Yolov5_DeepSort_Pytorch代码学习与修改记录
- 参考博客:多目标跟踪之数据关联算法——匈牙利算法
- Yolov5_DeepSort_Pytorch仓库: https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch.git
Deepsort的重点是:(我关注的是级联匹配这部分,重点分析casecade_matching,non-global assignment的特点和优缺点)
- 级联匹配 casecade_matching,non-global assignment。
指的是,每次只匹配几个track。按照since_time_update,就是连续多少帧没有匹配到dectect bbox的顺序来进行优先匹配。 - 联匹配完了,用IOU去打补丁。
Deepsort Paper原文重点:
- 参考博客:Deep SORT论文阅读总结
- DeepSORT论文翻译(SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC)_alex1801的博客-CSDN博客_deepsort论文翻译
- Deep SORT多目标跟踪算法代码解析 - pprp - 博客园
0. Abstract:
-
本方法加入了外观信息来提高SORT的性能,用余弦距离来度量 tracks 和 detection 的相似度以减少 SORT算法中ID switch的次数
-
并使用Kalman预测和实际detection间的平方马氏距离来滤除可能性小的匹配。
加入Reid提取的外观特征,对目标进行深度关联度量,ID switch减少了45%,外观距离减少ID交换;马氏距离滤除不大可能的匹配。
1. Introduction:
This is, because the employed association metric is only accurate when state estimation uncertainty is low. 翻译过来就是kalman的covariance小,costMatric才准确!
只有在状态估计的残差协方差的值较小(估计不确定性小,就是估计的方差小)时,关联的Metric才是准确的。
翻译一下就是:只有kf.covariance较小时,pos_cost_matrix的值才是靠谱的,准确的。 SORT的ID切换太多,都是因为kalman filter预测的mean的模型存在缺陷,其kf.covariance鲁棒性较差。
SORT算法ID switch次数高是因为采用的关联矩阵只在状态预测不确定性较小的时候准确(状态估计模型存在缺陷)
mark: 是啊,一直predict,不update,covariance就是一直累加累加。可不就变大了。costMatrix可不就变小了,然后unAssignedTrack就更容易匹配上Detect,因为它的Covariance太大了。————导致的后果就是:这个未指定的Track容易误匹配其他的detect。矩阵的横向,容易被匹配。
翻译一下:所以,Deepsort的作者怎么解决这个问题呢?——对metric打补丁!加入新的metric
因此,SORT在遮挡场景下存在缺陷。解决遮挡问题的办法:关联metric改为新的metric,新的metric结合了运动信息和外观信息。

2 SORT with deep association metric:
我们采用了传统的单一假设跟踪方法,逐帧数据关联。

A conventional way to solve the association between the predicted Kalman states and newly arrived measurements is to build an assignment problem that can be solved using the Hungarian algorithm. Into this problem formulation we integrate motion and appearance information through combination of two appropriate metrics.
运动模型、外观模型,两个metric的组合(翻译一下:但绝非相加之类的metric处理,因为两个metric的意义和量纲绝非一致,无法融合再一起。不不不,后面还是靠权重加在一起了!!!!!)

mark:
- ① The Mahalanobis distance takes state estimation uncertainty into account by measuring how many standard deviations the detection is away from the mean track location. Further, using this metric it is possible to exclude unlikely associations by thresholding the Mahalanobis distance at a 95% confifidence interval computed from the inverse
χ 2 distribution.
马氏距离通过测算检测与平均轨迹位置的距离,超过多少标准差,来考虑状态估计的不确定性。此外,可以通过从逆chi^2分布计算95% 置信区间的阈值,排除可能性小的关联。
翻译一下:用公式表示就是: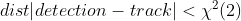 ,才是置信度范围内的马氏距离。
,才是置信度范围内的马氏距离。
-
② While the Mahalanobis distance is a suitable association metric when motion uncertainty is low, in our image-space problem formulation the predicted state distribution obtained from the Kalman filtering framework provides only a rough estimate of the object location. In particular, unaccounted camera motion can introduce rapid displacements in the image plane, making the Mahalanobis distance a rather uninformed metric for tracking through occlusions. Therefore, we integrate a second metric into the assignment problem.
当运动不确定性较低时 运动协方差covariance较小时,马氏距离是一个合适的关联度量,但在我们的图像空间问题公式中, 从卡尔曼滤波框架获得的预测状态分布 mean只提供了物体位置的粗略估计。特别是, 未计算的摄像机运动可以在图像平面上引入快速位移, 使马氏距离成为通过遮挡跟踪的一个相当未知的度量。因此,我们在分配问题中集成了第二个度量。
翻译一下:kalman的估计是粗略的,因为有相机移动等没考虑进去。所以在遮挡的情况下,马氏距离的信息量就不够了,uninformed metric
翻译一下:这个描述说没问题也没问题,比如在动态camera中,确实是这样。Kalman的预测有它的模型假设,模型失配了就存在较大的问题。但是静态camera中,马氏距离要是计算对了,可没有那么脆弱!!! - ③ 外观距离的计算:存储历史最近的100个样本的CNN特征,CNN128个维度;然后检测去挨个跟100个128的向量计算余弦距离,每一个距离都有一个阈值。在平方和100个阈值化后的[0-1]的值。作为cost的内容。 这第二个阈值t(2),我们可是在单独的另外的训练集上找到的经验值。
实际上,我们是预训练了一个CNN网络,来计算bbox的外观描述子(特征提取),这在2.4节中进一步详细解释。 - ④ 有了上面2个距离之后,大家都在[0-1]中取值,马氏距离pos_matrix是靠卡方距离来进行阈值化的,大于阈值的截断,同时用阈值来归一化,就是每行保证都是[0-1]之间,但是加起来的和可不是1。外观距离appearance_matrix是余弦距离,阈值化后的和。每一行∈[0,1],加起来也不是1。就这样的两个矩阵,用权重加权起来,得到最后的代价矩阵。
马氏距离提供了有关基于运动的可能物体位置的信息,这对于短期预测特别有用
余弦距离考虑外观信息,这对于在长期遮挡之后找回ID特别有用,此时运动不那么具有辨别力
最终的使用效果是:当相机运动时,lambda=0,不适用kalman距离了,使用外观距离;但用kalman来滤除完全不可能的匹配!!!
关联成本中仅使用外观信息。关联结果仍受两方面的约束。 仅当关联在两个度量的选通区域内时,称其为可接受关联: -
The influence of each metric on the combined association cost can be controlled through hyperparameter λ. During our experiments we found that setting λ = 0 is a reasonable choice when there is substantial camera motion. In this setting, only appearance information are used in the association cost term. However, the Mahalanobis gate is still used to disregarded infeasible assignments based on possible object locations inferred by the Kalman filter.
每个度量对联合关联成本的影响可以通过超参数λ来控制。在我们的实验中,我们发现,当有大量的摄像机运动时,设置λ=0是一个合理的选择。在此设置中,在关联代价项中只使用外观信息。然而,阈值化之后的马氏距离仍然被用于忽略基于卡尔曼滤波器推断出的可能的对象位置的不可行的分配。-
相应的代码如下面所示:(代码为:_fuull_cost_metric函数中,下图所示)
app_gate = app_cost > self.metric.matching_threshold # Now combine and threshold cost_matrix = self._lambda * pos_cost + (1 - self._lambda) * app_cost cost_matrix[np.logical_or(pos_gate, app_gate)] = linear_assignment.INFTY_COST # Return Matrix return cost_matrix
-
马氏距离是二维联合高斯分布,取log后的值,可以认为是概率分布。
但是卡方分布是两个i.i.d.的高斯分布的平方相加:
,n=2, α=95%的阈值
私以为,二者的概念都不一样,为什么要放在一起讨论????
找到原因了:The Relationship between the Mahalanobis Distance and the Chi-Squared Distribution – ML & Stats马氏距离同卡方分布的关系:作者证明了,马氏距离(不开根号),马氏距离的随机随机变量,是服从卡方分布的。卡方分布的自由度,就是马氏距离随机变量的维度。
如在此案例中,pos_matrix里面只有x,y两个坐标信息的话(中心点坐标),那么就是自由度为2的卡方分布。这里面表示的是这个马氏距离去除5%的outliers,剩下95%的置信度值。基本上,帮助有限。
同时这里的马氏距离是没有像二元高斯分布那样,加入log det|E|的部分的。没有协方差阵的行列式。

