softmax分类器matlab代码_【机器学习】对数线性模型之Logistic回归和SoftMax回归,最大熵模型...

来源 | AI小白入门
作者&编辑 | 文杰、yuquanle
原文链接:
【机器学习】对数线性模型之Logistic回归、SoftMax回归和最大熵模型mp.weixin.qq.com
一、Logistic回归
分类问题可以看作是在回归函数上的一个分类。一般情况下定义二值函数,然而二值函数构成的损失函数非凸,一般采用sigmoid函数平滑拟合(当然也可以看作是一种软划分,概率划分):从函数图像我们能看出,该函数有很好的特性,适合二分类问题。至于为何选择Sigmoid函数,后面可以从广义线性模型导出为什么是Sigmoid函数。
逻辑回归可以看作是在线性回归的基础上构建的分类模型,理解的角度有多种(最好的当然是概率解释和最小对数损失),而最直接的理解是考虑逻辑回归是将线性回归值离散化。即一个二分类问题如下:(二值函数)
Sigmod函数:
0-1损失的二分类问题属于一种硬划分,即是与否的划分,而sigmoid函数则将这种硬划分软化,以一定的概率属于某一类(且属于两类的加和为1)。Sigmoid函数将线性回归值映射到 [0,1]的概率区间,从函数图像我们能看出,该函数有很好的特性,适合二分类问题。 因此逻辑回归模型如下:
这里对于目标函数的构建不再是最小化函数值与真实值的平方误差了,按分类原则来讲最直接的损失因该是0-1损失,即分类正确没有损失,分类错误损失计数加1。但是0-1损失难以优化,存在弊端。结合sigmoid函数将硬划分转化为概率划分的特点,采用概率
同样采用梯度下降的方法有:
又:
所以有:
概率解释:
逻辑回归的概率解释同线性回归模型一致,只是假设不再是服从高斯分布,而是
所以最大化似然估计有:
logistic采用对数损失(对数似然函数)原因:
1)从概率解释来看,多次伯努利分布是指数的形式。由于最大似然估计导出的结果是概率连乘,而概率(sigmoid函数)恒小于1,为了防止计算下溢,取对数将连乘转换成连加的形式,而且目标函数和对数函数具备单调性,取对数不会影响目标函数的优化值。
2)从对数损失目标函数来看,取对数之后在求导过程会大大简化计算量。
二、Softmax回归
Softmax回归可以看作是Logistic回归在多分类上的一个推广。考虑二分类的另一种表示形式:
当logistic回归采用二维表示的话,那么其损失函数如下:
其中,在逻辑回归中两类分别为
其中向量的第
其中函数值是一个
其中
概率解释:
二分类与多分类可以看作是二元伯努利分布到多元伯努利分布的一个推广,概率解释同Logistic回归一致。详细解释放到广义线性模型中。
对于多分类问题,同样可以借鉴二分类学习方法,在二分类学习基础上采用一些策略以实现多分类,基本思路是“拆解法”,假设N个类别
一对一的基本思想是从所有类别中选出两类来实现一个两分类学习器,即学习出
一对多的基本思想是把所有类别进行二分类,即属于
三、最大熵模型:
很奇怪,为什么会把最大熵模型放到这,原因很简单,它和Logistic回归和SoftMax回归实在是惊人的相似,同属于对数线性模型。
熵的概念:
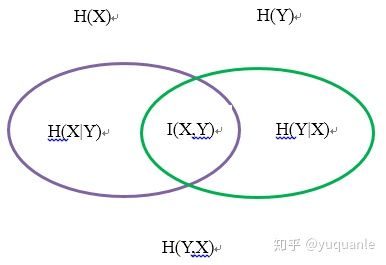
信息熵:熵是一种对随机变量不确定性的度量,不确定性越大,熵越大。若随机变量退化成定值,熵为0。均匀分布是“最不确定”的分布 。
假设离散随机变量X的概率分布为
其中熵满足不等式
联合熵:对于多个随机变量的不确定性可以用联合熵度量
假设离散随机变量
条件熵:在给定条件下描述随机变量的不确定性
假设离散随机变量
互信息:衡量两个随机变量相关性的大小
相对熵(KL散度):衡量对于同一个随机变量两个概率分布
有互信息和相对熵的定义有下式:
关于熵的介绍就到此,不细究,虽然上面的这些定义在机器学习中都会遇到,不过后面涉及到的主要还是熵和条件熵,互信息。
最大熵模型:
最大熵原理是概率模型学习中的一个准则。最大熵原理认为,学习概率模型时,在所有可能的概率模型分布中(满足所有条件下),熵最大的模型是最好的模型。熵最大即为最均匀的分布,从某种角度讲均匀分布总是符合我们理解的损失风险最小,也就是“不要不所有的鸡蛋放到一个篮子里,均匀的放置”。
给定训练集
一般来讲,最大熵模型常用于处理离散化数据集,定义随机变量
特征函数:
约束条件:对于任意的特征函数
特征函数
所以,满足约束条件的模型集合为:
因此最大熵模型的形式化表示如下:
由拉格让日乘子法,引入拉格让日乘子,定义拉格让日函数:
根据拉格朗日乘子法,
里层是
对偶问题是:
求解对偶问题,第一步最小化内部
那么外层最大化目标函数为:
为了求解
求解得:
这里,虽然我们不知道
因此,
代回
回顾对偶函数,内部最小化求解得到了
概率解释:
已知训练集的经验概率分布
其中,我们发现对数似然函数与条件熵的形式一致,最大熵模型目标函数前面有负号(这与最大化对数似然函数完全相反),同时最大熵模型中有约束条件。也正是因为约束条件,我们将原问题转化为对偶问题后发现,在满足约束条件的对偶函数的极大化等价于最大化对数似然函数。
当条件概率
代入到对数似然函数,同样有:
最后,我们再来看对偶函数表达式,我们发现,第一项其实是
下面再来对比下Logistic回归,SoftMax回归,最大熵模型:
1)同属于对数线性模。
2)Logistic回归和SoftMax回归都基于条件概率
3)由于都采用线性模型,三者都假设特征之间是独立的。
最大熵模型的优化问题:
最大熵模型从拉格朗日乘子法最大化对偶函数,还是从最大化对数似然函数,其目标函数如下:
常用的梯度优化算法都可以,另外对于最大熵模型也有专门的算法有GIS IIS 算法 。
代码实战
1.逻辑回归:
int LogReg()
{
const char *file="dataLogReg.txt";
const string model="gradAscent";
const double alpha=0.01;
Matrix x;
cout<<"loadData"<0)
{
cout<<1-y.data[i][0]< 2.SoftMax回归
int SoftMaxReg()
{
const char *file="dataLogReg.txt";
const string model="gradAscent";
const double alpha=0.01;
Matrix x;
cout<<"loadData"<test.data[i][1])
cout<<0-y.data[i][1]<<" ";
else
cout<<1-y.data[i][1]<<" ";
cout< 详细代码:
https://github.com/myazi/myLearn/blob/master/LineReg.cppgithub.com本文首发于公众号:AI小白入门(ID:StudyForAI),期待与您的相遇。
