XGBoost论文阅读
目录
1.摘要
2.方法
2.1 正则化学习目标
2.2 梯度提升树
2.3 收缩率和列采样
2.4分裂点查找算法
2.5 稀疏数据感知的节点分裂方法
3.工程实现
3.1 用block按列存储每个特征
3.2 分布式并行加速
1.摘要
提出了一种新的稀疏性感知算法,同时提供了一种缓存访问模式、数据压缩和分片,以构建可扩展的树增强系统。
XGBoost支持在各个场景中使用。提出一种树学习方法,支持稀疏数据,并行化和分布式训练、支持更快的模型探索。XGBoost是Boosting算法的一种工程实现。支持核外计算、缓存感知、和稀疏感知的学习。其次,支持正则化学习。
2.方法
2.1 正则化学习目标
加法模型
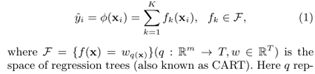
文章中给出了一个例子,对一个样本的预测值等于所有树预测值的加和

目标函数
损失和正则项,其中正则项包括,第k个叶子节点数量的正则项,以及叶子分数的正则项,这两项都是用来控制模型复杂度

目标函数 = 损失 + 正则项
l是衡量预测值yi与真实值yi的损失函数,是一个可微的凸函数。Ω(fk)是用于控制模型复杂度的惩罚项。用于平滑学习的权重, 防止过拟合。使用正则项倾向于使用简单的预测函数。
2.2 梯度提升树
目标函数是第i个样本的真实值yi,预测值由前t-1棵树的输出yi(t-1)加上第t棵树的输出ft(xi),之间的误差,加上对第t棵树的正则项组成。

将目标函数对ft-1(x)进行泰勒展开,

其中,![]() ,表示l对yi(t-1)的一阶偏导数,l对yi(t-1)的二阶偏导数为,
,表示l对yi(t-1)的一阶偏导数,l对yi(t-1)的二阶偏导数为,![]()
疑问:
(1)将目标函数展开成一阶偏导数和二阶偏导数的形式?
(2)为什么是对yi(t-1)的偏导数?
L(y,yit-1)为常数项,可以删除,于是目标函数变成以下形式

提前计算好每个样本的一阶导数和二阶导数,然后将每个叶子节点中每个样本的一阶导、二阶导分别相加,使用得分函数得到每个节点的分数Obj(w), 是让L=0,计算其极小值对应的分数.
树分裂的方式是,每个特征的每个值,找到分裂后增益最大(目标函数减小最多)的值作为分裂点。


将样本形式的目标函数转换成叶子节点形式
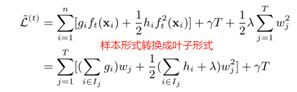
令L = 0,求L的极小值,得到w的最优解w*,并代入L求得L的最优解
![]()

公式(6)可以用于衡量树结构的好坏,分裂后目标函数L的减少量表示为
L分裂减少量 = L分裂前 – L分裂后

2.3 收缩率和列采样
如何理解收缩?
目标函数中12λj=1Twj2是指对每个叶子节点分数wj2(如果是回归,则是叶子内所有样本预测值的平均,分类则是投票)的正则项,收缩指的是使用λ这样一个正则化因子对叶子节点的分数进行正则化,使得原始的L变成带有约束项的优化。
文章解释这样做的目的是削弱当前树对最终预测的影响(因为是加法模型,每个样本的预测值为所有树预测的加和),留空间给后面的树进行学习,以提升模型
为什么不将一棵树学得很复杂? 防止过拟合!

为什么进行列采样?
第二个技术是对特征(列)进行采样。文章提到,使用列(特征)采样比使用行(样本)采样更能防止过拟合。同时,列采样技术的使用也加快了后面描述的并行算法的计算速度。但是损失了最终的精度。
如何做列采样?
列采样分为按列(特征采样),选候选的分裂特征;和按值采样,采样特征中的值作为候选的分裂点;如果选取了按列或者按值采样,则在后序每一层节点分裂过程中都会使用相应的候选特征或候选分裂点。
采样的个数要尽可能的多才有效果。
2.4分裂点查找算法
2.4.1 精确贪心算法
在分裂的时候需要枚举每个特征的每个值,找到分裂后目标函数减小的最多的特征和对应的值作为分裂点,时间复杂度高。因此对特征进行采样。
XGBoost把类别特征也当做了连续特征。为了能高效枚举分裂点,需要根据特征的值对数据进行排序,访问数据同时累加样本的梯度,来计算树的得分。

