墨天轮沙龙 | 清华乔嘉林:Apache IoTDB,源于清华,建设开源生态之路
在6月8日举办的【墨天轮数据库沙龙第七期—开源生态专场】中,清华大学博士,助理研究员,Apache IoTDB PMC 乔嘉林老师分享了《Apache IoTDB,源于清华,建设开源生态之路》主题演讲,本文为整理内容。
导读 大家好,我是来自清华大学的乔嘉林。Apache IoTDB是一个开源项目,起源于清华大学实验室,后续开源并捐给了Apache 基金会。今天我分享的内容主要分为四个方面:IoTDB 背景起源、IoTDB 介绍、开源建设以及如何加入我们。
背景起源
1、时序数据是什么
首先,IoTDB管理的是时序数据,即随着时间轴而不断变化的曲线数据,比如股票中的K线就是很典型的时序数据。时序数据在物联网领域中占据了很大的体量,它是设备物理量的数字化记录,是物理世界的真实刻画。
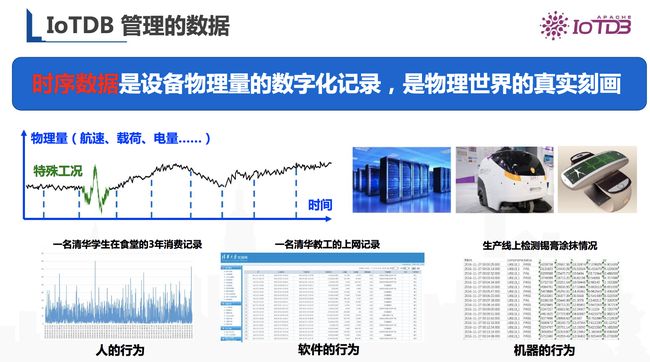
图1 时序数据示意
时序数据的用途主要分为四个场景:监控、告警、预测、追溯。
首先是监控场景的应用:大家都希望可视化监控软件,从而清晰看到它的运行状态。
其次时序数据能够用于告警场景。工业企业对机器设备进行监控时,很难用肉眼去分辨软件运行中的异常,因此我们需要去设置一些有效的规则,当数据超过预设的阈值时,实现报警的功能。
时序数据还能实现预测。当设备运行状态不好时,我们可以根据根据历史经验与数据变化的趋势,来预测这个设备是否会坏掉,从而帮助企业避免不必要的损失。
最后时序数据还能实现追溯。当我们发现故障,可以通过历史数据故障发生的原因来分析历史数据的变化规律,从而得到一些有用的知识,来避免后续的故障复现。

图2 时序数据的用途
2、IoTDB 发展起源
IoTDB 的发展一共历经了六个阶段。
2011年蕴育期:在国家 863 计划课题中,在三一重工等企业实践海量机器数据管理解决方案。
在工业物联网背景下,需要做到复杂元数据管理、海量数据存储、丰富的数据处理、边云协同,这些对数据管理都是极大的挑战。

图3 工业物联网数据管理需求
在这样的背景下,基于传统的关系型数据库单点瓶颈,模型难以修改写入、性能难以满足的痛点,我们从2011年开始尝试大数据管理方案,如Cassandra、HBase,但是它们也存在着一定的瓶颈。
因此我们调研了不同数据库管理时序数据的区别,如下图所示:
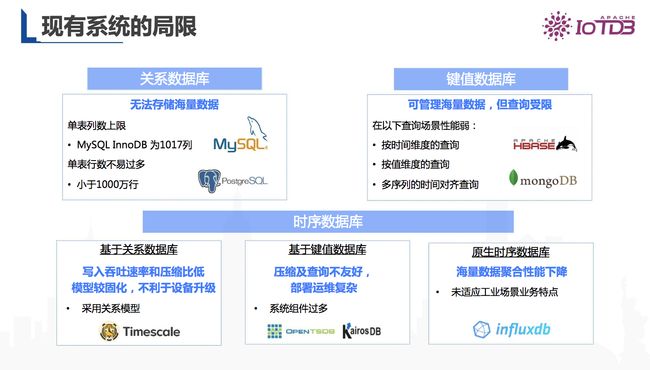
图4 现有系统管理时序数据的局限
因此从2015年我们进入了IoTDB的自研期,开始启动“清华IoTDB”研制。2016年3月提出时序数据列式紧致文件存储格式TsFile,随后发布 0.7.0 版本。
从研发数据文件格式开始,IoTDB的自研历程就此开启。下面的格式图描述了两个部分:左边是数据区,采用了列式存储的方式,将每一个时间序列的时间和值都分开存储,这样能够更好的实现编码和压缩。右边为索引图,能够对海量的时间序列快速查询。
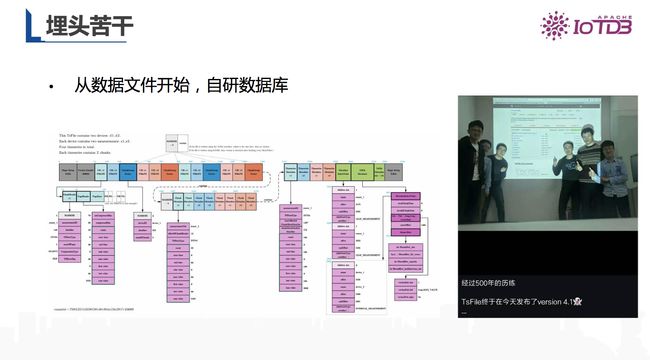
图5 数据管理的格式图
IoTDB 首次的实战项目是青海新能源大数据平台,项目是管理各个发电集团在青海发电厂的数据,在实战的过程中,我们也发现了工业管理中时序数据会存在的一些问题,比如乱序、数据规模不高,规模较大等,这些问题的发现也为我们后续的系统升级与完善提供了宝贵的经验。

