基于有向图、无向图的混合模型。它的概率图结构表示如下:

通过概率图结构的描述,可以发现:
- 观测变量层 v ( 1 ) v^{(1)} v(1),隐变量层 h ( 1 ) , h ( 2 ) h^{(1)},h^{(2)} h(1),h(2)三层的随机变量构成的概率图结构是Sigmoid信念网络;而隐变量层 h ( 2 ) , h ( 3 ) h^{(2)},h^{(3)} h(2),h(3)构成的概率图结构是受限玻尔兹曼机。
- 通过对受限玻尔兹曼机的堆叠(Stacking)实现对深度信念网络向更深层次进行延伸。
这里使用省略号替代了后续的堆叠部分。
如果将随机变量层 v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) , ⋯ v^{(1)},h^{(1)},h^{(2)},h^{(3)},\cdots v(1),h(1),h(2),h(3),⋯看作是关于对应层所有随机变量的集合,那么联合概率分布则表示为:
这里仍然以 v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) v^{(1)},h^{(1)},h^{(2)},h^{(3)} v(1),h(1),h(2),h(3)这四层结构进行示例。
P ( v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) ) \mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)}) P(v(1),h(1),h(2),h(3))
实际上,非相邻层之间存在条件独立性。
- 例如: v ( 1 ) v^{(1)} v(1)层与 h ( 2 ) h^{(2)} h(2)层。这明显是有向图结构中的顺序结构。在 h ( 1 ) h^{(1)} h(1)层可观测的条件下, h ( 2 ) h^{(2)} h(2)层中的任意结点与 v ( 1 ) v^{(1)} v(1)层之间条件独立:
h ( 2 ) ⊥ v ( 1 ) ∣ h ( 1 ) h^{(2)} \perp v^{(1)} \mid h^{(1)} h(2)⊥v(1)∣h(1) - 上述只是有向图结构。如果是混合结构呢?例如: h ( 1 ) h^{(1)} h(1)层与 h ( 3 ) h^{(3)} h(3)层。虽然既包含有向图结构,也包含无向图结构,但它们依然满足条件独立性:
h ( 1 ) ⊥ h ( 3 ) ∣ h ( 2 ) h^{(1)} \perp h^{(3)} \mid h^{(2)} h(1)⊥h(3)∣h(2)
以 h ( 1 ) , h ( 2 ) , h ( 3 ) h^{(1)},h^{(2)},h^{(3)} h(1),h(2),h(3)层中的某一组结构为例,具体概率图结构表示如下(红色路径):
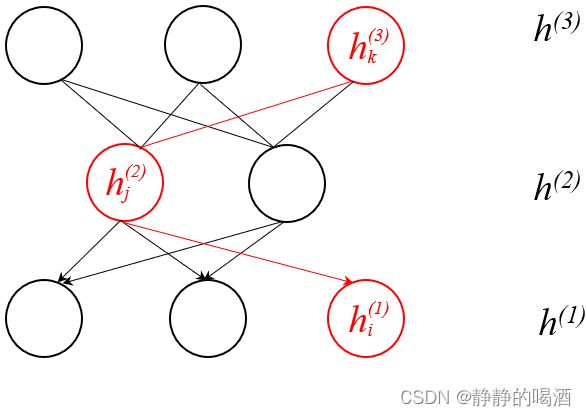
从有向图的角度观察,可以将红色部分表示为如下形式。如果在隐变量 h j ( 2 ) h_j^{(2)} hj(2)给定的条件下,隐变量 h k ( 3 ) , h i ( 1 ) h_k^{(3)},h_i^{(1)} hk(3),hi(1)之间要么是顺序结构关系,要么是同父结构关系,依然改变不了条件独立的本质。

至此,联合概率分布 P ( v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) ) \mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)}) P(v(1),h(1),h(2),h(3))可表示为:
P ( v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) ) = P ( v ( 1 ) ∣ h ( 1 ) , h ( 2 ) , h ( 3 ) ) ⋅ P ( h ( 1 ) , h ( 2 ) , h ( 3 ) ) = P ( v ( 1 ) ∣ h ( 1 ) ) ⋅ P ( h ( 1 ) ∣ h ( 2 ) , h ( 3 ) ) ⋅ P ( h ( 2 ) , h ( 3 ) ) = P ( v ( 1 ) ∣ h ( 1 ) ) ⋅ P ( h ( 1 ) ∣ h ( 2 ) ) ⋅ P ( h ( 2 ) , h ( 3 ) ) \begin{aligned} \mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)}) & = \mathcal P(v^{(1)} \mid h^{(1)},h^{(2)},h^{(3)}) \cdot \mathcal P(h^{(1)},h^{(2)},h^{(3)}) \\ & = \mathcal P(v^{(1)} \mid h^{(1)}) \cdot \mathcal P(h^{(1)} \mid h^{(2)},h^{(3)}) \cdot \mathcal P(h^{(2)},h^{(3)}) \\ & = \mathcal P(v^{(1)} \mid h^{(1)}) \cdot \mathcal P(h^{(1)} \mid h^{(2)}) \cdot \mathcal P(h^{(2)},h^{(3)}) \end{aligned} P(v(1),h(1),h(2),h(3))=P(v(1)∣h(1),h(2),h(3))⋅P(h(1),h(2),h(3))=P(v(1)∣h(1))⋅P(h(1)∣h(2),h(3))⋅P(h(2),h(3))=P(v(1)∣h(1))⋅P(h(1)∣h(2))⋅P(h(2),h(3))