2.4.2 近似算法
精确贪心算法的不足在于,(1)时间复杂度高,(2)当数据量很大时,不能完全放入内存中去。
近似算法的做法是,根据分位数为每个特征提供一些候选的分裂点,并提前计算好这些分裂点的一阶和二阶导数。然后找到增益最大的特征及对应的值作为分裂点。

总结起来,在精确贪心算法上提出两个优化方向,第一个是列采样,通过减少特征数,来减少外层循环的枚举次数;第二个是近似算法,通过提供特征的候选分裂点(分位数点),减少内层循环的次数。这样做的代价是损失了模型精度。
For k = 1 to m do
GL = 0,GR = 0
For j in sorted(I, by xjk) do
GL = GL + gj, HL = HL + hj
GR = G – GL,HR = H – HL
Score = max(Score,Gain)
END
END
加权分位法
为什么进行加权?如何进行加权?
近似算法中的一个重要步骤是提出候选分割点,找到一组分位点,{sk1,sk2,…,skl},分位数划分方法认为两个分位点之间的样本数量相同。
为什么进行加权,特征xi每个值的样本数量不同,不服从均匀分布,使用分位数对特征的值进行划分的方法存在样本数量不均匀的问题。有些样本出现的多,有些出现的少;有些样本影响大,有些样本影响小;
使用损失函数的二阶导数hi,进行加权,hi权重越大,代表样本数量越多;对权重进行归一化,给定一个超参数ε, 对于桶内样本权重不超过ε的样本集,可以划分到同一个桶内;
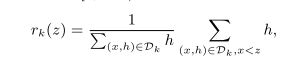
上式为归一化的权重,分母为特征k的所有特征的权重之和,分子为每个特征值所对应的权重。按权重将样本划分到不同的桶内,每个桶内的样本数量不同

2.5 稀疏数据感知的节点分裂方法
稀疏的来源:1)缺失值,2)统计中经常出现0,3)特征工程,例如one-hot向量;为了应对这些稀疏类型的数据,XGBoost提出将其带有这些样本的特征添加到默认的树节点中,默认方向包括,XGBoost以统一的方式处理所有稀疏模式。XGBoost在枚举每个特征的每个数值时,分别尝试将特征缺失的样本划分到左子树,划分到右子树,看哪个的收益更大;就将缺失样本划分到哪个子树中。

3.工程实现
3.1 用block按列存储每个特征
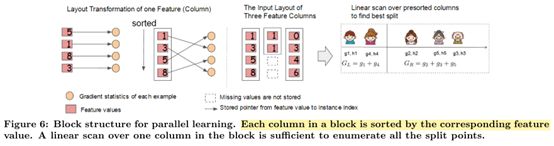
整个XGBoost最耗时的部分是树学习过程中,在节点分裂时,需要枚举每个特征的每个值,需要将样本按照某一特征进行排序;将排序好的特征按列存储在内存单元中,称为block。在block上同时对所有列的特征进行线性扫描,足以枚举所有的分裂点
3.2 分布式并行加速
For k = 1 to m do
GL = 0,GR = 0
For j in sorted(I, by xjk) do
GL = GL + gj, HL = HL + hj
GR = G – GL,HR = H – HL
Score = max(Score,Gain)
END
END通过block存排序的特征,按列进行存储特征i, 在内层循环遍历特征的时,使用多线程的方式遍历每个block从上到下同时遍历所有特征的值,从而将外层循环消除;
通过特征预先排序,按列存储特征将内层循环消除。
同时每个特征的值存储了每个样本的索引。
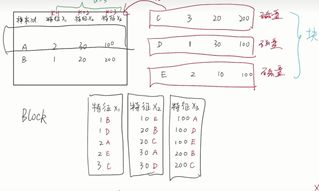
分块到不同的机器扫描,最后将gain结果进行汇总,得到最佳的特征及对应的值

缓存优化,为每个特征分配一个buffer,使用buffer将原来不连续的样本,存储每个样本的一阶和二阶导

参考:
https://www.bilibili.com/video/BV1nP4y177rw?p=15&vd_source=843e98298bc70b0e35331918314486ce