前端数据监控
文章目录
-
- 有什么数据需要收集?
- 收集完,怎么上报?
-
- 自动上报数据
- 手动上报数据
- 上报数据形式
- 上报完,各种数据怎么处理?
- 例子
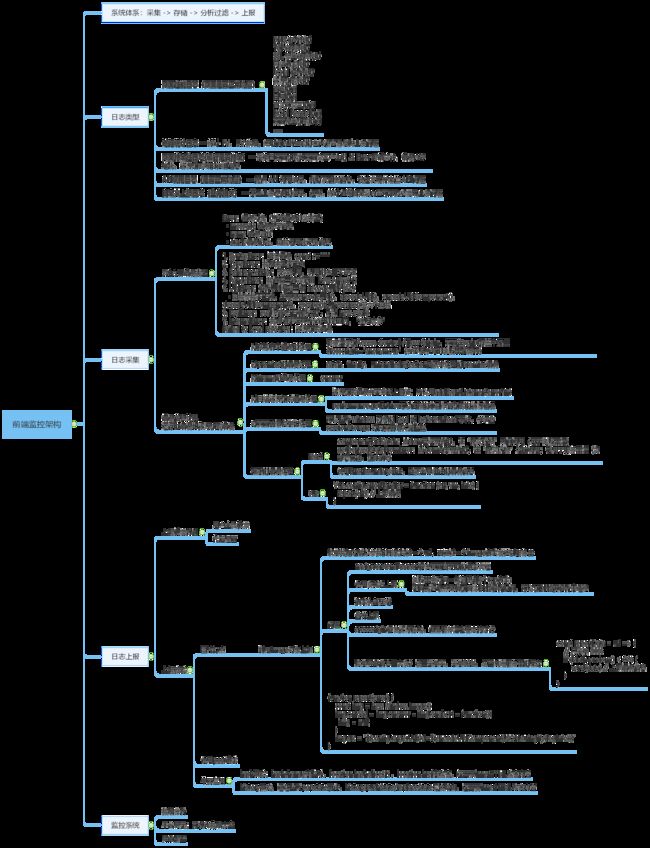
为什么要数据监控平台?各维度数据量化,去衡量真实用户的加载速度
监控平台链路:sdk上报,上报到服务器和数据存储(接收上报心想、数据清洗、入库),展示分析
有什么数据需要收集?
监控指标:
- 登录异常、启动过程异常
- 服务器页面加载失败404、500、503
- 混合App内部报错(套壳错误:webview、NW.js、Electron)
- 服务器接口返回错误
数据采集流程:上报、收集、清洗、入库
收集完,怎么上报?
自动上报数据
在head标签中嵌入上报数据的sdk脚本
收集哪些数据:
- error 错误类型数据、
- performance性能相关数据、
- 环境相关数据(公共数据)
- pid:projectId,产品的具体编号,方便我们以某个产品维度为基准进行查询
- uid:userId,以用户的uid为查询参数对数据进行存储的,以及方便跟踪错误相关的用户数据
- sid:sessionId,记录用户当次登录的所有操作
- version:版本。
- ua:userAgent 的缩写,是浏览器默认获取相关 IP、浏览器型号、操作系统版本等通用环境信息的数据。
- 开关类数据:比如,是否采集错误数据、是否采集性能数据、数据是否为测试数据,测试数据会上传到日志服务器,但是不会入库(主要是为了检测从收集到上报的链路。
手动上报数据
自动上报数据只能解决通用代码层面的错误问题,不能解决逻辑错误问题,逻辑错误对计算机来说不是错误,
所以需要人工甄别出什么样的错误是逻辑错误,然后制定出规则,在不匹配的情况下手动触发数据上报
- 用户行为数据:比如监控用户在线时长
- 流程错误数据:记录用户按照特定流程操作的数据集合
上报数据形式
- 通过请求方式get\head\post请求方式把数据传输到服务器
- 使用加载资源的方式(js/css/图片)把需要上报的数据传输到服务器(推荐,没有跨域问题)
图片体积小、支持透明。支持透明图片有BMP(BMP32格式可以支持透明,最小请求数据需要74字节)、png(67字节)、gif(43字节)
const log = (type = '', code, detail = {}, extra = {}){
const logInfo = {
type,
code,
detail: detailAdapter(code, detail),
extra: extra,
common: {
...commonConfig,
timestamp: Date.now(),
runtime_version: commonConfig.version,
sdk_version: config.version,
page_type: pageType
}
}
// 动态创建图片进行数据上报
var img = new window.Image();
img.src =「」.concat(feeTarget,「?d=」).concat(encodeURIComponent(JSON.stringify
(logInfo)));
}</code>
https://sdk.test.com/img01.gif?d={"detail":{"navigationStart":1550739289058,"unloadEventStart":0,"url":"m.test.com/bj/"},"common":{"pid":"test","uuid":...},"version":"1.0.0","sdk_version":"1.0.40","page_type":"m.test.com/bj/"}}
浏览器中对脚本报错信息有跨域限制, 通过标签引入js时, 需要在所有要监控的script标签中添加 crossorigin="anonymous" 属性后, 才能获取到错误堆栈数据, 否则只能看到Script error的提示
<script src="https://xxx.com/xxx.js" crossorigin="anonymous"></script>
上报完,各种数据怎么处理?
数据采集后,数据分析(机器学习)专家一般会对数据进行筛选、降维、建模(清洗、入库)
1)上报的数据在进入服务器时,会在服务器上留下访问日志
每次访问nginx服务器,会会把访问的日志写入access.log文件(这就是要收集的数据,前端监控平台的数据来源)
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
}
2)如果只有一台日志服务器或者日志量不大,可以监控access.log日志文件变化,将服务器日志access.log清洗入库。
日志服务器可能是多台机器,就需要引入kafka
数据存储:
例子
// sdk.js
import perf from './perf.js'
perf.init((perform)=>{
// 上传到后台
console.log('perf init', perform);
})
// perf.js
export default {
init: (cb) => {
Util.domready(() => {
// ...
// 收集数据后,传给cb带会去
cb(perfData);
});
}
}
开源产品:
sentry 搭建 vue react 一起使用 开箱即用
灯塔
商业产品:神策
参考:
书籍:从零搭建前端监控平台
Script error.解决方法
未完待续…