根据Sigmoid信念网络与受限玻尔兹曼机的定义,展开结果表示如下:
P ( v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) ) = ∏ i = 1 D P ( v i ( 1 ) ∣ h ( 1 ) ) ⋅ ∏ j = 1 P ( 1 ) P ( h j ( 1 ) ∣ h ( 2 ) ) ⋅ P ( h ( 2 ) , h ( 3 ) ) { P ( v i ( 1 ) ∣ h ( 1 ) ) = Sigmoid { [ W h ( 1 ) → v i ( 1 ) ] T h ( 1 ) + b i ( 0 ) } [ W h ( 1 ) → v i ( 1 ) ] P ( 1 ) × 1 ∈ W ( 1 ) P ( h j ( 1 ) ∣ h ( 2 ) ) = Sigmoid { [ W h ( 2 ) → h j ( 1 ) ] T h ( 2 ) + b j ( 1 ) } [ W h ( 2 ) → h j ( 1 ) ] P ( 2 ) × 1 ∈ W ( 2 ) P ( h ( 2 ) , h ( 3 ) ) = 1 Z exp { [ h ( 3 ) ] T W ( 3 ) ⋅ h ( 2 ) + [ h ( 2 ) ] T ⋅ b ( 2 ) + [ h ( 3 ) ] T b ( 3 ) } \begin{aligned} & \mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)}) = \prod_{i=1}^{\mathcal D} \mathcal P(v_i^{(1)} \mid h^{(1)}) \cdot \prod_{j=1}^{\mathcal P^{(1)}} \mathcal P(h_j^{(1)} \mid h^{(2)}) \cdot \mathcal P(h^{(2)},h^{(3)}) \\ & \begin{cases} \mathcal P(v_i^{(1)} \mid h^{(1)}) = \text{Sigmoid} \left\{\left[\mathcal W_{h^{(1)} \to v_i^{(1)}}\right]^T h^{(1)} + b_i^{(0)}\right\} \quad \left[\mathcal W_{h^{(1)} \to v_i^{(1)}}\right]_{\mathcal P^{(1)} \times 1} \in \mathcal W^{(1)} \\ \mathcal P(h_j^{(1)} \mid h^{(2)}) = \text{Sigmoid} \left\{\left[\mathcal W_{h^{(2)} \to h_j^{(1)}}\right]^T h^{(2)} + b_j^{(1)}\right\} \quad \left[\mathcal W_{h^{(2)} \to h_j^{(1)}}\right]_{\mathcal P^{(2)} \times 1} \in \mathcal W^{(2)} \\ \mathcal P(h^{(2)},h^{(3)}) = \frac{1}{\mathcal Z} \exp \left\{ \left[h^{(3)}\right]^T \mathcal W^{(3)} \cdot h^{(2)} + \left[h^{(2)}\right]^T\cdot b^{(2)} + \left[h^{(3)}\right]^Tb^{(3)}\right\} \\ \end{cases} \end{aligned} P(v(1),h(1),h(2),h(3))=i=1∏DP(vi(1)∣h(1))⋅j=1∏P(1)P(hj(1)∣h(2))⋅P(h(2),h(3))⎩ ⎨ ⎧P(vi(1)∣h(1))=Sigmoid{[Wh(1)→vi(1)]Th(1)+bi(0)}[Wh(1)→vi(1)]P(1)×1∈W(1)P(hj(1)∣h(2))=Sigmoid{[Wh(2)→hj(1)]Th(2)+bj(1)}[Wh(2)→hj(1)]P(2)×1∈W(2)P(h(2),h(3))=Z1exp{[h(3)]TW(3)⋅h(2)+[h(2)]T⋅b(2)+[h(3)]Tb(3)}
解析RBM隐变量的先验概率
深度信念网络被设计成 Sigmoid \text{Sigmoid} Sigmoid信念网络与若干受限玻尔兹曼机的叠加结构,它的设计思路具体是什么?