同时mark:注意到pos_cost只是除以了卡方的GATTING_THRESHOLD,并没有做normalization。所以pos_cost里面是马氏距离的原生的值。
然后 pos_cost * λ + (1-λ)* app_cost, app_cost是∈[0,1]。------------------------(两个metric直接相加,总让我无法理解! )
(私以为)两个metric能够相加的前提是:两个metric被正确消除了量纲的影响,两个metric才能被等值的考虑。
超过5%的数据都不要,只要95%置信度内的数据。 计算的cost矩阵不符合卡方分布啊!!!
卡方分布知识补充:
卡方分布_百度百科
此处自由度为2. 因为只有posx, posy两个维度的变量。所以是自由度为2的卡方分布。若是8,就是自由度为8的卡方分布。

这个代码里面:还对kalman计算的距离进行开根号处理!!! 马氏距离的原本含义是:二元联合高斯分布,即两个标准高斯分布的联合分布。不是标准高斯的,可以正交化为标准高斯的,公式自带标准化过程(去相关、正交化、去量纲…… 类似PCA,都一个意思)。
![]()
马氏距离的计算值,跟卡方距离对不上啊????!!!! 无论是原理上,还是计算过程上!!
实际的计算数值之后将贴出来,还要同样证明,每一行的track的数值相加不为1 !!!! 总的概率为1才行吧?
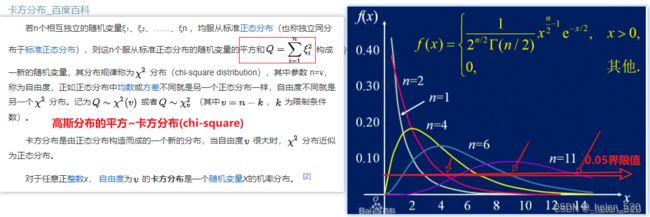
cost Matrix < thresh 的含义,是建立在costMatrix的值,服从卡方分布的情况下。然后斩断底部5%的数据为outliers。
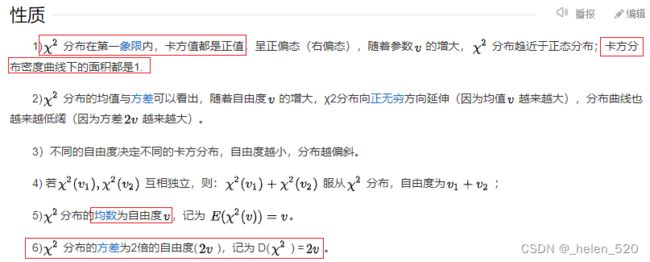

补充:卡方分布临界值表 统计分布临界值表 - 豆丁网

卡方分布知识补充:卡方分布的概率密度函数和它的一些衍生问题 - 知乎

3 匹配级联:Matching Cascade
Instead of solving for measurement-to-track associations in a global assignment problem, we introduce a cascade that solves a series of subproblems. To motivate this approach, consider the following situation: When an object is occluded for a longer period of time, subsequent Kalman filter predictions increase the uncertainty associated with the object location. Consequently, probability mass spreads out in state space and the observation likelihood becomes less peaked. Intuitively, the association metric should account for this spread of probability mass by increasing the measurement-to-track distance. Counterintuitively, when two tracks compete for the same detection, the Mahalanobis distance favors larger uncertainty, because it effectively reduces the distance in standard deviations of any detection towards the projected track mean. This is an undesired behavior as it can lead to increased track fragmentations and unstable tracks. Therefore, we introduce a matching cascade that gives priority to more frequently seen objects to encode our notion of probability spread in the association likelihood.
我们没有采用全局分配问题的求解方式,(解决全局分配问题就是以全局的方式解决检测-跟踪的关联问题),而是引入了解决一系列子问题的级联。为了激发这种方法,请考虑以下情况:当一个物体被遮挡较长时间时,随后的卡尔曼滤波预测增加了与物体位置相关的不确定性。因此,概率质量(概率密度分布函数会变平坦,没有尖峰)在状态空间中扩散,观测似然值降低(观察似然性变得不那么尖锐)。直观地说,关联度量应该通过增加测量到轨道的距离来解释概率质量的扩散。与直觉相反,当两条轨道竞争同一检测时,马氏距离倾向于更大的不确定性covariance,因为它有效地减少了任何检测对投影轨道均值的标准差距离。这是一种不希望出现的行为,因为它可能导致增加的轨道碎片和不稳定的轨道。因此,我们引入了一个匹配级联,优先考虑更常见的对象,以编码关联可能性中概率扩散的概念。
(翻译一下:我们为什么使用级联方式解决,而不是全局方式解决呢?
试想一下:当目标长时间被遮挡后,kalman预测的目标位置的误差/不确定性/covariance是会增加的。
因此,直观上来讲,我们的这个马氏距离/外观距离的metric度量应该通过增加检测-轨迹的距离值distance来将长时间遮挡导致的概率密度分布变平坦/概率下降/covariance增加,给考虑进metric中。
但是,当给一个检测框bbox分配track的时候,总是covariance大的那个track更容易被匹配。马氏距离偏爱covariance大的/也是就不确定性大的那个track。——这个是对的,没毛病
所以,这个就不合理,就会增加track碎片和不稳定的track/乱匹配的track。
所以,我们设计了一个匹配级联,优先保障频繁出现的目标匹配(先做概率高的目标匹配))