图6 IoTDB实战于青海新能源大数据平台
IoTDB在2018年进入了开源孵化期。同年11月,IoTDB 成为Apache 旗下孵化器项目,先后吸引了来自德国、美国、澳大利亚等国际同行关注。
IoTDB为什么要开源?在这里分享我们的想法。
IoTDB起源于高校,我们希望实现真刀真枪参与实际的项目。因此IoTDB的定位不仅是科研项目,更应该是工业级的产品,能够真正部署到这个用户的这个实际项目,能够产生价值,发挥价值。
第二点IoTDB作为基础软件,需要更广大的贡献者和用户的共同参与。
不仅如此,对标国外伯克利高校,他们拥有Spark这款做计算比较标准化的一个产品,我们希望中国高校也能打造一款开源软件,来提升中国高校在国际的影响力。
那么在开源的过程中为什么会选择Apache基金会呢?因为Apache是大数据系统的世家,平时我们熟知的Hadoop、Spark、HBase、Flink都是起源于Apache孵化器。时序数据作为大数据的种类,我们希望能够将这个项目开发齐全,从而选择Apache基金会。
以上就是IoTDB开源的路线。

图7 时序数据库从默默无闻到逐渐火热
2019年IoTDB 实现快速成长。项目相继获得优秀大数据产品、中国优秀开源项目一等奖,并在中国工业互联网峰会作为重要成果作主题发布。
2020年IoTDB 成功毕业。Apache IoTDB 升为全球顶级项目,这标志着 IoTDB 建成了全球认可的国际开源社区,并成为我国高校在Apache 社区主导的唯一孵化成功的项目。
2021年IoTDB 入选十三五成果。Apache IoTDB参加国家“十三五”科技创新成就展。
回顾IoTDB 的发展历程,可谓是“十年磨一剑”。

图8 Apache IoTDB 发展历程
IoTDB介绍
1、Apache IoTDB 是什么
Apache IoTDB(物联网数据库)是一体化收集、存储、管理与分析物联网时序数据的软件系统。它具有高性能和丰富的功能,并与 Apache Hadoop、Spark 和 Flink 等进行了深度集成,可以满足工业物联网领域的海量数据存储、高速数据读取和复杂数据分析需求。
Apache IoTDB 还拥有简单易用、低成本高性能、便捷迁移、丰富的数据处理生态、提供端-边-云”一站式解决方案的性能。
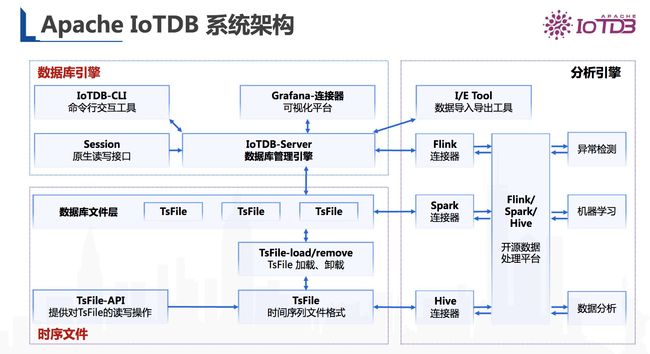
图9 Apache IoTDB 系统架构
2、Apache IoTDB 特点
Apache IoTDB 作为一款轻量化、高性能、低成本时序数据库,具有开放的系统架构、轻量化部署、生态丰富、物联网专属模型、高压缩比、低延迟查询、数据处理丰富、高效存储引擎等八大特点。