回顾受限玻尔兹曼机。其概率图结构表示如下:
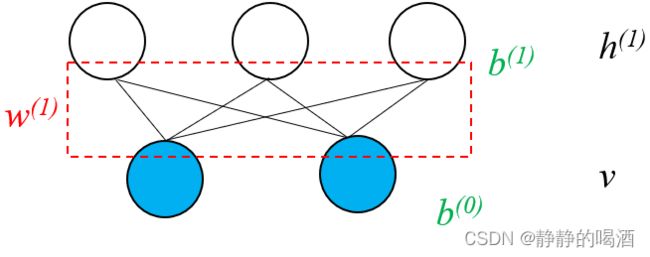
其中 W ( 1 ) \mathcal W^{(1)} W(1)表示隐变量、观测变量之间关联关系的权重信息; b ( 0 ) , b ( 1 ) b^{(0)},b^{(1)} b(0),b(1)分别表示观测变量、隐变量的偏置信息。在受限玻尔兹曼机——对数似然梯度求解中,介绍了关于 模型参数 θ \theta θ 的求解过程:
- 根据已知样本 V = { v ( i ) } i = 1 N \mathcal V = \{v^{(i)}\}_{i=1}^N V={v(i)}i=1N使用极大似然估计方法进行求解。其目标函数 L ( θ ) \mathcal L(\theta) L(θ)表示为:
L ( θ ) = 1 N ∑ v ( i ) ∈ V log P ( v ( i ) ; θ ) \mathcal L(\theta) = \frac{1}{N} \sum_{v^{(i)} \in \mathcal V} \log \mathcal P(v^{(i)};\theta) L(θ)=N1v(i)∈V∑logP(v(i);θ)
对应模型参数的对数似然梯度可表示为:
∇ θ L ( θ ) = 1 N ∑ v ( i ) ∈ V ∇ θ [ log P ( v ( i ) ; θ ) ] \nabla_{\theta} \mathcal L(\theta) = \frac{1}{N} \sum_{v^{(i)} \in \mathcal V} \nabla_{\theta} \left[ \log \mathcal P(v^{(i)};\theta)\right] ∇θL(θ)=N1v(i)∈V∑∇θ[logP(v(i);θ)] - 根据能量模型的对数似然梯度,将 ∇ θ [ log P ( v ( i ) ; θ ) ] \nabla_{\theta} \left[\log \mathcal P(v^{(i)};\theta)\right] ∇θ[logP(v(i);θ)]表示为如下形式:
∇ θ [ log P ( v ( i ) ; θ ) ] = P ( h k ( i ) = 1 ∣ v ( i ) ) ⋅ v j ( i ) − ∑ v ( i ) P ( v ( i ) ) ⋅ P ( h k ( i ) = 1 ∣ v ( i ) ) ⋅ v j ( i ) θ = W h k ( i ) ⇔ v j ( i ) \nabla_{\theta} \left[\log \mathcal P(v^{(i)};\theta)\right] = \mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) \cdot v_j^{(i)} - \sum_{v^{(i)}} \mathcal P(v^{(i)}) \cdot \mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) \cdot v_j^{(i)} \quad \theta = \mathcal W_{h_k^{(i)} \Leftrightarrow v_j^{(i)}} ∇θ[logP(v(i);θ)]=P(hk(i)=1∣v(i))⋅vj(i)−v(i)∑P(v(i))⋅P(hk(i)=1∣v(i))⋅vj(i)θ=Whk(i)⇔vj(i)
关于第一项:可以通过 Sigmoid \text{Sigmoid} Sigmoid函数直接求解后验概率 P ( h k ( i ) = 1 ∣ v ( i ) ) \mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) P(hk(i)=1∣v(i));
关于第二项:它是关于 N N N项的连加,其计算量极高。因而通过使用对比散度的方式对第二项进行近似:
这里的t t t表示吉布斯采样的迭代步骤。