道理上是没错的! 级联匹配跟全局匹配是出于完全不同的考虑的。
说明一下(翻译一下):
① 为啥deepsort会出现遮挡后,covariance一直在增加的情况。——因为遮挡后就没有检测框了,就没有匹配了。deepsort只做kalman predict,协方差只做加法。deepsort不做kalman correct,就没有covariance协方差误差迭代的步骤。所以covariance一直在加加加,加到好几万了。『见:② 现象——kf.predict() 预测环节中的不合理之处 里面的covariance一直在加weight * mean』。所以covariance一直在predict,没有correct。
而在, https://github.com/Smorodov/Multitarget-tracker 的代码逻辑中,对于unAssignedTrack是会用predict自己预测的值去correct自己的卡尔曼的。那么covariance也会被迭代,总体来看,每一个track的covariance都是会像正常的kalman过程收敛的。根据过程噪声和观测噪声的噪声水平差异,会收敛在不同的水平。参考:kalman简单例子——初始化参数对kalman性能的影响__helen_520的博客-CSDN博客_kalman 可以看到Pn+1|n+1的收敛图。
② 按照正常来说,kalman如果在unAssignedTrack也做correct的情况下,其track的covariance是会持续降低的。
对于马氏距离的cost matrix而言,covariance降低,相当于cost Matrix除以了一个小一点的值,这一行的数值都会比上一轮改行的数值大一些。
这个收敛的变化是微小的,慢慢的,趋于平稳的。所以更重要的是,需要靠马氏距离的分母,也就是空间位置/欧氏距离的部分的区分度来进行一个补偿。协方差是为了消除x,y量纲不匹配的问题。covariance的变化不能吃掉了/淹没了/覆盖了 欧氏距离远近的这样一个差异/不能改变太多。这样才能让马氏距离这个metric在长时间遮挡的情况下,也能保证其距离metric的鲁棒性!


这个图是理解级联匹配算法的关键。第5行:先让上一帧匹配过的track去挑检测框,占着坑。
def _match(self, detections):
# Split track set into confirmed and unconfirmed tracks.
confirmed_tracks = [i for i, t in enumerate(self.tracks) if t.is_confirmed()]
unconfirmed_tracks = [i for i, t in enumerate(self.tracks) if not t.is_confirmed()]
# Associate confirmed tracks using appearance features.
matches_a, unmatched_tracks_a, unmatched_detections = linear_assignment.matching_cascade(
self._full_cost_metric,
linear_assignment.INFTY_COST - 1, # no need for self.metric.matching_threshold here,
self.max_age,
self.tracks,
detections,
confirmed_tracks,
)
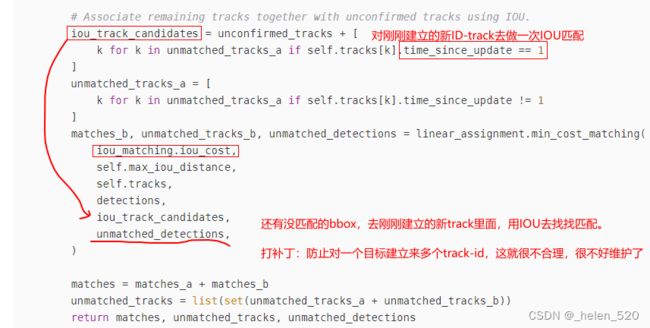
# Associate remaining tracks together with unconfirmed tracks using IOU.
iou_track_candidates = unconfirmed_tracks + [
k for k in unmatched_tracks_a if self.tracks[k].time_since_update == 1
]
unmatched_tracks_a = [
k for k in unmatched_tracks_a if self.tracks[k].time_since_update != 1
]
matches_b, unmatched_tracks_b, unmatched_detections = linear_assignment.min_cost_matching(
iou_matching.iou_cost,
self.max_iou_distance,
self.tracks,
detections,
iou_track_candidates,
unmatched_detections,
)
matches = matches_a + matches_b
unmatched_tracks = list(set(unmatched_tracks_a + unmatched_tracks_b))
return matches, unmatched_tracks, unmatched_detections补充SORT部分:
sort最大的问题,是IOU的costMatrix不可靠。导致大量的ID switch。

4 Deep Appearance Descripter 深度外观描述子
我们没做metric learning,而是使用了简单的最近邻查询 nearest neighbor queries。先得离线训练一个特征提取网络。我们采用的是在一个大规模的行人重识别数据集上训练的CNN网络,这个数据集包含了超过110万张图像,其中行人有1261个。这个数据集就非常适合在行人跟踪的上下文环境中进行deep metric learning。
行人重识别的CNN网络,128维度的特征图;有280W个参数,计算32个bboxs在GTX1050的显卡上,花了30ms,所以只要是现代的GPU,非常适合online tracking。
5 Experiment 实验部分
MOT16数据集,参数设置:检测的阈值为0.3, λ= 0和Amax = 30帧。
评价指标:参考:多目标跟踪MOT16数据集和评价指标 - 知乎
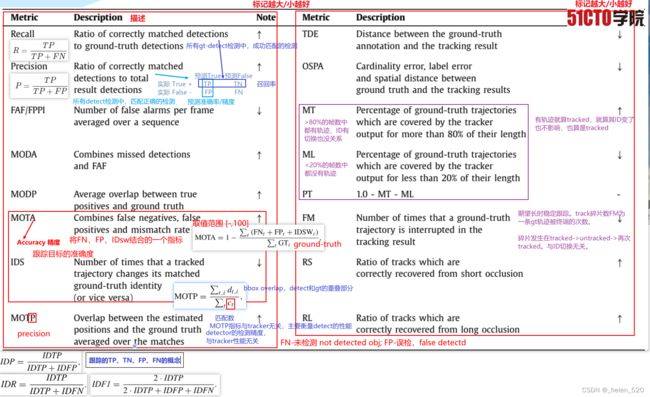
- MOTA Multi-object tracking accuracy 多目标跟踪准确度:结合了误报、漏检、和ID切换三个考虑因素,得到的总的跟踪精度。这个值越高越好。
定义为:
- MOTP(Multiple Object Tracking Precision) 多目标跟踪精确度:





与SORT相比, ID switches从1423减少到781,减少了约45%的ID切换。由于通过遮挡和遗漏来保持对象的身份,轨迹碎片会稍微增加。
还有就是MT的值增加了,就是80%的时间内track都匹配到自己的detect bbox的比例增加了。Mostly lost减少了。
我们的方法的ID交换是最少的,同时还能保持较高的MOTA分数、FM碎片率和FN 漏匹配。
如果调高了检测的置信度进行筛选,漏检增加(trick),能够大幅度提高我们算法的这些指标。(漏检对提高指标有好处!!!! 我去!)
但是呢,我们观察发现,这些错误的误匹配都是由于静态场景中的零星的检测导致的。由于我们跟踪age比较大,这些静态的目标通常会加入我们的轨迹维护中。
同时呢,我们也观察到,我们的算法不存在频繁的在误报中跳来跳去的轨迹。我们的轨迹都是比较平稳的,不会有太多跳来跳去的折线轨迹。
(完)
一、Yolov5有检测输出,deepsort无track输出,原因
测试视频:MOT_trackingDemo/test_MOT16-01.avi,MOT challenge,MOT16中的test_MOT16-01.avi。把img序列压成一个avi格式的视频。
① 现象:有检测输出,无轨迹输出
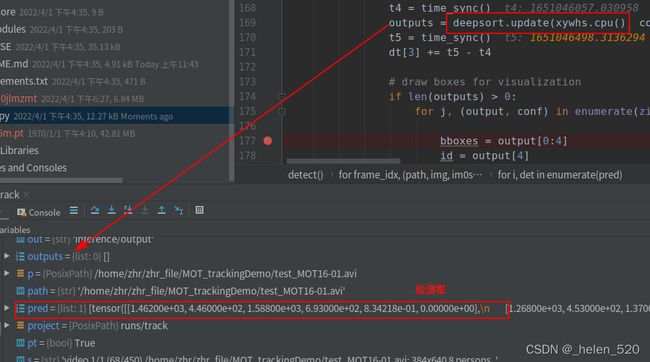
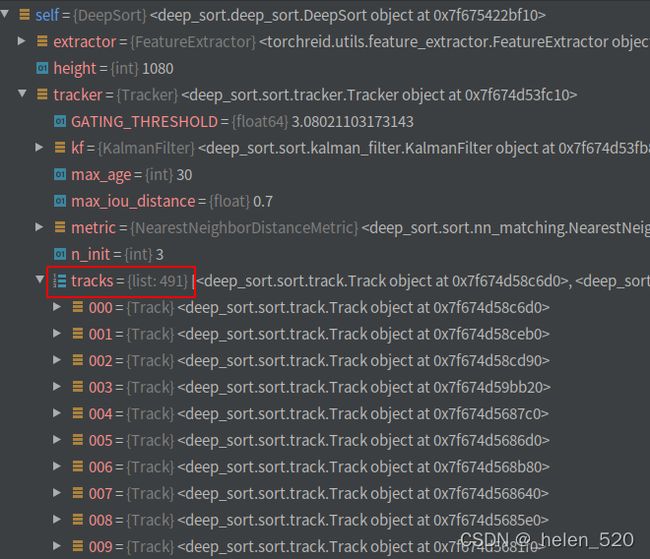
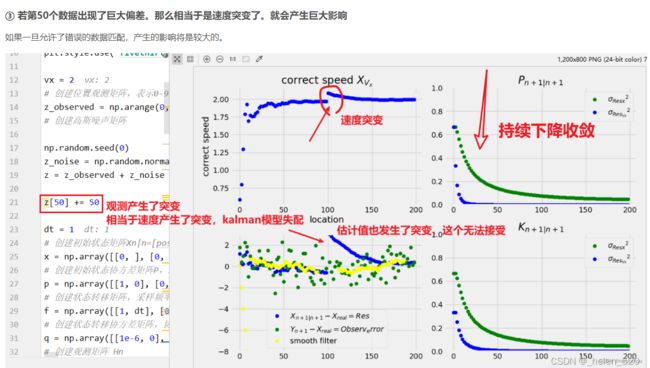
原因:第68帧为止,新建了491个ID了。(代码丝毫无改动的情况下)——基本上毫无匹配
video 1/1 (66/450) /home/zhr/zhr_file/MOT_trackingDemo/test_MOT16-01.avi: 384x640 7 persons, Done. YOLO:(0.018s), DeepSort:(0.136s)
video 1/1 (67/450) /home/zhr/zhr_file/MOT_trackingDemo/test_MOT16-01.avi: 384x640 8 persons, Done. YOLO:(0.019s), DeepSort:(0.139s)
video 1/1 (68/450) /home/zhr/zhr_file/MOT_trackingDemo/test_MOT16-01.avi: 384x640 8 persons, Done. YOLO:(0.018s), DeepSort:(441.283s)② 现象——kf.predict() 预测环节中的不合理之处:这些track基本上只出现过一次,没有过匹配,也没有被删除。且track的残差协方差巨大。
残差协方差的predict过程中,过程噪声processNoiseCov Qn与状态变量强相关,不符合kalman的基本假设!————『作者设计意图&根据未知』
同时,由于track.mean的速度部分只有第一次初始化为0,所以mean一直原地踏步,没有速度增量。一旦不被匹配,一直不会被update更新,将一直停留在原地。