图10 Apache IoTDB 的八个特点
下图为 IoTDB 在开源、模型、查询、文件上与其他时序数据库的对比。
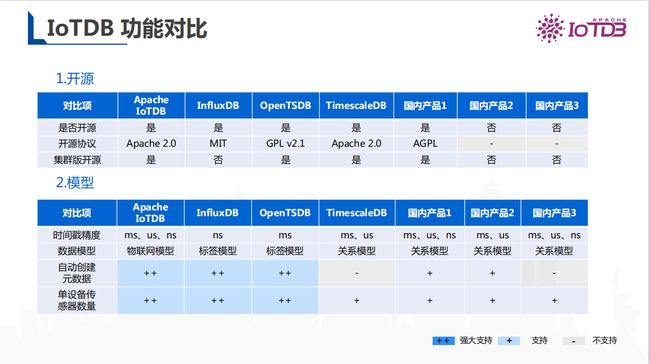
图11 Apache IoTDB 在开源、模型、查询、文件上与其他数据库的对比
3、Apache IoTDB 功能
IoTDB具有实现多种查询视图,查询时支持各类视图的SQL逻辑的功能。写入时是物联网的元数据,但在查询时可以转化为多种视图,每种视图都有SQL查询列,以及实现不同的过滤的条件,这样我们就可以根据业务系统的不同需要,针对不同的维度进行查询,从而实现写入非常动态的模型。
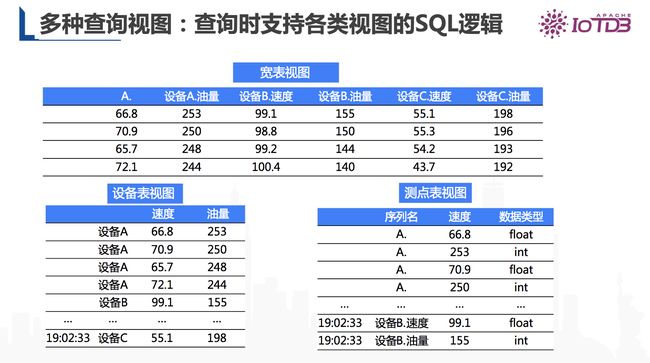
图12 Apache IoTDB 支持多种查询视图
不仅支持多种查询视图,IoTDB还具有查询功能丰富,支持降采样、数据对齐、修补的功能。在查询中能够实现降采样成每分钟1个数据点、多序列按时间进行数据对齐、 修补缺失的数据。

图13 Apache IoTDB 查询功能丰富
除了以上功能以外,IoTDB 还支持用户自定义函数,用户通过自行开发、创建自定义函数来满足定制化的计算需求。同时,目前已内置 11 类 UDF 库,共 75个 函数,供用户使用。
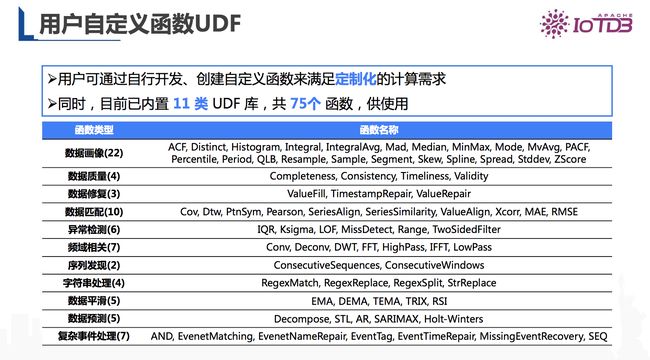
图14 Apache IoTDB UDF函数类型及名称
此外IoTDB具有自定义触发器,实现实时计算的功能。时序数据有告警的需求,因此我们在IoTDB中支持了触发器,当一条数据进入数据库时,基于校验的逻辑触发到某个阈值,便可以对其他系统进行一个告警。
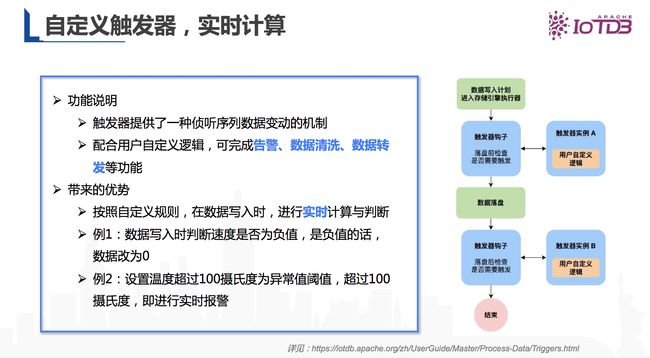
图15 Apache IoTDB 自定义触发器的功能
下图展示的功能是物化视图。我们希望对设备A和设备B的速度取出平均值,那我们就可以通过average这个函数来查询,接着将计算的结果写回到数据库里面,这样便于下次使用时直接取用结果,无需重复计算。以上就是物化视图 select into的功能实现场景。
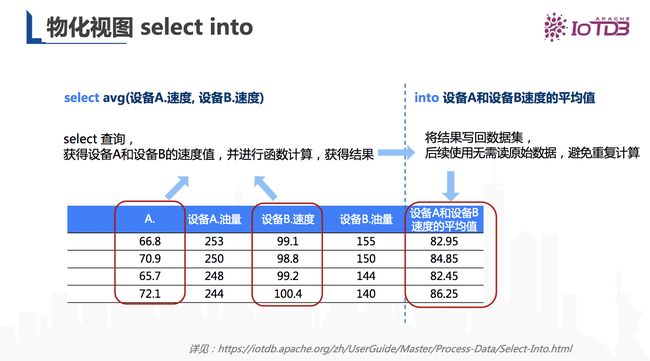
图16 Apache IoTDB 物化视图功能
最后介绍的是IoTDB连续查询的功能,这个功能在时序数据的管理应用中非常广泛。我们通常以高频的方式进行数据采集,同时不想漏掉任何一个点,但是分析时需要对数据进行各种各样的降采样或者分段的聚合,如果我们能够提前对数据进行分段并将它存下来,就能大大加速后续的分析效率。因此连续查询能够实现对后台操作自定义,并定时将一段时间的数据做计算与处理。