∑ v ( i ) P ( v ( i ) ) ⋅ P ( h k ( i ) = 1 ∣ v ( i ) ) ⋅ v j ( i ) = E v ( k ) ∼ P ( V t = k ) [ P ( h k ( i ) = 1 ∣ v ( i ) ) ⋅ v j ( i ) ] \sum_{v^{(i)}} \mathcal P(v^{(i)}) \cdot \mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) \cdot v_j^{(i)} = \mathbb E_{v^{(k)} \sim \mathcal P(\mathcal V^{t = k})} \left[\mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) \cdot v_j^{(i)}\right] v(i)∑P(v(i))⋅P(hk(i)=1∣v(i))⋅vj(i)=Ev(k)∼P(Vt=k)[P(hk(i)=1∣v(i))⋅vj(i)] - 关于参数 W h k ( i ) ⇔ v j ( i ) \mathcal W_{h_k^{(i)} \Leftrightarrow v_j^{(i)}} Whk(i)⇔vj(i)的梯度求解完成后,使用梯度上升法近似求解 W h k ( i ) ⇔ v j ( i ) \mathcal W_{h_k^{(i)} \Leftrightarrow v_j^{(i)}} Whk(i)⇔vj(i)。其余参数同理:
θ ( t + 1 ) ⇐ θ ( t ) + η ∇ θ [ log P ( v ( i ) ; θ ) ] θ = W h k ( i ) ⇔ v j ( i ) \theta^{(t+1)} \Leftarrow \theta^{(t)} + \eta \nabla_{\theta} \left[\log \mathcal P(v^{(i)};\theta)\right] \quad \theta = \mathcal W_{h_k^{(i)} \Leftrightarrow v_j^{(i)}} θ(t+1)⇐θ(t)+η∇θ[logP(v(i);θ)]θ=Whk(i)⇔vj(i)
观察,上述关于模型参数的学习过程是复杂的,并且包含两次近似(对比散度、梯度上升),其核心原因在于:受限玻尔兹曼机是一个无向图模型,随机变量结点之间没有明确的因果关系。
能否通过一些改进,让参数学习过程的效果更好?
以上述受限玻尔兹曼机概率图结构示例,再次将关注点转向 P ( v ) \mathcal P(v) P(v):
这里的上标就变成了网络层的编号,而不是样本编号。
P ( v ) = ∑ h ( 1 ) P ( h ( 1 ) , v ) = ∑ h ( 1 ) P ( h ( 1 ) ) ⋅ P ( v ∣ h ( 1 ) ) \begin{aligned} \mathcal P(v) & = \sum_{h^{(1)}} \mathcal P(h^{(1)},v) \\ & = \sum_{h^{(1)}} \mathcal P(h^{(1)}) \cdot \mathcal P(v \mid h^{(1)}) \end{aligned} P(v)=h(1)∑P(h(1),v)=h(1)∑P(h(1))⋅P(v∣h(1))
- 其中 h ( 1 ) h^{(1)} h(1)可看成 RBM \text{RBM} RBM中所有隐变量的随机变量集合, v v v则是所有观测变量的随机变量集合,而 h ( 1 ) h^{(1)} h(1)中的随机变量不是真实的,而是基于模型假定的。因此,称 P ( h ( 1 ) ) \mathcal P(h^{(1)}) P(h(1))为 先验概率;
- 而 P ( v ∣ h ( 1 ) ) \mathcal P(v \mid h^{(1)}) P(v∣h(1))则是给定隐变量条件下,样本的 生成过程(Generative Process)。
这些样本自然不是真实的,而是模型产生的‘幻想粒子’(Fantasy Particle).与幻想粒子相关的传送门