③ 级联匹配逻辑:cascade_depth为max_age
由于time_since_update即,目标连续XXX帧无匹配,就不进入cost Matrix计算。
def matching_cascade(
distance_metric, max_distance, cascade_depth, tracks, detections,
track_indices=None, detection_indices=None):
# cascade_depth = self.max_age # 30
if track_indices is None:
track_indices = list(range(len(tracks)))
if detection_indices is None:
detection_indices = list(range(len(detections)))
unmatched_detections = detection_indices
matches = []
for level in range(cascade_depth):
if len(unmatched_detections) == 0: # No detections left
break
track_indices_l = [
k for k in track_indices
if tracks[k].time_since_update == 1 + level
]
if len(track_indices_l) == 0: # Nothing to match at this level
continue
matches_l, _, unmatched_detections = \
min_cost_matching(
distance_metric, max_distance, tracks, detections,
track_indices_l, unmatched_detections)
matches += matches_l
unmatched_tracks = list(set(track_indices) - set(k for k, _ in matches))
return matches, unmatched_tracks, unmatched_detections命令行参数设置:
parser = argparse.ArgumentParser()
# 检测模型:模型位置,放在当前 Yolov5_DeepSort_Pytorch 目录下就可以了
parser.add_argument('--yolo_model', nargs='+', type=str, default='yolov5m.pt', help='model.pt path(s)')
# ReID模型
parser.add_argument('--deep_sort_model', type=str, default='osnet_ibn_x1_0_MSMT17')
# 视频输入:img/video、camera
parser.add_argument('--source', type=str, default='0', help='source') # file/folder, 0 for webcam
# 输出文件地址,推理output
parser.add_argument('--output', type=str, default='inference/output', help='output folder') # output folder
# 推理图像尺寸设置
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
# 目标置信度阈值筛选
parser.add_argument('--conf-thres', type=float, default=0.5, help='object confidence threshold')
# NMS的IOU阈值设置
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
# 输出视频格式设置
parser.add_argument('--fourcc', type=str, default='mp4v', help='output video codec (verify ffmpeg support)')
# GPU/CPU设置
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
# 是否展示tracking结果
parser.add_argument('--show-vid', action='store_true', help='display tracking video results')
# 是否存储视频跟踪结果
parser.add_argument('--save-vid', action='store_true', help='save video tracking results')
# 是否保存跟踪结果
parser.add_argument('--save-txt', action='store_true', help='save MOT compliant results to *.txt')
# 检测类别筛选:class 0 is person, 1 is bycicle, 2 is car... 79 is oven
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 16 17')
#
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--evaluate', action='store_true', help='augmented inference')
parser.add_argument("--config_deepsort", type=str, default="deep_sort/configs/deep_sort.yaml")
parser.add_argument("--half", action="store_true", help="use FP16 half-precision inference")
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detection per image')
# 使用opencv dnn for ONNX 推理
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
# 工程保存到runs/track/文件夹下
parser.add_argument('--project', default=ROOT / 'runs/track', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
# 就在已有的目录下,不要新建目录
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
# 模型位置,yolov5m.pt放在当前 Yolov5_DeepSort_Pytorch 目录下就可以了,其余参数设置如下
--source ../../MOT_trackingDemo/test_MOT16-03.avi --show-vid --exist-ok --class 0输出结果如下:(模型读入成功)
# 输出的结果如下:
Available ReID models for automatic download
['resnet50_market1501', 'resnet50_dukemtmcreid', 'resnet50_msmt17', 'resnet50_fc512_market1501', 'resnet50_fc512_dukemtmcreid', 'resnet50_fc512_msmt17', 'mlfn_market1501', 'mlfn_dukemtmcreid', 'mlfn_msmt17', 'hacnn_market1501', 'hacnn_dukemtmcreid', 'hacnn_msmt17', 'mobilenetv2_x1_0_market1501', 'mobilenetv2_x1_0_dukemtmcreid', 'mobilenetv2_x1_0_msmt17', 'mobilenetv2_x1_4_market1501', 'mobilenetv2_x1_4_dukemtmcreid', 'mobilenetv2_x1_4_msmt17', 'osnet_x1_0_market1501', 'osnet_x1_0_dukemtmcreid', 'osnet_x1_0_msmt17', 'osnet_x0_75_market1501', 'osnet_x0_75_dukemtmcreid', 'osnet_x0_75_msmt17', 'osnet_x0_5_market1501', 'osnet_x0_5_dukemtmcreid', 'osnet_x0_5_msmt17', 'osnet_x0_25_market1501', 'osnet_x0_25_dukemtmcreid', 'osnet_x0_25_msmt17', 'resnet50_MSMT17', 'osnet_x1_0_MSMT17', 'osnet_x0_75_MSMT17', 'osnet_x0_5_MSMT17', 'osnet_x0_25_MSMT17', 'osnet_ibn_x1_0_MSMT17', 'osnet_ain_x1_0_MSMT17']
YOLOv5 v6.1-38-g7c6a335 torch 1.11.0+cu102 CUDA:0 (NVIDIA GeForce RTX 2060, 5926MiB)
Model: osnet_ibn_x1_0
- params: 2,194,640
- flops: 978,878,352
Successfully loaded pretrained weights from "deep_sort/deep/checkpoint/osnet_ibn_x1_0_MSMT17.pth"
** The following layers are discarded due to unmatched keys or layer size: ['classifier.weight', 'classifier.bias']
YOLOv5 v6.1-38-g7c6a335 torch 1.11.0+cu102 CUDA:0 (NVIDIA GeForce RTX 2060, 5926MiB)二、MOT eval
模型文件,百度网盘链接:链接: https://pan.baidu.com/s/11I2QNucxdFAa1UWePyUrmg 密码: kqck
- 下载模型:参考 https://github.com/mikel-brostrom/Yolov5_DeepSort_OSNet/wiki/Evaluation,下载地址为:https://drive.google.com/file/d/1gglIwqxaH2iTvy6lZlXuAcMpd_U0GCUb/view谷歌网盘地址。如果有需要,我之后可以放在百度云盘里面。
下载crowdhuman_yolov5m.pt到yolov5/weights的文件夹中。
- git clone https://github.com/JonathonLuiten/TrackEval
- 下载data.zip到Yolov5_Deepsort_Pytorch主文件夹中,data.zip的下载地址为:https://omnomnom.vision.rwth-aachen.de/data/TrackEval/data.zip
- 下载MOT16.zip到Yolov5_Deepsort_Pytorch主文件夹中,MOT16.zip的下载地址为:https://motchallenge.net/data/MOT16.zip
- 在Yolov5_DeepSort_Pytorch文件夹下:运行命令 ./MOT_eval/eval.sh