图16 Apache IoTDB 连续查询功能
开源建设
1、关于Apache 基金会
Apache 基金会成立于199年,目前已有22年的历史,共有351个项目,总的代码数是2.2亿行。这些代码的总价值是220亿美元,共有8200个committer。
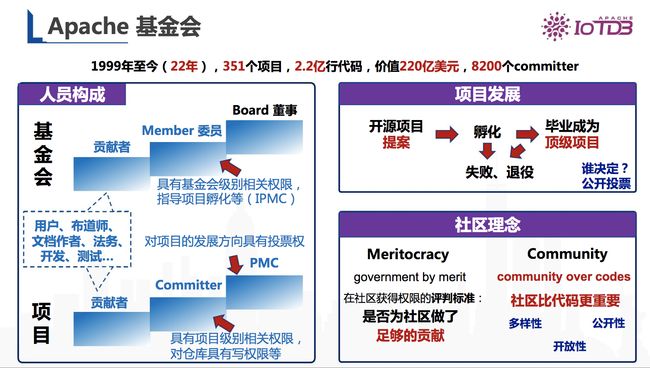
图17 Apache 基金会发展
2、IoTDB 的开源建设
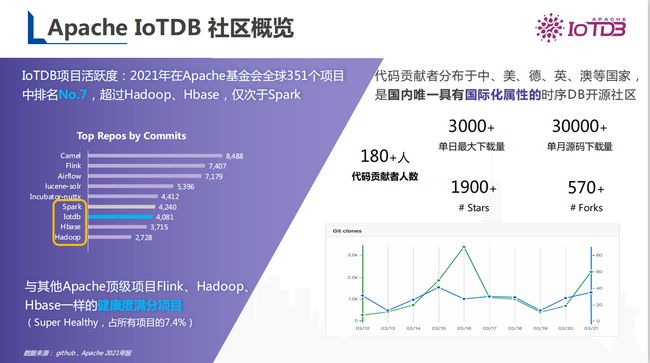
在2021年的Apache基金会全球351个项目排名中中,IoTDB 位列第七,超过Hadoop、Hbase,仅次于Spark。IoTDB 的代码贡献者分布于中、美、德、英、澳等国家,是国内唯一具有国际化属性的时序DB开源社区。
加入社区
开发者是开源的获益者,更应该成为贡献者,这也是 IoTDB 选择开源的原因。
以下是参与社区的通道,欢迎大家参与到开源建设中来。

图18 加入IoTDB组织
我今天的分享就到这里,谢谢大家!
更多精彩内容,欢迎大家观看现场视频回放与会议资料
视频回放:https://www.modb.pro/video/6499
会议资料:https://www.modb.pro/doc/64961
- 查看原文:https://www.modb.pro/db/421250
- 查看【国产数据库沙龙】开源生态专场文章、视频回放资源:https://www.modb.pro/topic/412121
欲了解更多可以进入墨天轮社区,围绕数据人的学习成长提供一站式的全面服务,打造集新闻资讯、在线问答、活动直播、在线课程、文档阅览、资源下载、知识分享及在线运维为一体的统一平台,持续促进数据领域的知识传播和技术创新。
关注官方公众号: 墨天轮、 墨天轮平台、墨天轮成长营、数据库国产化 、数据库资讯