由于是无向图模型,因而同上,从有向图的角度观察,可以将图结构中的每一条边视作双向的。也就是相互关联:

如果假设模型参数已经被学习完成,这意味着模型参数固定, P ( v ∣ h ( 1 ) ) \mathcal P(v \mid h^{(1)}) P(v∣h(1))也被固定住:
这里的 n n n表示模型中观测变量的数量, m m m表示模型中隐变量的数量。相关推导过程见RBM推断任务——后验概率
P ( v ∣ h ( 1 ) ) = ∏ i = 1 n P ( v i ∣ h ( 1 ) ) P ( v i ∣ h ) = { P ( v i = 1 ∣ h ) ⇒ Sigmoid ( ∑ j = 1 m w i j ⋅ h j + b i ) P ( v i = 0 ∣ h ) ⇒ 1 − Sigmoid ( ∑ j = 1 m w i j ⋅ h j + b i ) \begin{aligned} \mathcal P(v \mid h^{(1)}) & = \prod_{i=1}^n \mathcal P(v_i \mid h^{(1)}) \\ \mathcal P(v_i \mid h) & = \begin{cases} \mathcal P(v_i = 1 \mid h) \Rightarrow \text{Sigmoid} \left(\sum_{j=1}^m w_{ij} \cdot h_j + b_i\right)\\ \mathcal P(v_i = 0 \mid h) \Rightarrow 1 - \text{Sigmoid} \left(\sum_{j=1}^m w_{ij} \cdot h_j + b_i\right) \end{cases} \end{aligned} P(v∣h(1))P(vi∣h)=i=1∏nP(vi∣h(1))=⎩ ⎨ ⎧P(vi=1∣h)⇒Sigmoid(∑j=1mwij⋅hj+bi)P(vi=0∣h)⇒1−Sigmoid(∑j=1mwij⋅hj+bi)
而 P ( v ) \mathcal P(v) P(v)是真实样本关于随机变量的联合概率分布,自然是确定的:
相关推导过程详见RBM推断任务——边缘概率,这里的 b b b表示各观测变量与自身的关联关系(常数,偏置)组成的向量。
P ( v ) = 1 Z exp { b T v + ∑ j = 1 m log Softplus ( W j T v + c j ) } \mathcal P(v) = \frac{1}{\mathcal Z} \exp \left\{b^T v + \sum_{j=1}^m \log \text{Softplus}(\mathcal W_j^Tv + c_j) \right\} P(v)=Z1exp{bTv+j=1∑mlogSoftplus(WjTv+cj)}
那么根据上式,先验概率 P ( h ( 1 ) ) \mathcal P(h^{(1)}) P(h(1))自然也是确定的,它同样可以使用模型参数进行表示。
通过模型学习隐变量的先验概率
相比于使用模型参数表示先验概率 P ( h ( 1 ) ) \mathcal P(h^{(1)}) P(h(1)),一个新的思路是:针对隐变量先验概率 P ( h ( 1 ) ) \mathcal P(h^{(1)}) P(h(1))进行建模,通过模型将 P ( h ( 1 ) ) \mathcal P(h^{(1)}) P(h(1))学习出来。也就是说,通过的受限玻尔兹曼机将隐变量的联合概率分布求解出来。
观察上图(黑色箭头),利用真实样本使用醒眠算法的 Weak Phase \text{Weak Phase} Weak Phase方法能够获得关于隐变量后验的样本,并基于这些样本,专门对隐变量进行训练:
也就是说,为了学习‘Sigmoid信念网络’中的隐变量,需要对隐变量进行建模,构建‘隐变量的隐变量’对其进行学习。

此时,关于 h ( 1 ) h^{(1)} h(1)的边缘概率分布可表示为:
∑ h ( 2 ) P ( h ( 1 ) , h ( 2 ) ) \sum_{h^{(2)}} \mathcal P(h^{(1)},h^{(2)}) h(2)∑P(h(1),h(2))