MOT16 评估中:
继续跑,最后看结果和效果。是否有result统计,以及参数统计的结果。
遇到的傻问题:运行完了之后,该存的数据不知道存到哪里去了。郁闷了好久。
结果发现是脚本的问题,MOT16_eval/eval.sh,仔细看里面的脚本,里面的路径是作者设置好了的!!!!
所以最后去了作者事先设置好了的路径下面了。
$ python ~/Yolov5_DeepSort_OSNet/MOT16_eval/TrackEval/scripts/run_mot_challenge.py --BENCHMARK MOT16 --TRACKERS_TO_EVAL ch_yolov5m_deep_sort --SPLIT_TO_EVAL train --METRICS CLEAR Identity --USE_PARALLEL False --NUM_PARALLEL_CORES 4
Eval Config:
USE_PARALLEL : False
NUM_PARALLEL_CORES : 4
BREAK_ON_ERROR : True
RETURN_ON_ERROR : False
LOG_ON_ERROR : /home/zhr/Yolov5_DeepSort_OSNet/MOT16_eval/TrackEval/error_log.txt
PRINT_RESULTS : True
PRINT_ONLY_COMBINED : False
PRINT_CONFIG : True
TIME_PROGRESS : True
DISPLAY_LESS_PROGRESS : False
OUTPUT_SUMMARY : True
OUTPUT_EMPTY_CLASSES : True
OUTPUT_DETAILED : True
PLOT_CURVES : True
MotChallenge2DBox Config:
PRINT_CONFIG : True
GT_FOLDER : /home/zhr/Yolov5_DeepSort_OSNet/MOT16_eval/TrackEval/data/gt/mot_challenge/
TRACKERS_FOLDER : /home/zhr/Yolov5_DeepSort_OSNet/MOT16_eval/TrackEval/data/trackers/mot_challenge/
OUTPUT_FOLDER : None
TRACKERS_TO_EVAL : ['ch_yolov5m_deep_sort']
CLASSES_TO_EVAL : ['pedestrian']
BENCHMARK : MOT16
SPLIT_TO_EVAL : train
INPUT_AS_ZIP : False
DO_PREPROC : True
TRACKER_SUB_FOLDER : data
OUTPUT_SUB_FOLDER :
TRACKER_DISPLAY_NAMES : None
SEQMAP_FOLDER : None
SEQMAP_FILE : None
SEQ_INFO : None
GT_LOC_FORMAT : {gt_folder}/{seq}/gt/gt.txt
SKIP_SPLIT_FOL : False
CLEAR Config:
METRICS : ['CLEAR', 'Identity']
THRESHOLD : 0.5
PRINT_CONFIG : True
Identity Config:
METRICS : ['CLEAR', 'Identity']
THRESHOLD : 0.5
PRINT_CONFIG : True
Evaluating 1 tracker(s) on 7 sequence(s) for 1 class(es) on MotChallenge2DBox dataset using the following metrics: CLEAR, Identity, Count
Evaluating ch_yolov5m_deep_sort
MotChallenge2DBox.get_raw_seq_data(ch_yolov5m_deep_sort, MOT16-02) 0.2778 sec
MotChallenge2DBox.get_preprocessed_seq_data(pedestrian) 0.2561 sec
CLEAR.eval_sequence() 0.0542 sec
Identity.eval_sequence() 0.0127 sec
Count.eval_sequence() 0.0000 sec
1 eval_sequence(MOT16-02, ch_yolov5m_deep_sort) 0.6029 sec
MotChallenge2DBox.get_raw_seq_data(ch_yolov5m_deep_sort, MOT16-04) 1.1343 sec
MotChallenge2DBox.get_preprocessed_seq_data(pedestrian) 0.5486 sec
CLEAR.eval_sequence() 0.1355 sec
Identity.eval_sequence() 0.0331 sec
Count.eval_sequence() 0.0000 sec
2 eval_sequence(MOT16-04, ch_yolov5m_deep_sort) 1.8559 sec
MotChallenge2DBox.get_raw_seq_data(ch_yolov5m_deep_sort, MOT16-05) 0.1684 sec
MotChallenge2DBox.get_preprocessed_seq_data(pedestrian) 0.3186 sec
CLEAR.eval_sequence() 0.0646 sec
Identity.eval_sequence() 0.0176 sec
Count.eval_sequence() 0.0000 sec
3 eval_sequence(MOT16-05, ch_yolov5m_deep_sort) 0.5716 sec
MotChallenge2DBox.get_raw_seq_data(ch_yolov5m_deep_sort, MOT16-09) 0.1236 sec
MotChallenge2DBox.get_preprocessed_seq_data(pedestrian) 0.2047 sec
CLEAR.eval_sequence() 0.0442 sec
Identity.eval_sequence() 0.0105 sec
Count.eval_sequence() 0.0000 sec
4 eval_sequence(MOT16-09, ch_yolov5m_deep_sort) 0.3847 sec
MotChallenge2DBox.get_raw_seq_data(ch_yolov5m_deep_sort, MOT16-10) 0.1991 sec