很明显, P ( h ( 1 ) , h ( 2 ) ) \mathcal P(h^{(1)},h^{(2)}) P(h(1),h(2))就是新构建受限玻尔兹曼机(蓝色框部分)的联合概率分布。此时将 h ( 1 ) h^{(1)} h(1)在受限玻尔兹曼机中视作观测变量,基于 P ( h ( 1 ) ∣ v ) \mathcal P(h^{(1)} \mid v) P(h(1)∣v)的后验样本,可以学习出该受限玻尔兹曼机的参数信息。通过这些参数信息产生的关于 h ( 1 ) h^{(1)} h(1)的概率分布 P ( h ( 1 ) ) \mathcal P(h^{(1)}) P(h(1))要优于原始模型参数学习的 P ( h ( 1 ) ) \mathcal P(h^{(1)}) P(h(1))。
事实上,根据第一层受限玻尔兹曼机的逻辑,我们理论上可以将层数一直叠加上去,通过构建新的隐变量学习前一层隐变量的信息。
需要注意的是,这种堆叠式结构的求解方式是有约束条件的。那就是Weak Phase中关于隐变量 h ( 1 ) h^{(1)} h(1)的后验概率分布 P ( h ( 1 ) ∣ v ) \mathcal P(h^{(1)} \mid v) P(h(1)∣v)固定的条件下实现的。
如果不去固定P ( h ( 1 ) ∣ v ) \mathcal P(h^{(1)} \mid v) P(h(1)∣v),在h ( 2 ) h^{(2)} h(2)学习P ( h ( 1 ) ) \mathcal P(h^{(1)}) P(h(1))过程中,由于P ( h ( 1 ) ∣ v ) \mathcal P(h^{(1)} \mid v) P(h(1)∣v)产生样本对应分布的细微变化(可能存在波动、噪声),导致h ( 1 ) , h ( 2 ) h^{(1)},h^{(2)} h(1),h(2)层之间的模型参数是无法被固定下来的。相反,如果没有固定P ( h ( 1 ) ∣ v ) \mathcal P(h^{(1)} \mid v) P(h(1)∣v),假设h ( 1 ) , h ( 2 ) h^{(1)},h^{(2)} h(1),h(2)之间的模型参数被学习出来,学习得到的P ( h ( 1 ) ) \mathcal P(h^{(1)}) P(h(1))和P ( h ( 1 ) ∣ v ) \mathcal P(h^{(1)} \mid v) P(h(1)∣v)之间存在偏差,反而对h ( 1 ) , v h^{(1)},v h(1),v层之间的权重信息产生影响。
当然,也可以从有向图的角度去理解该问题。如果出现了如下结构:
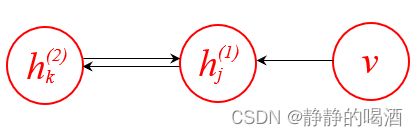
这种结构保留了v ⇒ h ( 1 ) v \Rightarrow h^{(1)} v⇒h(1)之间的关联关系,我们会发现,v , h ( 2 ) v,h^{(2)} v,h(2)之间不是完全的‘无关联’关系。因为内部包含一个V \mathcal V V型结构。一旦经过Weak Phase \text{Weak Phase} Weak Phase算法,得到了关于后验P ( h ( 1 ) ∣ v ) \mathcal P(h^{(1)} \mid v) P(h(1)∣v)的样本,此时结点h ( 1 ) h^{(1)} h(1)被观测,那么h ( 2 ) , v h^{(2)},v h(2),v之间是必不独立的。
终上,为了保证学习 h ( 1 ) h^{(1)} h(1)信息的受限玻尔兹曼机和 Sigmoid \text{Sigmoid} Sigmoid信念网络之间相互不影响,将上图中 v ⇒ h ( 1 ) v \Rightarrow h^{(1)} v⇒h(1) 部分去除:

上面过程就是深度信念网络模型的构建思想。
这里只是提到了使用受限玻尔兹曼机对隐变量的学习效果优于模型参数对隐变量的表示效果。下一节将解释为什么对隐变量建模的效果更优。
相关参考:
(系列二十七)深度信念网络2——叠加RBM的动机