MotChallenge2DBox.get_preprocessed_seq_data(pedestrian) 0.2612 sec
CLEAR.eval_sequence() 0.0573 sec
Identity.eval_sequence() 0.0138 sec
Count.eval_sequence() 0.0000 sec
5 eval_sequence(MOT16-10, ch_yolov5m_deep_sort) 0.5336 sec
MotChallenge2DBox.get_raw_seq_data(ch_yolov5m_deep_sort, MOT16-11) 0.1906 sec
MotChallenge2DBox.get_preprocessed_seq_data(pedestrian) 0.3497 sec
CLEAR.eval_sequence() 0.0705 sec
Identity.eval_sequence() 0.0178 sec
Count.eval_sequence() 0.0000 sec
6 eval_sequence(MOT16-11, ch_yolov5m_deep_sort) 0.6315 sec
MotChallenge2DBox.get_raw_seq_data(ch_yolov5m_deep_sort, MOT16-13) 0.2175 sec
MotChallenge2DBox.get_preprocessed_seq_data(pedestrian) 0.2918 sec
CLEAR.eval_sequence() 0.0607 sec
Identity.eval_sequence() 0.0149 sec
Count.eval_sequence() 0.0000 sec
7 eval_sequence(MOT16-13, ch_yolov5m_deep_sort) 0.5873 sec
All sequences for ch_yolov5m_deep_sort finished in 5.17 seconds
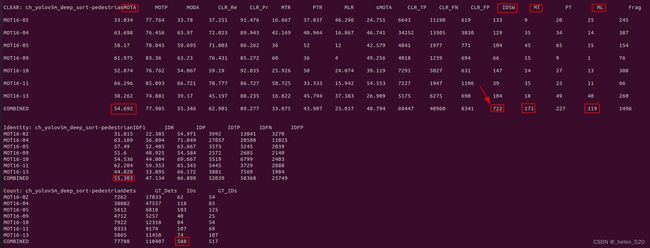
CLEAR: ch_yolov5m_deep_sort-pedestrianMOTA MOTP MODA CLR_Re CLR_Pr MTR PTR MLR sMOTA CLR_TP CLR_FN CLR_FP IDSW MT PT ML Frag
MOT16-02 33.034 77.764 33.78 37.251 91.476 16.667 37.037 46.296 24.751 6643 11190 619 133 9 20 25 245
MOT16-04 63.698 76.456 63.97 72.023 89.943 42.169 40.964 16.867 46.741 34252 13305 3830 129 35 34 14 387
MOT16-05 58.17 78.043 59.695 71.003 86.262 36 52 12 42.579 4841 1977 771 104 45 65 15 154
MOT16-09 61.975 83.36 63.23 76.431 85.272 60 36 4 49.256 4018 1239 694 66 15 9 1 76
MOT16-10 52.874 76.762 54.067 59.19 92.035 25.926 50 24.074 39.119 7291 5027 631 147 14 27 13 308
MOT16-11 66.296 85.093 66.721 78.777 86.727 50.725 33.333 15.942 54.553 7227 1947 1106 39 35 23 11 66
MOT16-13 38.262 74.881 39.17 45.197 88.235 16.822 45.794 37.383 26.909 5175 6275 690 104 18 49 40 260
COMBINED 54.692 77.905 55.346 62.901 89.277 33.075 43.907 23.017 40.794 69447 40960 8341 722 171 227 119 1496
Identity: ch_yolov5m_deep_sort-pedestrianIDF1 IDR IDP IDTP IDFN IDFP
MOT16-02 31.815 22.385 54.971 3992 13841 3270
MOT16-04 63.189 56.894 71.049 27057 20500 11025
MOT16-05 57.49 52.405 63.667 3573 3245 2039
MOT16-09 51.6 48.925 54.584 2572 2685 2140
MOT16-10 54.536 44.804 69.667 5519 6799 2403
MOT16-11 62.204 59.353 65.343 5445 3729 2888
MOT16-13 44.828 33.895 66.172 3881 7569 1984
COMBINED 55.303 47.134 66.898 52039 58368 25749
Count: ch_yolov5m_deep_sort-pedestrianDets GT_Dets IDs GT_IDs
MOT16-02 7262 17833 62 54
MOT16-04 38082 47557 118 83
MOT16-05 5612 6818 103 125
MOT16-09 4712 5257 40 25
MOT16-10 7922 12318 84 54
MOT16-11 8333 9174 107 69
MOT16-13 5865 11450 74 107
COMBINED 77788 110407 588 517
Timing analysis:
MotChallenge2DBox.get_raw_seq_data 2.3113 sec
MotChallenge2DBox.get_preprocessed_seq_data 2.2309 sec
CLEAR.eval_sequence 0.4870 sec
Identity.eval_sequence 0.1204 sec
Count.eval_sequence 0.0000 sec
eval_sequence 5.1675 sec
Evaluator.evaluate 5.1695 sec
https://github.com/mikel-brostrom/Yolov5_DeepSort_OSNet/wiki/Evaluation
作者给出的结果是:
数据基本上对应的上,我跑出来的指标略有下降。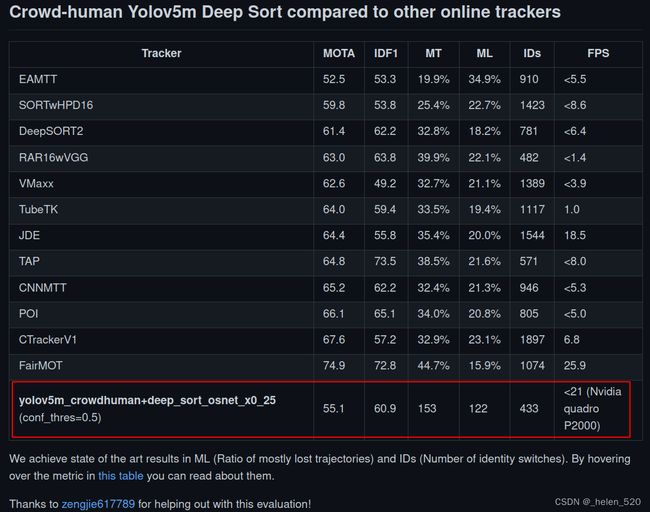
2.1 指标分析
参考博客:多目标跟踪MOT16数据集和评价指标 - 知乎


三、新版本的代码阅读分析
GitHub - mikel-brostrom/Yolov5_DeepSort_OSNet: Real-time multi-camera multi-object tracker using YOLOv5 and Deep SORT with OSNet
源码仓库地址: https://github.com/mikel-brostrom/Yolov5_DeepSort_OSNet
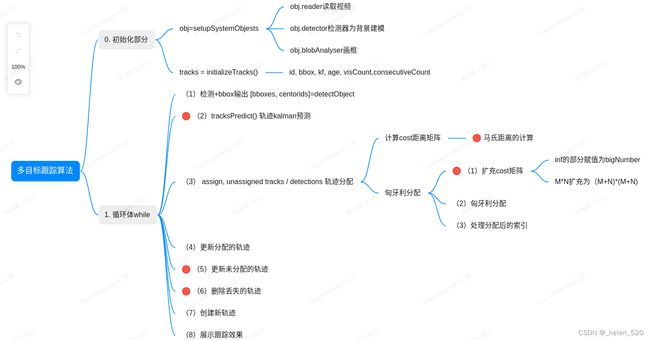
大体架构如此所示:

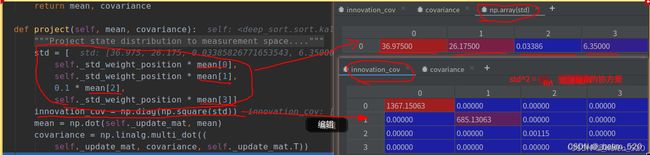
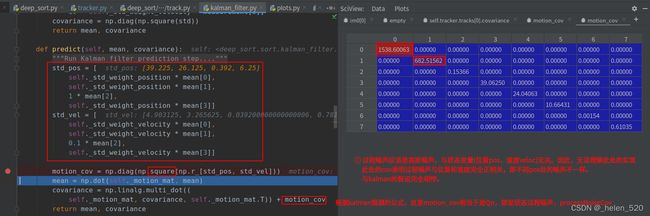
track的构成:
预测阶段:对track的mean和covariance进行更新。
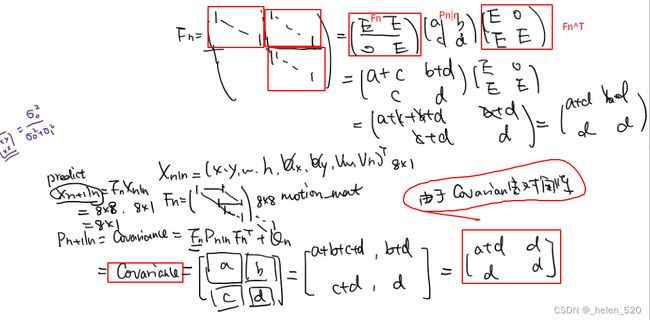
mean=Fn * mean, ![]() ,
,![]() ,[x_pos, y_pos, width, height, v_x, v_y, v_wid, v_hei] = [x_pos+v_x, y_pos+v_y, width+v_wid, height+v_hei, v_x, v_y, v_wid, v_hei]
,[x_pos, y_pos, width, height, v_x, v_y, v_wid, v_hei] = [x_pos+v_x, y_pos+v_y, width+v_wid, height+v_hei, v_x, v_y, v_wid, v_hei]
3.1 新建track时,kalman filter的初始化 covariance跟bbox本身息息相关
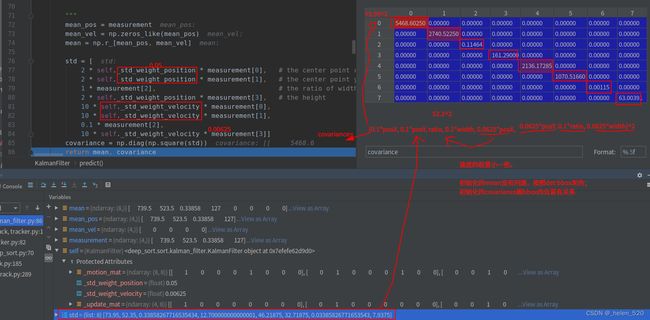
3.2 kalman filter predict 所有的track的kf都会predict
预测: 残差协方差的迭代过程——就是越加越多。
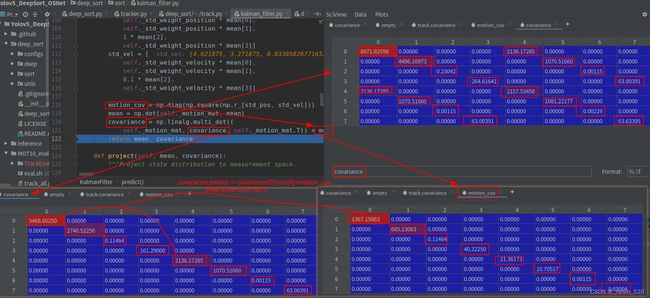

3.3 kalman filter的update,即correct()步骤,covariance小了很多。
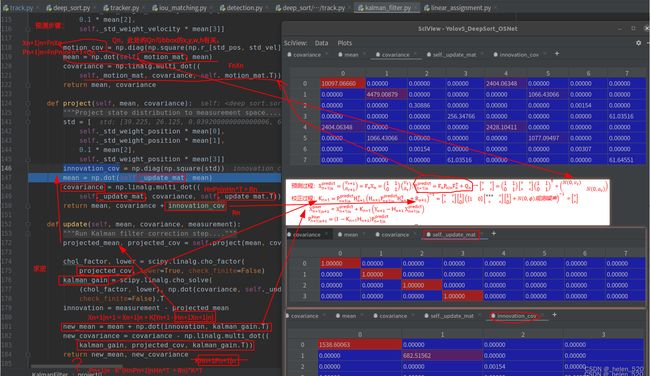
这里的correct的校正公式,并不跟传统的kalman校正公式吻合。
原因是python的求逆的代码的理解:![]() ,所以就是求
,所以就是求 ![]() 的解x(K)。
的解x(K)。
所以这样求得的就是K,kalman_gain,卡尔曼增益。projected_conv == ![]() ,projected_conv是取左上角部分,projected_mean也是取前半部分。
,projected_conv是取左上角部分,projected_mean也是取前半部分。
这样的话,covariance衰减的速度更慢了。————————主要是投影的projected_cov为4×4,但covariance为8×8,所以要转换矩阵size。没有用Hn-update_mat来转换,而是使用了KPK^T的格式来进行的转换。
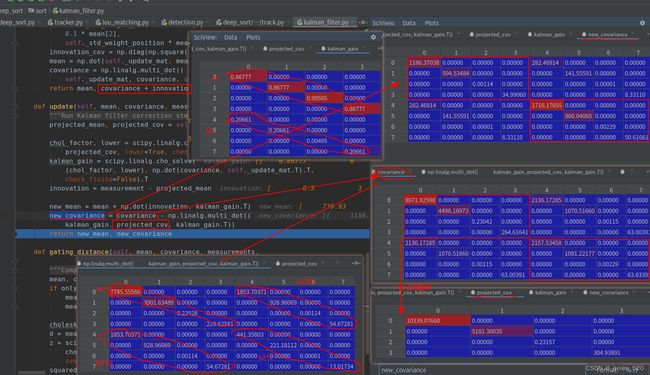
这里的covariance是() 
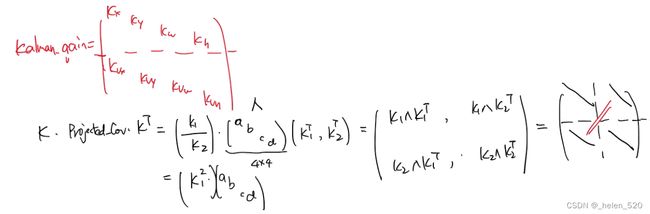

① projected_convariance的理解:Hn*Convariace*Hn^T = 取出covariance的左上角的4×4的矩阵块。
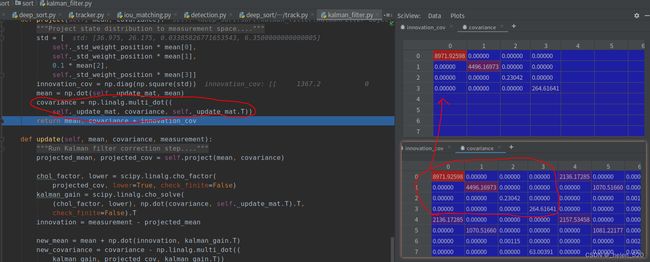

② projected_cov对角加载上Qn,过程噪声的协方差,就变成了kalman gain中的求逆部分。===projected_cov ,加的是Rn,是观测噪声。
所以![]() 中Rn的作用,就是对角加载了(目前而言的作用) 。取出covariance的左上角,再对角加载。
中Rn的作用,就是对角加载了(目前而言的作用) 。取出covariance的左上角,再对角加载。